C++学习之ORACLE③
1.集合运算符
查询部门号是10和20的员工信息: ?思考有几种方式解决该问题 ?
- SQL> select * from emp where deptno in(10, 20)
- SQL> select * from emp where deptno=10 or deptno=20
- 集合运算:
Select * from emp where deptno=10 加上
Select * from emp where deptno=20
集合运算所操作的对象是两个或者多个集合,而不再是表中的列(select一直在操作表中的列)
2.集合运算应用
- 参与运算的各个集合必须列数相同,且类型一致。
- 采用第一个集合的表头作为最终使用的表头。 (列名别名也只能在第一个集合上起)
- 可以使用括号()先执行后面的语句。
3.insert语句基本用法
使用 INSERT 语句向表中插入数据。其语法为:
INSERT INTO table [(column [, column...])]
VALUES (value [, value...]);
如果:values后面的值,涵盖了表中的所有列,那么table的列名可以省略不写。
SQL> desc emp; 查看员工表的结构,得到所有的列名。
SQL> insert into emp values (1001, 'Tom', 'Engineer', 7839, sysdate, 5000, 200, 10 )
SQL> insert into emp values (1005, 'Bone', 'Raphealy', 7829, to_date('17-12月-82', 'DD-MON-RR'), NULL, 300, 20);
如果:插入的时候没有插入所有的列,就必须显式的写出这些列的名字。
SQL> insert into emp(empno, ename, sal, deptno) values(1002, 'Marry', 6000, 20);
注意:字符串和日期都应该使用 ' ' 号引用起来。
没有写出的列自动填NULL, 这种方式称之为“隐式插入空值”。
“显式插入空值”: SQL> insert into emp(empno, ename, sal) values(1003, 'Jim', null);
SQL> insert into dept values(1, '1name', '1loc');
SQL> insert into dept(deptno, dname, loc) values(2, '2name', '2loc');
SQL> insert into dept(deptno, loc, dname) values(3, '3loc', '3name');
SQL> insert into dept(deptno, dname) values(4, '4name');
4.地址符
使用 INSERT 语句向表中插入数据。其语法为:
INSERT INTO table [(column [, column...])]
VALUES (value [, value...]);
如果:values后面的值,涵盖了表中的所有列,那么table的列名可以省略不写。
SQL> desc emp; 查看员工表的结构,得到所有的列名。
SQL> insert into emp values (1001, 'Tom', 'Engineer', 7839, sysdate, 5000, 200, 10 )
