OminiAdapt:学习跨任务不变性,实现稳健且环境-觉察的机器人操作
25年3月来自中科大、北理工和中科院自动化所的论文“OminiAdapt: Learning Cross-Task Invariance for Robust and Environment-Aware Robotic Manipulation”。
随着具身智能的快速发展,利用大规模人体数据对人形机器人进行高水平的模仿学习,成为学术界和工业界关注的焦点。然而,由于人形机器人感知和控制过程的复杂性、人形机器人与人类在形态和驱动机制上的长期物理差异以及缺乏从自我中心视觉中获取的任务相关特征,将人形机器人用于精准操作领域仍然具有挑战性。针对模仿学习中的协变量漂移问题,本文提出一种适用于人形机器人的模仿学习算法。通过聚焦主要任务目标,过滤背景信息,并结合通道特征融合和空间注意机制,该算法抑制环境干扰,并通过动态权重更新策略,显著提高人形机器人完成目标任务的成功率。
如图所示学习的机器人操作例子:

近年来,人形机器人和具身智能的发展进展迅速。然而,让这些机器人在非结构化环境中自主决策和完成任务仍然存在重大挑战 [12]。在这些复杂性中,机器人上半身的灵巧操作是一个关键方面,因为人形机器人必须了解周围环境、自主决策并有效地利用机械系统和控制装置执行任务。
最近,已经提出了几种方法来解决机器人决策操作任务的挑战。这些方法包括真实机器人的强化学习、模拟中的强化学习和真实机器人的模仿学习。其中,真实机器人模仿学习因其在学习特定操作任务方面的效率而备受关注,因为它消除了弥合模拟和现实世界部署之间差距的需要。例如,Mobile ALOHA [5] 引入动作分块 Transformer (ACT) 算法,该算法将动作序列划分为固定长度的块(例如,50 步动作块),并使用 Transformer 模型来预测这些动作块。此方法降低顺序建模的复杂性,同时保持轨迹连贯性。此外,HumanPlus [4] 开发一种称为 HIT 的仅解码器策略,该策略通过利用真实人形机器人上的分层控制架构,以最少的人类演示数据实现低成本的操作任务学习。
