PointNet++语义分割(semseg)训练自己的数据集并完成可视化并保存txt结果
省流:
(1)本文背景:将pipe点云上的缺陷和本体检测出来,即1种语义场景(pipe),2种类别(body和quexian)。请记住这两个数字。训练过程请看博主的《用PointNet++训练自己的数据集(语义分割模型semseg)》
(2)本篇用训练好的权重去分割训练网络时的测试集或者训练集(npy格式),进行可视化,并非是用训练好的权重去分割一个新的点云。这与博主的部件分割(partaseg)可视化《PointNet++训练自己的数据集并完成可视化并保存txt结果》是不同的。此外,可视化不是训练集或者测试集中某个完整点云,而是该点云被block后某一块的点云,不是完整点云(受block_size参数控制)。
本篇主要参考:《PointNet++分割预测结果可视化》并对博主没有提到的问题进行详解。从参考老哥这里看,这个代码既可以可视化语义分割(sem_seg)又可以可视化部件分割(part_seg),取决于421行的choice_dataset和 425行的导入那个模型:from models.pointnet2_sem_seg_msg import get_model as pointnet2
一:先上代码
在图中的这个目录下创建了一个visual.py,源码如下
"传入模型权重文件,读取预测点,生成预测的txt文件"import tqdm
import matplotlib.pyplot as plt
import matplotlib
import torch
import os
import json
import warnings
import numpy as np
from torch.utils.data import Datasetwarnings.filterwarnings('ignore')
matplotlib.use("Agg")def pc_normalize(pc):centroid = np.mean(pc, axis=0)pc = pc - centroidm = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))pc = pc / mreturn pcclass PartNormalDataset(Dataset):def __init__(self, root='./data/shapenetcore_partanno_segmentation_benchmark_v0_normal', npoints=2500,split='train', class_choice=None, normal_channel=False):self.npoints = npoints # 采样点数self.root = root # 文件根路径self.catfile = os.path.join(self.root, 'synsetoffset2category.txt') # 类别和文件夹名字对应的路径self.cat = {}self.normal_channel = normal_channel # 是否使用rgb信息with open(self.catfile, 'r') as f:for line in f:ls = line.strip().split()self.cat[ls[0]] = ls[1]self.cat = {k: v for k, v inself.cat.items()} # {'Airplane': '02691156', 'Bag': '02773838', 'Cap': '02954340', 'Car': '02958343', 'Chair': '03001627', 'Earphone': '03261776', 'Guitar': '03467517', 'Knife': '03624134', 'Lamp': '03636649', 'Laptop': '03642806', 'Motorbike': '03790512', 'Mug': '03797390', 'Pistol': '03948459', 'Rocket': '04099429', 'Skateboard': '04225987', 'Table': '04379243'}self.classes_original = dict(zip(self.cat, range(len(self.cat)))) # {'Airplane': 0, 'Bag': 1, 'Cap': 2, 'Car': 3, 'Chair': 4, 'Earphone': 5, 'Guitar': 6, 'Knife': 7, 'Lamp': 8, 'Laptop': 9, 'Motorbike': 10, 'Mug': 11, 'Pistol': 12, 'Rocket': 13, 'Skateboard': 14, 'Table': 15}if not class_choice is None: # 选择一些类别进行训练 好像没有使用这个功能self.cat = {k: v for k, v in self.cat.items() if k in class_choice}# print(self.cat)self.meta = {} # 读取分好类的文件夹jason文件 并将他们的名字放入列表中with open(os.path.join(self.root, 'train_test_split', 'shuffled_train_file_list.json'), 'r') as f:train_ids = set([str(d.split('/')[2]) for d in json.load(f)]) # '928c86eabc0be624c2bf2dcc31ba1713' 