面试题之网络相关
最近开始面试了,410面试了一家公司 问了我几个网络相关的问题,我都不会!!现在来恶补一下,整理到博客中,好难记啊,虽然整理下来了。在这里先祝愿大家在现有公司好好沉淀,定位好自己的目标,在自己的领域上发光发热,在自己想要的领域上(技术管理、项目管理、业务管理等)越走越远!希望各位面试都能稳过,待遇都是杠杠的!
1.HTTP和HTTPS的区别是什么?HTTP 1.0、1.1和2.0的主要区别是什么?
1) HTTP和HTTPS的区别
| HTTP | HTTPS | |
|---|---|---|
| 默认端口 | 80 | 443 |
| 传输方式 | 明文传输,不安全 | 加密传输,安全 |
| 加密方式 | 无加密 | 使用ssl/tls加密,需要ca证书 |
| 传输速度 | 快 | 相对慢 |
2) HTTP 1.0、1.1和2.0的主要区别是什么?
| HTTP 1.0 | HTTP 1.1 | HTTP 2.0 | |
|---|---|---|---|
| 连接方式 | 每个请求需要建立新的TCP连接 | 持久连接(默认keep-alive) | 二进制分帧 |
| 传输技术 | 串型请求 | 管道化技术 | 多路复用 |
| 头部信息 | 无host头字段 | 新增host头字段 | 头部压缩 |
| 断点续传 | 不支持断点续传 | 支持断点续传 | 服务器推送 |
2. https的双向认证原理
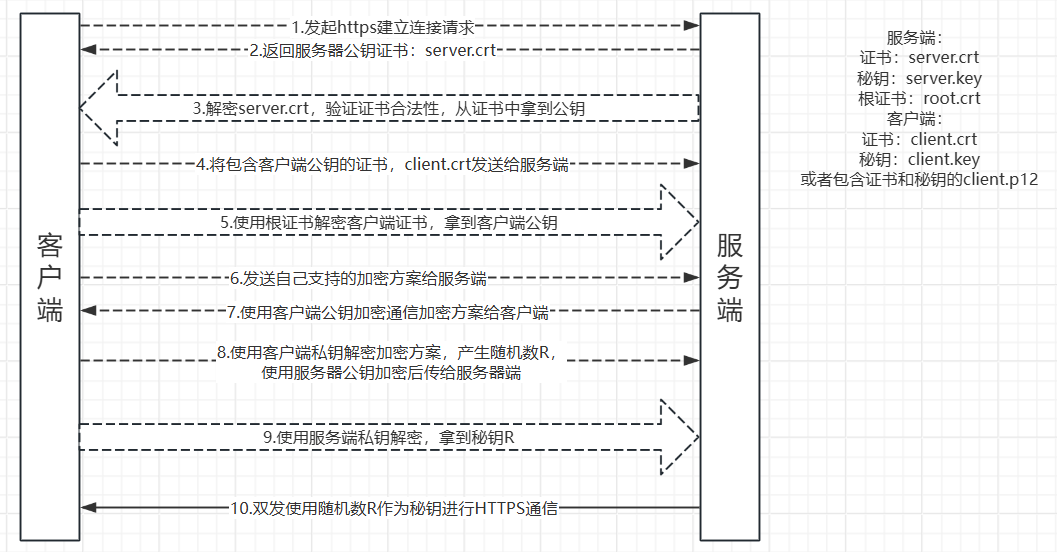
双向认证流程
1.客户端发起建立HTTPS连接请求,将SSL协议版本的信息发送给服务端;
2.服务端将本机的公钥证书(server.crt)发送给客户端;
3.客户端读取公钥证书(server.crt),取出了服务端公钥;
4.客户端将客户端公钥证书(client.crt)发送给服务端;
5.服务端使用根证书(root.crt)解密客户端公钥证书,拿到客户端公钥;
6.客户端发送自己支持的加密方案给服务端;
7.服务端根据自己和客户端的能力,选择一个双方都能接受的加密方案;
8.服务端使用客户端的公钥加密 后发送给客户端;
9.客户端使用自己的私钥解密加密方案,生成一个随机数R,使用服务器公钥加密后传给服务端;
10.服务端用自己的私钥去解密这个密文,得到了密钥R;
11.服务端和客户端在后续通讯过程中就使用这个密钥R进行通信了。
双向认证的目的主要是使得双方最终可以安全的得到秘钥R,后面所有传输都是通过秘钥R加密HTTPS双向认证,不仅仅需要用户浏览器校验服务器数字证书,还需要服务器端验证用户是否是可信的。
引用博客:https双向认证-CSDN博客
https证书的作用
- 保护网站安全:https证书通过加密传输保护网站和浏览器的通信,确保数据不会被网络不法分子干扰,保护客户信息和用户私人数据。
- 消除“不安全”标记:部署https证书可以消除浏览器对http站点的“不安全”标记,提升用户体验和网站信誉
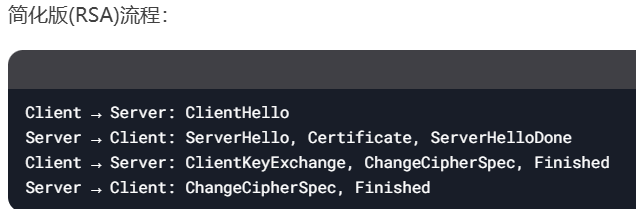
3.HTTPS的SSL/TLS握手过程是怎样的?
