AI小白的第八天:梯度下降(含代码实现)
回顾一下 梯度 Gradient
偏导数是针对多元函数而言的,而梯度其实就是一个包含多元函数所有偏导数的向量,表示函数在某一点处变化最快的方向和变化率。
对于一个多元函数 f ( x 1 , x 2 , . . . , x n ) f(x_{1},x_{2},...,x_{n}) f(x1,x2,...,xn),其梯度是一个向量,定义为函数对各变量的偏导数组成的向量:
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) \nabla f=(\frac {\partial f}{\partial x_{1}} ,\frac {\partial f}{\partial x_{2}},...,\frac {\partial f}{\partial x_{n}}) ∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f)
- ∇ \nabla ∇ 是梯度算子,读作nabla
梯度的方向是函数在该点处变化最快的方向。
梯度的模表示函数在该方向上的变化率。
例如,对于二元函数 f ( x , y ) {f(x,y)} f(x,y),梯度 ∇ f = ( ∂ f ∂ x , ∂ f ∂ y ) \nabla f=(\frac {\partial f}{\partial x},\frac {\partial f}{\partial y}) ∇f=(∂x∂f,∂y∂f)表示在(x,y)点处变化最快的方向和变化率。
在深度学习中,常常使用如下公式来更新模型参数:
θ t + 1 = θ t − η ∇ θ J ( θ t ) \theta _{t+1}=\theta _t - \eta \nabla_\theta J(\theta _t) θt+1=θt−η∇θJ(θt)
其中 θ t \theta_t θt表示模型参数在第t次迭代时的值, θ t + 1 \theta_{t+1} θt+1是模型参数在第t+1次迭代时的值, ∇ θ J ( θ t ) \nabla_\theta J(\theta _t) ∇θJ(θt)表示损失函数 J ( θ t ) J(\theta _t) J(θt)关于模型参数 θ \theta θ的梯度; η \eta η 是学习率,之前代码中设置过。通过不断迭代训练,就可以用梯度下降算法来训练模型了。
梯度下降
针对线性关系:
y = w x + b y=wx+b y=wx+b
在线性回归中,常用的损失函数是均方误差(mean squared error ,MSE):
M S E = ∑ i = 1 n ( y i − y ^ i ) 2 n MSE=\frac {\sum_{i=1}^{n}(y_i-\hat y_i)^2}{n} MSE=n∑i=1n(yi−y^i)2
这个相较于前面经常出现的SSE(Sum of Squares due to Error,误差平方和)
S S E = ∑ i = 1 n ( y i − y ^ i ) 2 SSE=\sum_{i=1}^n(y_i- \hat y_i)^2 SSE=i=1∑n(yi−y^i)2
是不是非常相似。均方误差突出一个均,这对单个样本的参考价值就大了很多。
言归正传,在均方差公式中
M S E = ∑ i = 1 n ( y i − y ^ i ) 2 n MSE=\frac {\sum_{i=1}^{n}(y_i-\hat y_i)^2}{n} MSE=n∑i=1n(yi−y^i)2
其中 y i y_i yi是样本的真实输出值, y ^ i \hat y_i y^i是模型预测的输出值,n是样本数量。
