NanoGraphrag原理和数据流讲解
根据NanoGraphrag工程,从数据流的角度进行graphrag核心原理讲解。
文章目录
- 根据NanoGraphrag工程,从数据流的角度进行graphrag核心原理讲解。
- 前言
- 一、核心原理
- 1.1 环境配置
- 1.2 代码理解
- 1.2.1 文本分块
- 1.2.2 实体和关系抽取
- 1.2.3 实体和关系合并
- 1.2.4 社区聚类和分层
- 1.2.5 构建社区报告
- 1.3 local查询
- 1.4 global查询
- 二、总结
前言
介绍:本文的初衷是微软的graphrag设计过于巧妙,上手需要大量时间和经验,因此,本项目基于轻量级的graphrag的复现项目nano-graphrag进行核心原理的学习。
Github:https://github.com/gusye1234/nano-graphrag
参考链接:安装部署参考上一篇blog:基于vllm和xinference本地化部署GraphRAG
一、核心原理

1.1 环境配置
# clone this repo first
cd nano-graphrag
pip install -e .
vllm启动qwen2.5-32b-instruct模型,xinference启动bge-m3模型,详细内容参考上一篇blog。
当前运行脚本为using_llm_api_as_llm+ollama_embedding.py 配置信息如下:
import os
import logging
# import ollama
import numpy as np
import requests
from openai import AsyncOpenAI
from nano_graphrag import GraphRAG, QueryParam
from nano_graphrag import GraphRAG, QueryParam
from nano_graphrag.base import BaseKVStorage
from nano_graphrag._utils import compute_args_hash, wrap_embedding_func_with_attrslogging.basicConfig(level=logging.WARNING)
logging.getLogger("nano-graphrag").setLevel(logging.INFO)# Assumed llm model settings
LLM_BASE_URL = "http://172.17.136.62:10081/v1"
LLM_API_KEY = "EMPTY"
MODEL = "qwen2.5_32b_instruct"# Assumed embedding model settings
EMBEDDING_MODEL = "nomic-embed-text"
EMBEDDING_MODEL_DIM = 1024 # bge-m3 维度是1024
EMBEDDING_MODEL_MAX_TOKENS = 8192# Xinference服务的URL地址
XINFERENCE_SERVER_URL = "http://172.17.136.62:9997"
# embedding模型的UID
EMBEDDING_MODEL_UID = "custom-bge-m3" # 替换为实际的模型UID
同时将原来的ollama_embedding替换为以下xinference_embedding
async def xinference_embedding(texts: list[str]) -> np.ndarray:"""使用xinference接入的embedding服务获取文本嵌入向量Args:texts (list[str]): 要获取嵌入的文本列表Returns:np.ndarray: 文本的嵌入向量数组"""embeddings = []for text in texts:# 构造请求URLurl = f"{XINFERENCE_SERVER_URL}/v1/embeddings"# 构造请求体payload = {"model": EMBEDDING_MODEL_UID,"input": text}# 设置请求头headers = {"Content-Type": "application/json","Accept": "application/json"}try:# 发送POST请求response = requests.post(url, json=payload, headers=headers)# 检查响应状态码if response.status_code == 200:# 解析响应中的嵌入向量embedding = response.json()["data"][0]["embedding"]embeddings.append(embedding)else:# 如果请求失败,抛出异常raise Exception(f"请求失败,状态码:{response.status_code}, 响应内容:{response.text}")except Exception as e:print(f"获取嵌入向量失败:{e}")# 如果获取嵌入失败,可以返回一个空向量或者处理异常embeddings.append(np.zeros(EMBEDDING_MODEL_DIM))return embeddings
1.2 代码理解
数据输入为:nano-graphrag/tests/zhuyuanzhang.txt
1.2.1 文本分块
文章默认使用1200token,overlap进行分块。并给每个块设置一个哈希值映射。

对应论文中的Texts Chunk, 这也是常规RAG的实现方式,如果是使用domain的数据集,需要根据自己的文章的语义格式进行自定义的文章分块,最大程度还原文章层级的语义信息。最新的研究,基于大模型进行语义的切分,参考以下内容:
- 🎯simple-qwen-0.5🎯,根据文档的结构元素进行切分,简单直直接,https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b;
- 🎯topic-qwen-0.5🎯:灵感来自思维链 (Chain-of-Thought) 推理,它会先识别文本中的主题,再根据主题进行切分,切分结果非常符合人类的直觉,https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b-cot-topic-chunking;
- 🎯summary-qwen-0.5🎯:能切分文档兵生成每个分块的摘要,在 RAG 应用中非常有用,https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b-summary-chunking
1.2.2 实体和关系抽取