这是第一个值with open(os.path.join(self.root, 'train_test_split', 'shuffled_val_file_list.json'), 'r') as f:val_ids = set([str(d.split('/')[2]) for d in json.load(f)])with open(os.path.join(self.root, 'train_test_split', 'shuffled_test_file_list.json'), 'r') as f:test_ids = set([str(d.split('/')[2]) for d in json.load(f)])for item in self.cat:self.meta[item] = []dir_point = os.path.join(self.root, self.cat[item]) # # 拿到对应一个文件夹的路径 例如第一个文件夹02691156fns = sorted(os.listdir(dir_point)) # 根据路径拿到文件夹下的每个txt文件 放入列表中# print(fns[0][0:-4])if split == 'trainval':fns = [fn for fn in fns if ((fn[0:-4] in train_ids) or (fn[0:-4] in val_ids))]elif split == 'train':fns = [fn for fn in fns iffn[0:-4] in train_ids] # 判断文件夹中的txt文件是否在 训练txt中,如果是,那么fns中拿到的txt文件就是这个类别中所有txt文件中需要训练的文件,放入fns中elif split == 'val':fns = [fn for fn in fns if fn[0:-4] in val_ids]elif split == 'test':fns = [fn for fn in fns if fn[0:-4] in test_ids]else:print('Unknown split: %s. Exiting..' % (split))exit(-1)# print(os.path.basename(fns))for fn in fns:"第i次循环 fns中拿到的是第i个文件夹中符合训练的txt文件夹的名字"token = (os.path.splitext(os.path.basename(fn))[0])self.meta[item].append(os.path.join(dir_point, token + '.txt')) # 生成一个字典,将类别名字和训练的路径组合起来 作为一个大类中符合训练的数据# 上面的代码执行完之后,就实现了将所有需要训练或验证的数据放入了一个字典中,字典的键是该数据所属的类别,例如飞机。值是他对应数据的全部路径# {Airplane:[路径1,路径2........]}#####################################################################################################################################################self.datapath = []for item in self.cat: # self.cat 是类别名称和文件夹对应的字典for fn in self.meta[item]:self.datapath.append((item, fn)) # 生成标签和点云路径的元组, 将self.met 中的字典转换成了一个元组self.classes = {}for i in self.cat.keys():self.classes[i] = self.classes_original[i]## self.classes 将类别的名称和索引对应起来 例如 飞机 <----> 0# Mapping from category ('Chair') to a list of int [10,11,12,13] as segmentation labels"""shapenet 有16 个大类,然后每个大类有一些部件 ,例如飞机 'Airplane': [0, 1, 2, 3] 其中标签为0 1 2 3 的四个小类都属于飞机这个大类self.seg_classes 就是将大类和小类对应起来"""self.seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}# for cat in sorted(self.seg_classes.keys()):# print(cat, self.seg_classes[cat])self.cache = {} # from index to (point_set, cls, seg) tupleself.cache_size = 20000def __getitem__(self, index):if index in self.cache: # 初始slef.cache为一个空字典,这个的作用是用来存放取到的数据,并按照(point_set, cls, seg)放好 同时避免重复采样point_set, cls, seg = self.cache[index]else:fn = self.datapath[index] # 根据索引 拿到训练数据的路径self.datepath是一个元组(类名,路径)cat = self.datapath[index][0] # 拿到类名cls = self.classes[cat] # 将类名转换为索引cls = np.array([cls]).astype(np.int32)data = np.loadtxt(fn[1]).astype(np.float32) # size 20488,7 读入这个txt文件,共20488个点,每个点xyz rgb +小类别的标签if not self.normal_channel: # 判断是否使用rgb信息point_set = data[:, 0:3]else:point_set = data[:, 0:6]seg = data[:, -1].astype(np.int32) # 拿到小类别的标签if len(self.cache) < self.cache_size:self.cache[index] = (point_set, cls, seg)point_set[:, 0:3] = pc_normalize(point_set[:, 0:3]) # 做一个归一化choice = np.random.choice(len(seg), self.npoints, replace=True) # 对一个类别中的数据进行随机采样 返回索引,允许重复采样# resamplepoint_set = point_set[choice, :] # 根据索引采样seg = seg[choice]return point_set, cls, seg # pointset是点云数据,cls十六个大类别,seg是一个数据中,不同点对应的小类别def __len__(self):return len(self.datapath)class S3DISDataset(Dataset):def __init__(self, split='train', data_root='trainval_fullarea', num_point=4096, test_area=5, block_size=1.0,sample_rate=1.0, transform=None):super().__init__()self.num_point = num_point # 4096self.block_size = block_size # 1.0self.transform = transformrooms = sorted(os.listdir(data_root)) # data_root = 'data/s3dis/stanford_indoor3d/'rooms = [room for room in rooms if 'Area_' in room] # 'Area_1_WC_1.npy' # 'Area_1_conferenceRoom_1.npy'"rooms里面存放的是之前转换好的npy数据的名字,例如:Area_1_conferenceRoom1.npy....这样的数据"if split == 'train':rooms_split = [room for room in rooms ifnot 'Area_{}'.format(test_area) in room] # area 1,2,3,4,6为训练区域,5为测试区域else:rooms_split = [room for room in rooms if 'Area_{}'.format(test_area) in room]"按照指定的test_area划分为训练集和测试集,默认是将区域5作为测试集"# 创建一些储存数据的列表self.room_points, self.room_labels = [], [] # 每个房间的点云和标签self.room_coord_min, self.room_coord_max = [], [] # 每个房间的最大值和最小值num_point_all = [] # 初始化每个房间点的总数的列表labelweights = np.zeros(2) # 初始标签权重,后面用来统计标签的权重 改动1/9 13改2# 每层初始化数据集的时候会执行以下代码for room_name in tqdm.tqdm(rooms_split, total=len(rooms_split)):# 每次拿到的room_namej就是之前划分好的'Area_1_WC_1.npy'room_path = os.path.join(data_root, room_name) # 每个小房间的绝对路径,根路径+.npyroom_data = np.load(room_path) # 加载数据 xyzrgbl, (1112933, 7) N*7 room中点云的值 最后一个是标签#points, labels = room_data[:, 0:6], room_data[:, 6] # xyzrgb, N*6; l, N 将训练数据与标签分开"前面已经将标签进行了分离,那么这里 np.histogram就是统计每个房间里所有标签的总数,例如,第一个元素就是属于类别0的点的总数""将数据集所有点统计一次之后,就知道每个类别占总类别的比例,为后面加权计算损失做准备"tmp, _ = np.histogram(labels, range(3)) # 统计标签的分布情况 [192039 185764 488740 0 0 0 28008 0 0 0, 0 0 218382] 改动2/9 13对应14 2对应3# 也就是有多少个点属于第i个类别labelweights += tmp # 将它们累计起来coord_min, coord_max = np.amin(points, axis=0)[:3], np.amax(points, axis=0)[:3] # 获取当前房间坐标的最值self.room_points.append(points), self.room_labels.append(labels)self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)num_point_all.append(labels.size) # 