【MySQL】MySQL数据库的基础操作、常用数据类型、表结构的操作
目录
1.数据库的操作
1.1 查看(显示)当前的数据库 (show databases;)
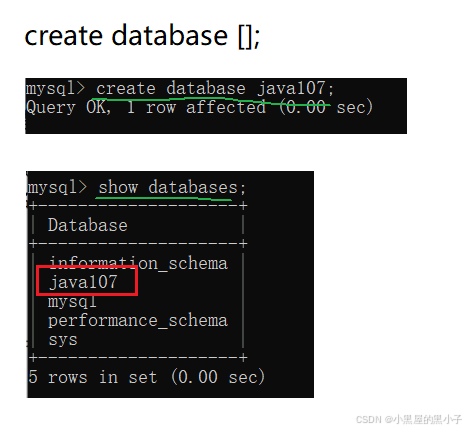
1.2 创建数据库 (create database 数据库名;)
1.3 选中(使用)数据库 (use 数据库名;)
1.4 删除数据库 (drop database 数据库名;)
2. 常用数据类型
2.1 数值类型
2.2 字符串类型
2.3 日期类型
【最常用的类型】
3. 表操作 (前提,use 数据库名;)
3.1 查看数据库中的表 (show tables)
3.2 创建表 (create table 表名(列名 类型......))
3.3 查看指定表的结构 (desc 表名;)
3.4 删除表 (drop table 表名;)
总结语句
练习
1.数据库的操作
- MySQL是一个客户端-服务器结构的程序
- 服务器是mysql数据库的本体,负责保存和管理数据。数据都是存储在硬盘上的。
- 一个mysql服务器上,有很多很多的表,可以把有关联关系(业务上关联)的一些表放到一起,构成了一个逻辑上的“数据集合",称为数据库。而且一个mysql服务器上可以有多个这样的数据库的。
- 如何组织数据的呢:按照这样的层次组织: 数据库(逻辑上的数据集合,有多个数据表)-> 数据表 -> 有很多行,每一行是一个“记录” -> 针对每一行,有很多列,每一列称为一个字段。每个列都是有一个具体的类型的。
- 不同的数据库(逻辑上的数据集合,有多个数据表),可以放到同一个mysql服务器上,也可以放到不同的mysql服务器上。
操作数据库的命令,也称为"SQL语句”,也可以理解成是一种编程语言。

1.1 查看(显示)当前的数据库 (show databases;)

- show 和 databases 之间有一个或者多个空格。单词与单词之间至少要有一个空格。
- 注意是databases,不是database!!!
- 注意英文分号结尾(客户端里的任何一个sql语句都需要使用 分号 来结尾)
- mysql客户端允许输入sql的时候换行。
不同电脑的数据库显示的不一样,因为里面数据库表不同。
例如上图中的mysql数据库,保存了当前服务器的各种信息。修改配置什么的都可以通过这个mysql数据库进行操作。这里慎重操作。
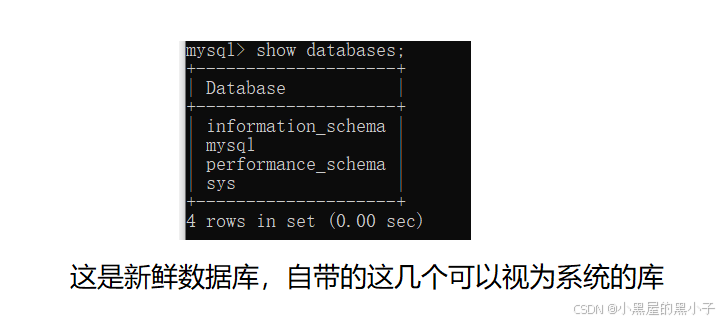
4 rows in set (0.00 sec)
- 执行完一个sql语句之后,会得到一个反馈,反馈会告诉我们,当前执行结果有多少行记录,以及消耗多少时间。
- set意思有两种:1、集合(HashSet)2、设置(get/set) 显然我们这里是第一个的意思。
- sec => second(秒)对于与计算机来说,0.03秒,30ms 就是蜗牛爬。0.00 sec 只能说明当前时间小于10ms的。即使是1ms,对于计算机来说,也是挺慢的了。影响时间的因素有很多,硬件、软件、运行环境等。所以数据库的很多操作都是低效的,在一个大型系统中,数据库很容易成为性能瓶颈。
有人可能要问了,客户端与服务器是通过网络通信的,是不是与网络有关系?是的确实有这方面因素,但当前情况下没关系。因为此时你的客户端和服务器在一个主机上,虽然是通过网络通信,但是走的是环回网卡(特殊的网卡)
1.2 创建数据库 (create database 数据库名;)
注意事项:
- 是database,不是databases!!! 查询是查询多个数据库加上s,创建的是一个数据库不加s
- java107 是数据库名字,数字,字母,下划线构成,数字不能开头(和Java变量命名一个道理)
- 数据库名字,表名,列名,不能是sql中的关键字(特殊含义的单词),例如create,show ,database 不能拿来命名。
- 如果就是想拿关键字作为数据库名,可以使用反引号 ` 把数据库名给引起来!!!