'-Goal-\nGiven a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities.\n\n-Steps-\n1. Identify all entities. For each identified entity, extract the following information:\n- entity_name: Name of the entity, capitalized\n- entity_type: One of the following types: [organization,person,geo,event]\n- entity_description: Comprehensive description of the entity\'s attributes and activities\nFormat each entity as ("entity"<|><entity_name><|><entity_type><|><entity_description>\n\n2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.\nFor each pair of related entities, extract the following information:\n- source_entity: name of the source entity, as identified in step 1\n- target_entity: name of the target entity, as identified in step 1\n- relationship_description: explanation as to why you think the source entity and the target entity are related to each other\n- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity\n Format each relationship as ("relationship"<|><source_entity><|><target_entity><|><relationship_description><|><relationship_strength>)\n\n3. Return output in English as a single list of all the entities and relationships identified in steps 1 and 2. Use **##** as the list delimiter.\n\n4. When finished, output <|COMPLETE|>\n\n######################\n-Examples-\n######################\nExample 1:\n\nEntity_types: [person, technology, mission, organization, location]\nText:\nwhile Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor\'s authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan\'s shared commitment to discovery was an unspoken rebellion against Cruz\'s narrowing vision of control and order.\n\nThen Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. “If this tech can be understood..." Taylor said, their voice quieter, "It could change the game for us. For all of us.”\n\nThe underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor\'s, a wordless clash of wills softening into an uneasy truce.\n\nIt was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths\n################\nOutput:\n("entity"<|>"Alex"<|>"person"<|>"Alex is a character who experiences frustration and is observant of the dynamics among other characters.")##\n("entity"<|>"Taylor"<|>"person"<|>"Taylor is portrayed with authoritarian certainty and shows a moment of reverence towards a device, indicating a change in perspective.")##\n("entity"<|>"Jordan"<|>"person"<|>"Jordan shares a commitment to discovery and has a significant interaction with Taylor regarding a device.")##\n("entity"<|>"Cruz"<|>"person"<|>"Cruz is associated with a vision of control and order, influencing the dynamics among other characters.")##\n("entity"<|>"The Device"<|>"technology"<|>"The Device is central to the story, with potential game-changing implications, and is revered by Taylor.")##\n("relationship"<|>"Alex"<|>"Taylor"<|>"Alex is affected by Taylor\'s authoritarian certainty and observes changes in Taylor\'s attitude towards the device."<|>7)##\n("relationship"<|>"Alex"<|>"Jordan"<|>"Alex and Jordan share a commitment to discovery, which contrasts with Cruz\'s vision."<|>6)##\n("relationship"<|>"Taylor"<|>"Jordan"<|>"Taylor and Jordan interact directly regarding the device, leading to a moment of mutual respect and an uneasy truce."<|>8)##\n("relationship"<|>"Jordan"<|>"Cruz"<|>"Jordan\'s commitment to discovery is in rebellion against Cruz\'s vision of control and order."