SQL> insert into emp values (1005, 'Bone', 'Raphealy', 7829, to_date('17-12月-82', 'DD-MON-RR'), NULL, 300, 20);
如果:插入的时候没有插入所有的列,就必须显式的写出这些列的名字。
SQL> insert into emp(empno, ename, sal, deptno) values(1002, 'Marry', 6000, 20);
注意:字符串和日期都应该使用 ' ' 号引用起来。
没有写出的列自动填NULL, 这种方式称之为“隐式插入空值”。
“显式插入空值”: SQL> insert into emp(empno, ename, sal) values(1003, 'Jim', null);
SQL> insert into dept values(1, '1name', '1loc');
SQL> insert into dept(deptno, dname, loc) values(2, '2name', '2loc');
SQL> insert into dept(deptno, loc, dname) values(3, '3loc', '3name');
SQL> insert into dept(deptno, dname) values(4, '4name');
5.批量处理
一次插入多条数据。
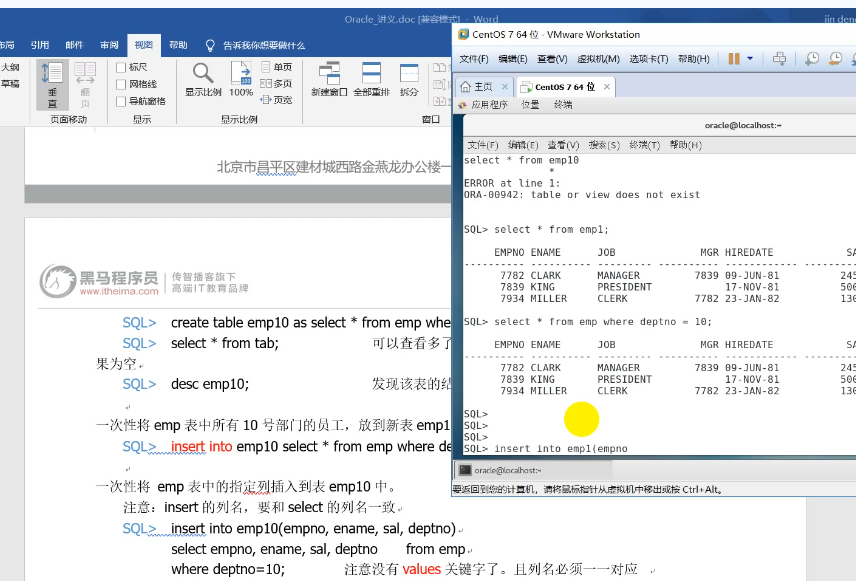
SQL> create table emp10 as select * from emp where 1=2; 创建一张表,用于测试。
SQL> select * from tab; 可以查看多了一张新表emp10,但select * from emp10 结果为空
SQL> desc emp10; 发现该表的结构和emp表的结构完全相同。
一次性将emp表中所有10号部门的员工,放到新表emp10中来。
SQL> insert into emp10 select * from emp where deptno=10 ;
一次性将 emp表中的指定列插入到表emp10中。
注意:insert的列名,要和select的列名一致
SQL> insert into emp10(empno, ename, sal, deptno)
select empno, ename, sal, deptno from emp
where deptno=10; 注意没有values关键字了。且列名必须一一对应
总结: 子查询可以出现在DML的任何语句中,不只是查询套查询。
6.更新数据和删除数据操作
对于更新操作来说,一般会有一个“where”条件,如果没有这限制条件,更新的就是整张表。
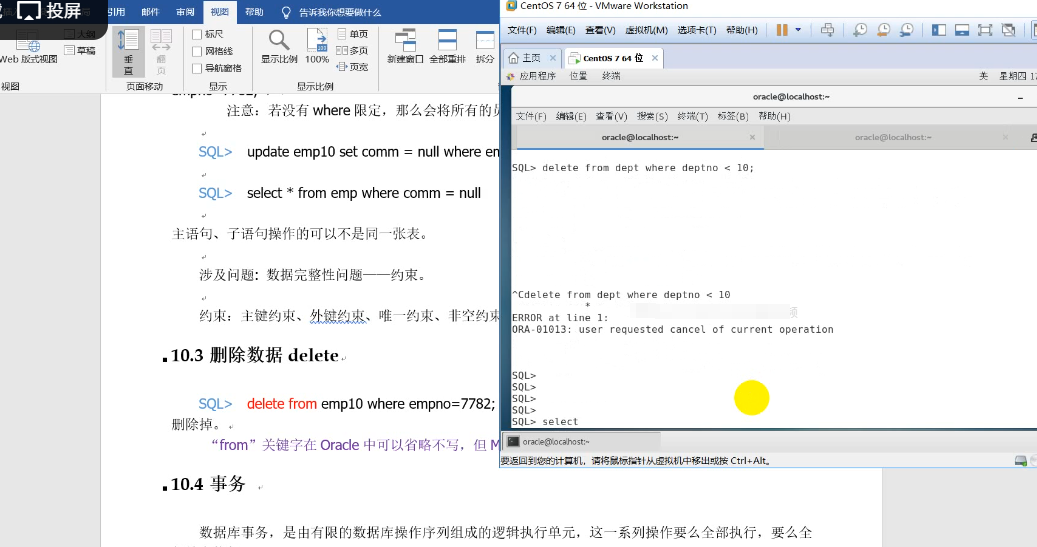
SQL> update emp10 set sal=4000, comm=300 where ename = 'CLARK'; ( 或 where empno=7782; )
注意:若没有where限定,那么会将所有的员工的sal都设置成4000,comm设置成300;
SQL> update emp10 set comm = null where empno=1000; 这个操作是否能成功呢?
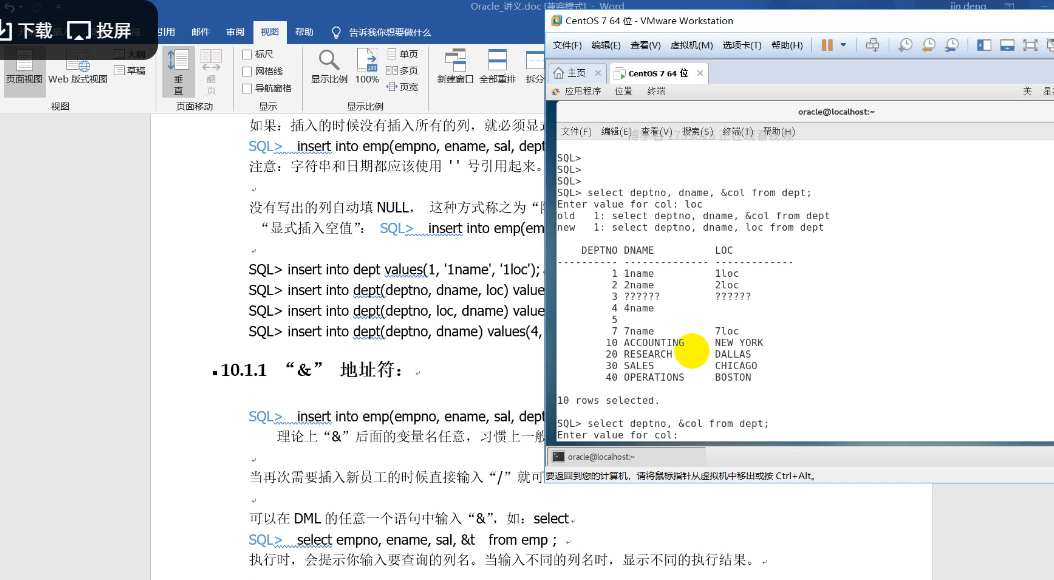
SQL> select * from emp where comm = null 这个查询可以成功吗?
