酶动力学预测工具CataPro安装教程
简介:预测酶动力学参数是酶发现和酶工程中的一项重要任务。在此,研究人员基于蛋白质语言模型、小分子语言模型和分子指纹,提出了一种名为 CataPro 的新酶动力学参数预测算法。该研究从 BRENDA 和 SABIO-RK 数据库中收集了最新的转化率(kcat)、迈克尔常数(Km)和催化效率(kcat/Km)数据。根据 0.4 的蛋白质序列相似性对这些数据进行聚类,我们得到了相应的 10 倍交叉验证数据集。CataPro 在这些无偏 10 倍交叉验证数据集上进行了训练,在预测 kcat、Km 和 kcat/Km 方面的性能优于之前的预测器。
安装教程:
1、创建并激活虚拟环境
conda create -n catapro python=3.10
conda activate catapro2、按照环境的需求安装以下必要的软件包
pytorch >= 1.13.0
transformers
numpy
pandas
RDKit
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=11.8 -c pytorch -c nvidia # 安装GPU版本的torchconda install -c conda-forge rdkit -y # 安装化学信息处理的开源工具包rdkitpip install transformers pandaspip install "numpy<2" # 因为PyTorch 版本的兼容问题,所以要安装numpy<2pip install sentencepiece # 加载 ProtT5_model 和 MolT5_model 时需要用到 HuggingFace 的 T5Tokenizer,而 T5Tokenizer 依赖于 SentencePiece 库3、安装并初始化 Git LFS
conda install -c conda-forge git-lfs -y # HuggingFace 模型仓库使用了 Git LFS (Large File Storage),专门用来处理大型文件的版本控制(比如模型权重)
git lfs install # 初始化 Git LFS
4、下载所需的预训练模型: prot_t5_xl_uniref50 and molt5-base-smiles2caption
# 步骤1:先只克隆元数据,不自动下载 LFS
# 这条命令告诉 git:只克隆仓库结构,不要拉取 LFS 文件。执行后你可以 cd prot_t5_xl_uniref50 看一下文件结构,此时 .bin 文件的大小可能是几十字节(是一个指针文件)。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Rostlab/prot_t5_xl_uniref50# 步骤2:手动拉取权重文件,这一步才会真正开始下载 .bin 文件(模型权重),你会看到下载进度条。
cd prot_t5_xl_uniref50
git lfs pull
# molt5-base-smiles2caption的安装与上面相同
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/laituan245/molt5-base-smiles2captioncd molt5-base-smiles2caption
git lfs pull
# 安装openpyxl,是pandas 用于写入 Excel 文件的依赖
pip install openpyxl5、测试运行
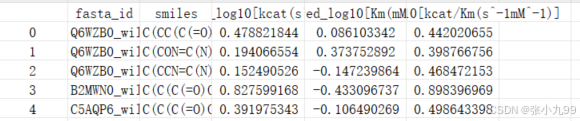
# 使用以下命令运行CataPro来推断酶促反应的动力学参数python predict.py \-inp_fpath samples/sample_inp.csv \-model_dpath models \-batch_size 64 \-device cuda:0 \-out_fpath catapro_prediction.csv输出结果如下:
参考链接:zchwang/CataPro: A generalized enzyme kinetics parameter prediction model.
参考文献:Robust enzyme discovery and engineering with deep learning using CataPro | Nature Communications