<|>5)##\n("relationship"<|>"Taylor"<|>"The Device"<|>"Taylor shows reverence towards the device, indicating its importance and potential impact."<|>9)<|COMPLETE|>\n#############################\nExample 2:\n\nEntity_types: [person, technology, mission, organization, location]\nText:\nThey were no longer mere operatives; they had become guardians of a threshold, keepers of a message from a realm beyond stars and stripes. This elevation in their mission could not be shackled by regulations and established protocols—it demanded a new perspective, a new resolve.\n\nTension threaded through the dialogue of beeps and static as communications with Washington buzzed in the background. The team stood, a portentous air enveloping them. It was clear that the decisions they made in the ensuing hours could redefine humanity\'s place in the cosmos or condemn them to ignorance and potential peril.\n\nTheir connection to the stars solidified, the group moved to address the crystallizing warning, shifting from passive recipients to active participants. Mercer\'s latter instincts gained precedence— the team\'s mandate had evolved, no longer solely to observe and report but to interact and prepare. A metamorphosis had begun, and Operation: Dulce hummed with the newfound frequency of their daring, a tone set not by the earthly\n#############\nOutput:\n("entity"<|>"Washington"<|>"location"<|>"Washington is a location where communications are being received, indicating its importance in the decision-making process.")##\n("entity"<|>"Operation: Dulce"<|>"mission"<|>"Operation: Dulce is described as a mission that has evolved to interact and prepare, indicating a significant shift in objectives and activities.")##\n("entity"<|>"The team"<|>"organization"<|>"The team is portrayed as a group of individuals who have transitioned from passive observers to active participants in a mission, showing a dynamic change in their role.")##\n("relationship"<|>"The team"<|>"Washington"<|>"The team receives communications from Washington, which influences their decision-making process."<|>7)##\n("relationship"<|>"The team"<|>"Operation: Dulce"<|>"The team is directly involved in Operation: Dulce, executing its evolved objectives and activities."<|>9)<|COMPLETE|>\n#############################\nExample 3:\n\nEntity_types: [person, role, technology, organization, event, location, concept]\nText:\ntheir voice slicing through the buzz of activity. "Control may be an illusion when facing an intelligence that literally writes its own rules," they stated stoically, casting a watchful eye over the flurry of data.\n\n"It\'s like it\'s learning to communicate," offered Sam Rivera from a nearby interface, their youthful energy boding a mix of awe and anxiety. "This gives talking to strangers\' a whole new meaning."\n\nAlex surveyed his team—each face a study in concentration, determination, and not a small measure of trepidation. "This might well be our first contact," he acknowledged, "And we need to be ready for whatever answers back."\n\nTogether, they stood on the edge of the unknown, forging humanity\'s response to a message from the heavens. The ensuing silence was palpable—a collective introspection about their role in this grand cosmic play, one that could rewrite human history.