【Linux】环境变量 程序地址空间
🌻个人主页:路飞雪吖~
🌠专栏:Linux
目录
🌠命令行参数:
🌟基本概念
🌟常见环境变量
✨<1> PATH : 指定命令的搜索路径
✨<2> HOME : 指定用户的主工作目录
✨<3> SHELL : 当前Shell,它的值通常是/bin/bash
✨<4> PWD:保存当前进程所在的工作路径
✨<5> USER:获取当前登录的用户
🌟查看环境变量的方法
🌟环境变量的相关命令
🌠环境变量 vs 本地变量
🌠小贴士:
🌟程序地址空间
🌠虚拟地址/线性地址:
🌟进程地址空间
🌠小贴士:
✨页表
✨地址空间mm_struct
🌠小贴士:
🌠 为什么要有虚拟地址空间和页表?
🌠命令行参数:
我们使用的所有指令是用C语言或者是其他语言写的,指令中的选项是通过命令行参数来实现的,命令行参数列表使得同一个程序,可以根据命令行参数,根据选项的不同,表现出不同的功能。比如:指令中选项的实现!
• main 函数的参数是谁传递的?
这个字符串首先是被命令行解释器(shell)【进程】拿到的,shell 拿到之后,首先把上面的命令按照空格打散,形成一张表(argv)和元素个数(argc)。命令行启动的程序,父进程都是shell,所以命令和shell命令行是父子关系。
如果对于一个全局变量,父子进程都不修改,对于全局变量父子进程只进行读取,并不会进行拷贝,即 对于数据(尤其是只读),子进程也能看到!
• 命令行参数它的打散和形成的过程是由shell(父进程)来做的,在命令行里面执行的命令和启动的程序是子进程,子进程是通过让shell以 fork() 的形式创建出来的,换句话说,如果shell打散之后形成了全局的 argc 和 argv[] 的表结构,这个表的内容它也不改变了(命令行参数不需要改),所以子进程也能读到,子进程把读到的对应命令行参数 argc 和 argv[] 传递给main函数就可以了。