尽管取得了这些进步,但关键瓶颈阻碍人形机器人模仿学习的实际部署。例如,作为模仿主要感官输入的自我中心视觉,易受动态背景杂波和目标物体变化的影响,导致特征提取不一致和感知域发生变化。其次,训练模拟和现实环境之间的物理差异会导致动作执行错误,因为在理想模型上训练的策略无法解释现实世界的动态。第三,传统的规范化化技术(如针对固定训练分布进行优化的批量规范化)难以实时适应新条件,导致在线操作期间的性能下降。感知鲁棒性、物理一致性和动态适应性方面相互交织的挑战,共同限制人形机器人模仿学习框架的可扩展性和可靠性。
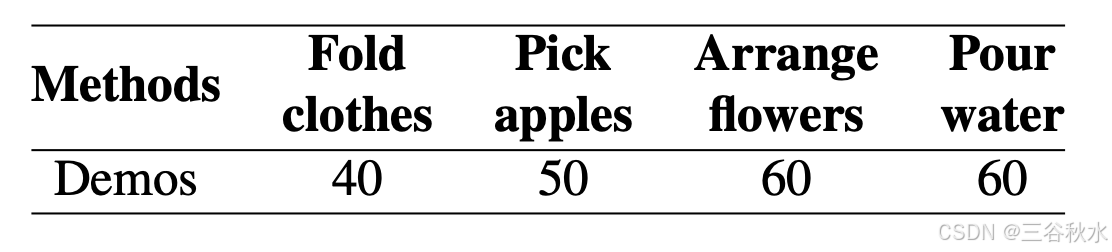
为了解决这些问题,本文为人形机器人提出一个 OminiAdapt 的多模态自适应模仿学习框架。
为了应对模仿学习对环境的高度敏感性以及为新任务重新训练的巨大成本,提出基于模仿学习的机器人策略架构 OminiAdapt,如图所示。系统采用 N 个摄像头(默认 N = 3 个,位于头部、胸部、手腕等处)以 30 Hz 的频率捕获同步图像流 {I_tvi}。当机械臂的运动能量超过 0.1 时,触发有效帧采集,确保采样效率。给定当前时间 t 的不同 RGB 摄像头视图和机器人本体感受 s_t = [q_tarm,θ_t^hand],OminiAdapt 预测机械臂和手轨迹的下一步 T 步。以下详细描述。
首先,用任务解释器模块和零样本语义分割模块初始化图像预处理,后续图像 {I_tvi} 使用前一时刻的掩码图像作为查询图像,通过连续目标跟踪生成掩码 {M_t^vi}。
其次,使用具有冻结卷积权重和可训练动态批量归一化(BN)层的ResNet18主干网络,处理掩码图像,提取特定视图的特征 {F_t^vi},从而更快地将学习迁移到新任务。
第三,这些特征图通过名为CBAM [20]的通道空间注意模块进行增强,这有助于在面对不同环境干扰时提高策略稳健性,即使环境只有很小的变化,也无需收集大量数据。
增强的多视图特征被聚合在一起。最后,融合特征 F_tin = Concat(F_t3D, F_tpro) 被输入到 Transformer 解码器中,预测 T 步未来动作 {τ_t+kpred},其中 F_t^pro = MLP (s ) 是时刻 t 的嵌入式机器人本体感受。遵循 [5],采用分块预测来实现时间连贯性。