完整握手过程:
-
Client Hello:
客户端发送支持的TLS版本、加密套件列表、随机数 -
Server Hello:
服务器选择TLS版本、加密套件,发送随机数和服务器证书 -
证书验证:
客户端验证服务器证书(CA链、有效期等) -
密钥交换:
客户端生成预主密钥,用服务器公钥加密发送;双方通过随机数和预主密钥生成会话密钥 -
Finished:
双方发送加密的Finished消息验证握手成功
3.HTTP/2的多路复用是如何实现的?
HTTP/2多路复用实现原理:
-
二进制分帧层:
-
将HTTP消息分解为独立的帧(HEADERS/DATA等)
-
帧可以乱序发送,通过流ID重新组装
-
-
流(Stream)概念:
-
每个请求/响应对应一个流,有唯一ID
-
流可以并行交错传输
-
流具有优先级权重
-
-
帧特性:
-
长度字段:9字节帧头
-
类型字段:10种帧类型
-
标志字段:如END_HEADERS, END_STREAM等
-
流ID:31位无符号整数
-
优势:
-
解决HTTP/1.x队头阻塞问题
-
单连接并行处理多个请求
-
减少TCP连接数
4.什么是WebSocket?它与HTTP有什么关系?
-
WebSocket:
-
全双工通信协议
-
建立在TCP之上
-
客户端和服务器可以主动发送消息
-
适用于实时应用(聊天、游戏等)
-
关系:
-
WebSocket握手阶段使用HTTP协议
-
建立连接后升级为WebSocket协议
-
使用ws://或wss://协议头
6.什么是RESTful API?它的特点是什么?
RESTful API是基于REST(Representational State Transfer)架构风格的API设计。
特点:
-
使用HTTP方法表示操作类型(GET/POST/PUT/DELETE等)
-
无状态
-
资源导向,URI表示资源
-
通常使用JSON/XML作为数据格式
-
可缓存
-
分层系统
7-13 TCP UDP详细的解说可以查看博客:网络问题之TCP/UDP协议-CSDN博客
7.简述 tcp 和 udp的区别?
tcp 和 udp 是 OSI 模型中的运输层中的协议。tcp 提供可靠的通信传输,而 udp 则常被用于让广播和细节控制交给应用的通信传输;其中OSI模型的全称是开放系统互连参考模型(Open Systems Interconnection Reference Model),是由国际标准化组织(ISO)提出的网络通信概念框架
两者的区别大致如下:
- tcp 面向连接,udp 面向非连接即发送数据前不需要建立链接;
- tcp 提供可靠的(数据传输)服务,udp 无法保证;
- tcp 面向字节流,udp 面向报文;
- tcp 数据传输慢,udp 数据传输快;
- tcp保证数据顺序,udp不保证
- tcp适用于可靠性传输的场景,如文件传输、网页浏览;udp适用于实时性要求高的场景,如视频会议、在线游戏
8. 说一下 tcp 粘包是怎么产生的?