主语句、子语句操作的可以不是同一张表。
涉及问题: 数据完整性问题——约束。 (插入、更新、删除都可能造成表数据的变化)
约束:主键约束、外键约束、唯一约束、非空约束。 (简单了解。后面约束章节讲解)
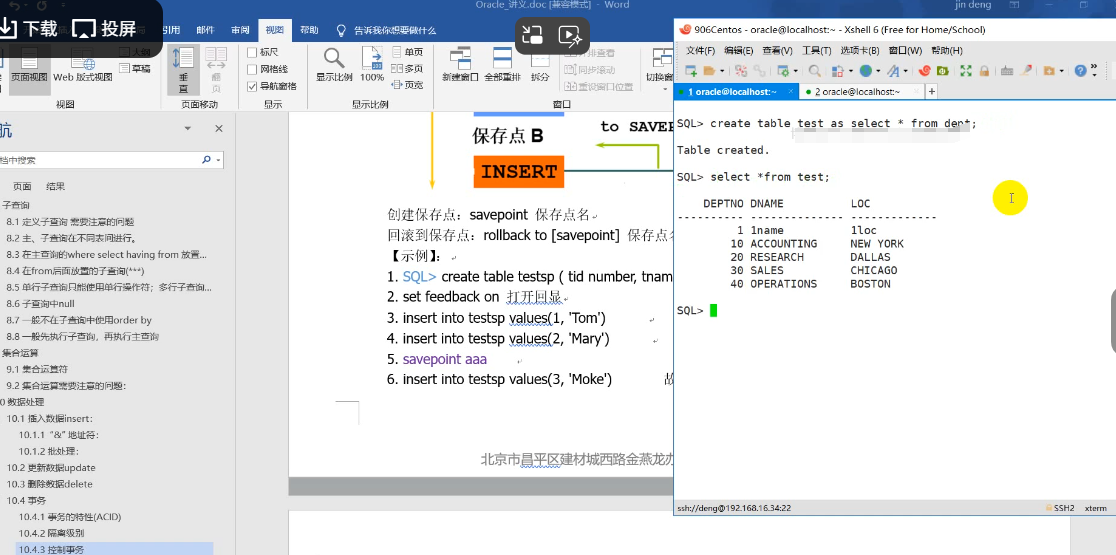
7.事务
数据库事务,是由有限的数据库操作序列组成的逻辑执行单元,这一系列操作要么全部执行,要么全部放弃执行。
数据库事务由以下的部分组成:
- 一个或多个DML语句
- 一个 DDL(Data Definition Language – 数据定义语言) 语句
- 一个 DCL(Data Control Language – 数据控制语言) 语句
事务的特点:要么都成功,要么都不执行。
8.课程小结
事务4大特性
- 原子性 (Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
- 一致性 (Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
- 隔离性 (Isolation):事务的执行不受其他事务的干扰,当数据库被多个客户端并发访问时,隔离它们的操作,防止出现:脏读、幻读、不可重复读。
- 持久性 (Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。

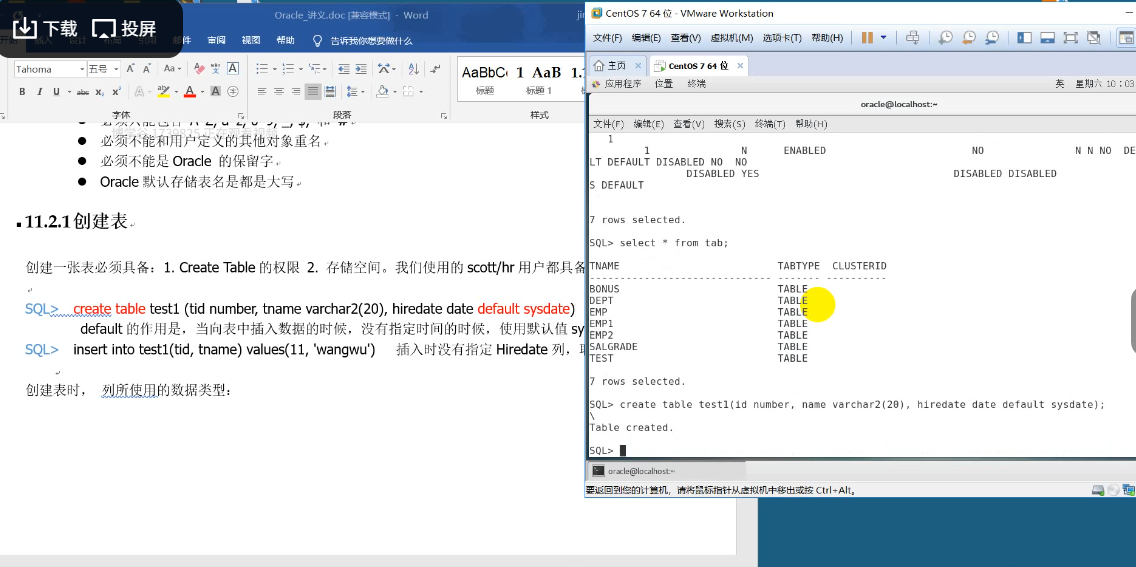
9.表的创建
数据库的对象:表、视图、索引、序列、同义词
:存储过程、存储函数、触发器、包、包体、数据库链路(datalink)、快照。(12个)
表 基本的数据存储集合,由行和列组成。
视图 从表中抽出的逻辑上相关的数据集合。
序列 提供有规律的数值。
索引 提高查询的效率
同义词 给对象起别名
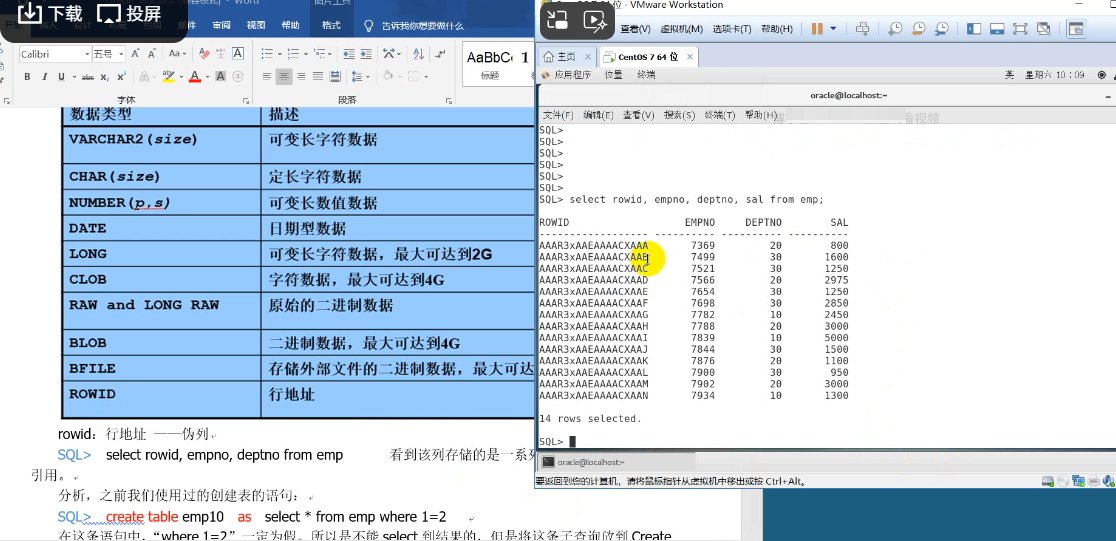
10.修改表列
基本的数据存储集合,由行和列组成。
表名和列名遵循如下命名规则:
- 必须以字母开头
