ChatRex: Taming Multimodal LLM for Joint Perception and Understanding 论文理解和翻译
一、TL;DR
- MLLM在感知方面存在不足(远远比不上专家模型),比如Qwen2-VL在coco上recall只有43.9%
- 提出了ChatRex,旨在从模型设计和数据开发两个角度来填补这一感知能力的缺口
- ChatRex通过proposal边界框输入到LLM中将其转化为retrieval任务
- 构建了一个data-engine,提出了Rexverse-2M数据集,支持了感知和理解的联合训练。
二、简要介绍
为什么要开发本文方法?
- MLLM缺乏细粒度的感知能力,特别是在目标检测方面。Qwen2-VL-7B在IoU阈值为0.5时仅达到了43.9%的recall
为什么出现这种情况?
MLLMs中感知和理解之间的性能差距主要源于两个因素:
- 感知和理解这两个任务之间的建模冲突
- 缺乏能够平衡感知和理解的数据。
对于目标检测,一种常见的做法是将边界框坐标量化为LLM词汇表中的token,以适应自回归框架。尽管这通过next token预测确保了与理解任务的兼容性,但我们认为这种方法与准确建模感知存在冲突,原因有三:
- 错误传播:表示一个边界框通常需要9个token,包括数字、方括号和逗号,其中任何一个标记的错误都可能导致级联错误,在多目标检测中情况会变得更糟。在后续实验中,我们发现这是召回率低的原因之一;
- 预测顺序的模糊性:在目标感知中,物体之间没有固有的顺序,然而自回归的特性却强加了一个顺序,LLM必须决定先预测哪个物体;
- 量化范围限制:当图像尺寸较大时,容易出现量化误差。
ChatRex怎么解决?
对于像图像描述和图像问答这样的多模态理解任务,我们保留了自回归文本预测框架。对于感知,特别是目标检测,将其转变为一个基于检索的任务。
具体来说,直接将边界框作为输入提供,每个边界框通过将其RoI feature与其位置embedding相结合来表示为一个对象token。当LLM需要引用一个物体时,它输出相关边界框的索引。这种方法将每个边界框表示为一个未量化的单一token,其顺序由输入的边界框决定,有效地解决了之前的建模冲突。
使用这种方法有两个关键挑战:
- 需要高分辨率的视觉输入:双视觉编码器设计,增加了一个额外的视觉编码器,为感知提供高分辨率的视觉信息
- 一个强大的目标proposal模型:引入了一个通用提议网络(UPN),它在预训练的开放集目标检测模型上利用基于粒度的提示学习。这使得能够生成覆盖多样化粒度、类别和领域的proposal,从而为LLM提供强大的边界框输入。
