7.训练篇5-毕设
使用23w张数据集-vit-打算30轮-内存崩了-改为batch_size = 8

我准备用23w张数据集,太大了,这个用不了,所以

是否保留 .stack() 加载所有图片? | 情况 | 建议 |
|---|---|---|
| ✅ 小数据集(<2w张,图像小) | 想加快速度 | 可以用 |
| ❌ 大数据集(>5w张图) | Colab / 本地内存有限 | ❌ 不建议,容易爆 RAM |
| ✅ 你正在用 Dataloader | 说明已动态加载 | 不需要这段代码 |
网上经验
| 模型 | 图片大小 | batch_size 安全值(Colab Pro) |
|---|---|---|
| ViT-B/16 | 224×224 | ✅ 8 非常安全(推荐) |
| ViT-B/16 | 224×224 | ⚠️ 16 可能会炸(尤其 A100/T4) |
| ViT-S/16 | 224×224 | ✅ 16~32 都行 |
| ViT-Tiny / DeiT-Tiny | 224×224 | ✅ 32~64 可尝试 |
什么是“骨架图”?
我们说“骨架图”,就是指:
-
神经网络的“结构组成”
-
包括:每一层的类型(如
Conv2d,Linear,Transformer等) -
每层的参数维度(比如
Linear(768 → 29)) -
模型的前向传递路线(从输入 → 输出)
ViT-B/16 模型骨架图包含:
| 模块名 | 内容简介 |
|---|---|
conv_proj | 把图像分成 patch(切成小块),变成 768 维向量 |
encoder | 12 层 Transformer,每层包括 self-attention + MLP |
heads | 线性分类层:将最终特征 [768] 映射到你要的类别(比如 29) |
举个例子(完整流程):