- 必须在 1–30 个字符之间
- 必须只能包含 A–Z, a–z, 0–9, _, $, 和 #
- 必须不能和用户定义的其他对象重名
- 必须不能是Oracle 的保留字
- Oracle默认存储表名是都是大写
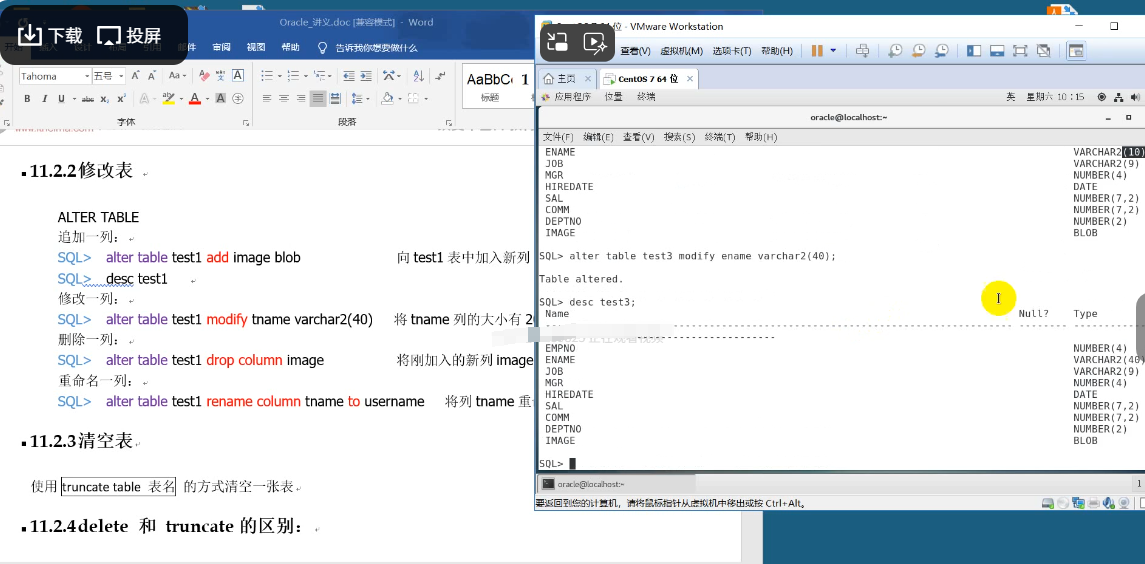
11.清空表
delete from 表名 (没有where 条件) 也可以清空一张表
- delete 逐条删除表“内容”,truncate 先摧毁表再重建。
(由于delete使用频繁,Oracle对delete优化后delete快于truncate)
- delete 是DML语句,truncate 是DDL语句。DML语句可以闪回(flashback)和回滚rollback,DDL语句不可以闪回和回滚。
(闪回: 做错了一个操作并且commit了,对应的撤销行为。了解)
- 由于delete是逐条操作数据,所以delete会产生碎片,truncate不会产生碎片。
(同样是由于Oracle对delete进行了优化,让delete不产生碎片)。两个数据之间的数据被删除,删除的数据——碎片,整理碎片,数据连续,行移动。
- delete不会释放空间,truncate 会释放空间。用delete删除一张10M的表,空间不会释放。而truncate会。所以当确定表不再使用,应使用truncate。
12.删除表和重命名表
当表被删除:
- 数据和结构都被删除
- 所有正在运行的相关事务被提交
- 所有相关索引被删除
- DROP TABLE 语句不能回滚,但是可以闪回
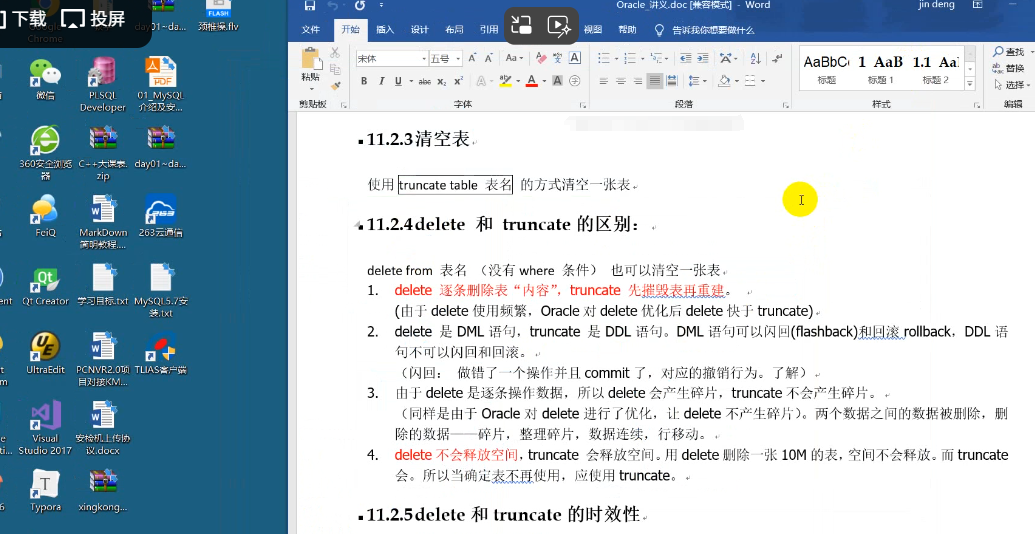
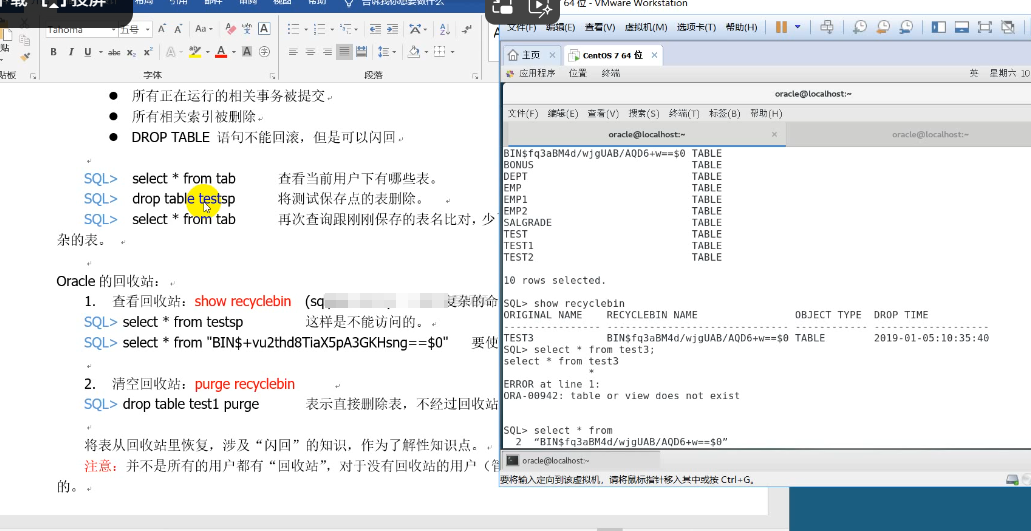
SQL> select * from tab 查看当前用户下有哪些表。 拷贝保存表名。
SQL> drop table testsp 将测试保存点的表删除。
SQL> select * from tab 再次查询跟刚刚保存的表名比对,少了testsp,但多了另外一张命名复杂的表。