' " ` 键盘左上角的按键,esc下面, tab 上面,1的左边 和~是一个按钮(保证你是英文状态)
5. 写sql的时候,sql的关键字是大小写不敏感的。 create database与CREATE DATABASE是一样的效果 。
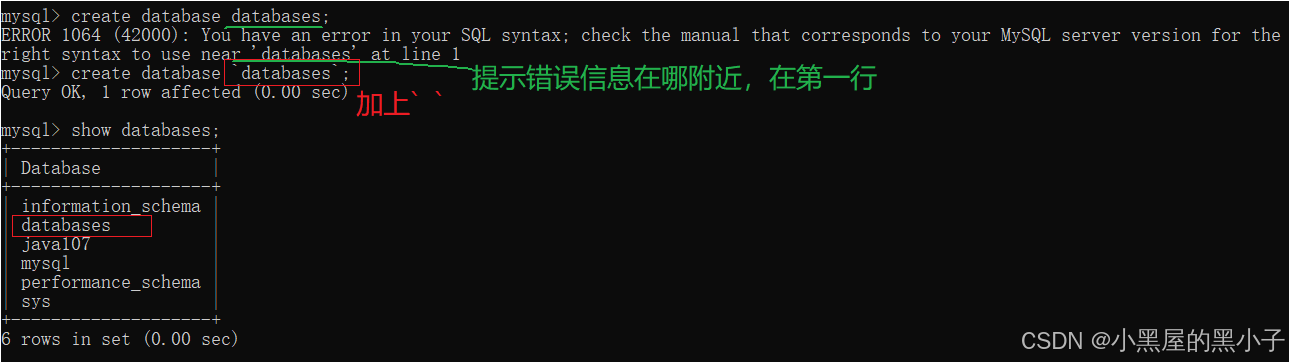
6. 创建数据库的时候名字不能重复
- 此时在创建的时候加上 IF NOT EXISTS 修饰(是否不存在),就不会因为数据库同名而报错,发现数据库已经存在,是不会继续创建数据库的。
- 用途:避免sql报错。实际工作中,很多时候是把一系列 sql 写到一个文件中,批量执行的;很少会这样一条一条的执行。在批量执行的情况下,如果一条sql报错了,后面的sql就无法继续执行了。

7. 创建数据库的时候,还可以指定字符集
- CHARACTER SET 指定数据库采用的字符集 例如:character set utf8 可以简写为charset utf8
- COLLATE 指定数据库字符集的校验规则 collate
- 当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci。MySQL 8.0 及更高版本。
- 如果需要在数据库中保存中文,mysql默认的字符集是拉丁文,不支持中文。必须要在创建数据库的时候,手动指定编码方式为支持中文的编码.(GBK,UTF8) MySQL 5.7 及更早版本。
- gbk现在已经用的越来越少了,主要是使用utf8(变长编码)作为编码方式。utf8不仅仅可以表示中文,也可以表示世界上的任何一种语言文字。
- 创建数据库的时候要指定字符集,不指定字符集(用默认的)很可能会插入中文失败。一般情况下编程中都是使用 utf8
- MySQL的utf8编码不是真正的utf8是一个“残本”,没有包含某些复杂的中文字符(少一些emoji表情,苹果手机短信功能中,带有的表情)。MySQL真正的utf8是使用utf8mb4,则是完整体的 utf8,建议大家都使用 utf8mb4
什么是字符集 英文:character set
(91条消息) 字符集详解(学习,看一篇就够了)_笑我归无处的博客-CSDN博客
计算机中,表示一个汉字,需要几个字节?不同的字符集下,结果是不同的。平时常用的字符集:
- GBK windows简体中文版,默认字符集。 2个字节表示一个汉字。C语言中,VS默认也是gbk,所以看到的一个汉字是两个字节,其实都是这里留下的印象。
- UTF8 更通用的字符集,不仅仅能表示中文。通常是3个字节表示一个汉字的。
- unicode 算是编码方式,是给一个字符进行编码的,但是无法给“字符串进行编码”,严格的说不能算是一个完全的字符集。比如,把多个unicode 编码的字符放到一起,构成一个字符串,就可能会乱套了。无法区分字符和字符之间的边界。基于unicode就演化出了一些可以给"字符串"编码的版本,例如UTF8字符集,但是不严谨。
- 在Java中,谈到char类型,内部编码unicode。谈到String,内部的编码一般是utf8。
例如修改字符串,Java 内部自动完成了编码转换。- 每种字符集,都是一个很大的码表。
查看字符编码(UTF-8)
http://mytju.com/classcode/tools/encode_utf8.asp
1.3 选中(使用)数据库 (use 数据库名;)
要想针对某个数据库中的表进行后续操作(增删改查),此时就得先明确是针对哪个库进行的,毕竟有很多数据库。表是从属于数据库的。要针对表操作,就需要先选中哪个数据库的表,指定清楚。