Transformer 解码器输出由定义损失所优化的动作,由两个项组成:一个是轨迹精度,另一个是速度不连续性。指数衰减因子 0.95^T−k 实现课程学习。
用于视觉预处理的连续目标跟踪
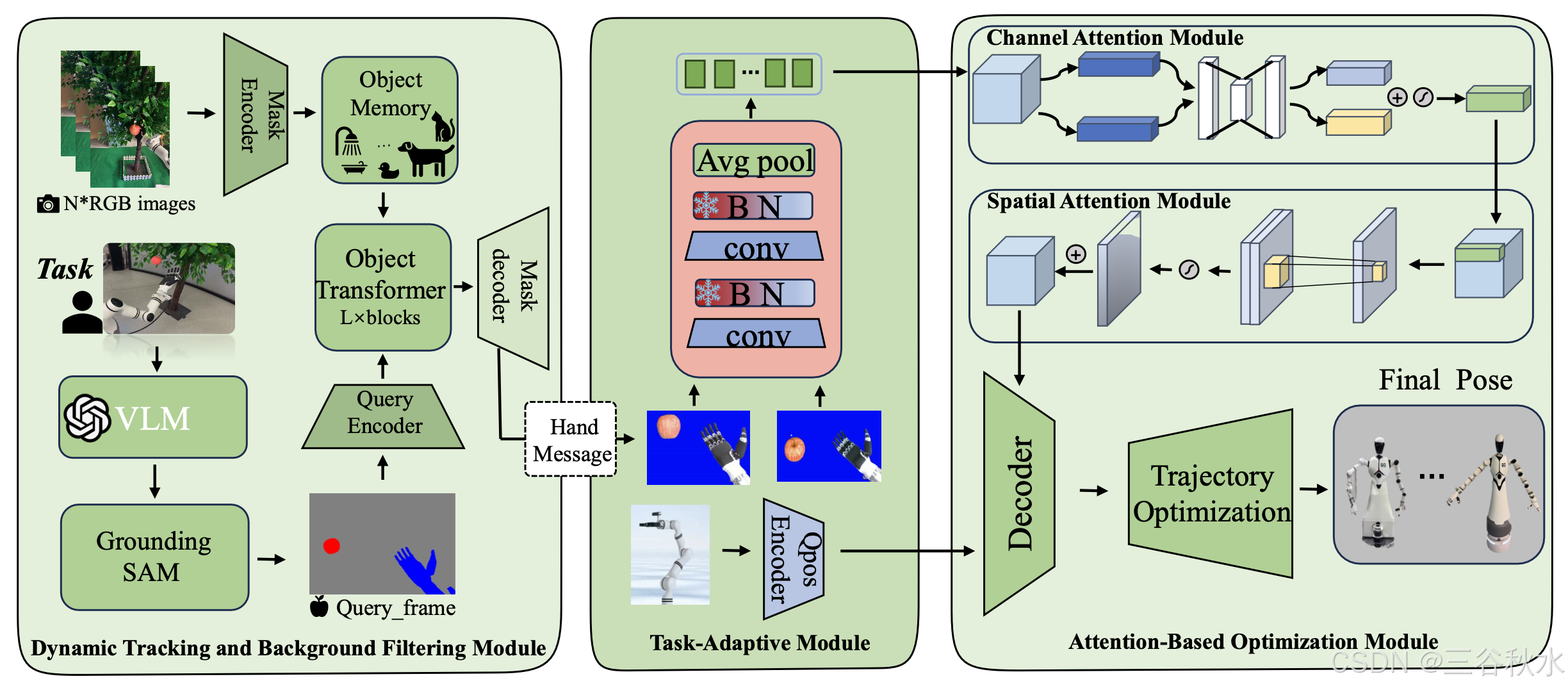
在预处理中,所有视图中的第一帧图像使用任务解释器模块和 GroundingSAM [16](ViT-B 主干)进行零样本语义分割初始化,以进行目标定位,后续帧通过 Cutie 跟踪器 [1] 进行连续目标跟踪和掩蔽处理。如图所示,多模态大模型的输入,由不同任务场景的摄像机拍摄图像和相应的任务描述组成。该模型从不同视角识别图像中机器人最需要关注的目标或元素,并生成基于文本的提示。
基于此操作,提出一种自动关键元素提示的生成范式。给定这些生成的文本提示,使用 GroundingSAM 对各个视角的初始帧图像 I_0v 进行零样本语义分割,生成相应的掩码 M_0v = GroundingSAM(I_0^v , T) 以初始化图像预处理。然后将当前图像用作后续帧的查询帧,并进行目标跟踪、分割和掩码处理的连续循环。后续帧通过增强的CUTIE跟踪器处理,以执行连续的目标级跟踪和分割。此过程不仅可以过滤掉背景干扰,而且形态扩张(r = 15 像素)还可以扩大手部掩码以实现遮挡稳健性,即使被树叶或衣服等物体遮挡,也可以尝试保留机械臂和手的边缘信息。为了确保不同视点之间的一致性,应用视图间一致性约束,这迫使几何变换后不同视图之间的掩码高度对齐。
动态自适应批量规范化 (DABN)
特征提取架构由预训练的特征提取模块和通道空间注意模块组成,以增强对手与物体交互的关注。主干网络采用动态自适应批量规范化 (DABN) 设计,是一个冻结的多视图共享权重 ResNet18(在 ImageNet 上预训练),其中只有主干中的 BN 层被激活以在特定于任务的训练期间进行联合微调。这种 DABN 设计允许主干缩小不同任务之间的差距,同时共享卷积层参数并调整 BN 参数以轻松启动和快速适应新任务,减少训练时间和资源消耗,并提高策略可转移性和环境适应性。每个任务策略都维护自己的一组独立的 BN 参数 {μ_k,σ_k,γ_k,β_k}。