Oracle的回收站:
1. 查看回收站:show recyclebin (sqlplus 命令) 那个复杂的命名即是testsp在回收站中的名字。
SQL> select * from testsp 这样是不能访问的。
SQL> select * from "BIN$+vu2thd8TiaX5pA3GKHsng==$0" 要使用“回收站中的名字”
2. 清空回收站:purge recyclebin
SQL> drop table test1 purge 表示直接删除表,不经过回收站。
将表从回收站里恢复,涉及“闪回”的知识,作为了解性知识点。
注意:并不是所有的用户都有“回收站”,对于没有回收站的用户(管理员)来说,删除操作是不可逆的。
13.约束概念和分类
Not Null 非空约束
例如:人的名字,不允许为空。
2. Unique 唯一性约束
例如:电子邮件地址,不可以重复。
3. Check 检查性约束
如:人的性别,只能填男或者女;工作后薪水满足的条件应该大于0。
4. Primary Key 主键约束
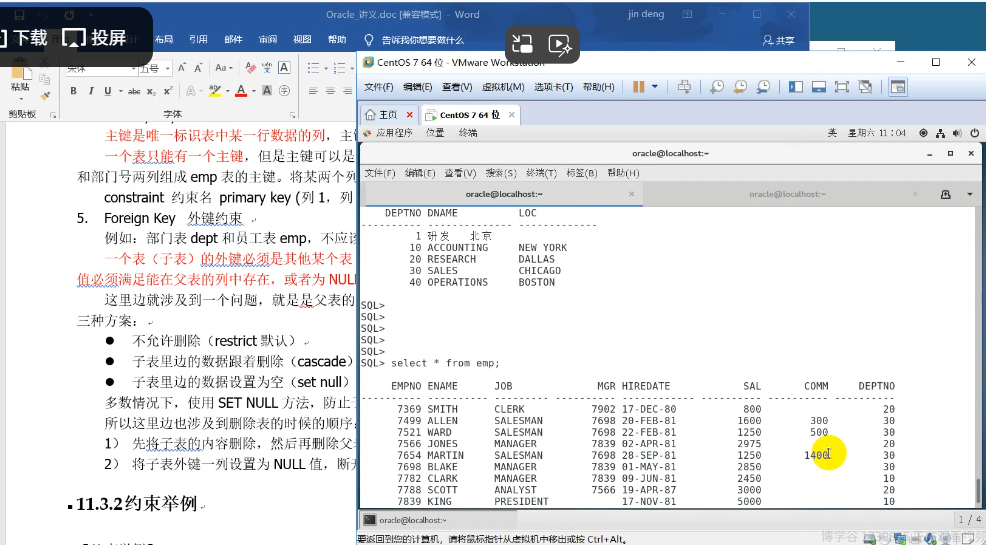
主键是唯一标识表中某一行数据的列,主键约束隐含Not null + Unique。
一个表只能有一个主键,但是主键可以是某一列,也可以是多列组成表的主键,比如说可以用员工名和部门号两列组成emp表的主键。将某两个列作为主键必须用表级约束
constraint 约束名 primary key (列1,列2)
5. Foreign Key 外键约束
例如:部门表dept和员工表emp,不应该存在不属于任何一个部门的员工。用来约束两张表的关系。
一个表(子表)的外键必须是其他某个表(父表)的具有唯一约束的列(一般都用主键),子表外键的值必须满足能在父表的列中存在,或者为NULL。
这里边就涉及到一个问题,就是是父表的键值被删除,这时候子表里边的外键值应该怎么办?有以下三种方案:
- 不允许删除(restrict默认)