tcp 粘包可能发生在发送端或者接收端,分别来看两端各种产生粘包的原因:
- 发送端粘包:发送端需要等缓冲区满才发送出去,造成粘包;
- 接收方粘包:接收方不及时接收缓冲区的包,造成多个包接收。
9.tcp粘包/拆包的解决办法
TCP粘包/拆包的解决方法主要包括协议设计优化和框架级解码器支持,核心思路是为数据包定义明确的边界规则。
主要解决方案
-
固定长度法
发送方将每个数据包封装为固定长度(如200字节),不足部分填充特定字符(如空格或0)。接收方按固定长度读取数据,避免粘包/拆包。
示例:设定每个数据包长度为100字节,发送端填充不足部分,接收端每次读取100字节。 -
特殊分隔符法
在数据包末尾添加特定分隔符(如\r),接收方根据分隔符拆分数据。例如FTP协议使用换行符作为边界。
适用场景:文本协议或需要人工可读的数据格式。 -
消息头定义长度法
在数据包头部添加长度字段(如4字节的int值),接收方先读取长度信息,再按该长度读取完整数据包。
优势:灵活适配变长数据,广泛应用于自定义协议设计。 -
应用层协议封装
设计更复杂的协议规范,例如将消息分为消息头和消息体,头部包含校验、版本等信息,消息体按业务逻辑扩展。
典型应用:Netty等框架通过:ml-search[LengthFieldBasedFrameDecoder]支持此类协议。 -
框架级解码器支持
使用网络框架(如Netty)内置的解码器自动处理粘包/拆包:FixedLengthFrameDecoder:固定长度解码; LineBasedFrameDecoder:基于换行符分割;DelimiterBasedFrameDecoder:自定义分隔符;LengthFieldBasedFrameDecoder:头部含长度的通用方案。
优势:减少手动处理复杂度,提升开发效率。
其他补充
- HTTP协议的解决方案:通过
Content-Length明确数据长度,或使用chunked编码分块传输,天然规避粘包问题。 - UDP无粘包问题:因其面向数据报文且自带消息边界保护。
建议结合具体场景选择方案:简单文本通信可用分隔符法,高性能场景推荐消息头长度法或Netty框架集成。
10.什么是TCP的三次握手和四次挥手?
三次握手(建立连接):
-
客户端发送SYN=1, seq=x
-
服务器回复SYN=1, ACK=1, seq=y, ack=x+1
-
客户端发送ACK=1, seq=x+1, ack=y+1
四次挥手(断开连接):
-
客户端发送FIN=1, seq=u
-
服务器回复ACK=1, ack=u+1
-
服务器发送FIN=1, seq=v
-
客户端回复ACK=1, ack=v+1
11. tcp 为什么要三次握手,两次不行吗?为什么?
如果采用两次握手,那么只要服务器发出确认数据包就会建立连接,但由于客户端此时并未响应服务器端的请求,那此时服务器端就会一直在等待客户端,这样服务器端就白白浪费了一定的资源。若采用三次握手,服务器端没有收到来自客户端的再此确认,则就会知道客户端并没有要求建立请求,就不会浪费服务器的资源。
12. TCP的拥塞控制机制是如何工作的?
TCP拥塞控制包含四个核心算法:
-
慢启动(Slow Start):
-
初始拥塞窗口(cwnd)为1 MSS
-
每收到一个ACK,cwnd指数增长(1,2,4,8...)
-
当cwnd达到慢启动阈值(ssthresh)时进入拥塞避免阶段
-
-
拥塞避免(Congestion Avoidance):
-
cwnd线性增长(每RTT增加1 MSS)
-
当检测到丢包时,调整ssthresh为当前cwnd的一半
-
-
快速重传(Fast Retransmit):
-
收到3个重复ACK时立即重传丢失的报文段
-
不等待超时重传计时器
-
-
快速恢复(Fast Recovery):