从数据角度来看:
- 当前的MLLMs也受到缺乏能够有效平衡感知和理解的数据的限制。
- 开发了一个完全自动化的数据引擎,构建了Rexverse-2M数据集,该数据集包含不同粒度级别的图像-区域-文本注释三元组。
- 数据引擎由三个主要模块组成。第一个模块为输入图像生成图像描述,第二个模块使用一个基础模型对引用的对象或短语进行对齐,第三个模块在多个粒度级别上细化区域描述。
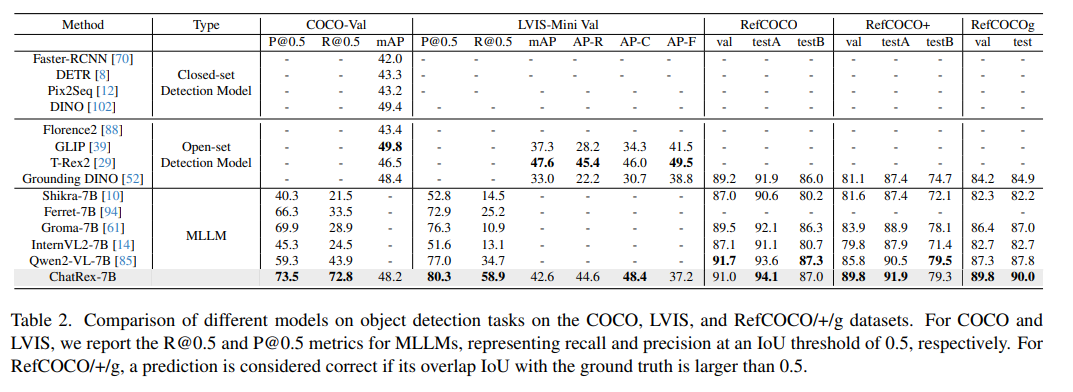
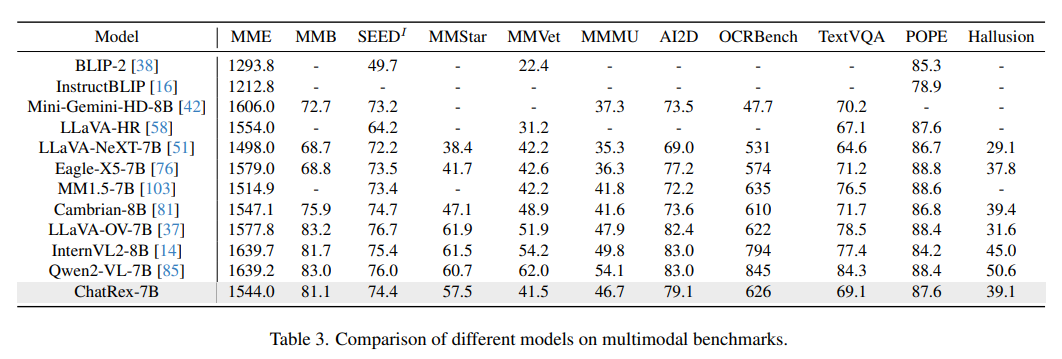
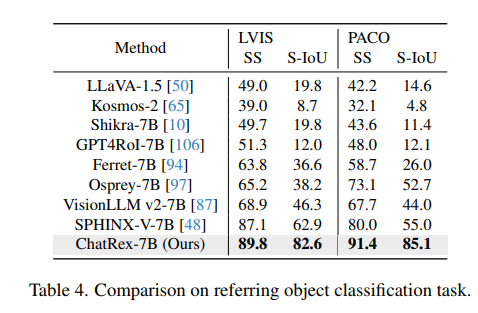
实验结果表明,ChatRex在目标检测任务中表现出色,包括COCO、LVIS和RefCOCO/+/g,同时在多模态基准测试中也展现出具有竞争力的性能。如图1所示。
 三个主要贡献:
三个主要贡献:
-
揭示了MLLMs在感知方面的性能差距,并引入了解耦的模型ChatRex和通用提议网络(UPN),以解决感知和理解之间的建模冲突。
-
开发了一个自动化数据引擎,创建了Rexverse-2M,这是一个全面支持感知和理解任务的数据集,用于模型训练。
-
实验结果表明,ChatRex展现出强大的感知和多模态理解能力,强调了这两种互补能力对于MLLM来说都是必不可少的。
三、模型结构
ChatRex 采用了一种将感知与理解解耦的设计(注意后面的训练策略)。
- 对于感知部分,我们训练了一个通用proposal网络来检测任意物体,并为 LLM 提供边界框输入。
- 对于理解部分,我们采用了标准的 LLaVA 结构,并引入双视觉编码器以实现高分辨率图像编码。
3.1 通用提议网络(UPN)
要求proposal模型具备两个关键特性:
- 强大的泛化能力,能够在任何场景中为任意物体生成提议框;
- proposal框应全面,涵盖实例级和部件级的物体。
我们采用了双粒度提示调整策略(直接采用多数据集合并不行,由于其标注规则不一样):
具体来说,我们以 T-Rex2 作为基础模型。该模型输出目标查询 Qdec,这些查询通过一个 MLP 来预测边界框。这些边界框的分类是通过查询和提示嵌入 E 之间的点积来实现的:
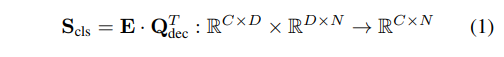
其中,C 表示类别数量,N 表示检测查询的数量(默认为 900),D 是输出查询的通道维度。我们通过引入两个额外的可学习提示 Pfine 和 Pcoarse,并将它们连接成 Pconcat 来将边界框分类为细粒度或粗粒度类别:
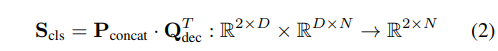
在训练过程中,我们使用 SA-1B 作为细粒度数据集,其他检测数据集(如 COCO 和 O365)作为粗粒度输入。这种双粒度提示设计有效地解决了不同数据集之间的标注歧义问题,使提议模型能够准确地捕捉和描述不同细节级别的物体。
3.2 多模态大语言模型架构
双视觉编码器:如图 3 所示,我们使用 CLIP 中的 ViT 进行低分辨率图像编码,使用 LAION 中的 ConvNeXt 进行高分辨率图像编码。
为了减少输入到 LLM 的视觉标记数量,我们首先调整两个视觉编码器的输入分辨率,确保它们在最后一个尺度上生成相同数量的标记。然后,我们将这两个标记直接沿着通道维度连接起来,产生与低分辨率标记数量相同的标记。
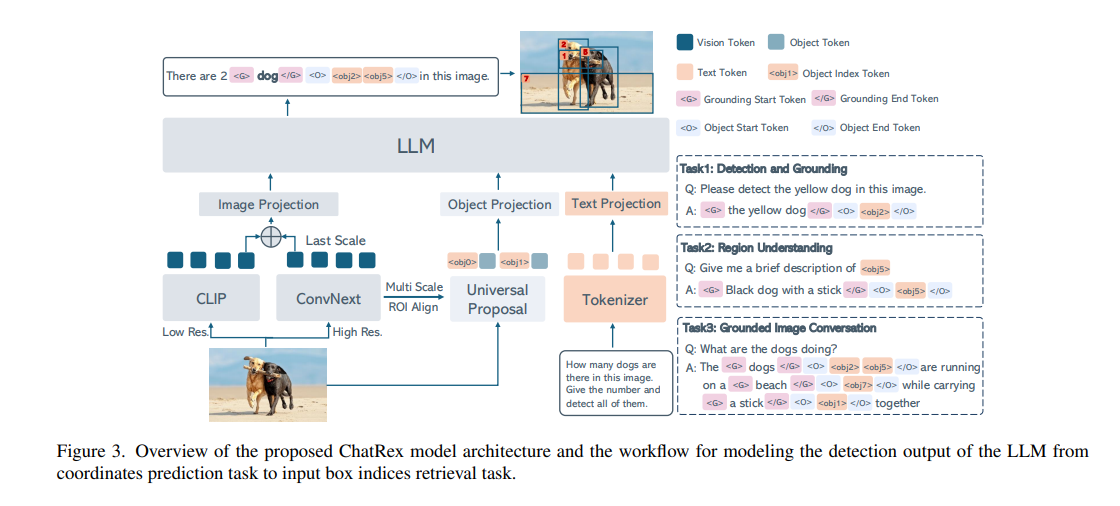
目标编码器:我们将通用提议网络输出的每个边界框编码为目标标记,并将它们输入到 LLM 中。
假设从 UPN 输入 K 个边界框 {Bi}i=1K,令 FH 表示高分辨率编码器产生的多尺度视觉特征,对于每个边界框 Bi,我们使用多尺度 RoI Align 提取其内容特征 Ci:
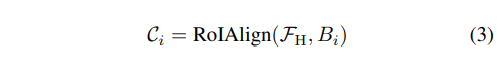
由于 RoI 特征不包含位置信息,而位置信息对于指代任务至关重要,我们通过正弦-余弦位置嵌入层对每个边界框坐标进行编码,并将其添加到 RoI 特征中:
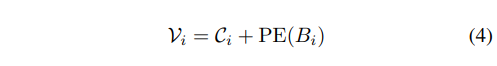
LLM:使用两个单独的 MLP 投影器将视觉和目标token映射到文本空间。我们还在每个目标标记中添加一个索引标记,以告知 LLM 每个目标标记的索引,具体将在第 3.3 节中描述。
视觉token随后与文本token连接起来,并输入到 LLM 中进行下一个token预测任务。我们默认使用 Qwen2.5-7B 作为我们的 LLM。
3.3 任务定义
将利用 LLM 进行检测的任务定义为对输入边界框的索引选择过程。为此,我们首先通过引入专用token来扩展 LLM 的词汇表,包括目标索引标记 <obj0>、<obj1>、...、<objN>(其中 N 表示输入边界框的最大数量,在本工作中设置为 100),基础token<g>、结束token</g>、目标开始token<o> 和目标结束token</o>。
LLM 输入格式:LLM 的输入标记序列结构如下:
![]()
其中,<image> 表示视觉编码器的视觉token,<roi> 表示与每个相应边界框相关联的目标特征。每个 <roi> token都以其相应的目标索引标记作为前缀。