- 子表里边的数据跟着删除(cascade)
- 子表里边的数据设置为空(set null)
多数情况下,使用SET NULL方法,防止子表列被删除,数据出错。
所以这里边也涉及到删除表的时候的顺序:
1) 先将子表的内容删除,然后再删除父表。
2) 将子表外键一列设置为NULL值,断开引用关系,然后删除父表。
14.约束举例说明
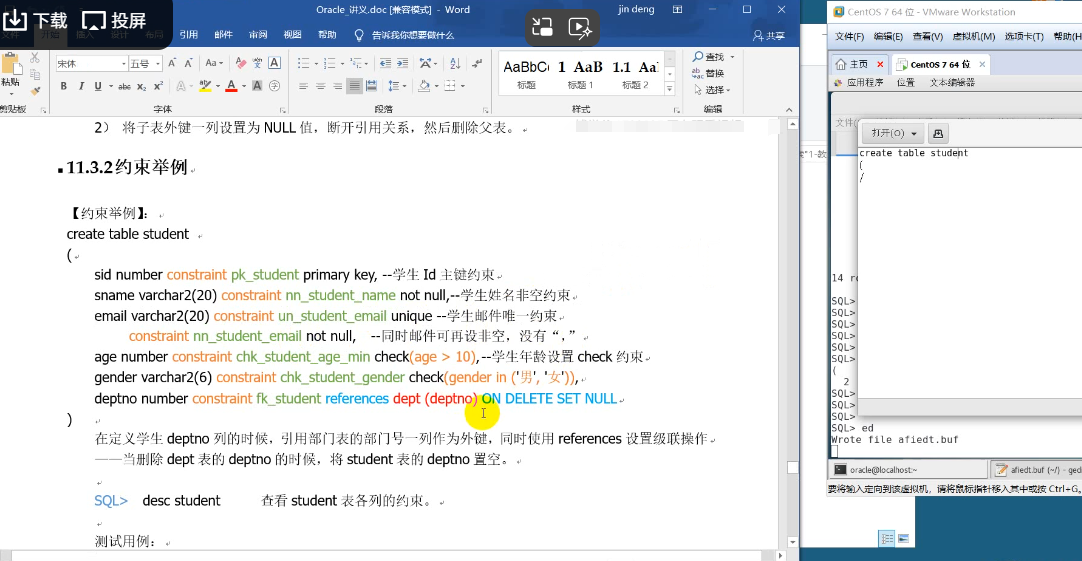
【约束举例】:
create table student
(
sid number constraint pk_student primary key, --学生Id主键约束
sname varchar2(20) constraint nn_student_name not null,--学生姓名非空约束
email varchar2(20) constraint un_student_email unique --学生邮件唯一约束
constraint nn_student_email not null, --同时邮件可再设非空,没有“,”
age number constraint chk_student_age_min check(age > 10), --学生年龄设置check约束
gender varchar2(6) constraint chk_student_gender check(gender in ('男', '女')),
deptno number constraint fk_student references dept (deptno) ON DELETE SET NULL
)
在定义学生deptno列的时候,引用部门表的部门号一列作为外键,同时使用references设置级联操作
——当删除dept表的deptno的时候,将student表的deptno置空。
SQL> desc student 查看student表各列的约束。

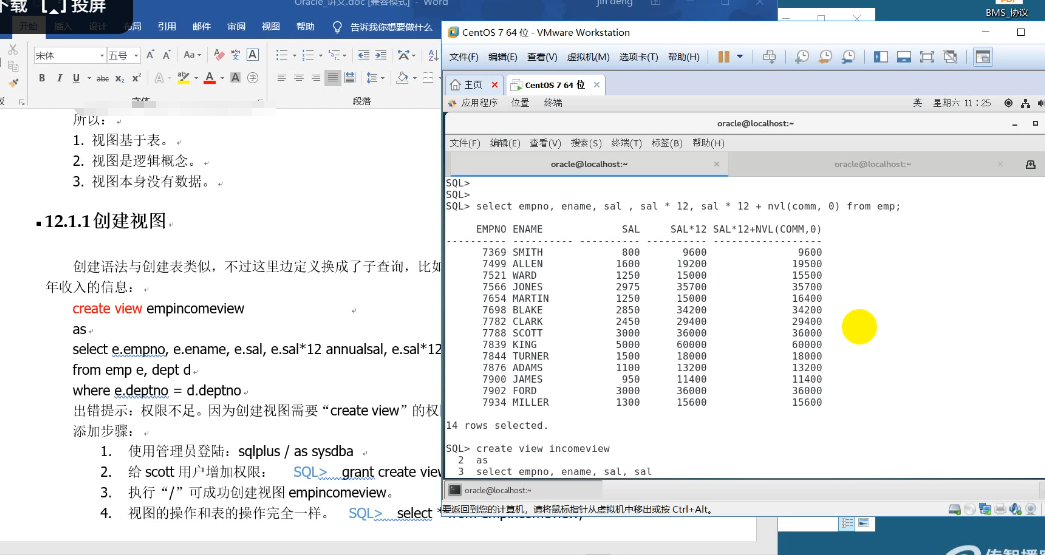
15.视图