-
重传丢失的报文段后,cwnd = ssthresh + 3 MSS
-
每收到一个重复ACK,cwnd增加1 MSS
-
当收到新数据的ACK时,退出快速恢复
-
13. OSI 的七层模型都有哪些?TCP/IP四层模型?
OSI的七层模型:
- 物理层:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
- 数据链路层:负责建立和管理节点间的链路。
- 网络层:通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。
- 传输层:向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输。
- 会话层:向两个实体的表示层提供建立和使用连接的方法。
- 表示层:处理用户信息的表示问题,如编码、数据格式转换和加密解密等。
- 应用层:直接向用户提供服务,完成用户希望在网络上完成的各种工作。
| 层级 | 名称 | 英文 | 功能概要 | 典型协议/设备 |
|---|---|---|---|---|
| 7 | 应用层 | Application Layer | 为用户应用程序提供网络服务接口 | HTTP, FTP, SMTP |
| 6 | 表示层 | Presentation Layer | 数据格式转换、加密解密 | SSL, TLS, JPEG |
| 5 | 会话层 | Session Layer | 建立、管理和终止会话 | NetBIOS, RPC |
| 4 | 传输层 | Transport Layer | 提供端到端的可靠数据传输 | TCP, UDP |
| 3 | 网络层 | Network Layer | 路由选择、IP寻址和分组转发 | IP, ICMP, 路由器 |
| 2 | 数据链路层 | Data Link Layer | 物理寻址、错误检测和帧传输 | Ethernet, PPP, 交换机 |
| 1 | 物理层 | Physical Layer | 传输原始比特流,定义电气和物理特性 | RS-232, 光纤, 网卡 |
TCP/IP四层模型:
-
网络接口层
-
网络层(internet层)
-
传输层(TCP/UDP)
-
应用层(HTTP/FTP等)

记忆口诀:"应表会传网数物"(从第7层到第1层)
理解OSI模型有助于网络问题排查(如:ping通但无法上网→应用层问题)和协议设计。虽然实际网络更多使用TCP/IP模型,但OSI的分层概念仍是网络工程师的重要基础.
14. get 和 post 请求有哪些区别?
- get 请求会被浏览器主动缓存,而 post 不会。
- get 传递参数有大小限制,而 post 没有。
- post 参数传输更安全,get 的参数会明文显示在 url 上,post 不会。
15. 如何实现跨域?
实现跨域有以下几种方案:
- 服务器端运行跨域 设置 CORS 等于 *;
- 在单个接口使用注解 @CrossOrigin 运行跨域;
- 使用 jsonp 跨域;
16. 说一下 JSONP 实现原理?
jsonp:JSON with Padding,它是利用script标签的 src 连接可以访问不同源的特性,加载远程返回的“JS 函数”来执行的。
17.http 响应码 301 和 302 代表的是什么?有什么区别?
301:永久重定向。
302:暂时重定向。
它们的区别是,301 对搜索引擎优化(SEO)更加有利;302 有被提示为网络拦截的风险。
18. forward 和 redirect 的区别?
forward 是转发 和 redirect 是重定向:
- 地址栏 url 显示:foward url 不会发生改变,redirect url 会发生改变;
- 数据共享:forward 可以共享 request 里的数据,redirect 不能共享request里面的数据;
- 效率:forward 比 redirect 效率高
19. Java中Socket编程的基本步骤是什么?
服务器端:
-
创建ServerSocket对象,绑定端口
-
调用accept()方法监听客户端连接
-
获取输入输出流进行通信
-
关闭资源
客户端:
-
创建Socket对象,指定服务器地址和端口
-
获取输入输出流进行通信
-
关闭资源
20.Java BIO、NIO、AIO有什么区别?
