vLLM高效部署Qwen2.5-VL系列视觉大模型:从推理优化到Dify社区版集成
vLLM高效部署Qwen2.5-VL系列视觉大模型:从推理优化到Dify社区版集成
- 前言 (为什么在vLLM部署Qwen2.5-VL系列)
- 一、vLLM安装Qwen2.5-VL系列
- 二、推理加速策略1:vLLM中使用flash attention推理加速
- 三、推理加速策略2:预处理Resize图像实现推理加速
- 四、Dify OpenAI-API-compatible上调用vLLM的Qwen2.5-VL 系列
- 五、社区版Dify的LLM推理平台选哪个?
前言 (为什么在vLLM部署Qwen2.5-VL系列)
去年,我在这个社区版Dify专栏上发布过一篇视觉大模型的博文。社区版Dify+Ollama+llama3.2-vision 实现多模态聊天 。这个大模型管理平台是Ollama,部署的视觉大模型是llama3.2-vision。实现的功能就是可以上存图像跟大模型多轮对话聊天。
但是,我发现有些问题,在一些需要读取其中文文本的(中文OCR)时候,llama3.2-vision并不出色,并且它大概是11b的模型,在Ollama 平台上推理并不算快。而vLLM推理平台可以支持多并发的需求,更重要的是,Ollama 目前并不支持推理Qwen2.5-VL系列(官方的版本)。
视觉多模态模型的最主要最主要的一个功能是(图像/视频内容理解) Image caption & Video caption。推理速度的需求也是存在,因此本篇博文主要介绍 vLLM部署Qwen2.5-VL,并且发布到Dify 平台上使用,其次,分享一些可以推理加速的经验。
Qwen2.5-VL-7B-Instruct 单卡推理实现效果:
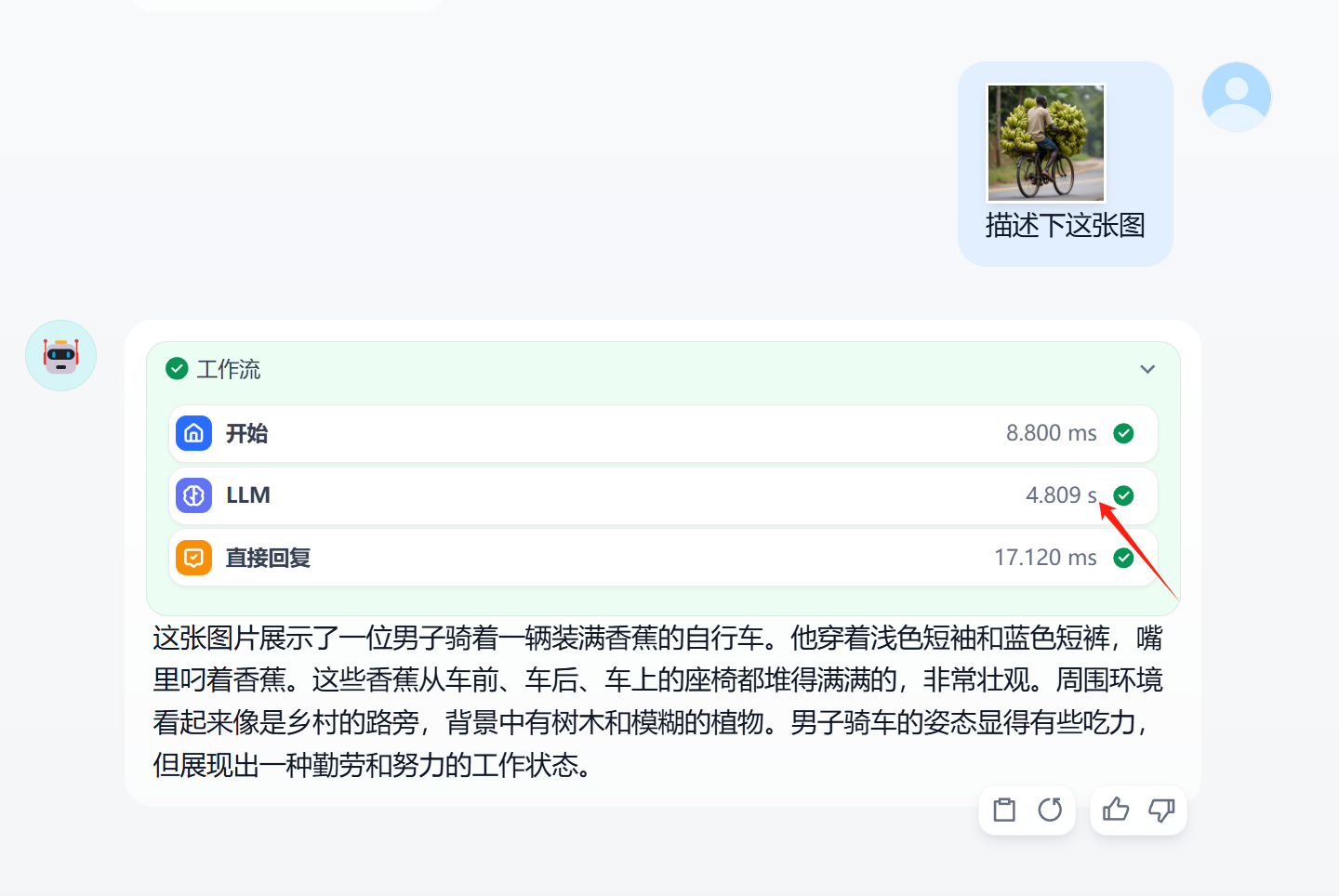
一、vLLM安装Qwen2.5-VL系列
主要是参考这个Qwen2.5-VL 系列vLLM部署官方Github 仓库,我的建议是建立conda 虚拟 环境,直接安装就行。
然后按照其中步骤,实现推理和安装就行。
由于vLLM的推理只要是发布一个API,官方的教程是这样的。你可以部署这几个系列模型:
- Qwen/Qwen2.5-VL-3B-Instruct
- Qwen/Qwen2.5-VL-7B-Instruct
- Qwen/Qwen2.5-VL-32B-Instruct
- Qwen/Qwen2.5-VL-72B-Instruct
以下是以Qwen/Qwen2.5-VL-7B-Instruct 在vLLM发布API的例子:
vllm serve Qwen/Qwen2.5-VL-7B-Instruct --port 8000 --host 0.0.0.0 --dtype bfloat16 --limit-mm-per-prompt image=5,video=5
命令解释:
- port是web 端口;
- host是设置允许访问的主机IP;
- dtype bfloat16 是设置为混合精度;提高推理速度;
- limit-mm-per-prompt image=5,video=5 是设置单次聊天中最多的图像和最多的视频数目。
经常遇到的两个问题:
下载模型的网络问题和指定卡推理的问题,因此你可以在命令行上加上指定的HF镜像网站,和指定的显卡运行,如:
sudo CUDA_VISIBLE_DEVICES=2 HF_ENDPOINT=https://hf-mirror.com vllm serve Qwen/Qwen2.5-VL-7B-Instruct --port 8000 --host 0.0.0.0 --dtype bfloat16 --limit-mm-per-prompt image=5,video=5
如果你需要多卡推理和多卡使用,请参考:
sudo CUDA_VISIBLE_DEVICES=2,3 HF_ENDPOINT=https://hf-mirror.com vllm serve Qwen/Qwen2.5-VL-7B-Instruct --port 8000 --host 0.0.0.0 --dtype bfloat16 --tensor-parallel-size 2 --limit-mm-per-prompt image=5,video=5
安装完成后,按照官方的测试代码来测试即可实现,如有特殊的vLLM 的问题可以参考 vLLM官方的使用指南,这里有更详细的说明。
二、推理加速策略1:vLLM中使用flash attention推理加速
在vLLM 中,我们可以使用Flash attention 推理加速,链接在这里。

我在第一次运行 vllm serve … 命令的时候,出现了 一个warning:
WARNING 04-01 15:36:33 [vision.py:97] Current `vllm-flash-attn` has a bug inside vision module,
so we use xformers backend instead. You can run pip install flash-attn to use flash-attention backend.