如果你输入一张图片 img = [1, 3, 224, 224]:(1指batch_size)
-
conv_proj把它切成 16x16 的 patch(共 196 个 patch),每个 patch 映射为 768 维向量 -
Transformer 对 768 的向量做注意力建模(12 层)
-
取出第一个“分类 token”的输出,传给
Linear(768 → num_classes)num_classes=29,这里 -
输出结果为
[1, num_classes],比如[1, 29]
ViT 是一种用“文字处理的方式”来看图片的模型。
把图像当成一串“小块块”(Patch),就像文本中的“单词”,然后用 Transformer 来分析这些块的关系。
类比图像与文字:
| 文本(NLP) | 图像(ViT) |
|---|---|
| 单词 Word | 图像小块 Patch |
| 词向量 | Patch 向量(Embedding) |
| BERT 模型 | ViT 模型(结构几乎一样) |
输入图像:[B, 3, 224, 224]表示你输入的是 batch_size = B 张 RGB 彩色图像,分辨率为 224x224。│
【步骤1】Conv2d 分块 → Patch Embedding(patch 大小为 16x16)│ 得到 patch 数量:224/16 * 224/16 = 196个 patch(再加1个分类Token)│ 每个 patch 映射为 768维向量↓
总输入:[B, 197, 768] (197 = 196 patch + 1 cls_token)【步骤2】加上位置编码(告诉模型每个 patch 的位置)↓【步骤3】12 层 Transformer 编码器(每层都包含以下结构):├── LayerNorm├── Multi-head Self Attention(观察所有 patch 之间的关系)├── MLP(前馈网络:两个 Linear + GELU 激活)└── Residual(残差连接)↓【步骤4】取出第一个位置的输出(cls_token)↓【步骤5】传入全连接层(Linear(768 → 29)) → 输出分类结果