\n\nThe encrypted dialogue continued to unfold, its intricate patterns showing an almost uncanny anticipation\n#############\nOutput:\n("entity"<|>"Sam Rivera"<|>"person"<|>"Sam Rivera is a member of a team working on communicating with an unknown intelligence, showing a mix of awe and anxiety.")##\n("entity"<|>"Alex"<|>"person"<|>"Alex is the leader of a team attempting first contact with an unknown intelligence, acknowledging the significance of their task.")##\n("entity"<|>"Control"<|>"concept"<|>"Control refers to the ability to manage or govern, which is challenged by an intelligence that writes its own rules.")##\n("entity"<|>"Intelligence"<|>"concept"<|>"Intelligence here refers to an unknown entity capable of writing its own rules and learning to communicate.")##\n("entity"<|>"First Contact"<|>"event"<|>"First Contact is the potential initial communication between humanity and an unknown intelligence.")##\n("entity"<|>"Humanity\'s Response"<|>"event"<|>"Humanity\'s Response is the collective action taken by Alex\'s team in response to a message from an unknown intelligence.")##\n("relationship"<|>"Sam Rivera"<|>"Intelligence"<|>"Sam Rivera is directly involved in the process of learning to communicate with the unknown intelligence."<|>9)##\n("relationship"<|>"Alex"<|>"First Contact"<|>"Alex leads the team that might be making the First Contact with the unknown intelligence."<|>10)##\n("relationship"<|>"Alex"<|>"Humanity\'s Response"<|>"Alex and his team are the key figures in Humanity\'s Response to the unknown intelligence."<|>8)##\n("relationship"<|>"Control"<|>"Intelligence"<|>"The concept of Control is challenged by the Intelligence that writes its own rules."<|>7)<|COMPLETE|>\n#############################\n-Real Data-\n######################\nEntity_types: organization,person,geo,event\nText: 第一章 童年\n\n我们从一份档案开始。\n\n姓名:朱元璋别名(外号):朱重八、朱国瑞\n\n性别:男\n\n民族:汉\n\n血型:?\n\n学历:无文凭,秀才举人进士统统的不是,后曾自学过\n\n职业:皇帝\n\n家庭出身:(至少三代)贫农\n\n生卒:1328-1398\n\n最喜欢的颜色:黄色(这个好像没得选)\n\n社会关系:\n\n父亲:朱五四,农民\n\n母亲:陈氏,农民(不好意思,史书中好像没有她的名字)\n\n座右铭:你的就是我的,我还是我的\n\n主要经历:\n\n1328年-1344年放牛\n\n1344年-1347年做和尚,主要工作是出去讨饭(这个……)\n\n1347年-1352年做和尚主要工作是撞钟\n\n1352年-1368年造反(这个猛)\n\n1368年-1398年主要工作是做皇帝\n\n一切的事情都从1328年的那个夜晚开始,农民朱五四的妻子陈氏生下了一个男婴,大家都知道了,这个男婴就是后来的朱元璋。大凡皇帝出世,后来的史书上都会有一些类似的怪象记载。\n\n比如刮风啊,下暴雨啊,冒香气啊,天上星星闪啊,到处放红光啊,反正就是要告诉你,这个人和别人不一样。朱元璋先生也不例外,他出生时,红光满地,夜间房屋中出现异光,以致于邻居以为失火了,跑来相救(明实录)。\n\n然而当时农民朱五四的心情并不像今天我们在医院产房外看到的那些焦急中带着喜悦的父亲们,作为已经有了三个儿子、两个女儿的父亲而言,首先要考虑的是吃饭问题。\n\n农民朱五四的工作由两部分构成,他有一个豆腐店,但主要还是要靠种地主家的土地讨生活,这就决定了作为这个劳动家庭的一员,要活下去只能不停的干活。\n\n在小朱五四出生一个月后,父母为他取了一个名字(元时惯例):朱重八,这个名字也可以叫做朱八八,我们这里再介绍一下,朱重八家族的名字,都很有特点。\n\n朱重八高祖名字:朱百六;\n\n朱重八曾祖名字:朱四九;\n\n朱重八祖父名字:朱初一;\n\n他的父亲我们介绍过了,叫朱五四。\n\n取这样的名字不是因为朱家是搞数学的,而是因为在元朝,老百姓如果不能上学和当官就没有名字,只能以父母年龄相加或者出生的日期命名。(登记户口的人一定会眼花)\n\n朱重八的童年在一间冬凉夏暖、四面通风、采光良好的破茅草屋里度过,他的主要工作是为地主刘德家放牛。他曾经很想读书,可是朱五四是付不起学费的,他没有李密牛角挂书那样的情操,自然也没有杨素那样的大官来赏识他,于是,他很老实的帮刘德放了十二年的牛。\n\n因为,他要吃饭。\n\n在此时,朱重八的梦想是好好的活下去,到十六岁的时候,托村口的吴老太作媒,找一个手脚勤快、能干活的姑娘当媳妇,然后生下自己的儿女,儿女的名字可能是朱三二、或者朱四零,等到朱三二等人大了,就让他们去地主刘小德家放牛。\n\n这就是十六岁时的朱重八对未来生活的幸福向往。\n\n此时的中国,正在极其腐败的元王朝的统治下,那些来自蒙古的征服者似乎不认为在自己统治下的老百姓是人,他们甚至经常考虑把这些占地方的家伙都杀掉,然后把土地用来放牧(元史),从赋税到徭役,只要是人能想出来的科目,都能用来收钱,过节要收“过节钱”、干活有“常例钱”、打官司有“公事钱”,怕了吧,那我不出去还不行吗?不干事还不行吗?那也不行,平白无故也要钱,要收“撒花钱”。服了吧。\n\n于是,在这个马上民族统治中国六十余年后,他们的国家机器已经到了无法承受的地步,此时的元帝国就好像是一匹不堪重负的骆驼,只等那最后一根稻草。\n\n这根稻草很快就到了。\n\n1344年是一个有特殊意义的年份,在这一年,上天终于准备抛弃元了,他给中国带来了两个灾难,同时也给元挖了一个墓坑,并写好了墓志铭:石人一只眼,挑动黄河天下反。\n\n他想的很周到,还为元准备了一个填土的人:朱重八。\n\n当然朱重八不会想到上天会交给他这样一个重要的任务。\n\n这一年,他十七岁。\n\n很快\n######################\nOutput:\n'