也就是说建议我使用xformers backend 的flash-attention 来推理加速。
pip install flash-attn
然后重新启动 vllm serve ,即可在推理中得到加速,注意当你安装这个库文件之后不用在命令行添加任何flash attention 的命令了,也就是说, vllm 是间接地在xformers 上使用的flash-attention。
三、推理加速策略2:预处理Resize图像实现推理加速
首先,让我们先看一下 Qwen2.5-VL Technical Report 论文的创新点:
- 基于 Qwen2.5系列 LLM;
- 编码部分:动态分辨率 和 视频绝对时间编码;
- 引入window attention 从头开始训练 ViT;
- ViT之后,引入2层MLP再传到LLM(多尺寸输入,动态压缩,而不是直接ViT输入!);
- …
我顺便讲一下ViT编码部分:
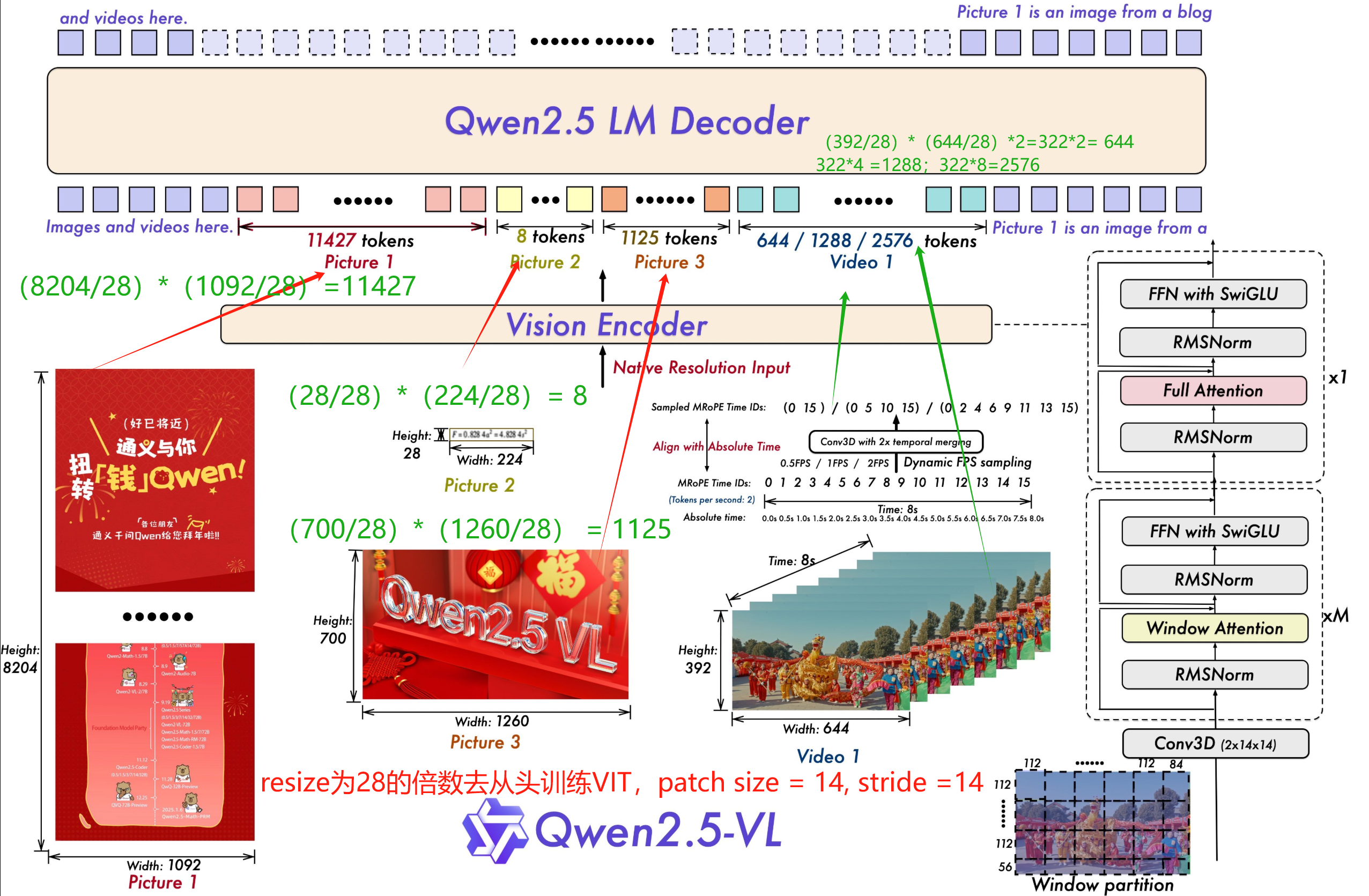
以上图像来自 Qwen2.5-VL官方论文,链接地址:https://arxiv.org/abs/2502.13923
这里说明下,Qwen2.5-VL 的ViT 编码需要统一尺寸为28的倍数,其pacth size 是14,stride是14,所以一张图的长宽都除以28,之后相乘就是tokens的数目! 而视频的采样,是在图像的基础上加上三组不同的帧率采样得到三种倍数增长的tokens。这会直接影响 Image Caption 速度,不管你用的是哪个模型,因为Qwen2.5-VL系列都用同一个ViT:
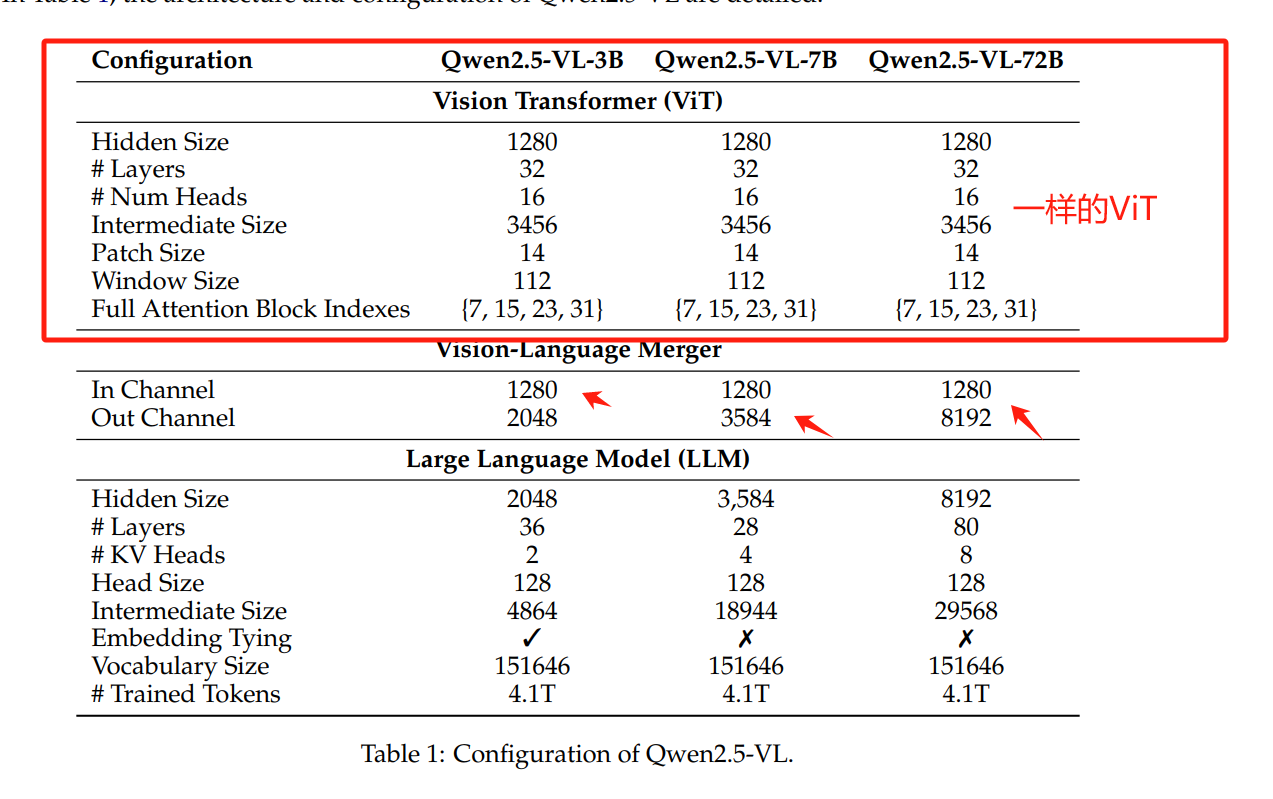
尽管Qwen2.5-VL是支持动态的分辨率输入,但是越大的图,Tokens越多,其次,可以顺便resize为28的倍数。因此我的推理加速策略,选取最大的图像分辨率,并且保持比例resize为28的倍数。
我的最大分辨率设置为1260,其中处理过程代码如下:
├── utils/
│ ├── resize_base64.py
├── main.py
resize_base64.py 代码:
import cv2
import base64