| 步骤 | 模块 | 输出 shape(假设 B=8) | 说明 |
|---|---|---|---|
| 输入图像 | img | [8, 3, 224, 224] | 一批图像 |
| Patch Embedding | conv_proj | [8, 768, 14, 14] | 用卷积切成 14x14 个 patch,每个是 768 维向量 |
| → Flatten + permute | .reshape() | [8, 196, 768] | 展平为 patch 序列:14×14 = 196 个 patch |
| 加 CLS token | cls_token + concat | [8, 197, 768] | 加 1 个 [CLS] 向量在开头,共 197 个 token |
| 加位置编码 | pos_embedding | [8, 197, 768] | 给每个 patch 一个位置信息(加法) |
Encoder Block × 12 层:
每层结构都一样,输入输出 shape 都是:
Layer input: [8, 197, 768] Layer output: [8, 197, 768]
说明:每层的输出仍然是 197 个 token(含CLS),每个 token 是 768 维特征。
最终输出阶段:
| 步骤 | 模块 | 输出 shape |
|---|---|---|
| 分类 token | x[:, 0, :] | [8, 768] → 取第1个CLS token |
| 全连接层 | Linear(768 → num_classes) | [8, 29](假设你要分29类) |
使用的ViT-B/16 模型
| 名字 | 含义 |
|---|---|
| ViT | Vision Transformer(图像版的 Transformer) |
| B | Base(中等模型大小,有 12 层 encoder) |
| 16 | Patch 大小为 16×16 像素 |
使用的步骤,新手小白
| 阶段 | 要做的事 | 示例代码 / 解释 |
|---|---|---|
| ① 加载预训练模型 | 使用 torchvision 的 vit_b_16 | ✅ 一行代码就能加载 |
| ② 修改输出层 | 替换为自己的分类数,比如 29 类 | model.heads.head = nn.Linear(768, 29) |
| ③ 预处理图像 | 必须是 224×224 大小,标准化 | 用 transforms.Resize + Normalize |
| ④ 训练模型 | 和 ResNet 一样用 dataloader | 训练 epoch,记录 loss 和 acc |
| ⑤ 保存 / 加载模型 | torch.save() + torch.load() | 保存好 .pth 文件 |
| ⑥ 预测一张图像 | 图像 → Tensor → 模型预测 | 用 softmax 和 argmax 得到分类结果 |
| ⑦ 可视化 attention(进阶) | 可选:叠图显示 ViT 看哪里了 | 用 attention map(可视化热图) |
只是做一个手势识别任务(而不是 ImageNet 等通用视觉任务),完全没必要用到全部 23 万张数据,使用的是预训练的 ViT(pretrained=True),你只需要每类几百到上千张图像,就能训练出一个效果不错的模型。
用 ViT-B/16 训练 batch_size=8 的一轮(epoch)
在 A100 上 大约每 step 0.05 - 0.08 秒(视数据加载效率不同)