论文中是支持多轮抽取的,工程中是通过entity_extract_max_gleaning 控制
再次抽取的指令工程为:
‘MANY entities were missed in the last extraction. Add them below using the same format:\n’
结果是:
'("entity"<|>"朱元璋"<|>"person"<|>"朱元璋,别名朱重八、朱国瑞,原是一名贫穷的农民的孩子,自学成为皇帝。")##\n("entity"<|>"朱五四"<|>"person"<|>"朱五四是朱元璋的父亲,农民,经营豆腐店,主要工作是种地主家的土地。")##\n("entity"<|>"陈氏"<|>"person"<|>"陈氏是朱元璋的母亲,农民,真实姓名在史书中未记载。")##\n("entity"<|>"元朝"<|>"organization"<|>"元朝是当时统治中国的蒙古王朝,极其腐败,经常对人民征税。")##\n("entity"<|>"刘德"<|>"person"<|>"刘德是朱元璋放牛的地主,他让十六岁的朱元璋为他家放了十二年牛。")##\n("entity"<|>"石人一只眼,挑动黄河天下反"<|>"event"<|>"这是在元朝时期上天写下的墓志铭,预示着元朝的覆灭。")##\n("relationship"<|>"朱元璋"<|>"朱五四"<|>"朱元璋是朱五四的儿子,朱五四作为父亲,希望朱元璋能够活下去,这关系表明父子间的血缘和期望关系。"<|>10)##\n("relationship"<|>"朱五四"<|>"元朝"<|>"朱五四作为底层农民,深受元朝苛政的影响。"<|>9)##\n("relationship"<|>"朱元璋"<|>"元朝"<|>"朱元璋在元朝后期通过造反最终推翻了元朝统治,成为明朝的开国皇帝。"<|>9)##\n("relationship"<|>"刘德"<|>"朱元璋"<|>"刘德作为地主,雇佣朱元璋为他放牛,影响了朱元璋童年和早期的生活。"<|>8)##\n("relationship"<|>"元朝"<|>"石人一只眼,挑动黄河天下反"<|>"元朝的末日由墓志铭暗示,这关系显示了元朝面临的衰败和即将到来的反抗。"<|>9)<|COMPLETE|>'
1.2.3 实体和关系合并
将整篇文章的所有实体和关系进行合并,同时也将实体的描述description也进行合并,如果description的长度超过500,则会调用大模型重新生成一次整体的描述。合并后的实体和关系,大概如下所示:
实体
dict_keys(['"朱元璋"', '"汤和"', '"郭子兴"', '"濠州"', '"孙德崖"', '"朱重八"', '"马姑娘"', '"军中的总管"', '"濠州四名农民统帅"', '"军队中的农民兵士"', 0])
关系
dict_keys([('"朱元璋"', '"汤和"'), ('"朱元璋"', '"郭子兴"'), ('"郭子兴"', '"濠州"'), ('"孙德崖"', '"郭子兴"'), ('"孙德崖"', '"濠州"'), ('"朱重八"', '"朱元璋"'), ('"朱元璋"', '"马姑娘"'), ('"郭子兴"', '"马姑娘"'), ('"朱元璋"', '"军中的总管"'), ('"濠州四名农民统帅 "', '"军队中的农民兵士"')])
实体的具体信息如下所示:
{'entity_type': '"PERSON"', 'description': '"朱元璋是一个有能力的统帅,经历了从被囚禁到自由,再到成功领导军事行动的过程,最终脱离郭子兴,开创了自己的霸业。"<SEP>"朱元璋是朱重八后来成为皇帝后的名字,他后来能吃饱饭,并回忆起与父母一起生活的痛苦经历。"<SEP>"朱元璋,别名朱重八、朱国瑞,原是一名贫穷的农民的孩子,自学成为皇帝。"<SEP>"朱元璋,原名朱重八,是军队中的士兵,因其才能和胆识很快被提拔并得到郭子兴的重用,是个勇敢、有计谋、冷静、深思熟虑的人。他对财物不贪图,成为郭子兴的重要智囊和助手。"', 'source_id': 'chunk-8091a468687529ab4647eec0e9f0e1dc<SEP>chunk-4bdd775f30019125ecf386a970f73cb9<SEP>chunk-b26706fdda696524be1e5ff48c2836c2<SEP>chunk-41fce71cb1f6198f0eb409c3481892ec', 'entity_name': '"朱元璋"'}
完整解释如下:
| 字段名 | 含义 | 示例值 |
|---|---|---|
entity_type | 实体的类型,这里是 "PERSON",表示这是一个“人物”。 | "PERSON" |
description | 对实体的详细描述,分为多个片段,用 <SEP> 分隔。 | "朱元璋是一个有能力的统帅..."<SEP>"朱元璋是朱重八后来成为皇帝后的名字..." |
source_id | 描述片段的来源 ID,指向存储在数据库中的文本块,用 <SEP> 分隔。 | "chunk-8091a468687529ab4647eec0e9f0e1dc<SEP>chunk-4bdd775f30019125ecf386a970f73cb9" |
entity_name | 实体的名称,这里是 "朱元璋"。 | "朱元璋" |
- 插入到向量数据库
将实体+实体描述,进行embedding之后,插入到VDB中,便于后续local的检索
1.2.4 社区聚类和分层
在正式介绍leiden算法之前,用一个通俗的例子讲解leiden的核心过程:
用一个社交网络中的朋友分组的例子来讲解 Hierarchical Leiden 算法,用简单易懂的语言分步骤说明,避免专业术语,确保每个细节都讲清楚。
例子:班级同学的朋友分组
假设我们有一个 10人的班级,每个同学之间有不同的兴趣爱好和互动关系。我们想通过他们的互动模式,将他们分成不同的“朋友小组”(社区),并且观察这些小组在不同层次上的结构。
1. 初始场景:班级里的同学
- 同学列表:A、B、C、D、E、F、G、H、I、J。
- 兴趣和互动:
- 篮球爱好者:A、B、C、D(经常一起打篮球)。
- 音乐爱好者:E、F、G(经常一起唱歌或弹吉他)。
- 学习小组:H、I、J(经常一起学习)。
- 跨组互动:
- A偶尔和E一起参加运动会。
- G和H偶尔一起复习功课。
- F和I是邻居,偶尔聊天。
2. 问题:如何分组?