def resize_to_multiples_of_28_and_get_base64(image_path):# 读取图片if isinstance(image_path, str):# 如果输入是文件路径img = cv2.imread(image_path)else:# 如果输入是numpy数组img = image_pathif img is None:return "无法读取图片"# 获取原始图片尺寸height, width = img.shape[:2]# 设置最大尺寸max_dimension = 1260# 保持原始比例进行缩放if width > max_dimension or height > max_dimension:# 确定哪个维度超出了限制if width >= height:# 如果宽度是较大的维度new_width = max_dimensionnew_height = int(height * (max_dimension / width))else:# 如果高度是较大的维度new_height = max_dimensionnew_width = int(width * (max_dimension / height))else:# 如果两个维度都没有超过最大值,保持原始尺寸new_width = widthnew_height = height# 调整为28的倍数new_width = new_width - (new_width % 28) if new_width % 28 != 0 else new_widthnew_height = new_height - (new_height % 28) if new_height % 28 != 0 else new_height# 确保尺寸至少为28x28new_width = max(28, new_width)new_height = max(28, new_height)# 调整图片大小resized_img = cv2.resize(img, (new_width, new_height))print(new_width, new_height)# 转换为base64_, buffer = cv2.imencode('.png', resized_img)encoded_image = base64.b64encode(buffer)encoded_image_text = encoded_image.decode("utf-8")return f"data:image;base64,{encoded_image_text}"