选中数据库,选中之后,会有个提示。


1.4 删除数据库 (drop database 数据库名;)

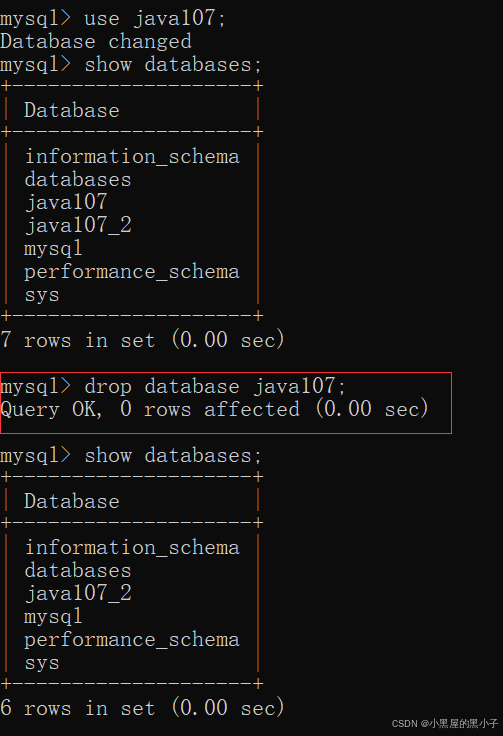
- IF EXISTS 判断数据库中是否存在,意思是如果存在
- [ ] 是可选项,可以去掉,也可以添加,根据情况
- 删除操作,删掉的不仅仅是database,而且也删除了database中所有的表和表里所有的数据。
这里我们要认识到,删除数据库操作,是一个非常危险的操作。从删库到跑路,更严重的,可能还得进去。
当前阶段,删除自己的数据库没事。如果在公司里,公司的数据库都是一些重要的商业数据,价值是难以估量的。
2. 常用数据类型
- 一个表,包含很多行,每一行也称为一条记录。一个行里可以有很多列,每一列也称为是一个字段。每个列都是有一个具体的类型的。
- 关于数据类型 ,描述了这个数据是什么样的数据,类型系统和C/Java非常相似的。
2.1 数值类型
分为整型和浮点型:
整型
| 数据类型 | 大小 | 说明 | 对应java类型 | 对应C类型 |
| BIT[ (M) ] | M指定位数, 默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 | char[] |
| TINYINT | 1字节 | Byte | signed char | |
| SMALLINT | 2字节 | Short | short int | |
| INT | 4字节 | Integer | int | |
| BIGINT | 8字节 | Long | long long int |
扩展资料:
- Java 的数据类型Byte,Short,Integer,Long这一套命名的方式成了主流。为什么SQL与之不一样呢?SQL其实是一个比较古老的编程语言,辈分和C差不多。那年还没有Java语言。
- Java 中就没有无符号类型。mysql中虽然有无符号类型,但是不推荐用。
- 数值类型指定为无符号(unsigned),表示不取负数。
- 1字节(bytes)= 8bit。对于整型类型的范围:
- 有符号范围:-2^(类型字节数*8-1)到2^(类型字节数*8-1)-1,如int是4字节,就是-2^31到2^31-1
- 无符号范围:0到2^(类型字节数*8)-1,如int就是2^32-1
- 尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其如此,还不如设计时,将int类型提升为bigint类型。
浮点型:
| 数据类型 | 大小 | 说明 | 对应java类型 | 对应C类型 |
| FLOAT(M,D) | 4字节 | 单精度,M指定长度,D指定 小数位数。会发生精度丢失 | Float | float |
| DOUBLE(M,D) | 8字节 | 双精度,M指定长度,D指定 小数位数。会发生精度丢失(比float精度高) | Double | double |
| DECIMAL(M,D) | M/D最大值+2 | 双精度,M指定长度,D表示 小数点位数。精确数值 | BigDecimal | char[] |
| NUMERIC(M,D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal | char[] |
- 例如:double(M,D) -》 double(3,1) 10.2 20.0;100 error 10.02 error
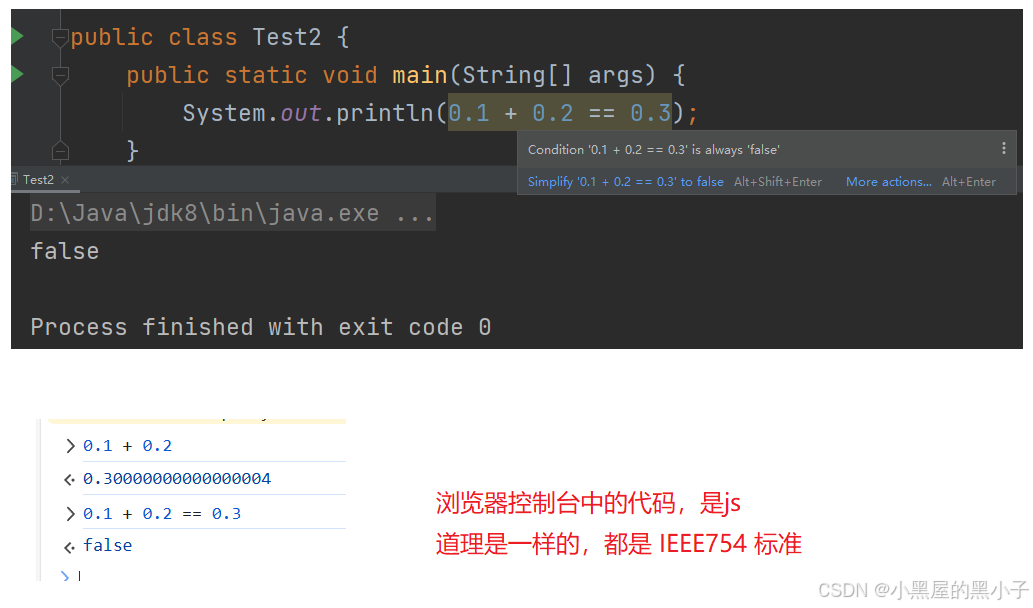