标签的数量 也就是点的数量"通过for循环后,所有的房间里类别分布情况和坐标情况都被放入了相应的变量中,后面就是计算权重了"labelweights = labelweights.astype(np.float32)labelweights = labelweights / np.sum(labelweights) # 计算标签的权重,每个类别的点云总数/总的点云总数"感觉这里应该是为了避免有的点数量比较少,计算出训练的iou占miou的比重太大,所以在这里计算一下加权(根据点标签的数量进行加权)"self.labelweights = np.power(np.amax(labelweights) / labelweights, 1 / 3.0) # 为什么这里还要开三次方???print('label weight\n')print(self.labelweights)sample_prob = num_point_all / np.sum(num_point_all) # 每个房间占总的房间的比例num_iter = int(np.sum(num_point_all) * sample_rate / num_point) # 如果按 sample rate进行采样,那么每个区域用4096个点 计算需要采样的次数room_idxs = []# 这里求的应该就是一个划分房间的索引for index in range(len(rooms_split)):room_idxs.extend([index] * int(round(sample_prob[index] * num_iter)))self.room_idxs = np.array(room_idxs)print("Totally {} samples in {} set.".format(len(self.room_idxs), split))def __getitem__(self, idx):room_idx = self.room_idxs[idx]points = self.room_points[room_idx] # N * 6 --》 debug 1112933,6labels = self.room_labels[room_idx] # NN_points = points.shape[0]while (True): # 这里是不是对应的就是将一个房间的点云切分为一个区域center = points[np.random.choice(N_points)][:3] # 从该个房间随机选一个点作为中心点block_min = center - [self.block_size / 2.0, self.block_size / 2.0, 0]block_max = center + [self.block_size / 2.0, self.block_size / 2.0, 0]"找到符合要求点的索引(min<=x,y,z<=max),坐标被限制在最小和最大值之间"point_idxs = np.where((points[:, 0] >= block_min[0]) & (points[:, 0] <= block_max[0]) & (points[:, 1] >= block_min[1]) & (points[:, 1] <= block_max[1]))[0]"如果符合要求的点至少有1024个,那么跳出循环,否则继续随机选择中心点,继续寻找"if point_idxs.size > 1024:break"这里可以尝试修改一下1024这个参数,感觉采4096个点的话,可能存在太多重复的点"if point_idxs.size >= self.num_point: # 如果找到符合条件的点大于给定的4096个点,那么随机采样4096个点作为被选择的点selected_point_idxs = np.random.choice(point_idxs, self.num_point, replace=False)else: # 如果符合条件的点小于4096 则随机重复采样凑够4096个点selected_point_idxs = np.random.choice(point_idxs, self.num_point, replace=True) ## normalizeselected_points = points[selected_point_idxs, :] # num_point * 6 拿到筛选后的4096个点current_points = np.zeros((self.num_point, 9)) # num_point * 9current_points[:, 6] = selected_points[:, 0] / self.room_coord_max[room_idx][0] # 选择点的坐标/被选择房间的最大值 做坐标的归一化current_points[:, 7] = selected_points[:, 1] / self.room_coord_max[room_idx][1]current_points[:, 8] = selected_points[:, 2] / self.room_coord_max[room_idx][2]selected_points[:, 0] = selected_points[:, 0] - center[0] # 再将坐标移至随机采样的中心点selected_points[:, 1] = selected_points[:, 1] - center[1]selected_points[:, 3:6] /= 255.0 # 颜色信息归一化current_points[:, 