梯度下降法对参数w和b的更新公式为
w ← w − α ∂ L ∂ w w \leftarrow w - \alpha \frac{\partial L}{\partial w} w←w−α∂w∂L
b ← b − α ∂ L ∂ b b \leftarrow b - \alpha \frac{\partial L}{\partial b} b←b−α∂b∂L
也就是用参数本身减去对于参数的线性回归模型偏导数参数乘以一个学习率 α \alpha α来更新自己。偏导数相当于控制了纠正方向,学习率则控制了参数纠正的模长。
代码实现
纯手动实现
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import torchmatplotlib.use('TkAgg')# 设置随机数种子,使得每次运行代码生成的数据相同
np.random.seed(42)# 生成100个随机数据,w为2,b为1,也就是说,我们的样本数据是围绕线性函数y=2x+1来生成的。
x = np.random.rand(100, 1)
# 让y的标签值有一个0-1直接的偏差,并且这个偏差进一步缩小为0.1倍。为什么要缩小,其实可以自己删除掉后看看样本的分布状态就知道了。
y = 1 + 2 * x + 0.1 * np.random.randn(100, 1)print('x的数量:', x.size)
print('y的数量:', y.size)# 将羊背数据转换为张量
x_tensor = torch.from_numpy(x).float()
y_tensor = torch.from_numpy(y).float()# 设置学习率
learning_rate = 0.1
# 设置训练轮数
num_epochs = 1000# 初始化参数,就是给系数w和b设置初始值(生成样本时,我们给定的w和b的预期值分别是2和1)
# 使用PyTorch库randn()方法[创建一个形状为(1,)的随机张量w,其值从标准正态分布中采样]。requires_grad=True表示该张量在后续计算中需要记录梯度,用于反向传播。
w = torch.randn(1, requires_grad=True)
# 使用PyTorch库zeros()方法[使用PyTorch库创建一个标量张量,值为0,形状为(1,)。]。requires_grad=True表示该张量在后续计算中需要记录梯度,用于反向传播。
b = torch.zeros(1, requires_grad=True)# 开始训练
for epoch in range(num_epochs):# 计算预测值,这里可以看到y_pred中是包含w和b了,w和b也在上面设置为需要计算梯度。y_pred = x_tensor * w + b# 计算损失 这里使用均方误差作为损失函数,python的语法里,**表示幂运算, mean()方法可以自动计算均值loss = ((y_pred - y_tensor) ** 2).mean()# 反向传播,这里其实就是在计算w和b的梯度loss.backward()# 更新参数with torch.no_grad():# 更新w和bw -= learning_rate * w.gradb -= learning_rate * b.grad# 清空梯度w.grad.zero_()b.grad.zero_()# 输出训练后的参数,与数据生成时设置的常数基本一致
print('w:', w)
print('b:', b)# 绘制散点图和直线
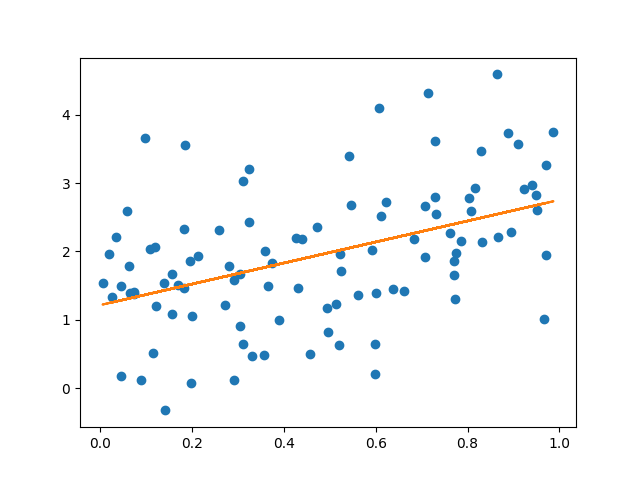