- 此处的float和double和Java/C类似都是按照IEEE 754标准来存储的浮点数。存在一定的缺陷,会发生精度会丢失,有一定的误差。
- 例如比较 0.1 + 0.2 == 0.3 -》 false 用 == 比较两个浮点数,非常危险的。
- DECIMAL(M,D) 精度更高的浮点数,使用其他的方式来存储小数。类似于 字符串的方式来保存的。
- 使用decimal表示小数,精度是更高了,但运算速度会变慢,占用的空间也更多。不同情况下使用不同的类型表示。
- 例如表示科学数据的时候,相对于精度,运算速度和空间就不那么重要了。
- 算钱的时候也对精度要求非常高,例如银行可能精确到厘。针对我们日常超市购物价格一般都是精确的分的。使用decimal表示小数,精度高了但运算速度会变慢,占用的空间也更多。一般超市一个月或者一年流水非常多,数据量非常的大,运算时间就非常的长,更好的选择是使用 int 来表示钱,以分为单位即可 0.5元 -》 50分,精度高,运算速度快,占用空间少。
上面看到的这些数值类型都是有符号(带有正负的),mysql中也有无符号类型,但是mysql官方文档,明确说,无符号类型不建议使用,而且会在未来的版本中就不再支持了。
像java、Python、JS等这样的高级语言都没有无符号类型,说明,无符号类型存在非常严重的问题。拿两个无符号类型相减,可能产生溢出问题,例如 10u - 20u =》 没有负号,产生很大的数字。
C/C++有无符号类型。为什么之后的语言很少支持无符号类型。因为以前的计算机各方面成本比较高,例如内存空间比较珍贵,为了尽可能的节约成本能省则省的原则,设定了有符号类型和无符号类型,来应对不同数据情况下,使用无符号类型能表示更多的数据,节省了内存空间。但随着发展,内存空间已经不那么珍贵,动不动就是几百个G,相当于无符号可能会引起的溢出问题,这个时候再去节省这点空间就没必要了。
2.2 字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 | 对应C的类型 |
| VARCHAR (SIZE) | 0 - 65,535字节 | 可变长度字符串 | String | char[] |
| TEXT | 0 - 65,535字节 = 64k | 长文本数据 | String | char[] |
| MEDIUMTEXT | 0 - 16,777,215字节 | 中等长度文本数据 | String | char[] |
| BLOB | 0 - 65,535字节 | 二进制形式的长文本数据 | byte[] | char[] |
解释说明:
- varchar(size) 设定一个"变长字符串" ,size指定的是最大长度,表示该类型里最多存储几个字符,注意单位是字符,不是字节。例如:一个汉字算是一个字符,但是可能是对应多个字节。
- 假设指定name列,类型是varchar(10),此时姓名最多几个字? 10个字,但不是立即分配10个字符的存储空间,而是会先分配一个比较小的空间,如果不够自动扩展。根据存的数据长度动态调整的。最大的空间不会超过10
- 文本数据:存储的都是字符。这些字符都是可以在对应的码表上查到的。
- 二进制数据:存储的是二进制的数据(由许多0, 1构成的),在码表上查不到。例如:音乐,图片,视频都属于二进制数据。
- 图片等一般很少会在数据库的某一列中,存储的数据过大(几十M,几百M)会大大影响到数据库的增删改查的效率。而且BLOB类型 大小有限也就是64k。 例如,后续会进行列的数据比较,数据过大会影响条件判断等。