0:6] = selected_pointscurrent_labels = labels[selected_point_idxs]if self.transform is not None:current_points, current_labels = self.transform(current_points, current_labels)return current_points, current_labels, current_labelsdef __len__(self):return len(self.room_idxs)class Generate_txt_and_3d_img:def __init__(self, img_root, target_root, num_classes, testDataLoader, model_dict, color_map=None):self.img_root = img_root # 点云数据路径self.target_root = target_root # 生成txt标签和预测结果路径self.testDataLoader = testDataLoaderself.num_classes = num_classesself.color_map = color_mapself.heat_map = False # 控制是否输出heatmapself.label_path_txt = os.path.join(self.target_root, 'label_txt') # 存放label的txt文件self.make_dir(self.label_path_txt)# 拿到模型 并加载权重self.model_name = []self.model = []self.model_weight_path = []for k, v in model_dict.items():self.model_name.append(k)self.model.append(v[0])self.model_weight_path.append(v[1])# 加载权重self.load_cheackpoint_for_models(self.model_name, self.model, self.model_weight_path)# 创建文件夹self.all_pred_image_path = [] # 所有预测结果的路径列表self.all_pred_txt_path = [] # 所有预测txt的路径列表for n in self.model_name:self.make_dir(os.path.join(self.target_root, n + '_predict_txt'))self.make_dir(os.path.join(self.target_root, n + '_predict_image'))self.all_pred_txt_path.append(os.path.join(self.target_root, n + '_predict_txt'))self.all_pred_image_path.append(os.path.join(self.target_root, n + '_predict_image'))"将模型对应的预测txt结果和img结果生成出来,对应几个模型就在列表中添加几个元素"self.generate_predict_to_txt() # 生成预测txtself.draw_3d_img() # 画图def generate_predict_to_txt(self):for batch_id, (points, label, target) in tqdm.tqdm(enumerate(self.testDataLoader),total=len(self.testDataLoader), smoothing=0.9):# 点云数据、整个图像的标签、每个点的标签、 没有归一化的点云数据(带标签)torch.Size([1, 7, 2048])points = points.transpose(2, 1)# print('1',target.shape) # 1 torch.Size([1, 2048])xyz_feature_point = points[:, :6, :]# 将标签保存为txt文件point_set_without_normal = np.asarray(torch.cat([points.permute(0, 2, 1), target[:, :, None]], dim=-1)).squeeze(0) # 代标签 没有归一化的点云数据 的numpy形式np.savetxt(os.path.join(self.label_path_txt, f'{batch_id}_label.txt'), point_set_without_normal,fmt='%.04f') # 将其存储为txt文件" points torch.Size([16, 2048, 6]) label torch.Size([16, 1]) target torch.Size([16, 2048])"assert len(self.model) == len(self.all_pred_txt_path), '路径与模型数量不匹配,请检查'for n, model, pred_path in zip(self.model_name, self.model, self.all_pred_txt_path):#print("model_name",n)#print("model", model)#print("pred_path", pred_path)#print("xx:",self.to_categorical(label, 