main.py 代码:
from openai import OpenAI
from utils.resize_base64 import resize_to_multiples_of_28_and_get_base64
import time
import cv2
openai_api_key = "EMPTY"
openai_api_base = "http://ip addr:port/v1/" # vllm
client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)
t0 = time.time()
image_path = r"./995.jpg"
print(cv2.imread(image_path).shape)
base64_qwen = resize_to_multiples_of_28_and_get_base64(image_path)chat_response = client.chat.completions.create(model="Qwen/Qwen2.5-VL-7B-Instruct",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user","content": [{"type": "image_url","image_url": {"url": base64_qwen},},{"type": "text", "text": "简要地描述这张图?"},],},],
)
print("Chat response:", chat_response)
content = chat_response.choices[0].message.content
print(content)
print(time.time()-t0)
一张分辨率为6000*8000的图,在没有经过resize时, Qwen/Qwen2.5-VL-7B-Instruct 识别需要8.56秒 :

同一张图,而经过resize 处理后的图分辨率是840 *1260,Qwen/Qwen2.5-VL-7B-Instruct 识别时间是1.98秒:
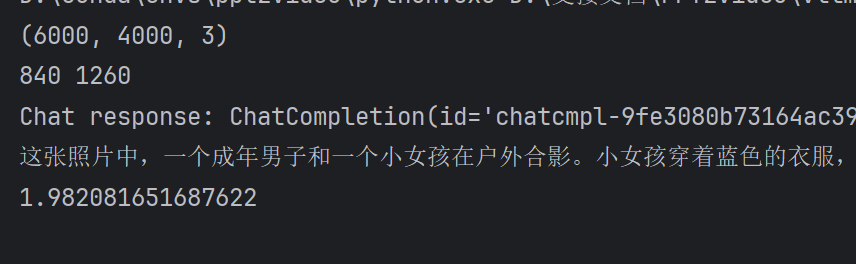
经过resize 到范围内的图,明显可以提高Image Caption 的速度!