• 编译器、操作系统、加载器,不是相互割裂的,是彼此有关系的!


🌟基本概念
• 环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数。
• 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
• 环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性。

每一个进程都有一个环境变量表,这个环境变量表是继承于它的父进程的!
🌟常见环境变量
✨<1> PATH : 指定命令的搜索路径
✨<1> PATH : 指定命令的搜索路径 。本质是内存级的变量,是在shell内部维护起来的,我们可以通过一定的命令行方式来改环境变量,改了之后我们就可以直接执行我们的程序,不用带路径。
如果不想带路径,让自己写的可执行程序运行起来:
• 可以把自己写的可执行程序拷贝到 /usr/bin 目录下,就可以不带路径去执行自己写的可执行程序;
• 把自己的路径,添加到PATH中。(此时PATH是一个内存级的数据)
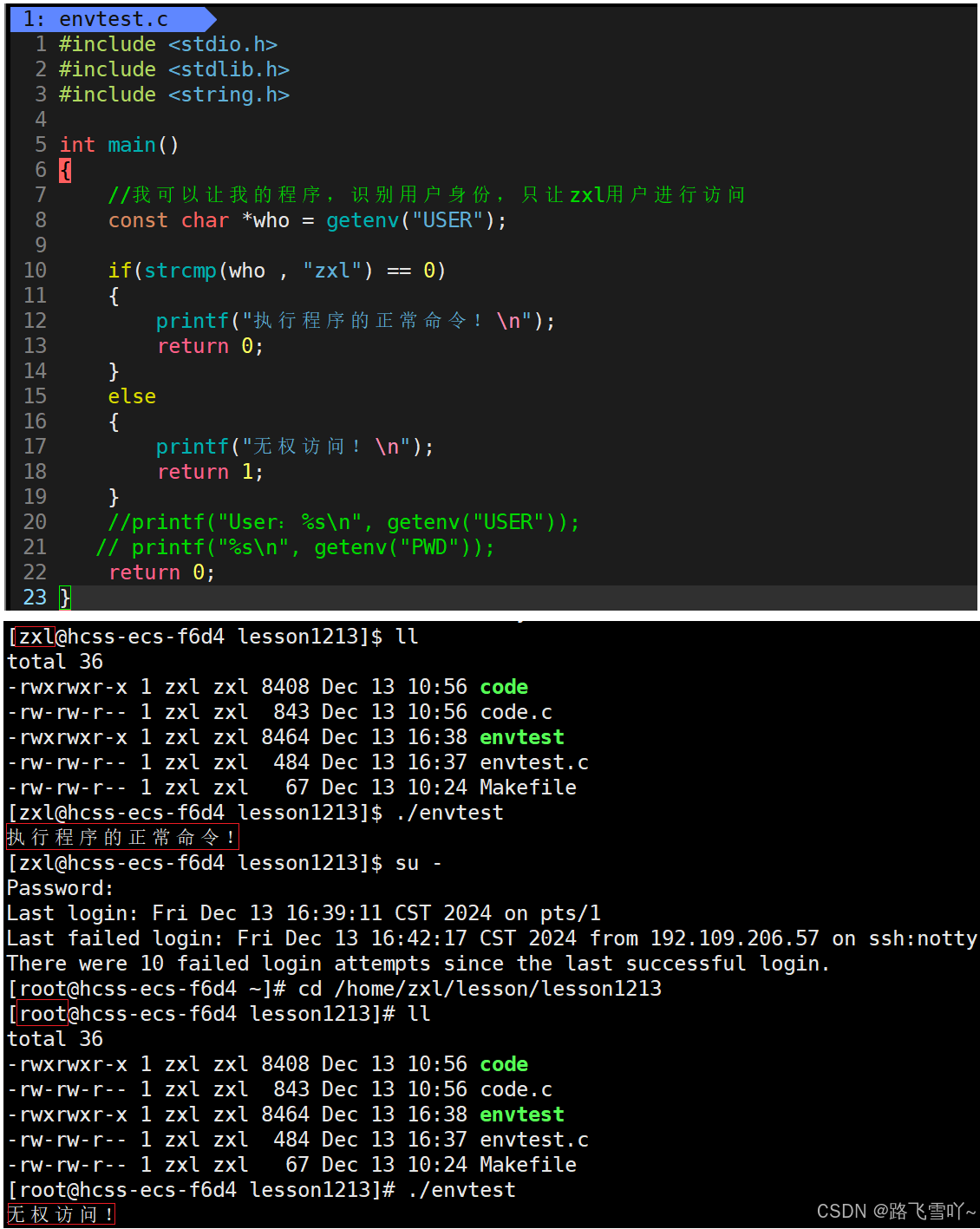
我们在写完一个可执行程序code时,要执行这个可执行程序要输入指定路径(./当前路径) “./code” 命令行才能找的这个可执行程序并且去执行它,我们也可以把我们写的这个可执行程序拷贝到 " /usr/bin" 目录下就可以只写程序名"code"就可以执行,而像 "ls、pwd..." 这些命令并不需要指定路径编译器就能找到它并且去执行,为什么系统知道,这些命令在 " /usr/bin " 路径下?因为PATH环境变量,告诉了shell,它应该去哪一个路径下查指令!