我们需要将这10个同学分成不同的小组,使得:
- 同一小组内的同学互动频繁(紧密联系)。
- 不同小组之间的互动较少(松散联系)。
3. Hierarchical Leiden 算法的步骤
阶段1:初始划分(每个同学自己是一个小组)
- 初始状态:每个同学都是独立的小组,共10个小组。
- 目标:逐步合并或拆分小组,使得组内互动更紧密。
阶段2:第一层划分(大组)
算法开始工作:
- 计算“紧密程度”:
- 比如,A和B经常一起打篮球,他们之间的“互动强度”很高。
- A和E的互动较少,所以他们的“连接”较弱。
- 合并或拆分:
- 篮球组:A、B、C、D互动频繁,合并成一个大组。
- 音乐组:E、F、G合并成一个组。
- 学习组:H、I、J合并成一个组。
- 跨组的弱连接(如A-E、G-H、F-I)暂时忽略,因为它们属于不同组。
结果:
- 第一层社区:3个大组(篮球组、音乐组、学习组)。
阶段3:第二层划分(细分小组)
算法继续深入:
- 检查每个大组是否还能进一步细分:
- 篮球组:A、B是主力队员,C、D是替补。他们内部互动更紧密,可以再分成两个小组:
- 主力组:A、B。
- 替补组:C、D。
- 音乐组:E、F擅长唱歌,G擅长弹吉他。可以分成:
- 声乐组:E、F。
- 乐器组:G。
- 学习组:H、I是学霸,J是学渣。可以分成:
- 学霸组:H、I。
- 学渣组:J(单独一组,因为互动较少)。
- 篮球组:A、B是主力队员,C、D是替补。他们内部互动更紧密,可以再分成两个小组:
结果:
- 第二层社区:6个小组(主力组、替补组、声乐组、乐器组、学霸组、学渣组)。
阶段4:第三层划分(更细的小组)
算法继续检查是否还能细分:
- 主力组:A和B是否还能再分?可能不行,因为他们互动很紧密,无法再拆分。
- 声乐组:E和F可能合并成一个更紧密的小组。
- 其他小组:无法再细分,因为成员过少或互动不够紧密。
最终结果:
- 第三层社区:5个小组(主力组、替补组、声乐组、乐器组、学霸组、学渣组)。
(注意:学渣组J无法再分,保持原样。)
4. 层次化结构
通过上述步骤,我们得到了一个层次化的社区树:
顶层(最粗粒度):
├─ 篮球组(A、B、C、D)
├─ 音乐组(E、F、G)
└─ 学习组(H、I、J)第二层:
├─ 篮球组 → 分为 主力组(A、B)和替补组(C、D)
├─ 音乐组 → 分为 声乐组(E、F)和乐器组(G)
└─ 学习组 → 分为 学霸组(H、I)和学渣组(J)第三层:
└─ 所有小组无法再细分(如主力组不能再分)
在进行leiden算法之前进行节点的聚类。
- 获取最大联通子图
nano-graphrag/nano_graphrag/_storage/gdb_networkx.py
graph = NetworkXStorage.stable_largest_connected_component(self._graph) # 获取最大联通子图,不分析离散子图
在复杂网络中,可能存在多个不相连的子图(比如 A 和 B 没有任何联系)。为了简化问题,我们只处理最大的连通部分。
- 使用 Hierarchical Leiden 算法进行社区检测
community_mapping = hierarchical_leiden(graph,max_cluster_size=self.global_config["max_graph_cluster_size"],random_seed=self.global_config["graph_cluster_seed"],
)
输出结果类似 [{"node": "A", "level": 0, "cluster": "篮球组"}, {"node": "A", "level": 1, "cluster": "主力组"}]
- 初始化存储结构和遍历社区划分结果
node_communities: dict[str, list[dict[str, str]]] = defaultdict(list)
__levels = defaultdict(set)
for partition in community_mapping:level_key = partition.levelcluster_id = partition.clusternode_communities[partition.node].append({"level": level_key, "cluster": cluster_id})__levels[level_key].add(cluster_id)
node_communities = dict(node_communities)
__levels = {k: len(v) for k, v in __levels.items()}
logger.info(f"Each level has communities: {dict(__levels)}")
初始化两个数据结构,用于存储社区划分结果。
- node_communities:记录每个节点在不同层次上的社区归属(如每个同学属于哪些小组)。
- __levels:记录每个层次上的所有社区编号(如第一层有2个大组,第二层有4个小组)。
遍历 community_mapping,将每个节点的社区归属信息填充到 node_communities 和 __levels 中