四、Dify OpenAI-API-compatible上调用vLLM的Qwen2.5-VL 系列
在0.14.0 版本的Dify上暂时还没有支持vLLM 的插件,而在1.1.3版本的Dify上 vLLM插件不能正常调用模型。怎么办,非常简单,Dify 上的OpenAI-API-compatible完全支持调用vLLM,换句话说,vLLM可以按照OpenAI 那套交互协议来调用API。
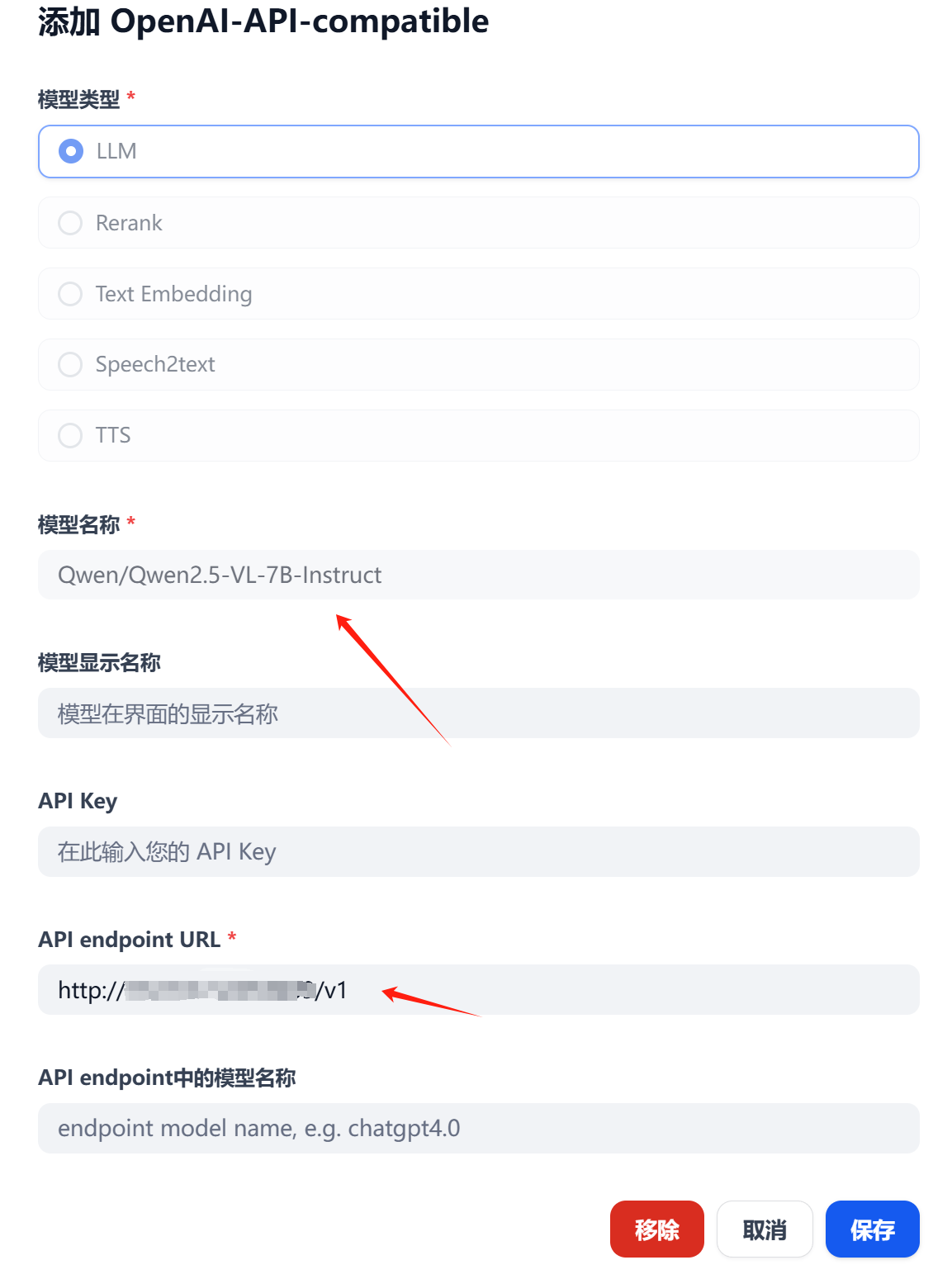
当然啦,要在下面选择支持vision:

最后,Dify 的工作流很快就能实现了:

五、社区版Dify的LLM推理平台选哪个?
我之前的文章发布了Dify 的LLM推理平台都是Ollama,这里主要介绍了vLLM,该如何做选择?这里给你提供参考:
- vLLM:
依赖NVIDIA GPU,显存占用较高,支持动态批处理和千级并发请求,适合处理大规模推理任务。显存占用固定,需为峰值负载预留资源,适合高并发、低延迟的企业级应用场景。 - Ollama:优化了单次推理速度,但并发处理能力有限,能动态调整资源占用,空闲时释放显存,适合个人开发者和小规模实验场景的本地化。
如本文内容对你有帮助,请点赞支持原创,欢迎留言和私信讨论。