- 实际开发中如果需要保存图片,一般都是把图片单独放到专门的目录中,然后让数据库保存图片的路径。
blob 存储的是二进制字符串 和 bit[]不一样. bit[]只能存最多64 bit
blob可以存更长(相对来说的),64kb,比如要存一个小的图片,存一个小的音频文件
- 字符集:要想在计算机中显示文字,必须把文字都收集起来放在一个表中,这个表叫字符集(Charset)。
- 码表:字符集中的每个文字,都分配一个数字号码,这叫码表(Code chart)。比如中文 ‘霸’字,在码表中对应的码是38712(十进制),或者9738(十六进制)。
- 编码方式:有了码表,就需要确定哪些文字用几个字节表示,以及如果有多个字节代表一个字,字节的读取顺序,这些就是字符编码方式(Encoding)。
虽然为了严谨起见,上面把字符集和码表分开说明,但实际上很多字符集也给每个字符分配了一个码(Code Point),所以很多人经常也把字符集叫做码表、码表叫做字符集。
字符集与编码系列:Unicode字符集-CSDN博客
2.3 日期类型
| 数据类型 | 大小 | 说明 | 对应java类型 | 对应C的类型 |
| DATETIME | 8 字节 | 范围从1000到9999年, 不会进行时区的检索及转换。 | java.util.Date、 java.sql.Timestamp | MYSQL TIME |
| TIMESTAMP | 4 字节 | 范围从1970到2038年, 自动检索当前时区并进行转换。 | java.util.Date、 java.sql.Timestamp | MYSQL TIME |
- TIMESTAMP表示时间戳,大小是4个字节。计算机使用时间戳 表示时间。以1970年1月1日0时0分0秒作为基准,计算当前时刻和基准时刻的秒数/毫秒数/微秒数之差。
- DATETIME也表示时间戳,大小是 8个字节。
- datetime timestamp 都能表示年月日,时分秒。
- 在对应的java类型中,java.util.Date这个类型 ,只能表示年月日,不能表示时分秒。
- java.sql.Timestamp 这个类型能表示年月日,时分秒,8个字节的ms级时间戳,不用担心2038年的问题。
tips:
- 现在使用4个字节,表示秒级时间戳,已经捉襟见肘了。目前时刻的时间戳数字(1744806476),快要超过4个字节的范围了(如果是有符号,-21亿->421亿;如果是无符号,0->42亿9千万,但是Java中就没有无符号类型,mysql虽然有无符号类型,不推荐用),所以2038年(13年之后),4个自己就无法继续表示秒级时间戳了。
- 2038年的时候,一定会有很多程序/系统,因为时间戳的问题产生严重bug。比如,坐
什么的,就要谨慎点。在2000年也因时间戳发生过bug(千年虫)。感兴趣的同学可以去搜索一下。
【最常用的类型】
- int 整型
- long 长整型
- double(M,N) 双精度浮点数类型
- decimal(M,N) 双精度浮点数类型
- varchar(size) 可变长度字符串
- datetime 日期类型
3. 表操作 (前提,use 数据库名;)
前提:需要操作数据库中的表时,要先选中(使用)该数据库:
如果不选中:
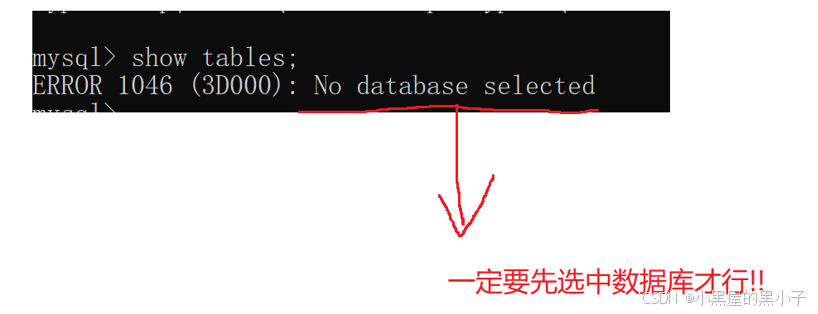
3.1 查看数据库中的表 (show tables)
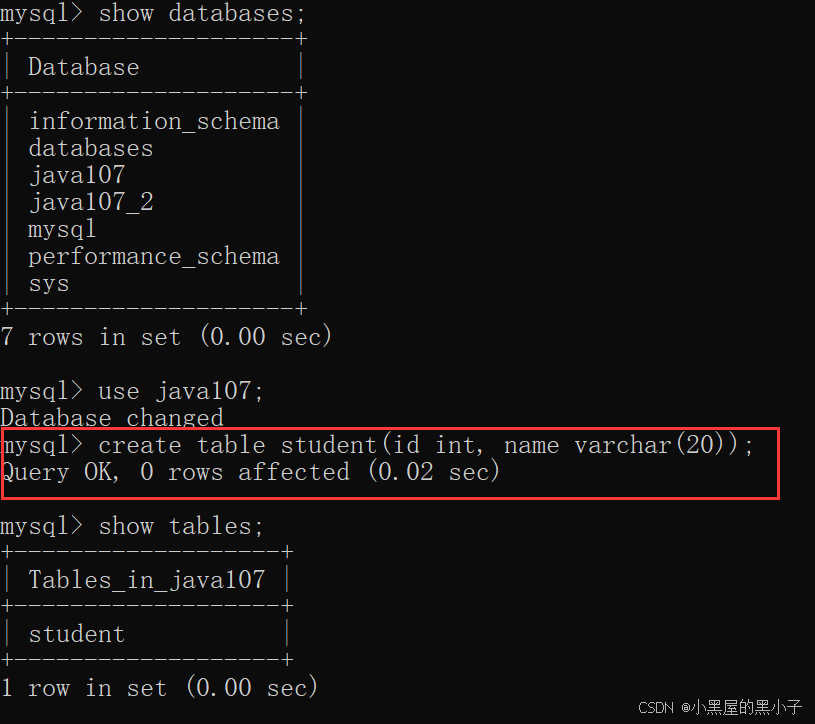
查看当前数据库中的所有表

3.2 创建表 (create table 表名(列名 类型......))
