容器的CPU
1、限制进程的CPU

通过Cgroup来限制进程资源的使用,CPU Cgroup 是 Cgroups 其中的一个 Cgroups 子系统,它是用来限制进程的 CPU 使用的。
- cpu.cfs_period_us,它是 CFS 算法的一个调度周期,一般它的值是 100000,以 microseconds 为单位,也就 100ms。
- cpu.cfs_quota_us,它“表示 CFS 算法中,在一个调度周期里这个控制组被允许的运行时间,比如这个值为 50000 时,就是 50ms。
如果用这个值去除以调度周期(也就是 cpu.cfs_period_us),50ms/100ms = 0.5,这样这个控制组被允许使用的 CPU 最大配额就是 0.5 个 CPU。(很有意思)
启动了一个进程,不断死循环,在一个四核的机器上会占用25%的cpu。
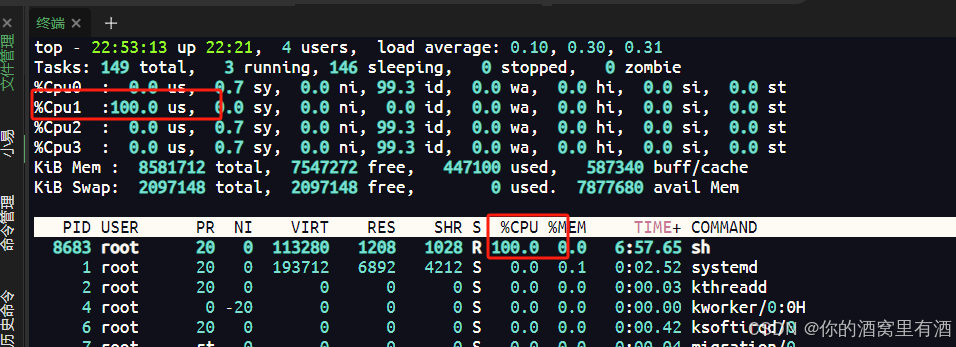
并且这个进程的pid是8683,然后我们对这个进程的cpu使用率进行限制。

首先将进程id写入cgroup.procs文件中,并向cpu.cfs_quota_us中写入50000,也就代表这个进程最多只能使用半个cpu。再执行top看下具体信息:
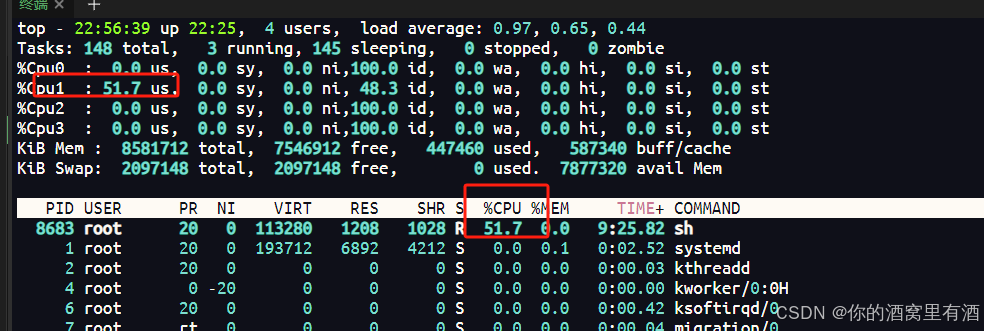
可以看到已经被限制住了。像k8s的pod中cpu的limit就是修改的这个值。
- cpu.shares。这个值是 CPU Cgroup 对于控制组之间的 CPU 分配比例,它的缺省值是 1024。
Request CPU"就是无论其他容器申请多少 CPU 资源,即使运行时整个节点的 CPU 都被占满的情况下,我的这个容器还是可以保证获得需要的 CPU 数目,那么这个设置具体要怎么实现呢?显然我们需要设置 cpu.shares 这个参数:在 CPU Cgroup 中 cpu.shares == 1024 表示 1 个 CPU 的比例,那么 Request CPU 的值就是 n,给 cpu.shares 的赋值对应就是 n*1024。
其中容器相关的配置在这个目录下,对应的文件也是这些,可以针对每个容器中的所有进程进行cpu的限制。
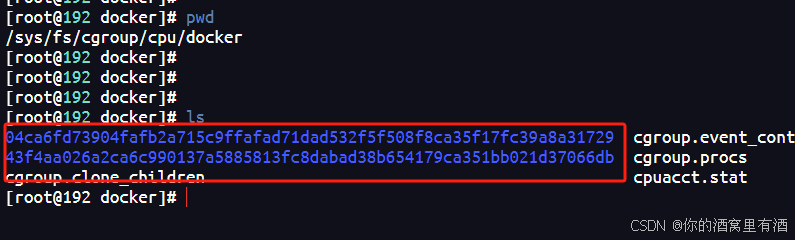