- 调用子图生成方法
self._cluster_data_to_subgraphs(node_communities)
将社区划分结果传递给 _cluster_data_to_subgraphs 方法,进一步处理生成子图。其实就是将聚类的cluster信息放到每个图中的节点中
节点cluster信息, 隶属哪个层级,隶属哪个社区

1.2.5 构建社区报告
- 构建社区模板信息
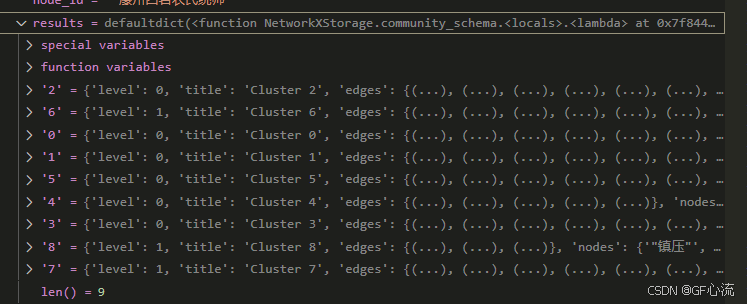
results:用于存储每个社区的详细信息。
每个社区(以 cluster_key 为键)包含以下字段:
level:社区所在的层次。
title:社区的名称。
edges:与该社区相关的边集合。
nodes:属于该社区的节点集合。
chunk_ids:与该社区相关的数据块 ID(如来源 ID)。
occurrence:社区出现的频率(归一化值)。
sub_communities:该社区的子社区列表。
max_num_ids:记录所有社区中最大的 chunk_ids 数量,用于计算 occurrence。
levels:记录每一层的所有社区编号。
- 遍历图中的节点,并更新社区信息
遍历节点所属的每个社区(cluster),更新对应社区的信息:
将社区编号添加到对应层次的集合中(levels)。
设置社区的层级(level)和标题(title)。
将当前节点添加到社区的节点集合中。
将与该节点相关的边添加到社区的边集合中。
将节点的来源 ID 添加到社区的 chunk_ids 集合中。
更新最大 chunk_ids 数量。
按照层次顺序,计算每个社区的子社区。
如果下一层的某个社区的所有节点都属于当前社区,则将其视为当前社区的子社区。
- 逆序遍历社区模板表格的内容,生成每个层级的社区报告
从子图开始生成对应的报告的内容_form_single_community_report
1、获取一个社区的描述
- 获取所有结点和所有边
- 将数据组织成:社区id+实体类别+实体描述+实体的度
- [0, ‘“二十四个来朱元璋队伍里找工作的人”’, ‘“ORGANIZATION”’, ‘“这二十四个人后来成为了朱元璋事业的基石,包括徐达、汤和和周德兴等关键人物。”’, 1]
- [1, ‘“军中的总管”’, ‘“ROLE”’, ‘“朱元璋担任过的职位,大致相当于起义军的办公室主任,负责管理和监督军队中的事务。”’, 1]
- 根据度进行排序,重要的结点放第一,同理边也是这样处理;然后两者根据大模型的上下文窗口进行截断。
- 如果数据超出 token 限制且存在子社区,则递归处理子社区。也可以通过配置强制使用子社区。调用 _pack_single_community_by_sub_communities 函数,递归生成子社区的描述。
2、使用prompt组装整个社区的描述,发送给大模型,返回结果
- 最终生成社区报告
{‘report_string’: ‘# 元朝及其影响\n\n元朝是中国历史上一个实施等级制度的朝代,其统治经历了腐败和最终被推翻的命运。元朝的末期,朱元璋推翻了蒙古统治建立了明朝。社会中的不同群体及其政策引发了广泛的社会不满,从而促使历史变革的到来。\n\n## 元朝的统治与腐败\n\n元朝是一个在中国历史上实施等级制度的朝代,其统治过程中体现了严重的腐败问题。蒙古人作为高等级统治者的身份,对南人等低等级群体进行压迫,这种压迫和不平等关系是社会矛盾激化的关键因素,不可避免地导致民众的广泛不满和反抗精神的崛起。\n\n## 朱元璋的历史角色\n\n朱元璋是元朝晚期的关键人物,他成功推翻了蒙古王朝的统治,建立了明朝,并成为明朝的开国皇帝。朱元璋的历史角色,作为逆境中崛起的领袖,体现了社会变革和反抗压力的作用,为后来的政治和社会秩序带来了根本性变化。\n\n## 徭役对社会的影响\n\n徭役作为元朝统治期间的一项政策,对于民众而言代表着严重的负担。元朝强迫民众参与河堤等工程的无偿劳动,不仅消耗了人们的生活资源,也进一步加剧了元朝与农民之间的紧张关系。和平民百姓对政府的不满和反抗情绪的升级,徭役政策进一步恶化了这一情势。\n\n## 南人的地位及其遭遇\n\n南人作为元朝统治下的低等人群体,常常遭受蒙古人的压迫。这种压迫体现在经济和政治方面的不公平待遇,导致社会团结的瓦解和反抗的种子逐渐生长。南人的命运是元朝腐败统治的直接反映,也预示着元朝末期的动摇与衰败。\n\n## 社会矛盾与元朝的预兆\n\n元朝末期,"石人一只眼,挑动黄河天下反"成为了预示元朝末日的墓志铭。这不仅揭示了元朝统治的社会矛盾和衰败趋势,也暗示着社会反抗即将来临。这些矛盾最终推动了朱元璋这样的领袖组织起反抗力量,终结了蒙古人的统治。’, ‘report_json’: {‘title’: ‘元朝及其影响’, ‘summary’: ‘元朝是中国历史上一个实施等级制度的朝代,其统治经历了腐败和最终被推翻的命运。元朝的末期,朱元璋推翻了蒙古统治建立了明朝。社会中的不同群体及其政策引发了广泛的社会不满,从而促使历史变革的到来。’, ‘rating’: 8.0, ‘rating_explanation’: ‘影响严重性评分为较高,反映了元朝统治期间的政治腐败和使用强制手段对人民的影响,以及等级压迫引发的社会紧张,这些都是推动革命发生的潜在因素。’