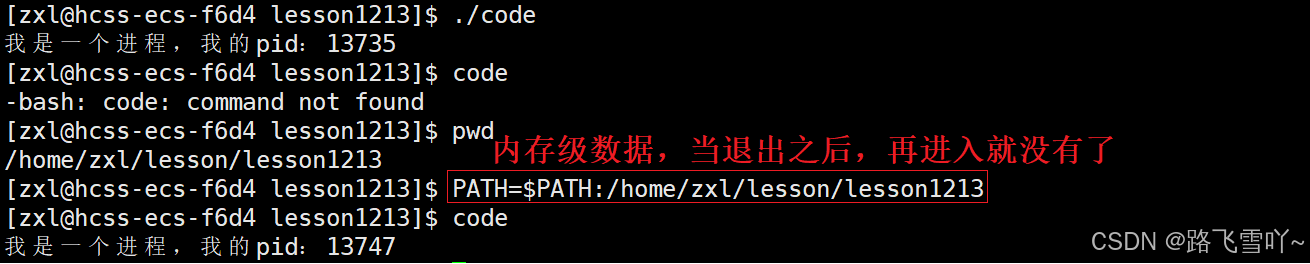
$PATH的内容,最开始是从哪里来的?最开始肯定不在内存里面,大部分的环境变量最开始时一定是在系统的配置文件当中的! 我们登录 -> 启动一个shell进程 -> 读取用户和系统相关的环境变量的配置文件 -> 形成自己的环境变量表 -> 创建的子进程就能拿到这个表里面的内容。
所以我们在命令行直接修改完 PATH环境变量之后,这个PATH环境变量只是一个内存级的数据,如果我们想让一个环境变量永久有效,就要找到它的环境变量的配置文件进行修改。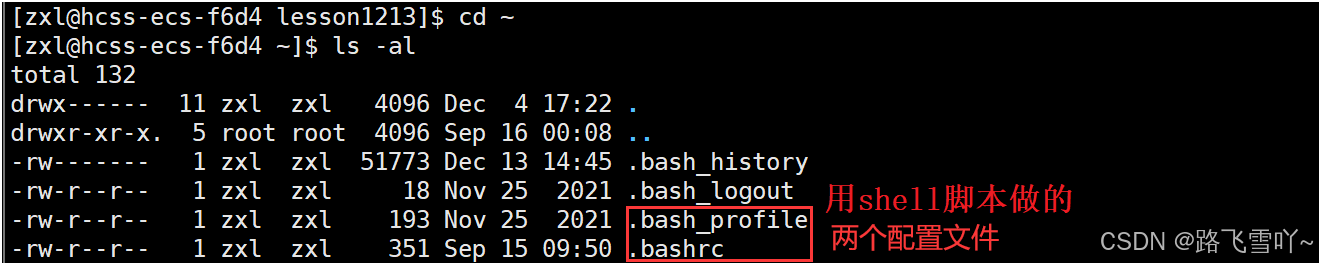 当我们的bash启动时,bash就会读取这两个配置文件,来形成自己的环境变量信息,所以默认登录的时候都会默认是处在自己的家目录的,只有在自己的家目录下才能找到约定好的这两个配置文件。
当我们的bash启动时,bash就会读取这两个配置文件,来形成自己的环境变量信息,所以默认登录的时候都会默认是处在自己的家目录的,只有在自己的家目录下才能找到约定好的这两个配置文件。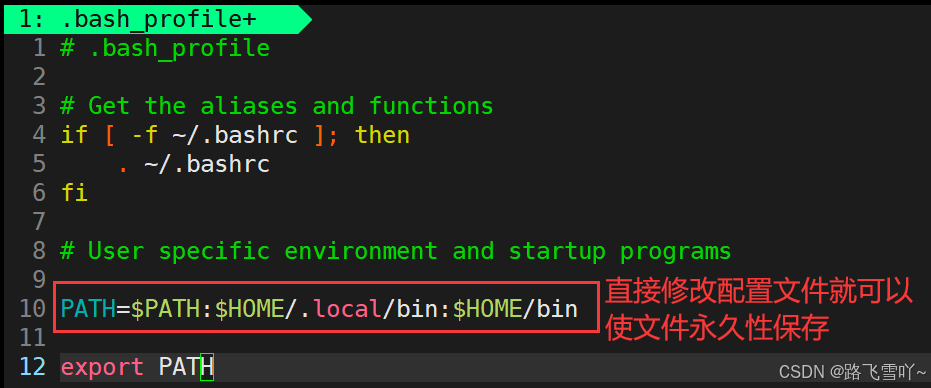
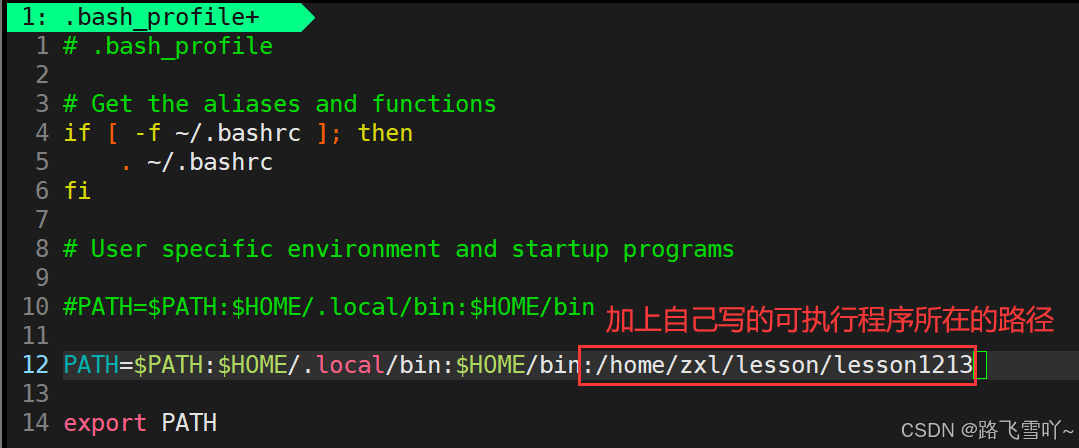

修改完成之后,自己写的可执行程序退出之后,还保留着,再次登录还能执行。
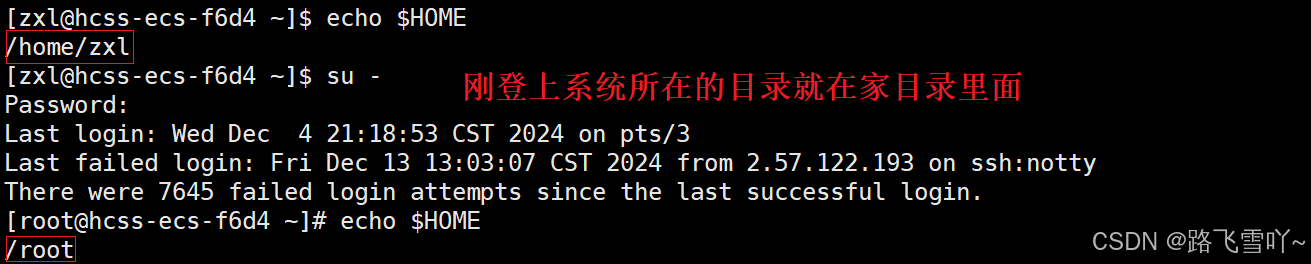
我们知道每启动一个进程,进程内部都会记录是谁启动的这个进程(uid),在启动进程的时候,系统中的环境变量早就已经写了user是谁,并且把该进程的uid写入到进程的pcb中了。