- 列的名字在前,类型在后 (违背日常的编码习惯的)
- C, Java 类型 变量名 = 0;其实有些编程语言,就是把类型放后面。例如,Python,Go,C++(部分场景),C++是世界上公认的语法最复杂的编程语言。

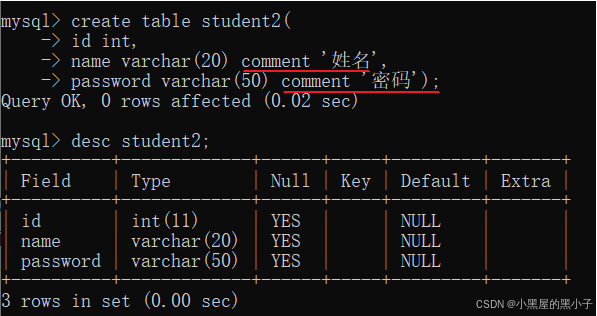
使用 -- 、 # 或者 comment 作为注释。注释只是在源码中存在,并不会在数据库中保存起来。
comment这个注释不太好用,只能在创建表的时候用。
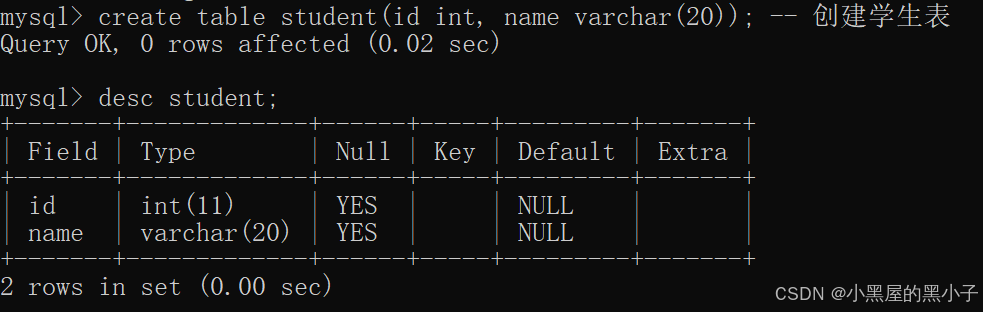
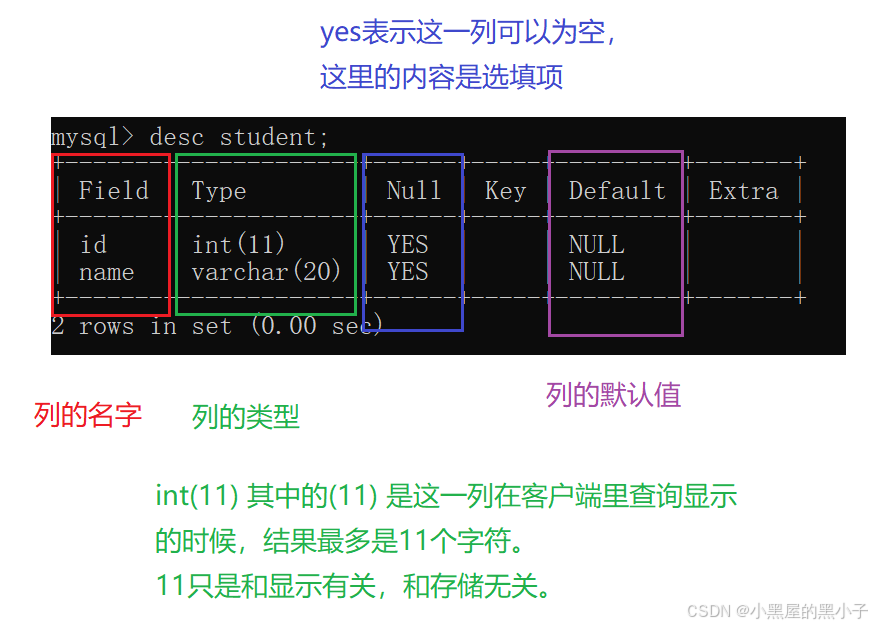
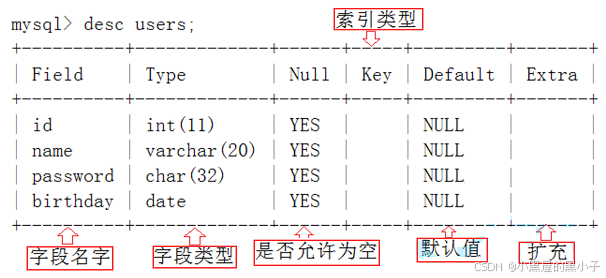
3.3 查看指定表的结构 (desc 表名;)
- desc -> describe的缩写。(描述一个表的特征)
- describe(其实mysql里也有一个关键字,就是describe )
int(11)其中的(11)是这一列在客户端里查询显示的时候,结果显示最多是11个字符。11只是和显示有关,和存储无关。
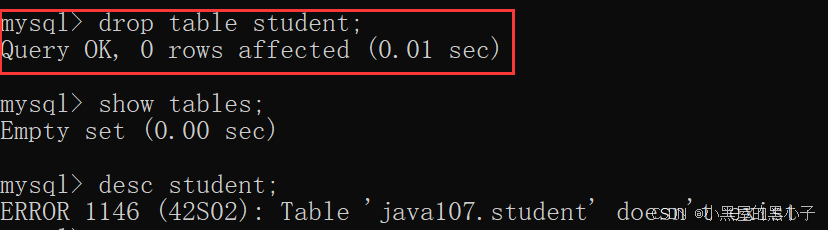