, ‘findings’: […]}, ‘level’: 0, ‘title’: ‘Cluster 0’, ‘edges’: [[…], […], […], […], […], […], […], […], […], […], […]], ‘nodes’: [‘“元朝”’, ‘“明朝”’, ‘“中国”’, ‘“石人一只眼,挑动黄河天下反”’, ‘“南人”’, ‘“徭役”’, ‘“蒙古人”’, ‘“朱五四”’], ‘chunk_ids’: [‘chunk-90074c0167f1b96f110e0701bbd3370b’, ‘chunk-9a76d8ffa3427c606f749054f4201706’, ‘chunk-8091a468687529ab4647eec0e9f0e1dc’, ‘chunk-2c6a57e1314b2c844652242279238744’], ‘occurrence’: 0.5714285714285714, ‘sub_communities’: []}
report_string就是社区报告,同时还会生成findings部分的内容
1.3 local查询
- 用户的输入转成embedding和VDB中的向量【实体名称+描述】进行相似度的计算
{'__id__': 'ent-1e497bb0c42616252d466d61aeae80e3', 'entity_name': '"濠州"', '__metrics__': 0.5388440280607757, 'id': 'ent-1e497bb0c42616252d466d61aeae80e3', 'distance': 0.5388440280607757}
- 根据实体名称,召回实体结点+结点的度
{'entity_type': '"GEO"', 'description': '"濠州是指文本中提到的战争发生的地点,是郭子兴和孙德崖为首的四人小组的所在地。"<SEP>"濠州是朱元璋活动的重要地理位置,是他从郭子兴手中脱离并开始自己事业的地方。"', 'source_id': 'chunk-41fce71cb1f6198f0eb409c3481892ec<SEP>chunk-4bdd775f30019125ecf386a970f73cb9', 'clusters': '[{"level": 0, "cluster": 2}, {"level": 1, "cluster": 7}]', 'entity_name': '"濠州"', 'rank': 3}
- 根据召回回来的结点,找到最关联的社区、文本块、关系
- _find_most_related_community_from_entities
- 现在0,1,2层级进行社区的检索,并召回对应的社区报告
- 统计各个社区的频次,按照高到低排序,再按社区的ranking排序,召回top的社区报告的内容
- 然后再进行内容的划分,不超过一定的模型上下文的长度
- _find_most_related_text_unit_from_entities
- 提取节点关联的文本单元:从节点数据中提取所有相关的文本单元 ID。
- 获取邻居节点及其关联的文本单元:找出一跳邻居节点及其关联的文本单元。
- 一跳的节点存在上下文,当前的文本块在一条节点的正文引用中,这样的关系加一
- 统计文本单元的相关性:根据与邻居节点的关联次数,评估文本单元的重要性。
- 排序文本单元:按优先级和相关性对文本单元进行排序。
- 截断结果:根据 token 限制截断文本单元列表,并返回最终结果。
- _find_most_related_edges_from_entities
- 获取所有的边
- 获取边的度
- 按照度、权重排序
- 截断结果,满足LLM的上下文窗口长度
- _find_most_related_community_from_entities
1.4 global查询
1、获取社区模板
results:用于存储每个社区的详细信息。
每个社区(以 cluster_key 为键)包含以下字段:level:社区所在的层次。title:社区的名称。edges:与该社区相关的边集合。nodes:属于该社区的节点集合。chunk_ids:与该社区相关的数据块 ID(如来源 ID)。occurrence:社区出现的频率(归一化值)。sub_communities:该社区的子社区列表。max_num_ids:记录所有社区中最大的 chunk_ids 数量,用于计算 occurrence。levels:记录每一层的所有社区编号。
2、社区优先使用012层级的社区,同时使用社区的重要性进行降序排序,再进一步卡社区总数的上限
3、获取社区的报告
4、再根据setting中的global_min_community_rating进行筛选社区报告中的内容
5、再按照社区出现的频率、社区的rating进行排序
- 每个社区内部先进行裁剪字数
- 然后每个社区都需要对query进行内容的回答,内容的回答+评分
- 筛选评分以及对应的答案,再进行内容的裁剪
6、组合prompt,最后发给大模型进行内容的回答。
二、总结
local search中构建文本块中的实体和关系的映射,这点对于多路召回是有意义的。并且graphrag比较适合的场景是,原本有良好知识图谱的业务场景。不过global这个思路,可以运用在多文档召回上,不仅仅局限在单篇文章。