经过整体训练后,任务特定的嵌入向量 e_task 被路由来选择 BN 参数。
多维注意机制
从不同视角提取的特征通过通道空间注意模块,采用[20]中的CBAM模块,该模块可以抑制与任务无关的干扰,高频噪声和不相关的颜色通道,并有助于关注手和目标之间的空间关系,特别是在交互区域,优化物体轮廓和手部部位。通道注意机制,侧重于抑制不相关的特征通道,提高模型对高频噪声(例如机器人反射)的抵抗力,它通过双路径池化(GAP和GMP)计算权重α_c。空间注意机制,通过卷积层生成热图,使策略能够更好地学习手和任务目标之间的空间关系,关注手与物体交互中的细节,从而有效提高其处理背景干扰的能力并增强鲁棒性和环境适应性。
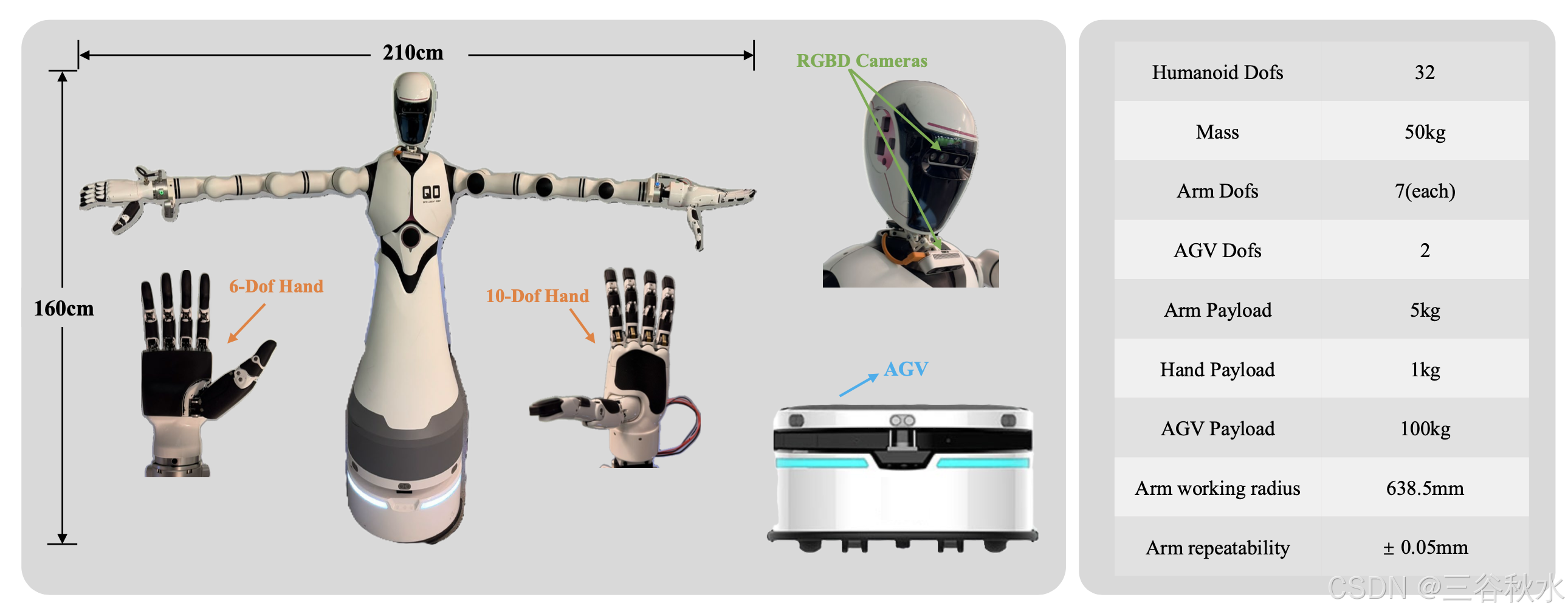
双臂移动机器人,由一个 AGV 底盘和一对配备不同灵巧手 7 自由度机械臂组成。机械臂是 Realman 的 RM75-6F 轻型人形机械臂,集成六轴力传感器。右臂配备 Inspire 的 RH56DFX 灵巧手,左臂配备 LinkerHand 的 L10 灵巧手,具有十个活动自由度。双手通过串行通信控制。AGV 底盘是 YUNJI 的 WATER2 号。所有组件都通过以太网连接到 NVIDIA Jetson Orin。机器人的头部、颈部和右手配备三个 RGB 摄像头(Intel RealSense D435i)。Inspire 灵巧手可以施加最大 10 N 的力,而 LinkerHand L10 通过其多自由度设计提供增强的操控能力,并在所有五个指尖上都配有触觉传感器。手臂的额定有效载荷为 5 公斤。
下图显示机器人示意图。在未来的工作中,计划充分利用 LinkerHand 的触觉数据来进一步改进方法。
在对比实验中,在折叠衣服场景中为每个任务收集 40 个数据样本,在摘苹果场景中收集 50 个训练样本。对于更具挑战性的任务,例如倒水和插花收集了 60 个数据样本,如表所示。通过 20 次实验运行来评估每个场景以比较成功率。在消融实验中,每个任务尝试 10 次,每次试验都分析逐步成功率和最终成功率。此外,对于多场景泛化任务,使用不同的数据分布率在不同场景中进行了实验以进行测试。