深入理解PCA降维:原理、实现与应用
1. 引言
在机器学习与数据科学领域,我们经常会遇到高维数据带来的"维度灾难"问题。随着特征数量的增加,数据稀疏性、计算复杂度等问题会显著加剧。主成分分析(PCA, Principal Component Analysis)作为一种经典的降维技术,能够有效解决这一问题。本文将全面介绍PCA的原理、数学基础、实现方法以及实际应用。
2. 概念
2.1 PCA的定义
PCA是一种通过线性变换将高维数据投影到低维空间的统计方法,其核心思想是在保留数据主要特征的同时降低数据维度。PCA通过找到数据方差最大的方向(主成分)来实现这一目标。
2.2 PCA的应用场景
- 数据可视化:将高维数据降至2D/3D便于可视化
- 特征提取:减少特征数量,提高模型效率
3. 原理
3.1 向量内积
内积:
![]()
A与B内积:
![]()
3.2 基与基变换
基也称基底,是描述向量空间的基本工具。任意两个线性无关的二维向量都可以作为一组基底。
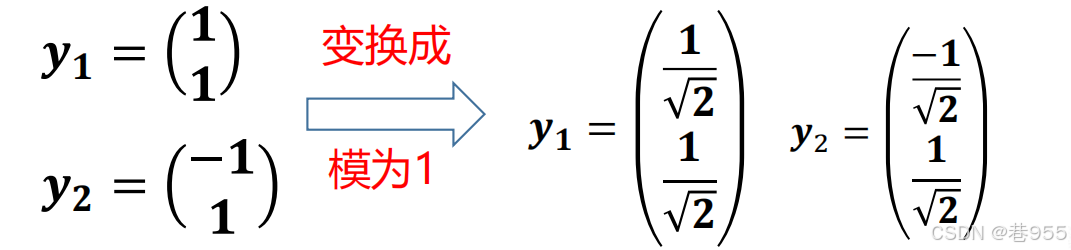
定义一组新的基底 y1 、y2,并将坐标点(3,2)映射到新的基底中,如下所示:
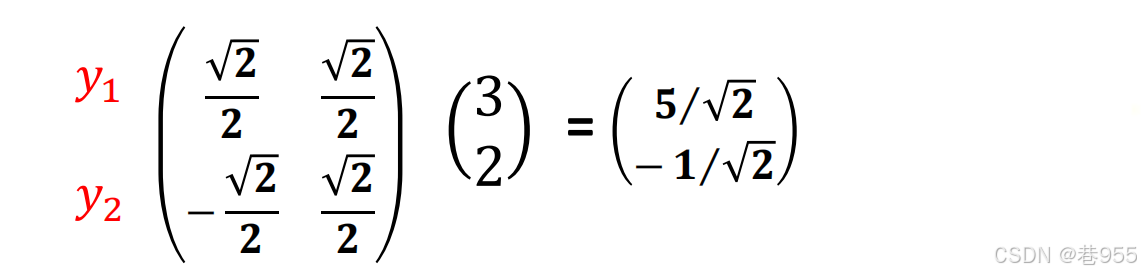
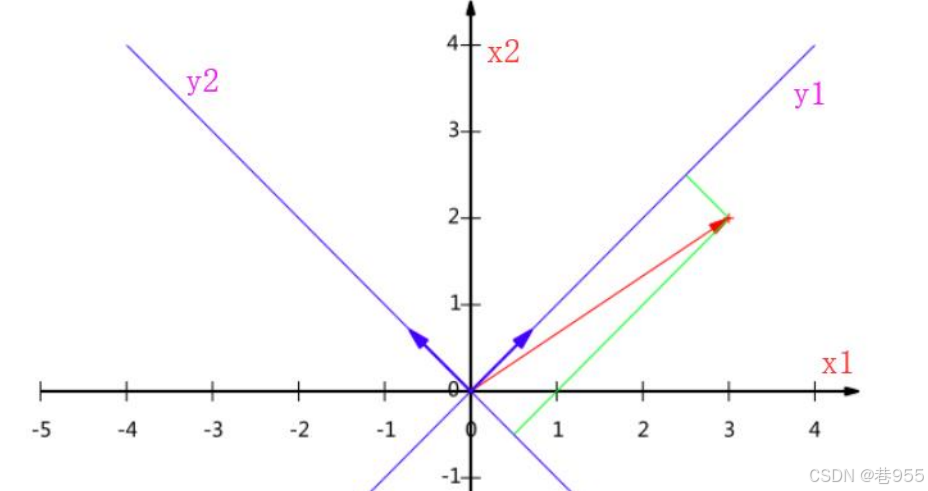
几何坐标如下所示:
将其推广到多维,如下所示:
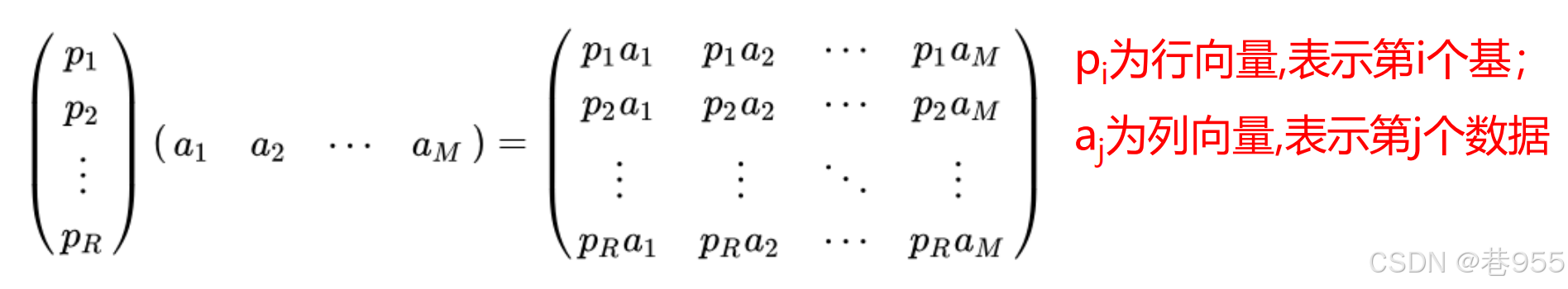
从抽象角度来说来说,基变换就是将一个坐标映射到另一组基底中,而因此产生的线性变换。
3.3 选择最优基
为了找到最优的基底,我们要寻找到一组基,使得所有的点映射后,所产生的方差最大。代表着点越离散,丢失的点越少。(对于二维降到一维来说)
方差:
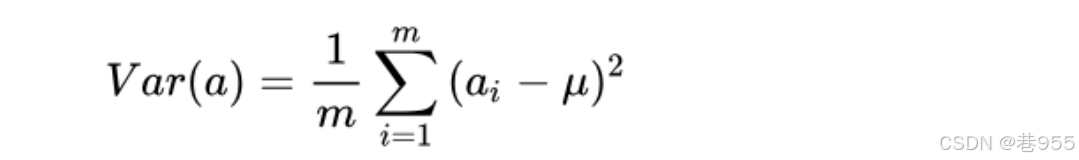
而对于三维降到二维,仅仅一个基底是不够用的,我们需要找到两个线性无关的基。通过协方差找到最优一组基。
协方差:

协方差为0时,两个字段完全独立。而我们利用这一特性来找到另一组基,因此两个基一定是正交的。
推广:
协方差矩阵:

方差:
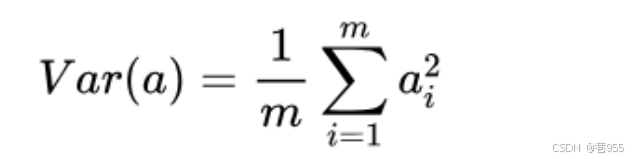
协方差:
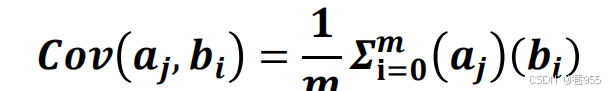
3.4 协方差矩阵对角化
基于上述思路,我们可以知道,想要找到最优基,就是找到一组除主对角线以外全为0的对角矩阵。因此,我们对协方差矩阵进行对角化。(协方差矩阵为实对称矩阵,一定可以相似对角化)。