| BIO(传统IO) | NIO(非阻塞IO) | AIO(异步IO) | |
|---|---|---|---|
| 全称 | Blocking I/O | New I/O/Non-blocking I/O | Asynchronous I/O |
| JDK版本 | JDK1.0 | JDK1.1 | JDK1.7 |
| 面向核心 | 面向流(steam) | 面向缓冲区(buffer) | 面向事件(Event) |
| 关键特征 | 同步阻塞IO,读写阻塞 | 同步非阻塞IO+多路复用,但需要轮询 | 异步非阻塞+回调机制,操作系统完成IO后会主动通知 |
| 处理能力 | 一个线程只能处理一个连接 | 单线程可以处理多个连接(selector) | 可多线程处理,但需要注意线程安全 |
| 适用场景 | 适合连接数少的场景 | 适合高并发、连接数多但连接时间短的场景 | 适用于连接数多且连接时间长的场景 |
| 主要组件 | / | 核心组件:Channel、Buffer、Selector | Channel(异步版本)、Buffer(异步使用) |
| 主要组件 | 作用 |
|---|---|
Selector | 多路复用器;通过 |
Channel | 类似于流,但可以双向读写,非阻塞 I/O 通道(如 SocketChannel、ServerSocketChannel)。 |
SelectionKey | 标识 Channel 和 Selector 的绑定关系,包含感兴趣的事件(OP_READ 等)。 |
| Buffer | 数据容器 |
21. BIO、NIO和AIO深度拷问?
Q:为什么Netty选择NIO而不是AIO?
A:"主要考虑三点:1) Linux平台AIO实现不完善,实际仍用epoll模拟;2) NIO模型更成熟稳定;3) Netty的NIO优化已能达到AIO的性能水平,AIO会有多线程的安全需要考虑"
Q:BIO线程池大小的合理设置?
A:"根据业务类型有两种策略:1) CPU密集型:核心数+1;2) IO密集型:通过公式[线程数=CPU核心数×(1+等待时间/计算时间)]计算。"
Q:NIO的空轮询Bug如何解决?
A:"1) 升级JDK7+已修复;2) 对于老版本可通过重建Selector或设置select超时规避。"
Q:如何避免AIO回调线程成为性能瓶颈?
A:"采用三种策略:1) 使用分层线程池,将I/O回调与业务处理分离;2) 对耗时操作采用非阻塞写法;3) 使用ManagedBlocker防止ForkJoinPool工作线程耗尽..."
Q:AIO是否适合CPU密集型场景?
A:"AIO的设计初衷是优化I/O密集型场景。对于CPU密集型任务需要特别注意:1) 回调线程池大小需调整;2) 考虑将计算任务offload到专用线程池。"
Q:AIO回调里的异常如何处理?
A:"完善的异常处理应包括:1) 在failed()中记录完整上下文;2) 资源清理;3) 连接重连机制。"
22.Java中有哪些常用的网络框架?
-
Netty:高性能异步事件驱动框架,适合开发高性能服务器和客户端
-
Apache HttpClient:HTTP客户端库,支持HTTP协议的各种功能
-
OkHttp:高效的HTTP客户端,支持HTTP/2和WebSocket
-
Spring WebClient:Spring提供的响应式HTTP客户端,非阻塞IO
-
Jersey:JAX-RS参考实现,用于构建RESTful服务
23.什么是零拷贝(Zero-copy)?零拷贝Java中如何实现?浅拷贝和深拷贝又是什么?
注意:零拷贝是系统I/O的优化技术,浅拷贝和深拷贝是java中对象复制的一种方式。
零拷贝:是一种避免CPU将数据从一块存储拷贝到另一块存储的技术,减少不必要的内存拷贝,提高系统性能。
-
数据直接从内核空间传输到目标,不经过用户空间
-
减少CPU拷贝次数和上下文切换
-
提高数据传输效率
浅拷贝:只复制对象本身和其中的基本数据类型,对于引用类型的属性,只复制引用地址而不复制引用的对象
深拷贝:不仅复制对象本身,还会递归复制对象的所有引用属性,生成一个完全独立的副本。
| 特性 | 零拷贝 | 浅拷贝 | 深拷贝 |
|---|---|---|---|
| 作用层面 | 系统I/O优化技术 | 对象复制方式 | 对象复制方式 |
| 拷贝内容 | 避免数据复制 | 对象+基本数据类型 | 对象+所有引用对象 |
| 主要目的 | 减少数据拷贝次数 | 快速创建对象副本 | 创建完全独立的对象副本 |
| 关注重点 | 内存与I/O性能优化 | 对象结构复制 | 对象引用关系的完全复制 |
| 典型应用 | 文件/网络传输 | 简单对象复制 | 需要完全独立的对象 |
| 实现层级 | 操作系统/虚拟机层 | 编程语言层面 | 编程语言层面 |
| 性能 | 最高 | 较高 | 较低 |
| 内存使用 | 最少 | 较少 | 较多 |
| 独立性 | 不适用 | 引用属性共享 | 完全独立 |
| 实现复杂度 | 系统级支持 | 简单 | 复杂 |
零拷贝的Java实现:
-
FileChannel.transferTo()/transferFrom()
-
MappedByteBuffer内存映射
-
Netty的CompositeByteBuf
Q:零拷贝技术为什么能提高性能?