3.4 删除表 (drop table 表名;)
- IF EXISTS 判断数据库中是否存在,意思是如果存在
- 删除表甚至比删除库更很危险,进行数据库操作一定一定要谨慎再谨慎。
- 备份,写数据库的时候写多份,设置权限,能够一定程度的解决上述问题.


总结语句
对数据库操作:
- show databases; 查看数据库
- create database 库名; 创建数据库
- use 库名; 选中数据库
- drop database 库名; 删除数据库
对表操作: 前提先选中数据库
- show tables; 查看表
- create tables 表名 (列名 类型, 列名 类型 ....); 创建表
- desc 表名; 查看指定表结构
- drop table 表名; 删除表
常用数据类型:
- int 整型
- long 长整型
- double(M,N) 双精度浮点数类型
- decimal(M,N) 双精度浮点数类型
- varchar(size) 可变长度字符串
- datetime 日期类型
练习
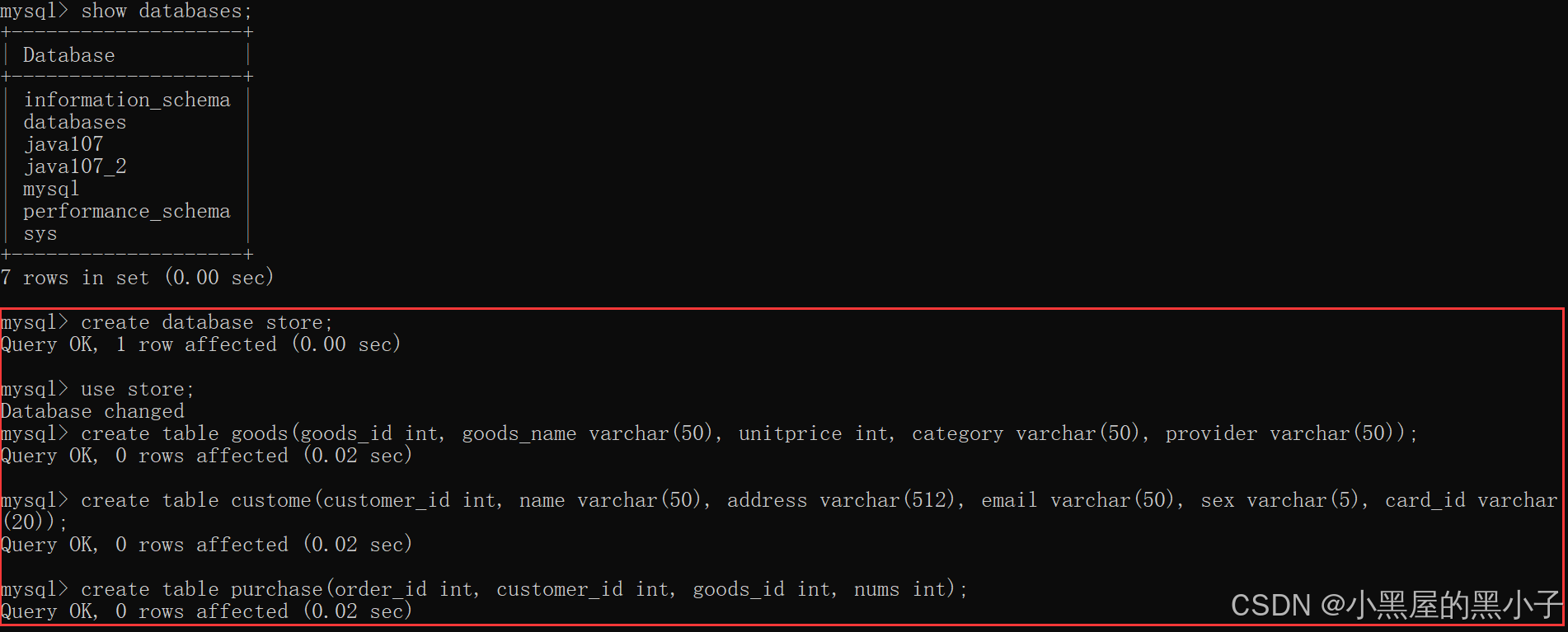