对角化的原理即求特征值与特征向量。即: ![]() = 0 。求出特征值后,带回原矩阵,求出特征向量。单位后,则求出最优基。
= 0 。求出特征值后,带回原矩阵,求出特征向量。单位后,则求出最优基。
4. 代码
导入相关库,读取数据,并将特征与标签分离:
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA#导入数据
datas=pd.read_excel('电信客户流失数据.xlsx')
data=datas.iloc[:,:-1]
target=datas.iloc[:,-1]重新划分训练集与测试集
from sklearn.model_selection import train_test_split
data_train,data_test,target_train,target_test=\train_test_split(data,target,test_size=0.2,random_state=20)寻找决策树的最优深度:
from sklearn.model_selection import train_test_split, cross_val_score
scores = []
depth_param_range = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]
for i in depth_param_range:dtr = tree.DecisionTreeClassifier(criterion='gini',max_depth=i,random_state=42)score = cross_val_score(dtr,data_train,target_train, cv=6, scoring='recall')score_mean = sum(score) / len(score)scores.append(score_mean)# print(f"当depth={i}时,召回率 Recall为: {score_mean}")best_c = depth_param_range[np.argmax(scores)]
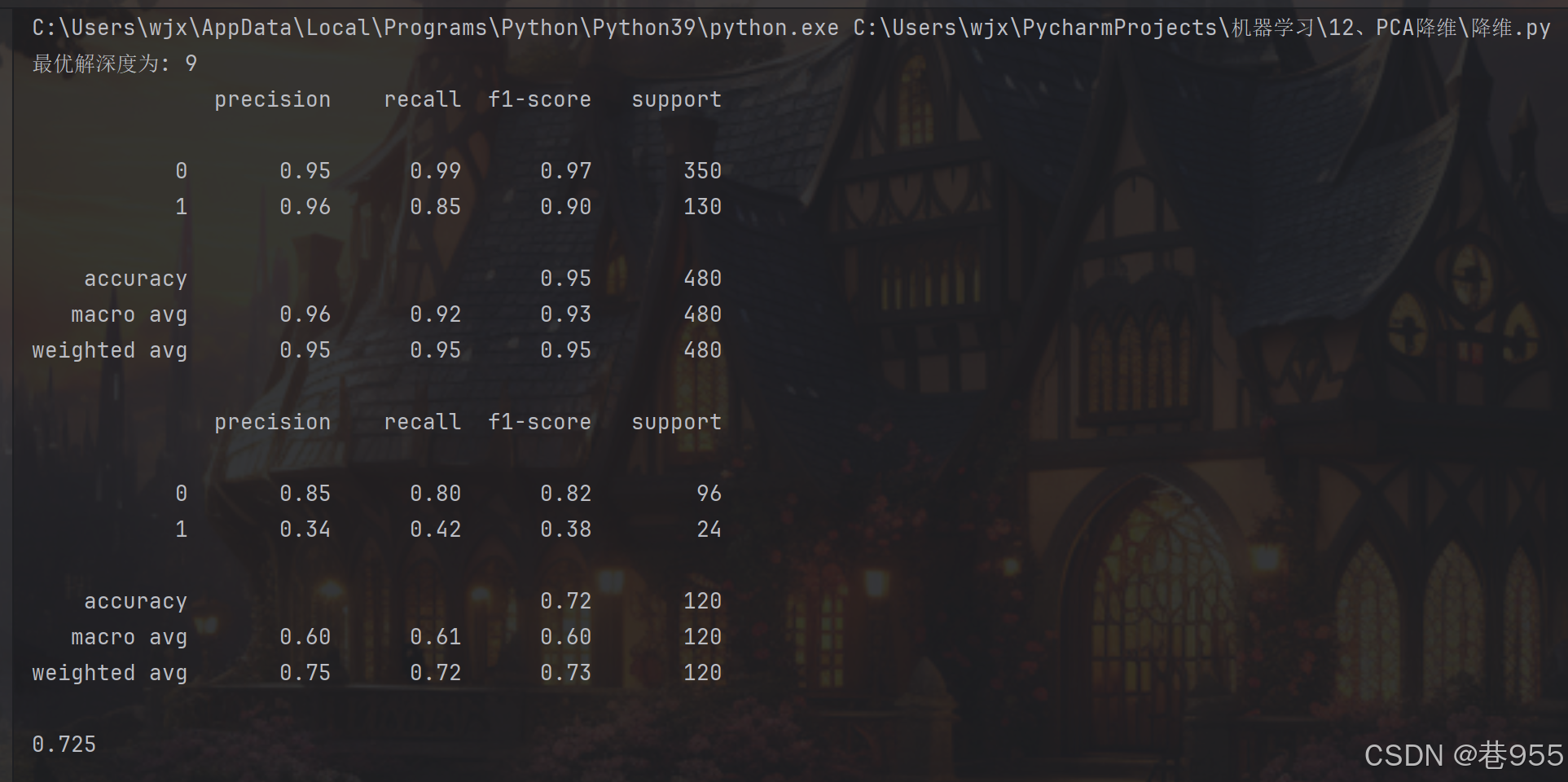
print(f"最优解深度为: {best_c}")用决策树算法训练数据:
dtr = tree.DecisionTreeClassifier(criterion='gini',max_depth=best_c,random_state=42)
dtr.fit(data_train,target_train)测试模型训练效果:
from sklearn import metricstrain_predicted=dtr.predict(data_train)
print(metrics.classification_report(target_train,train_predicted))
# cm_plot(target_train,train_predicted).show()test_predicted=dtr.predict(data_test)
print(metrics.classification_report(target_test,test_predicted))
# cm_plot(target_test,test_predicted).show()
dtr.score(data_test,target_test)print(dtr.score(data_test,target_test))结果如下:
PCA降维:创建PCA对象,并拟合模型
pca = PCA(n_components=0.9) # 初始化 PCA,保留 90% 的原始数据方差
pca.fit(data) # 在整个数据集(data)上拟合 PCA(计算主成分)# 打印 PCA 解释的方差信息
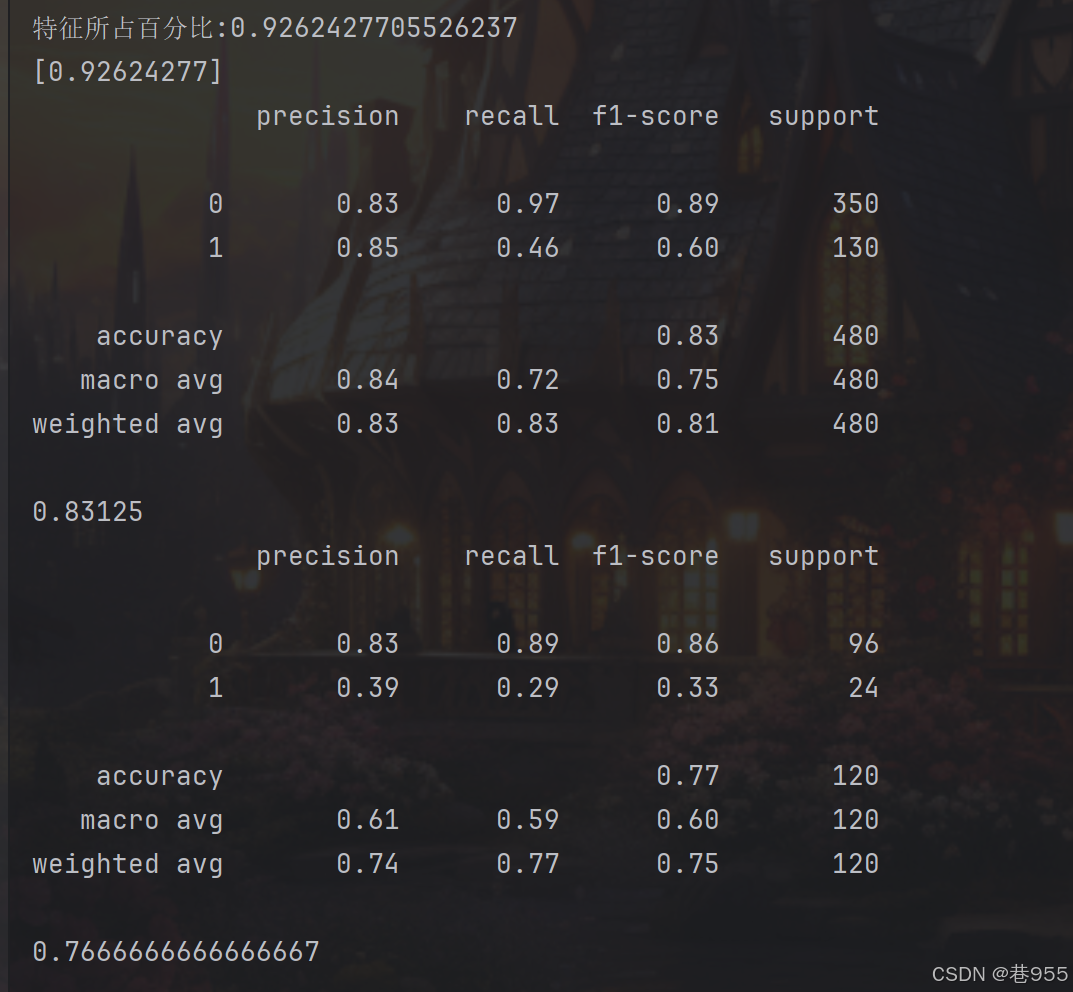
print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_))) # 累计方差占比(应≈90%)
print(pca.explained_variance_ratio_) # 每个主成分的方差贡献率对数据降维后重新训练并评估:
new_x_train = pca.transform(data_train) # 对训练集降维
dtr.fit(new_x_train, target_train) # 用降维后的训练数据训练决策树# 在训练集上预测并评估
new_x_train_predicted = dtr.predict(new_x_train)
print(metrics.classification_report(target_train, new_x_train_predicted)) # 分类报告(精确率、召回率、F1等)
print(dtr.score(new_x_train, target_train)) # 准确率(Accuracy)对测试集也进行降维,并预测评估:
new_x_test = pca.transform(data_test) # 对测试集降维new_x_test_predicted = dtr.predict(new_x_test) # 预测测试集