常见数据库对象——视图:从表中抽出的逻辑上相关的数据集合。
通俗来说,可以把视图看成是虚拟的表,只是一个查询语句的结果。
所以:
1. 视图基于表。
2. 视图是逻辑概念。
3. 视图本身没有数据。
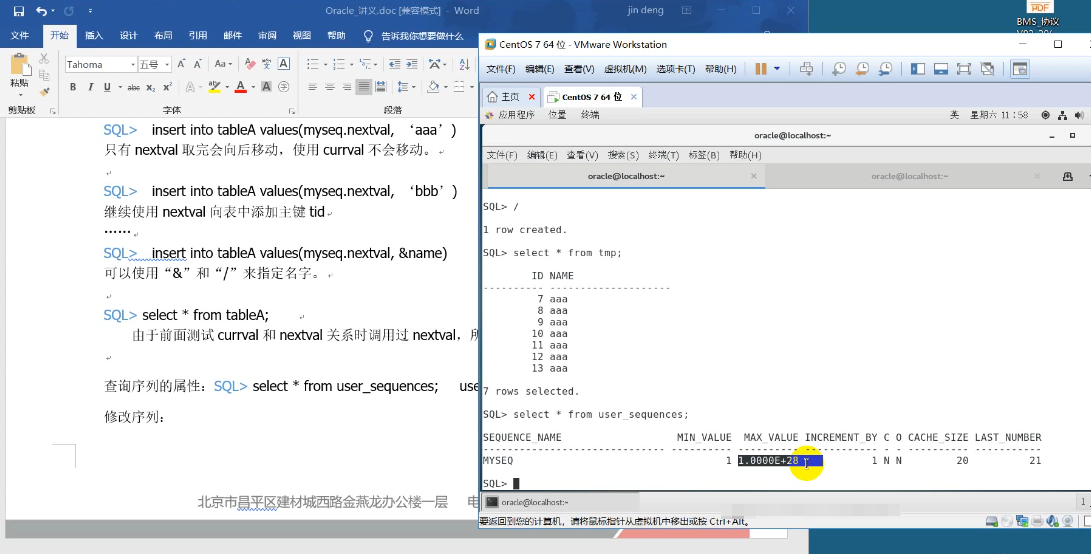
16.序列
可以理解成数组:默认,从[1]开始,缓存长度[20] [1, 2, 3, 4, 5, 6, …, 20] 在内存中。
*
由于序列是被保存在内存中,访问内存的速率要高于访问硬盘的速率。所以序列可以提高效率。
-
-
- 序列的使用:
-
1. 初始状态下:指针*指向1前面的位置。欲取出第一个值,应该将*向后移动。每取出一个值指针都向后移。
2. 常常用序列来指定表中的主键。
3. 创建序列:create sequence myseq 来创建一个序列。
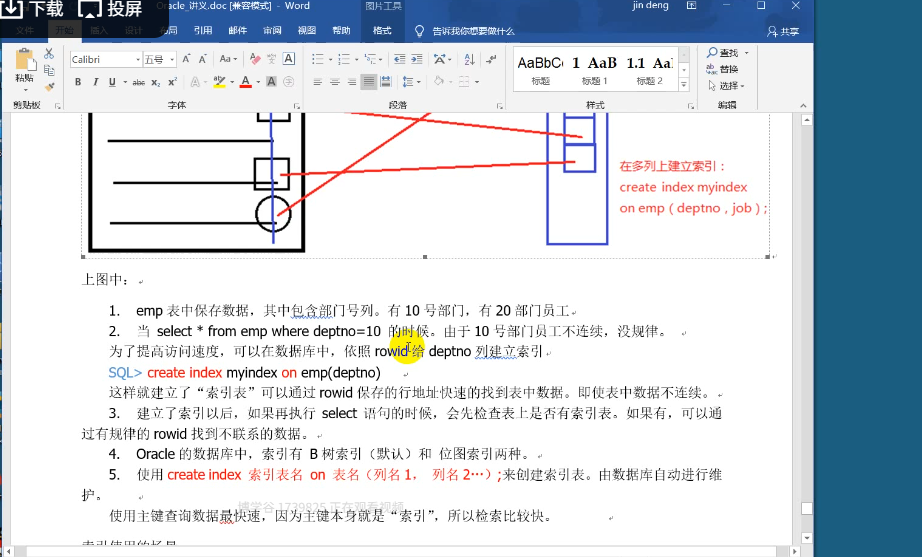
17.索引
索引,相当于书的目录,提高数据检索速度。提高效率(视图不可以提高效率)
- 一种独立于表的模式对象, 可以存储在与表不同的磁盘或表空间中
- 索引被删除或损坏, 不会对表产生影响, 其影响的只是查询的速度
- 索引一旦建立, Oracle 管理系统会对其进行自动维护, 而且由 Oracle 管理系统决定何时使用索引. 用户不用在查询语句中指定使用哪个索引
- 在删除一个表时, 所有基于该表的索引会自动被删除
- 通过指针加速 Oracle 服务器的查询速度
- 通过快速定位数据的方法,减少磁盘 I/O
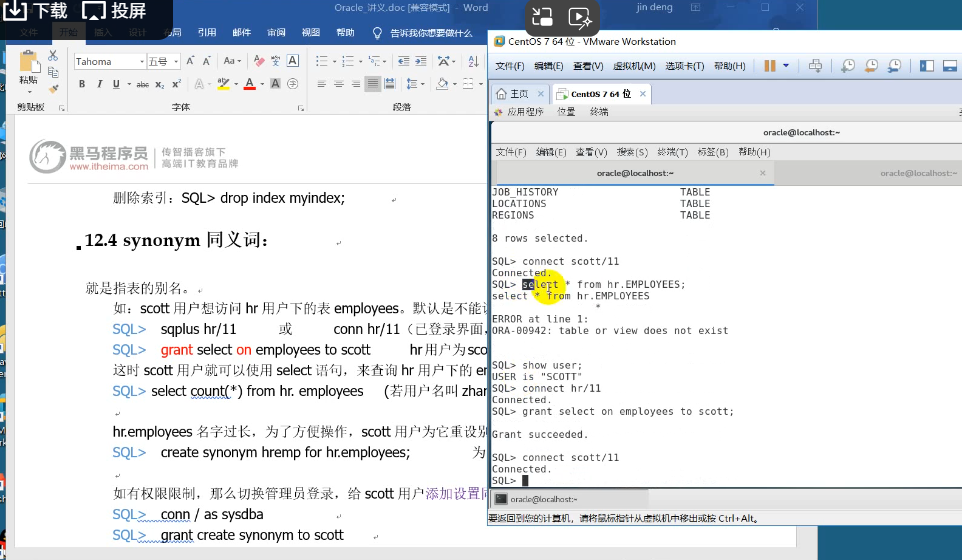
18.同义词
就是指表的别名。
如:scott用户想访问hr用户下的表employees。默认是不能访问的。需要hr用户为scott用户授权:
SQL> sqplus hr/11 或 conn hr/11(已登录界面, 切换登陆)
SQL> grant select on employees to scott hr用户为scott用户开放了employees表的查询权限。