plt.plot(x, y, 'o')
plt.plot(x_tensor.numpy(), y_pred.detach().numpy())
plt.show()执行代码会得到

还有上面提到的,如果y的样本数据不缩小0.1倍,就会变成下面这个样子。其实也还好,这样的样本就该得到这样的最优解。
利用PyTorch 框架实现
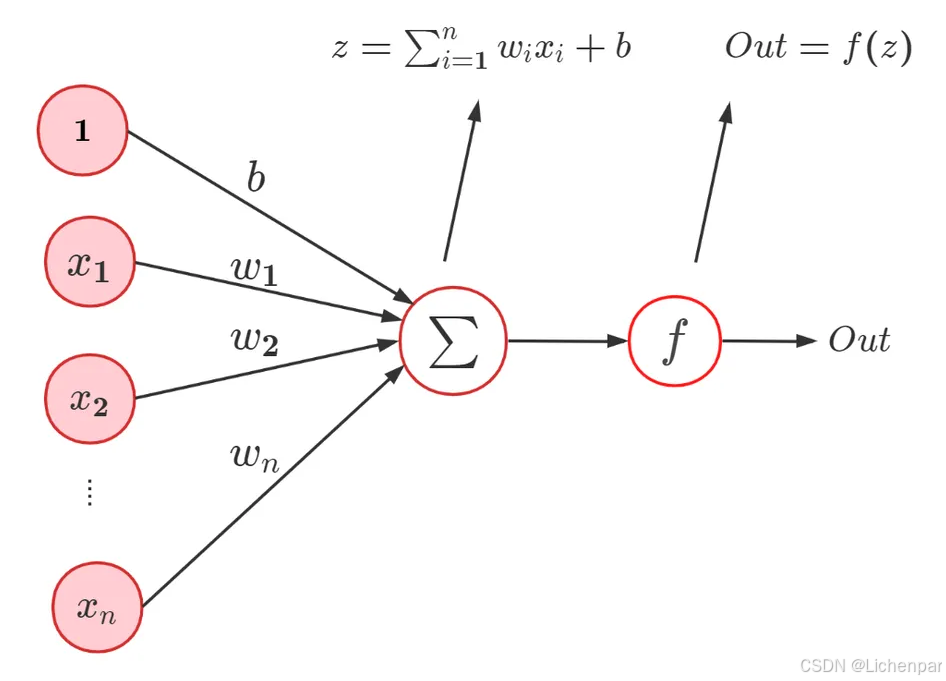
还记得神经元模型的数学表达式么?AI小白的第五天:神经网络原理
其公式可以用矩阵的形式总结为: O u t = f ( x w + b ) Out = f(xw+b) Out=f(xw+b)
- x w xw xw的意思就是矩阵 x [ x 1 , x 2 . . . x n ] x[x_{1},x_{2}...x_{n}] x[x1,x2...xn]乘以矩阵 w [ w 1 , w 2 . . . w n ] w[w_{1},w_{2}...w_{n}] w[w1,w2...wn],矩阵乘法的计算方法就是左行乘以右列,因为都是1行n列,因此就是 x n w n x_{n}w_{n} xnwn了。最终得到一个新的矩阵。
- f f f是激活函数,那啥是激活函数呢?
- b b b是截距,有时也叫偏置(bias)
因为输出只有1个,因此也只能进行二分类。
我们还曾经写了一个神经元模型训练识别数字的代码。AI小白的第三天:抛弃捷径思想,拥抱hello world
现在,我们又来用模型解决问题了。
import matplotlibmatplotlib.use('TkAgg')import numpy as np
import torch
import torch.nn as nn# 设置随机数种子,使得每次运行代码生成的数据相同
np.random.seed(42)# 生成随机数据
x = np.random.rand(100, 1)
y = 1 + 2 * x + 0.1 * np.random.randn(100, 1)# 将数据转换为 pytorch tensor
x_tensor = torch.from_numpy(x).float()
y_tensor = torch.from_numpy(y).float()# 设置超参数
learning_rate = 0.1
num_epochs = 1000# 定义输入数据的维度和输出数据的维度
input_dim = 1
output_dim = 1# 定义模型,还记得么,nn就是神经网络的缩写,Linear就是线性的。我梦创建一个线性模型。输入和输出的张量维度都是1维的
model = nn.Linear(input_dim, output_dim)# 定义损失函数和优化器
criterion = nn.MSELoss() # MSELoss均方误差损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # SGD梯度下降法# 开始训练
for epoch in range(num_epochs):# 将输入数据喂给模型y_pred = model(x_tensor)# 计算损失loss = criterion(y_pred, y_tensor)# 清空梯度optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()# 输出训练后的参数
print('w:', model.weight.data)
print('b:', model.bias.data)执行结果如下。因为随机数的种子设置的是一样的,因此得到的样本也是一样的。模型计算和手撸算法两种方式计算的结果也是一样的。