A:主要通过三个方面:1) 减少CPU拷贝次数;2) 减少用户态和内核态切换;3) 避免缓冲区多次复制。在文件传输中,性能可提升50%以上。
Q:如何选择使用浅拷贝还是深拷贝?
A:考虑三个因素:1) 对象引用结构的复杂度;2) 对独立性的要求;3) 性能需求。如果引用对象不需要独立,用浅拷贝;如果需要完全隔离,用深拷贝。
Q:Java中如何实现完美的深拷贝?
A:最可靠的方式是序列化法,但需要注意:1) 所有相关类必须实现Serializable;2) 性能较差;3) 对于复杂对象图更安全。也可以采用递归clone方式,但要处理好循环引用问题。Apache Commons和Spring都提供了beanUtils浅拷贝,当对象序列化后可以考虑SerializationUtils或使用 JSON 序列化进行深拷贝
24. 什么是DNS解析?
DNS解析:通过递归查询和迭代查询两种方式,将域名转换成ip地址的过程
25. Netty的Reactor模式是如何实现的?
Netty 的 Reactor 模式 是其高并发核心设计,通过多线程分层处理 I/O 事件,实现高效的事件驱动,Boss 线程:专注接受连接; Worker 线程:高效处理 I/O 和业务;Pipeline:灵活扩展处理逻辑。
Netty的Reactor模式实现:
-
核心组件:
-
EventLoopGroup:线程池,包含多个EventLoop
-
EventLoop:事件循环,每个处理多个Channel
-
Channel:网络连接抽象
-
ChannelPipeline:处理器链
-
-
线程模型:
-
BossGroup:接受连接,通常1个线程
-
WorkerGroup:处理I/O,通常2*cpu核心数线程
-
每个Channel绑定到一个EventLoop
-
-
事件处理流程:
-
接收连接 → 注册到WorkerGroup
-
读事件 → 触发ChannelPipeline
-
写事件 → 通过ChannelFuture异步处理
-
-
关键设计:
-
无锁化设计:Channel绑定固定线程
-
零拷贝:使用ByteBuf和FileRegion
-
内存池:重用ByteBuf内存
-
26. Java NIO的Selector底层是如何工作的?
说明:Selector 的底层通过 操作系统多路复用 API 监听 Channel 事件,实现单线程高效管理海量连接。其核心是: 注册 FD 到内核事件表。 阻塞等待 就绪事件。 批量处理 就绪的 I/O 操作。
Selector底层工作原理:
-
系统依赖:
-
Linux:epoll
-
Windows:IOCP
-
MacOS:kqueue
-
-
核心机制:
-
注册:Channel.register(selector, ops)
-
就绪选择:selector.select()
-
事件处理:遍历selectedKeys()
-
-
epoll实现细节:
-
epoll_create创建epoll实例
-
epoll_ctl注册文件描述符
-
epoll_wait等待事件就绪
-
水平触发(LT)模式
-
-
性能关键:
-
事件集(interest set)与就绪集(ready set)分离
-
O(1)时间复杂度的事件通知
-
减少系统调用次数
-
27. 如何设计一个高性能的Java网络服务器?