这时scott用户就可以使用select语句,来查询hr用户下的employees表的信息了。
SQL> select count(*) from hr. employees (若用户名叫zhangsanfeng则zhangsanfeng.employees)
hr.employees名字过长,为了方便操作,scott用户为它重设别名:
SQL> create synonym hremp for hr.employees; 为hr.employees创建了同义词。
如有权限限制,那么切换管理员登录,给scott用户添加设置同义词权限。
SQL> conn / as sysdba
SQL> grant create synonym to scott
SQL> select count(*) from hremp 使用同义词进行表查询操作。
——同义词、视图 等用法在数据保密要求较高的机构使用广泛,如银行机构。好处是既不影响对数据的操作,同时又能保证数据的安全。
19.SQL和sqlplus区分
我们这里边我们要注意的是,我们之前运行的SQL命令都在sqlplus上执行,但是其实sqlplus除了运行SQL命令外,还支持运行sqlplus自身的命令,这些命令是客户端命令,服务端是不会拿到并运行的。
SQL → 语言,关键字不能缩写,在sqlplus中都得带分号执行。这里边就包括我们之前学的DML、DDL、DCL语句。
sqlplus → Oracle提供的工具,可在里面执行SQL语句,它配有自己的命令(ed、c、set、col) 特点是缩写关键字。
SQL
-
- 一种语言
- ANSI 标准
- 关键字不能缩写
- 使用语句控制数据库中的表的定义信息和表中的数据
SQL*Plus
-
- 一种环境
- Oracle 的特性之一
- 关键字可以缩写
- 命令不能改变数据库中的数据的值
- 集中运行
这里我们只要能够区分哪些是SQL,哪些sqlplus命令就行,最简单的方法就是在sqlplus中使用help index命令,就可以列出sqlplus的命令:
20.上午课程