5))#print("yy:",points.shape) #yy: torch.Size([1, 9, 50000])#print("zz:", points.ndim)##print("First sample points:", points[0, :, :]) # 第一个样本的所有点points=points.float() #自己加的 RuntimeError: Index put requires the source and destination dtypes match, got Float for the destination and Double for the source.seg_pred, trans_feat = model(points) #改动3/9 16 1 seg_pred, trans_feat = model(points, self.to_categorical(label, 1))seg_pred = seg_pred.cpu().data.numpy()# =================================================# seg_pred = np.argmax(seg_pred, axis=-1) # 获得网络的预测结果 b n cif self.heat_map:out = np.asarray(np.sum(seg_pred, axis=2))seg_pred = ((out - np.min(out) / (np.max(out) - np.min(out))))else:seg_pred = np.argmax(seg_pred, axis=-1) # 获得网络的预测结果 b n c# =================================================seg_pred = np.concatenate([np.asarray(xyz_feature_point), seg_pred[:, None, :]],axis=1).transpose((0, 2, 1)).squeeze(0) # 将点云与预测结果进行拼接,准备生成txt文件svae_path = os.path.join(pred_path, f'{n}_{batch_id}.txt')np.savetxt(svae_path, seg_pred, fmt='%.04f')def draw_3d_img(self):# 调用matpltlib 画3d图像each_label = os.listdir(self.label_path_txt) # 所有标签txt路径self.label_path_3d_img = os.path.join(self.target_root, 'label_3d_img')self.make_dir(self.label_path_3d_img)assert len(self.all_pred_txt_path) == len(self.all_pred_image_path)for i, (pre_txt_path, save_img_path, name) in enumerate(zip(self.all_pred_txt_path, self.all_pred_image_path, self.model_name)):each_txt_path = os.listdir(pre_txt_path) # 拿到txt文件的全部名字for idx, (txt, lab) in tqdm.tqdm(enumerate(zip(each_txt_path, each_label)), total=len(each_txt_path)):if i == 0:self.draw_each_img(os.path.join(self.label_path_txt, lab), idx, heat_maps=False)self.draw_each_img(os.path.join(pre_txt_path, txt), idx, name=name, save_path=save_img_path,heat_maps=self.heat_map)print(f'所有预测图片已生成完毕,请前往:{self.all_pred_image_path} 查看')def draw_each_img(self, root, idx, name=None, skip=1, save_path=None, heat_maps=False):"root:每个txt文件的路径"points = np.loadtxt(root)[:, :3] # 点云的xyz坐标points_all = np.loadtxt(root) # 点云的所有坐标points = self.pc_normalize(points)skip = skip # Skip every n pointsfig = plt.figure()ax = fig.add_subplot(111, projection='3d')point_range = range(0, points.shape[0], skip) # skip points to prevent crashx = points[point_range, 0]z = points[point_range, 1]y = points[point_range, 2]"根据传入的类别数 自定义生成染色板 标签 0对应 随机颜色1 标签1 对应随机颜色2"if self.color_map is not None:color_map = self.color_mapelse:color_map = {idx: i for idx, i in enumerate(np.linspace(0, 0.9, num_classes))}Label = points_all[point_range, -1] # 拿到标签# 将标签传入前面的字典,找到对应的颜色 并放入列表Color = list(map(lambda x: color_map[int(x)], Label)) #改动4/9: TypeError: list indices must be integers or slices, not numpy.float64ax.scatter(x, # xy, # yz, # zc=Color, # Color, # height data for colors=25,marker=".")ax.axis('auto') # {equal, scaled}ax.set_xlabel('X')ax.set_ylabel('Y')ax.set_zlabel('Z')ax.axis('off') # 设置坐标轴不可见ax.grid(False) # 设置背景网格不可见ax.view_init(elev=0, azim=0)if save_path is None:plt.savefig(os.path.join(self.label_path_3d_img, f'{idx}_label_img.png'), dpi=300, bbox_inches='tight',transparent=True)else:plt.savefig(os.path.join(save_path, f'{idx}_{name}_img.png'), dpi=300, bbox_inches='tight',transparent=True)def pc_normalize(self, pc):l = pc.shape[0]centroid = np.mean(pc, axis=0)pc = pc - centroidm = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))pc = pc / mreturn pcdef make_dir(self, root):if os.path.exists(root):print(f'{root} 路径已存在 无需创建')else:os.mkdir(root)def to_categorical(self, y, num_classes):""" 1-hot encodes a tensor """print("y:",y)print("num_classes",num_classes)new_y = torch.eye(num_classes)[y.cpu().data.numpy(),]if (y.is_cuda):return new_y.cuda()return new_ydef load_cheackpoint_for_models(self, name, model, cheackpoints):assert cheackpoints is not None, '请填写权重文件'assert model is not None, '请实例化模型'for n, m, c in zip(name, model, cheackpoints):print(f'正在加载{n}的权重.....')weight_dict = torch.load(os.path.join(c, 'best_model.pth'))m.load_state_dict(weight_dict['model_state_dict'])print(f'{n}权重加载完毕')if __name__ == '__main__':import copyimg_root = r'D:\YinParker\Desktop\AllFileFolder\A_Other_projects_in_laboratory\pointNet2\Pointnet_Pointnet2_pytorch-master\data\stanford_indoor3d' # 数据集路径target_root = r'D:\YinParker\Desktop\\' # 输出结果路径num_classes = 2 # 填写数据集的类别数 如果是s3dis这里就填13 shapenet这里就填50 改动5/9choice_dataset = 'S3dis' # 预测ShapNet数据集# 导入模型 部分"所有的模型以PointNet++为标准 输入两个参数 输出两个参数,如果模型仅输出一个,可以将其修改为多输出一个None!!!!"# ==============================================from models.pointnet2_sem_seg_msg import get_model as pointnet2 #改自己模型pointnet2_sem_seg_msg#from models.finally_csa_part_seg import get_model as csa #用来对比的模型 改动6/9#from models.pointcouldtransformer_part_seg import get_model as pct #用来对比的模型model1 = pointnet2(num_classes=num_classes).eval()#model2 = csa(num_classes, normal_channel=True).eval() 改动7/9#model3 = pct(num_class=num_classes, normal_channel=False).eval()# ============================================# 实例化数据集"Dataset同理,都按ShapeNet格式输出三个变量 point_set, cls, seg # pointset是点云数据,cls十六个大类别,seg是一个数据中,不同点对应的小类别""不是这个格式的话就手动添加一个"if choice_dataset == 'ShapeNet':print('实例化ShapeNet')TEST_DATASET = PartNormalDataset(root=img_root, npoints=2048, split='test', normal_channel=False)testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=1, shuffle=False, num_workers=0,drop_last=True)color_map = {idx: i for idx, i in enumerate(np.linspace(0, 0.9, num_classes))}else:TEST_DATASET = S3DISDataset(split='test', data_root=img_root, num_point=50000, test_area=2, #改动8/9block_size=5.0, sample_rate=10.0, transform=None)testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=1, shuffle=False, num_workers=0,pin_memory=True, drop_last=True)color_maps = [(0,0,255),(255,0,0),(152, 223, 138), (174, 199, 232), (255, 127, 14), (91, 163, 138), (255, 187, 120), (188, 189, 34),(140, 86, 75), (255, 152, 150), (214, 39, 40), (197, 176, 213), (196, 156, 148), (23, 190, 207), (112, 128, 144)]color_map = []for i in color_maps:tem = ()for j in i:j = j / 255tem += (j,)color_map.append(tem)print('实例化S3DIS')# 将模型和权重路径填写到字典中,以下面这个格式填写就可以了# 如果加载权重报错,可以查看类里面的加载权重部分,进行对应修改即可model_dict = {'PonintNet': [model1, r'D:\YinParker\Desktop\AllFileFolder\A_Other_projects_in_laboratory\pointNet2\Pointnet_Pointnet2_pytorch-master\log\sem_seg\2025-04-09_19-21\checkpoints'] #改动9/9# 'CSA': [model2, r'权重路径2'],# 'PCT': [model3, r'权重路径3']}c = Generate_txt_and_3d_img(img_root, target_root, num_classes, testDataLoader, model_dict, color_map)二、改动:
改动1: 158行左右
2种类别

改动2:169行左右
写类别+1 : 2+1=3

改动3:298行左右
如果后面421行的choice_dataset = ‘S3dis’ ,即用语义分割(semseg)数据格式,则298行就不要后面的 self.to_categorical(label, 2)因为在pointnet2_sem_seg.py的22行的 def forward(self, xyz):只有两个参数。若choice_dataset = 'ShapeNet’并且用部件分割模型,因为pointnet2_part_seg_msg.py的第237行def forward(self, xyz, cls_label):有三个参数,所以得加上参数self.to_categorical(label, 2),2是类别个数。

改动4:356行左右

改动5:
你训练集或测试集的路径、输出路径、个数

训练集测试机路径下是:Area1开头的是训练的,Area2开头的是测试集
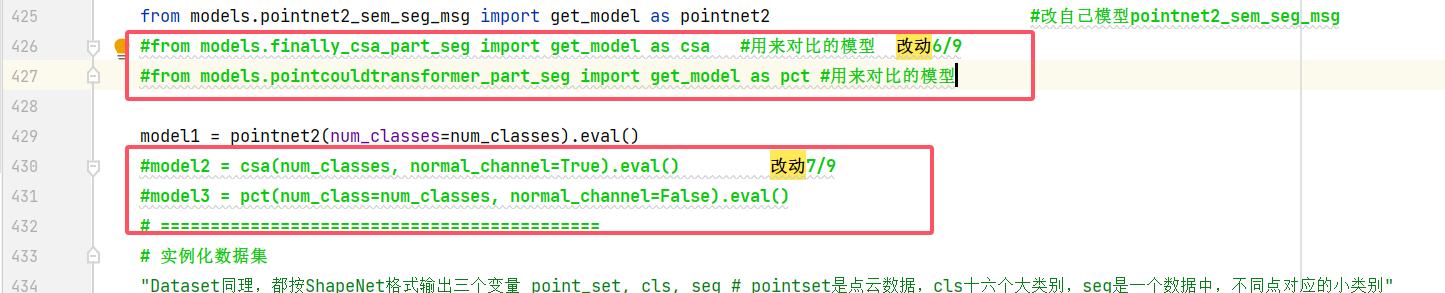
改动6、7:426行左右
下面两个是作对比用的,不用也行;第一个选好自己的模型
改动8: 444行左右
根据自己实际情况改参数,tset_area选1或者2就是分别对训练集和测试集进行可视化(Area1和Area2是根据自己的实际情况来的)

改动9: 461行左右
配合改动6和7 加载模型权重

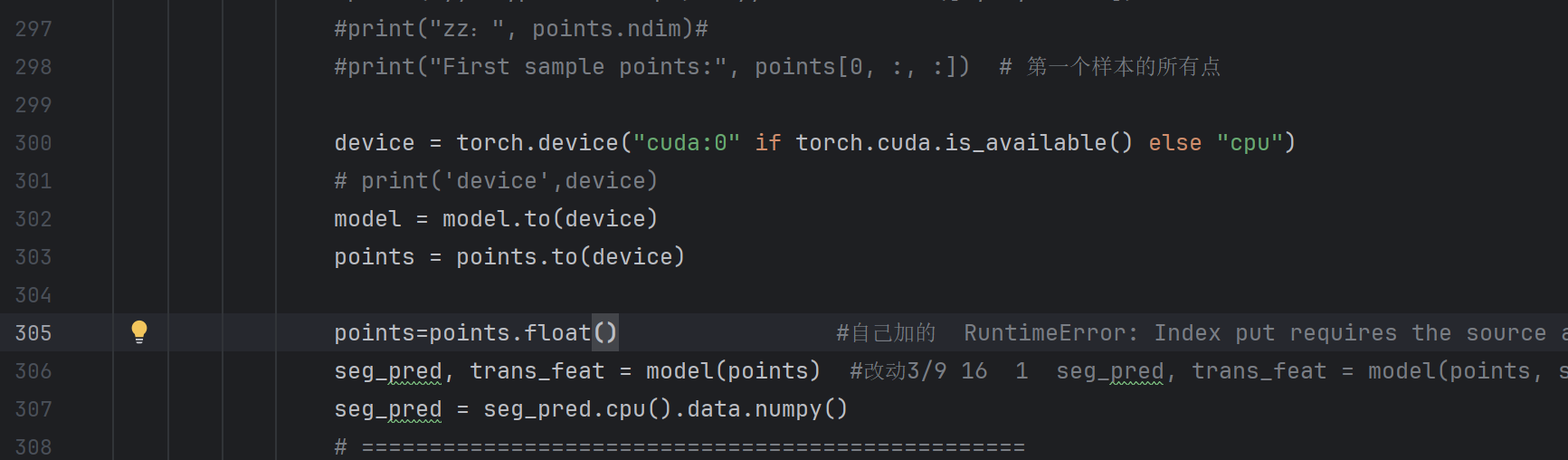
改动10:在GPU上跑
原本代码是用cpu跑,比较慢,现在用gpu显卡跑,加上:(加的位置看图)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# print('device',device)
model = model.to(device)
points = points.to(device)
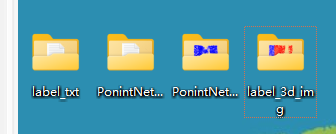
程序运行结果
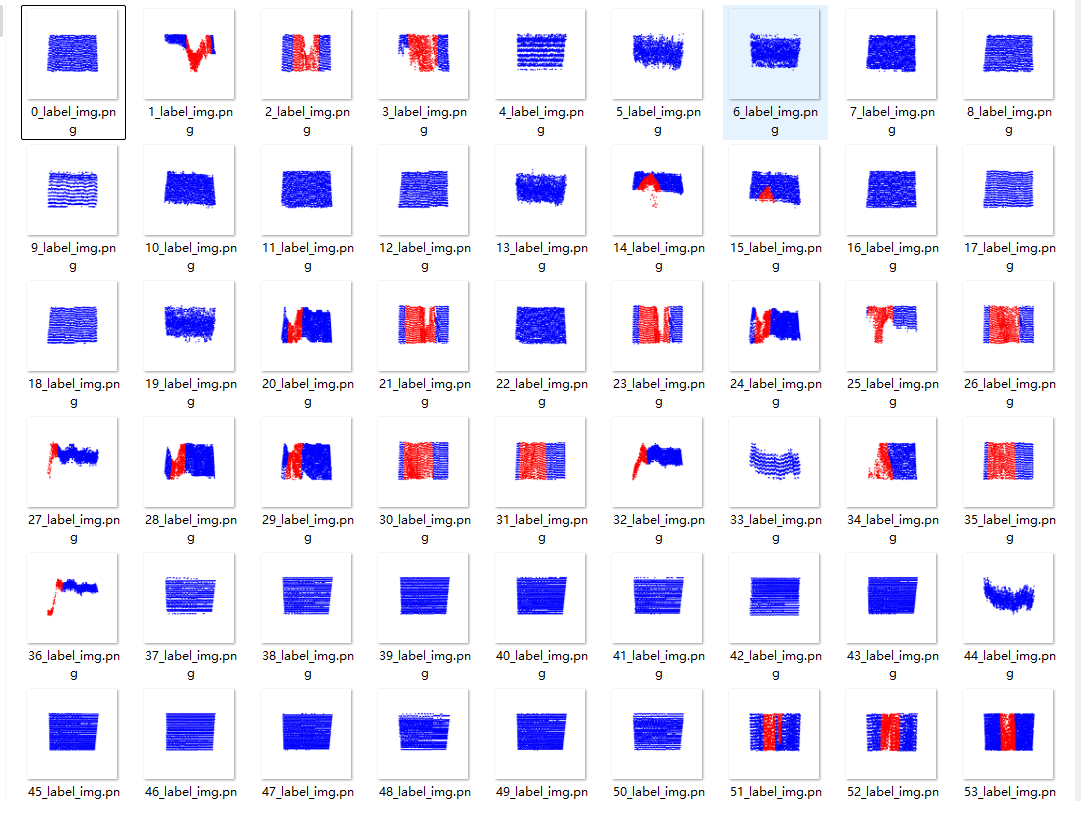
在桌面生成四个文件夹,根据文件夹名字可以看出那个是标签那个是预测。再次提醒:可视化不是训练集或者测试集中某个完整点云,而是该点云被block后某一块的点云,不是完整点云。(受block_size参数控制)
某一文件夹:
若对你有用,请点赞收藏