高性能服务器设计要点:
-
架构设计:
-
事件通知模式:Reactor模式或Proactor模式
-
主从多Reactor结构,分工明确
-
业务线程池与IO线程分离,业务分离
-
-
网络层优化:
-
使用NIO/Netty:一个线程处理多个连接
-
连接复用(如HTTP keep-alive),防止短链
-
零拷贝技术:从网络直接到内存,减少CPU切换
-
-
协议优化:
-
二进制协议优于文本协议,少用json/xml
-
头部压缩(如HTTP/2 HPACK),能少送就少送
-
批处理与小包合并,资源压包
-
-
资源管理:
-
对象池化(ByteBuf, 线程等),对象线程重复利用,垃圾回收压力小。
-
异步非阻塞设计,能异步就异步
-
背压(backpressure)控制,控制流量方式压爆
-
-
监控调优:
-
关键指标监控(连接数、QPS、延迟),
-
JVM调优(堆外内存、GC策略)
-
操作系统参数调优(文件描述符数等)
-
总结白话:架构怎么搭建,使用“事件通知模式”Reactor或者Proactor,来活就干,主从多Reactor,分工明确不卡顿,老板线程接客,员工线程干活,网络IO和业务逻辑分开,别让煮面条的去算账。网络怎么快?用NIO/NETTY,一个线程馆一万条连接,省事。连接别老断(keep-alive)反复握手不累吗?数据少搬家(零拷贝),直接从网卡送到内存,不绕路。协议怎么省?别用JSON/XML这种小作文,二进制协议(如PROTOBUF)更紧凑。压缩头部(像HTTP2)能少穿就少穿。小包攒一攒在发,别动不动就快递员跑腿。资源怎么管?对象别用完就扔(池化),bytebug、线程重复用。垃圾回收压力小。能异步就异步,别堵着门口等结果。流量太大时踩刹车(背压),防止服务器被冲垮。怎么调优?盯紧指标:多少人连,美妙多少请求?慢不慢?JVM别拖后腿:堆外内存用起来,GC策略调聪明点。系统参数别抠门:文件描述符开大点,别让连接既不进来。
口诀:
事件驱动分好工,
Netty零拷贝快如风,
二进制协议省流量,
池化异步不过载。
28. 分布式系统中有哪些常见的网络问题?如何解决?
常见问题及解决方案:
-
网络分区(脑裂):
解决方案:Quorum机制、Lease机制、 fencing token -
延迟波动:
解决方案:超时与重试策略、截止时间传播 -
消息丢失:
解决方案:ACK机制、持久化队列、幂等设计 -
时钟不同步:
解决方案:逻辑时钟(Lamport时钟)、混合时钟(HLC) -
流量激增:
解决方案:熔断器模式、限流算法(令牌桶、漏桶) -
跨机房通信:
解决方案:一致性哈希、就近路由、数据同步策略
29. RPC框架的网络通信层是如何设计的?
RPC网络通信层设计要点:
-
协议设计:
-
魔数+版本号
-
消息类型(请求/响应)
-
序列化方式
-
压缩标志
-
请求ID
-
数据长度+载荷
-
-
连接管理:
-
连接池(固定大小/弹性)
-
心跳机制
-
空闲连接回收
-
-
IO模型:
-
NIO多路复用
-
异步回调或Future模式
-
Zero-copy优化
-
-
可靠性保障:
-
超时重试
-
熔断降级
-
链路加密
-
30. 如何诊断Java网络应用的性能瓶颈?
诊断方法与工具:
-
网络层诊断:
-
netstat -antp查看连接状态 -
tcpdump/Wireshark抓包分析 -
ping/traceroute检查网络质量
-
-
应用层诊断:
-
JMC(Java Mission Control)分析网络IO
-
Netty的
ChannelTrafficShapingHandler统计流量 -
分布式追踪(SkyWalking, Zipkin)
-
-
关键指标:
-
连接建立时间(TCP握手)
-
请求响应时间(RTT)
-
吞吐量(QPS/TPS)
-
错误率(连接失败、超时等)
-
-
JVM诊断:
-
jstack检查线程阻塞 -
jmap分析内存使用 -
GC日志分析网络缓冲区回收
-
-
压测工具:
-
wrk/ab进行HTTP压测
-
JMeter模拟复杂场景
-
TCPCopy流量回放
-
31. 如何设计一个可靠的UDP协议?
可靠UDP设计要点:
-
基本机制:
-
序列号:为每个数据包分配唯一ID
-
ACK确认:接收方确认收到的包
-
超时重传:RTT动态计算重传超时
-
-
流量控制:
-
滑动窗口机制
-
接收方通告窗口大小
-
拥塞控制(类似TCP的慢启动)
-
-
有序交付:
-
接收端缓冲乱序到达的包
-
按序列号重组数据
-
-
连接管理:
-
三次握手建立虚拟连接
-
心跳保持连接活性
-
优雅关闭机制
-
-
实现优化:
-
FEC(前向纠错)减少重传
-
包分片与重组
-
加密与完整性校验
-