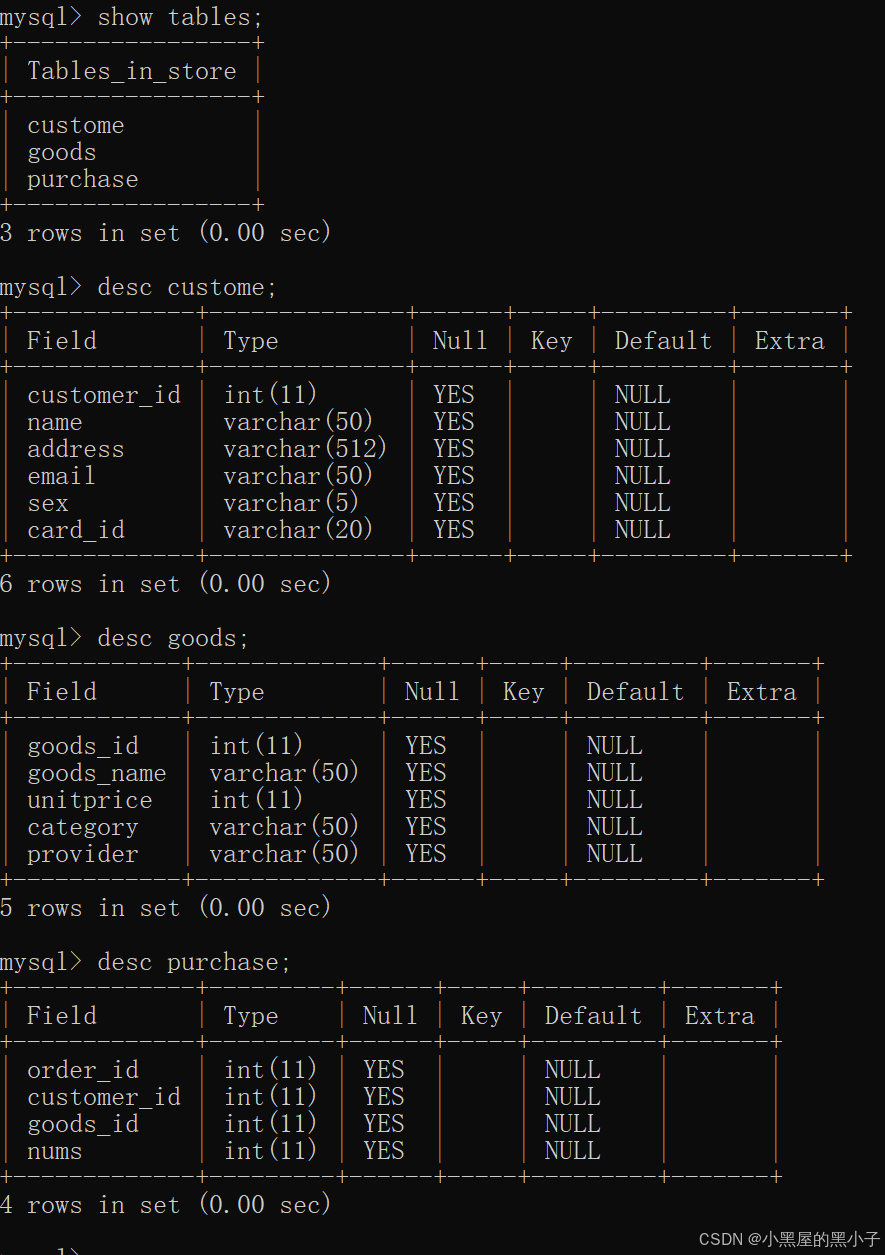
有一个商店的数据,记录客户及购物情况,有以下三个表组成:
- 商品goods(商品编号goods_id,商品名goods_name,单价unitprice,商品类别category,供应商provider)
- 客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证card_id)
- 购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
注意事项:
- 单价使用啥类型表示? double (3,1) 不精确 。decimal是更好的选择 (更精确) ,但是会降低速率。
- 此处更好的选择是使用int 可以使用 分 为单位。 元 角 分。上面数值类型中有解释。
- 有些字段,看起来是数字,实际上是字符串。像身份证,虽然是由数字构成的,但是这个数字不能够参与+ - * /算术运算,所以将身份证设置为varchar(N) 类型的
- 这里varchar(50)为什么是50,目前是拍脑门想出来的。这个具体多少,得看具体的需求(产品经理(PM)提出的)
好啦Y(^o^)Y,本节内容到此就结束了。下一篇内容一定会火速更新!!!