解耦的任务定义:LLM 产生的检测结果使用以下名词短语和边界框索引的组合来构建:
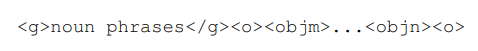
其中,<objm> 和 <objn> 指代特定的目标索引 token, token与名词短语相关联的检测到的物体序列的起始(m)和结束(n)。这种结构化的格式使得名词短语与其对应的边界框索引之间能够实现精确的映射。
凭借这种输入输出模式,ChatRex 能够处理各种任务,例如检测、基础定位、区域理解以及基础对话,除了生成纯文本响应之外,如图 3 所示。
4. 数据和训练
本文目标是为了构建一个可以有效用于感知和理解任务的数据集,最终构建了一个包含两百万张标注图像的 RexVerse-2M 数据集,其多粒度标注是通过一个完全自动化的数据引擎生成的。然后,我们采用 LLaVA 中的标准两阶段训练方法,使模型在保留感知能力的同时逐步获得多模态理解和对话技能。
4.1 RexVerse-2M 数据引擎
我们的目标是。为了实现这一目标,我们的数据管道专注于生成包含图像描述、区域描述和边界框的标注三元组。如图 4 所示,数据引擎围绕三个核心模块构建:图像描述、目标定位和区域描述。
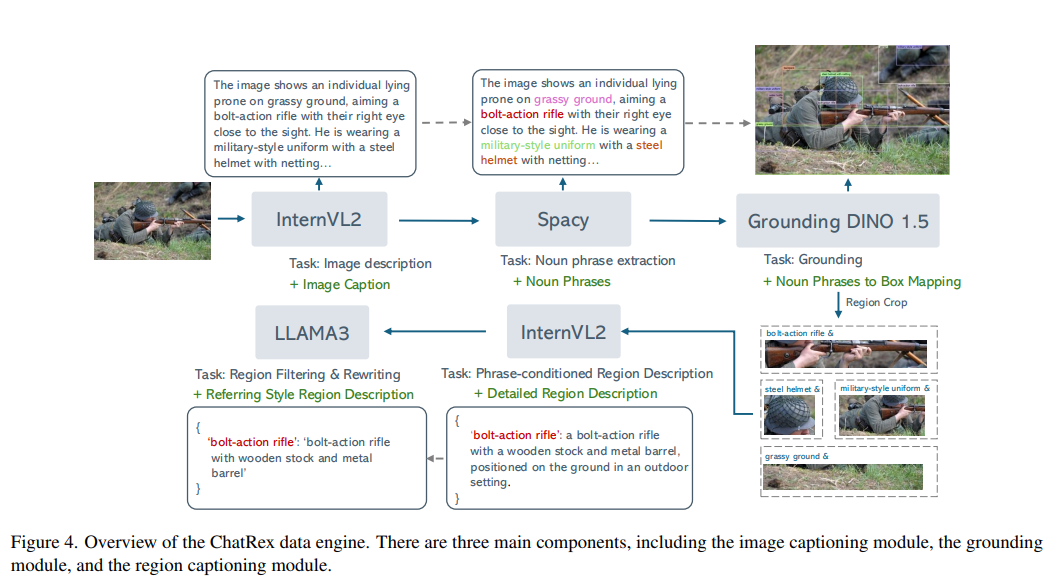
图像收集:我们从 COYO700M 数据集中收集图像,通过一系列过滤过程,包括移除分辨率小和带有 NSFW 标签的图像。我们还训练了一个图像分类器,以过滤掉具有纯白色背景的低内容网络图像。最后,我们选择了两百万张图像作为数据集图像。
图像描述:我们使用 InternVL2-8B 为每张图像生成图像描述。这些图像描述将通过类别名称或描述性短语引用图像中的主要物体。
短语定位:然后,我们利用 SpaCy 从生成的图像描述中提取名词短语。根据描述,SpaCy 可能会识别出类别名称,如“士兵”,或者描述性短语(每个区域至少 3 个单词),如“军装风格的制服”。我们还将过滤掉一些可能不是物体的抽象名词,如“图像”“背景”等。随后,我们使用 Grounding DINO 1.5 对过滤后的名词短语进行定位。这一过程最终产生与它们的类别名称或简短短语描述相关联的边界框。
短语条件区域描述:类别名称或简短短语通常提供的信息有限,们实现了一种短语条件的图像描述策略,利用 InternVL2-8B 模型 生成与每个区域相关的预定义短语相条件化的图像描述。通过这些短语引导模型,我们确保生成的描述更加准确且与上下文相关,提高caption质量