✨<2> HOME : 指定用户的主工作目录
✨<2> HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
当我们登录系统的时候,系统首先会给我的用户创建bash来给我们做准备,bash就要读取对应环境变量相关的一些配置文件,然后配置自己相关的环境变量(PATH、HOME...来初始化),所以在你还没登录你的环境变量就已经被设置好了,
bash也是一个进程(cwd),它会设置自己的cwd,它会把自己(bash)的cwd设置成我们读到的HOME环境变量。
所有命令行启动的进程都是bash的子进程! 这些子进程的task_struct的属性大多是从父进程里面拷贝进来的(进程的代码可以是共享的,但是数据是自己各自私有的一份)以父进程为模板,包括属性cwd,子进程的cwd是继承bash(父进程)的当前工作路径的!

✨<3> SHELL : 当前Shell,它的值通常是/bin/bash
✨<3> SHELL : 当前Shell,它的值通常是/bin/bash。
SHELL会记录下来,当前用户在登录时,启动的是哪一个SHELL,所以 /bin/bash 就会把SHELL相关的可执行程序的路径和程序给记录下来。

✨<4> PWD:保存当前进程所在的工作路径
✨<4> PWD:保存当前进程所在的工作路径。
获取环境变量的方式:
• 通过环境变量来获取当前进程所处的工作路径:
所以进程能获取自己所在的路径,例如:新建文件 "log.txt" --> get("PWD")/filename

✨<5> USER:获取当前登录的用户
✨<5> USER:获取当前登录的用户
环境变量是系统提供的具有”全局“属性的变量!