print(metrics.classification_report(target_test, new_x_test_predicted)) # 测试集分类报告
print(dtr.score(new_x_test, target_test)) # 测试集准确率运行结果如下:
完整代码如下:
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA#导入数据
datas=pd.read_excel('电信客户流失数据.xlsx')
data=datas.iloc[:,:-1]
target=datas.iloc[:,-1]from sklearn.model_selection import train_test_split
data_train,data_test,target_train,target_test=\train_test_split(data,target,test_size=0.2,random_state=20)from sklearn import tree# dtr = tree.DecisionTreeClassifier(criterion='gini',max_depth=None,random_state=42)
# dtr.fit(data_train,target_train)from sklearn.model_selection import train_test_split, cross_val_score
scores = []
depth_param_range = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]
for i in depth_param_range:dtr = tree.DecisionTreeClassifier(criterion='gini',max_depth=i,random_state=42)score = cross_val_score(dtr,data_train,target_train, cv=6, scoring='recall')score_mean = sum(score) / len(score)scores.append(score_mean)# print(f"当depth={i}时,召回率 Recall为: {score_mean}")best_c = depth_param_range[np.argmax(scores)]
print(f"最优解深度为: {best_c}")dtr = tree.DecisionTreeClassifier(criterion='gini',max_depth=best_c,random_state=42)
dtr.fit(data_train,target_train)from sklearn import metricstrain_predicted=dtr.predict(data_train)
print(metrics.classification_report(target_train,train_predicted))
# cm_plot(target_train,train_predicted).show()test_predicted=dtr.predict(data_test)
print(metrics.classification_report(target_test,test_predicted))
# cm_plot(target_test,test_predicted).show()
print(dtr.score(data_test,target_test))pca=PCA(n_components=0.9)
pca.fit(data)print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)new_x_train=pca.transform(data_train)
dtr.fit(new_x_train,target_train)new_x_train_predicted=dtr.predict(new_x_train)
print(metrics.classification_report(target_train,new_x_train_predicted))
print(dtr.score(new_x_train,target_train))new_x_test=pca.transform(data_test)new_x_test_predicted=dtr.predict(new_x_test)
print(metrics.classification_report(target_test,new_x_test_predicted))
print(dtr.score(new_x_test,target_test))
5. 结论
PCA是一种强大而灵活的降维工具,在数据预处理、特征工程和探索性数据分析中有着广泛应用。理解PCA的数学原理有助于更好地调参和解释结果。虽然PCA有一些局限性,但通过核技巧、稀疏约束等扩展方法,可以适应更复杂的应用场景。