区域描述过滤与重写:最后,使用 LLaMA3-8B 来验证生成的描述是否准确地与它们的原始类别名称或简短短语对齐,过滤掉任何剩余的幻觉输出。验证后,我们进一步提示模型将这些详细的描述精炼为更简洁的指代表达式,从而增强指代任务的训练效果。
Rexverse-2M 数据集:
-
210 万张带有描述的图像;
-
1020 万个标注了类别标签的区域;
-
250 万个标注了简短短语的区域;
-
250 万个带有详细描述的区域;
-
240 万个带有指代表达式的区域。
此外,我们还使用这个数据引擎为 ALLaVA-4V-Instruct 数据集中的 776K 条基础对话数据进行了标注,用于指令调优。具体来说,我们将对话响应视为图像描述,然后通过该引擎进行处理。
4.2 训练策略
4.2.1 UPN 训练
我们使用两类带有边界框的数据集来训练我们的通用提议网络(UPN):
- 粗粒度数据集,包括 O365 、OpenImages、Bamboo、COCO、LVIS 、HierText 、CrowdHuman、SROIE 和 EgoObjects ;
- 细粒度数据集 SA-1B 。
所有数据集的类别被定义为粗粒度或细粒度,将任务简化为一个二分类问题。遵循 T-Rex2 的方法,我们使用匈牙利匹配来匹配预测和真实标签。我们采用 L1 损失和 GIOU 损失来进行边界框预测,并使用 sigmoid 焦点损失进行分类。
4.2.2 ChatRex 训练任务
我们采用三个主要任务来训练 ChatRex,包括:
-
基础定位:模型根据给定的类别名称、短语或指代表达式输出对应物体的索引。
-
区域理解:给定区域索引,模型生成不同详细程度的描述,包括类别名称、简短短语、详细描述或指代表达式。
-
基础图像对话:模型需要输出在其生成的对话输出中提到的物体的索引。我们将当前图像的真实边界框与 UPN 提出的边界框混合,并最多保留 100 个边界框作为输入。
我们采用三阶段训练过程,每个阶段的数据如表 1 所示。

-
第一阶段:对齐训练。在第一阶段,目标是将视觉特征和目标特征与文本特征空间对齐。为此,我们训练图像投影 MLP、目标投影 MLP,以及 LLM 的输入和输出嵌入,因为我们已经为其词汇表添加了特殊标记。
-
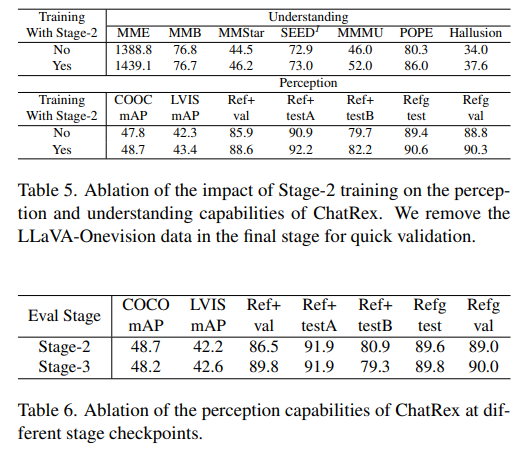
第二阶段:感知训练。在这一阶段,我们通过在 Rexverse-2M 和其他基础数据上训练 ChatRex 来提升其感知能力。在这个阶段,所有参数都是可训练的。
-
第三阶段:联合训练。在这一阶段,我们将感知和理解任务整合到一个统一的训练过程中,确保 ChatRex 获得这两种能力。这种联合优化使模型具备全面的多模态能力,并实现感知与理解之间的相互增强。
五、Experiments