2、如何正确拿到容器的CPU可销
在传统虚拟机时代,我们习惯使用top来查看进程所占用的CPU情况,但是在容器环境下这个就不那么好用了。
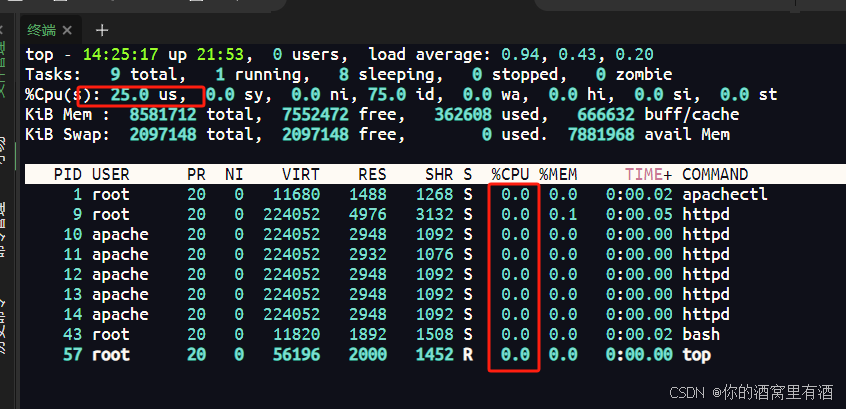
如图所示:容器中所有进程和的CPU使用率都是0.0但是总的CPU使用率却是25%,这是为什么呢?
再看一下宿主机上上的cpu使用情况:
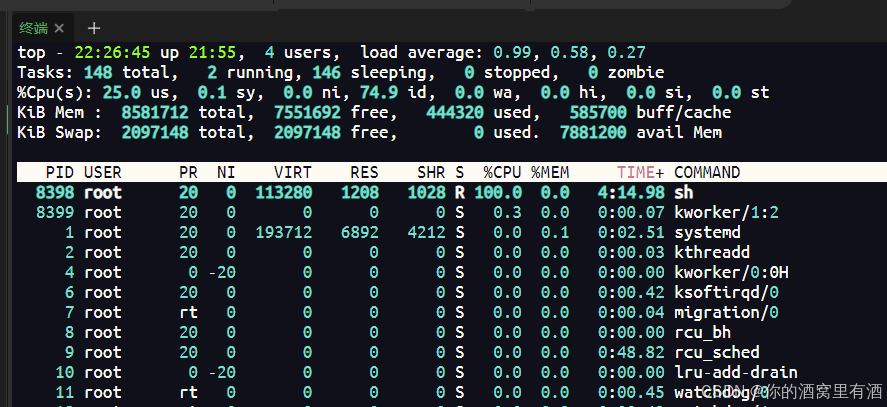
不难发现宿宿主机上的cpu使用率和容器上的cpu使用率是一样的。
因此这个例子说明,在容器中使用top命令获取容器的cpu使用率是有问题的。
daixu
3、容器与Load Average
为什么使用了CPU Cgroup限制了容器对CPU的使用率,但是系统的Load Average还是会受容器进程的影响而升高呢?
什么是Load Average,字面意思是平均负载,这个东西怎么理解呢?当我们发现系统慢的时候,一般会使用uptime 或者top命令来查看cpu的情况,其中:

load averages 代表过去1分钟,5分钟,15分钟系统的平均负载。
但是平均负载该如何理解呢?平均负载指的是平均活跃进程或者线程数,这里的活跃包括可运行和不可中断,也就是说不仅是活跃的线程也包含了等待cpu和等待IO的进程。

因此要回答系统的Load Average还是会受容器进程的影响而升高的问题就很简单,因为Load Average不仅包含了运行的进程数,还包含了等待资源的进程数量。而CPU Cgroup限制的是运行的进程,而限制不了处于等待状态的进程。