如果是23w张大概需要14h
| 原因 | 说明 |
|---|---|
| ✅ ViT 已经在 ImageNet 上学过了 | 它早就“学会看图”了,你只需要教它你手势的分类方式 |
| ✅ 手势分类是“小数据任务” | 一般只需要几十个类,图像也比较规范,模型很好学 |
| ✅ 23w 张图片训练成本高 | 占用 GPU 时间大、调参慢、不适合原型验证 |
以29类手势为例
| 每类图片数 | 总图片数 | 适用阶段 | 训练建议 |
|---|---|---|---|
| 100 | 2,900 | 快速验证 | 快速调试训练流程,10分钟出结果 |
| 500 | 14,500 | 初始训练 | 可达到不错效果 |
| 1,000 | 29,000 | 稳定训练 | 精度较好,不容易过拟合 |
| 3,000+ | 87,000+ | 高精度训练 | 适合微调完整 ViT,建议 batch_size 大一点 |
| 23万张 | ✖ | 实验冗余 | 除非你做的是论文级 benchmark,否则不建议一开始就全用 |
实际证明我前面想的不太对
29类-每类1500张-batch_size=32-训练轮数25
这个准确率

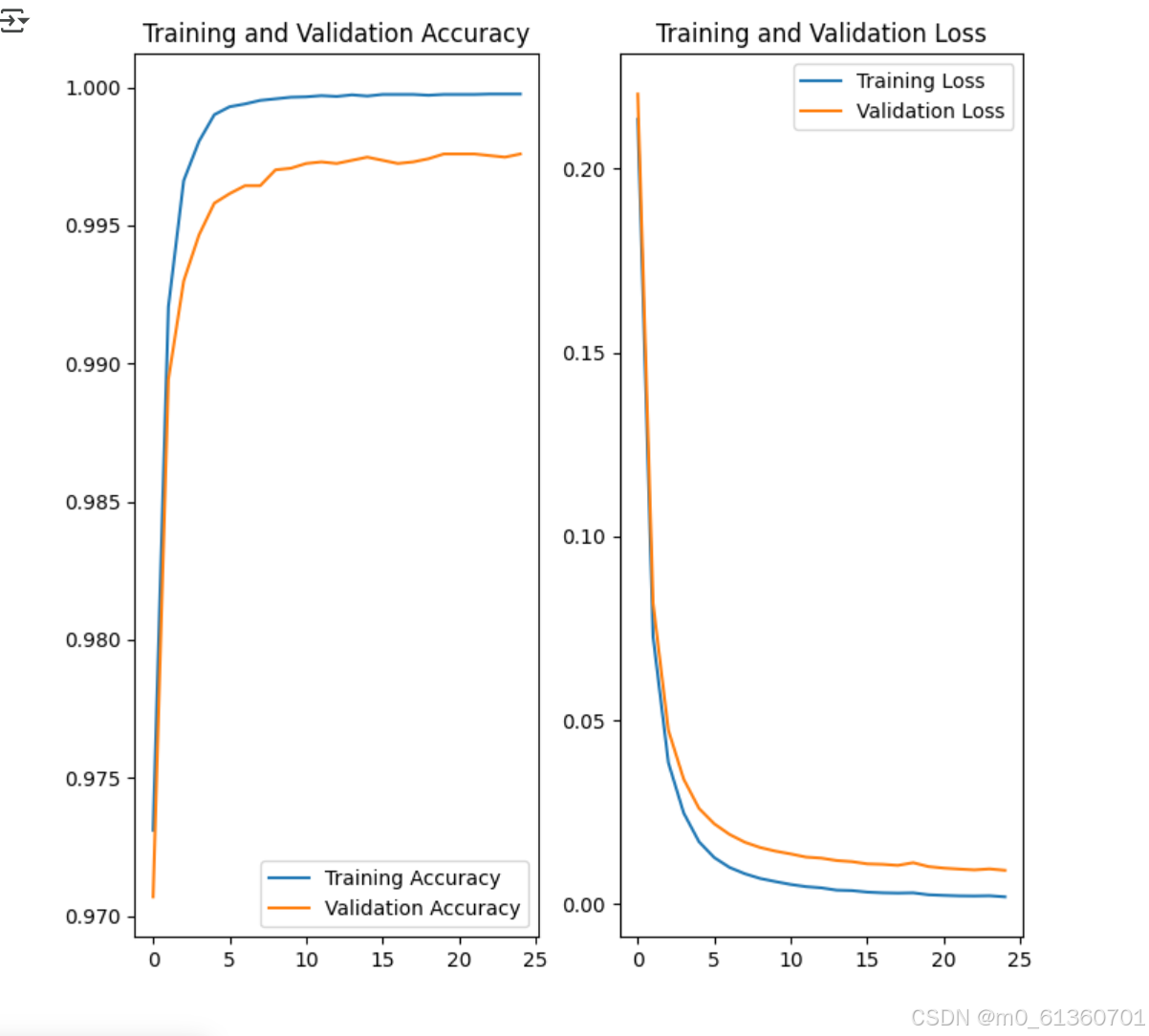

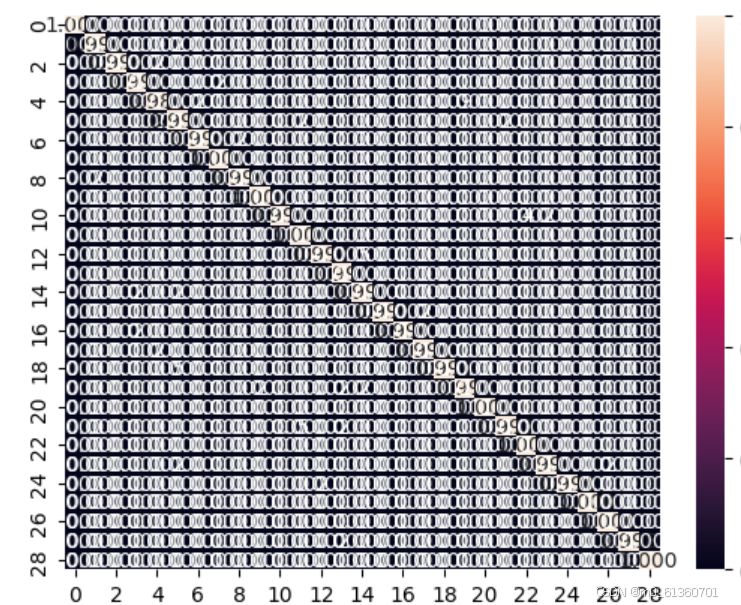


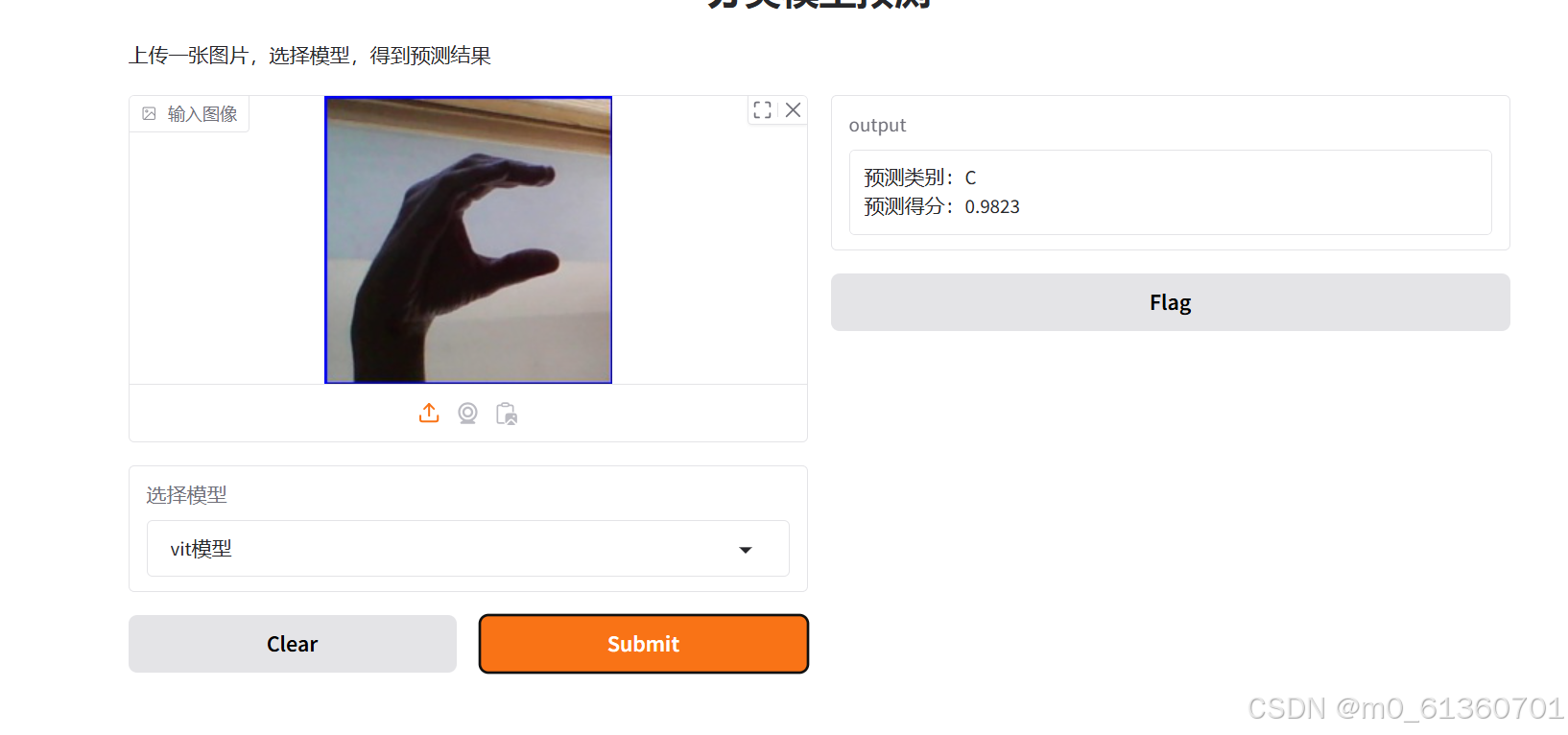
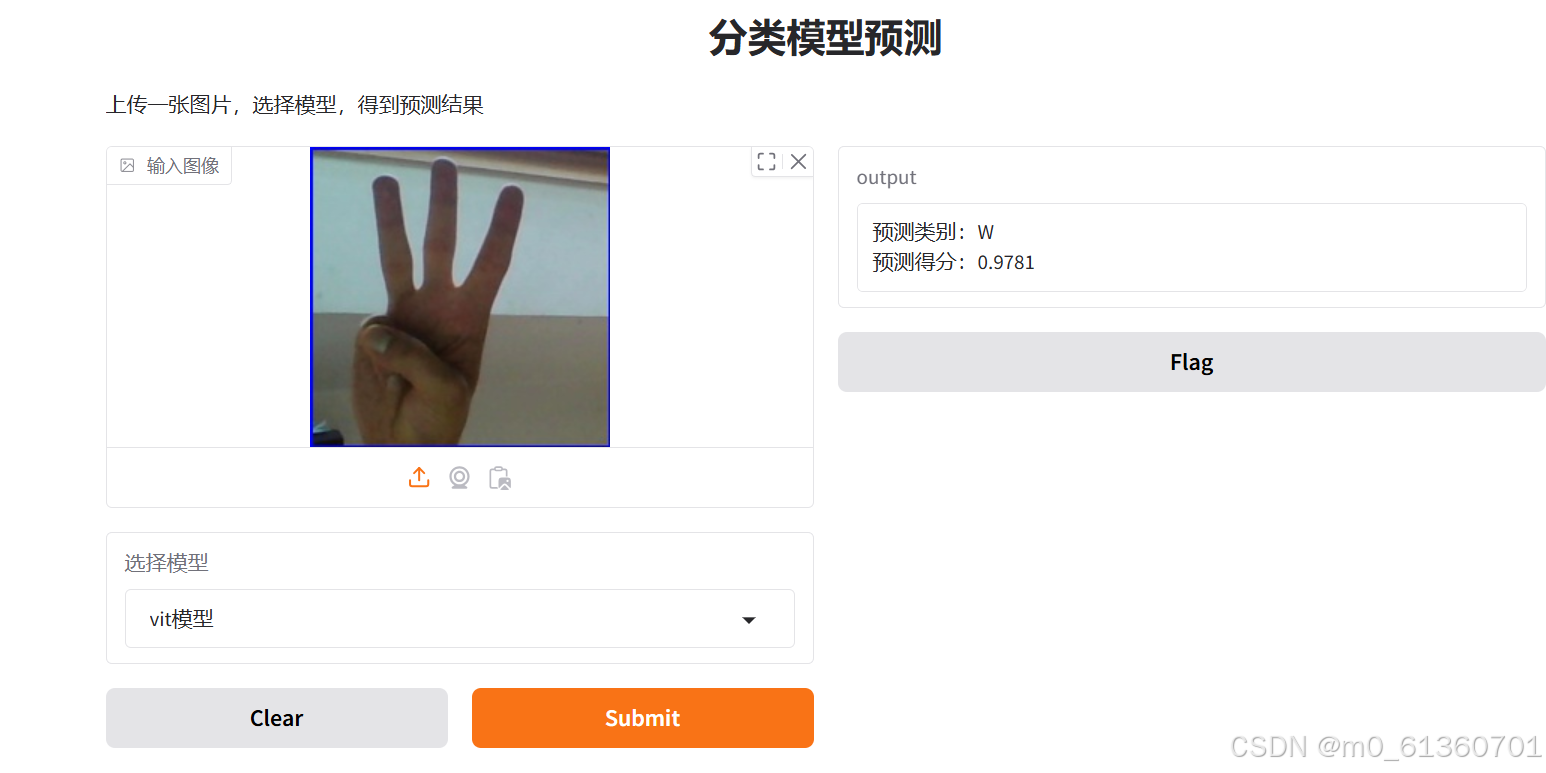
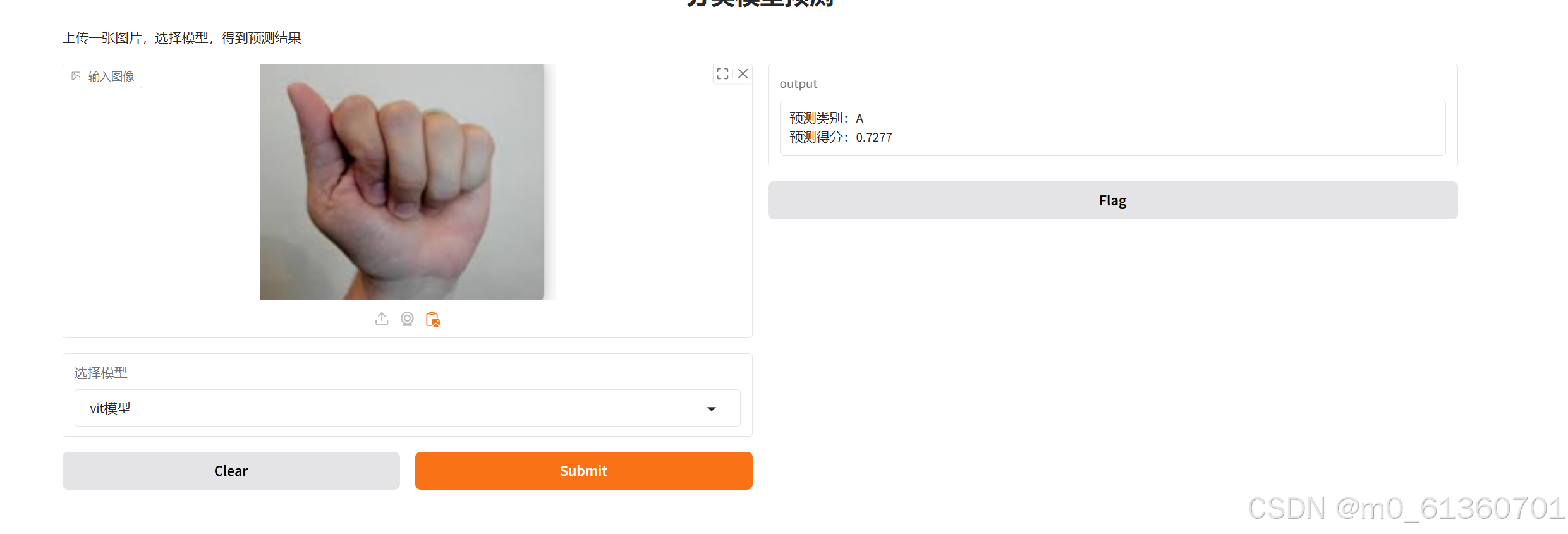
粘贴的,目前识别率可以,我在想是不是因为其他网络训练的数据集没有没那么多的原因
ViT 使用 Patch + Linear(MLP) 取代 CNN
意思是:
传统的 CNN 是用卷积核去提取图像的特征,
而 ViT 把图片分成一个个小块(Patch),
然后把这些块“摊平”,送入一个 全连接层(Linear),
相当于在「不使用卷积」的情况下提取图像特征。
CNN 是怎么处理图像的?
CNN 会:
-
使用 卷积核 在图像上滑动,提取「局部特征」(比如边缘、纹理)
-
层层提取,直到得到高层语义(比如眼睛、猫、狗等)
-
它保留了空间结构信息(哪儿亮、哪儿暗)
2. ViT 的方式不同:
ViT 把图像当作一个 序列 来处理(就像处理一串句子)
步骤如下:
| 步骤 | 说明 |
|---|---|
| Step 1:划分 Patch | 把图片分成很多小块,比如 16×16 的小方格 |
| Step 2:展平 Flatten | 把每个 Patch 展成一个向量,比如 [16×16×3] 变成 [768] |
| Step 3:Linear 映射 | 每个向量送入一个全连接层 Linear(768, D) 映射到 D 维 |
| Step 4:加位置编码 | 为了保留“每个 Patch 在哪”的信息 |
| Step 5:送入 Transformer 编码器 | 用注意力机制提取全局特征 |
| Step 6:分类 | 用一个 [CLS] token 输出最终类别 |
CNN:
-
用卷积核滑动,提取图像局部结构信息。
-
空间感知强。
-
不适合长期依赖(大图全局信息难整合)
ViT:
-
把图像切成 Patch,当作“词”看待。
-
不用卷积核,全靠注意力机制(Attention)和全连接层(MLP) 学特征。
-
非常适合提取全局依赖信息。
举个比喻!
| 方法 | 比喻 |
|---|---|
| CNN | 用放大镜一块块看图像细节(边缘、纹理),一步步整合 |
| ViT | 把整张图像分成小纸片,然后把每片数字交给语言专家(Transformer)来分析整体意思 |