🌟查看环境变量的方法
echo $NAME // NAME:你的环境变量名称例如:
echo $PATH🌟环境变量的相关命令
| echo | 显示某个环境变量的值 |
| export | 设置一个新的环境变量 |
| env | 显示所有的环境变量 |
| unset | 清除环境变量 |
| set | 显示本地定义的shell变量和环境变量 |
🌠环境变量 vs 本地变量
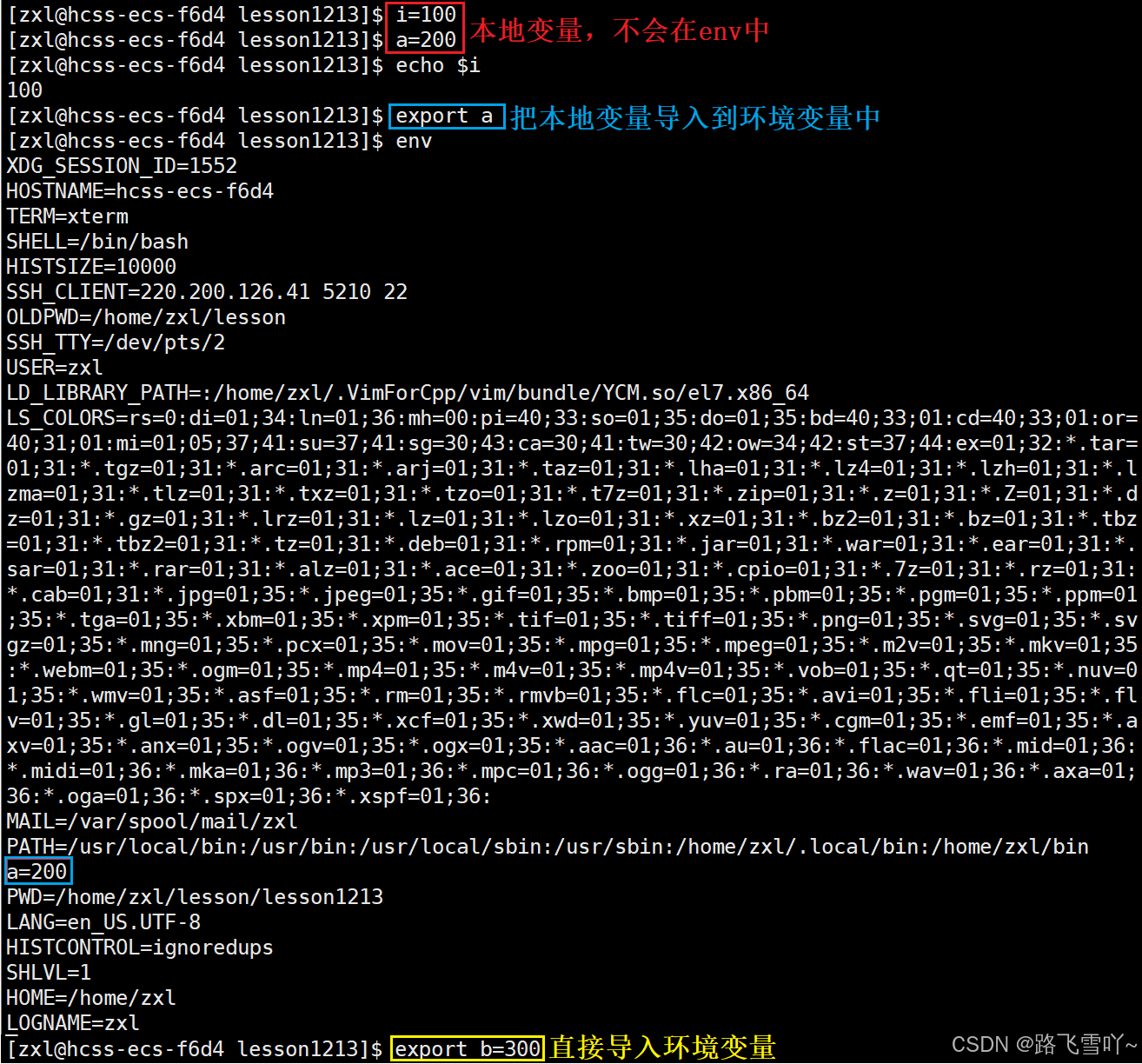
环境变量可以被子进程继承下去,而本地变量不能。
环境变量可以被所有bash之后的进程全部看到,所以,环境变量具有”全局属性“!!!
• 系统的配置信息,尤其是具有"指导性"的配置信息,它是系统配置起效的一种表现;
• 进程具有独立性!环境变量可以用来进程间传递数据(只读数据!!!)。

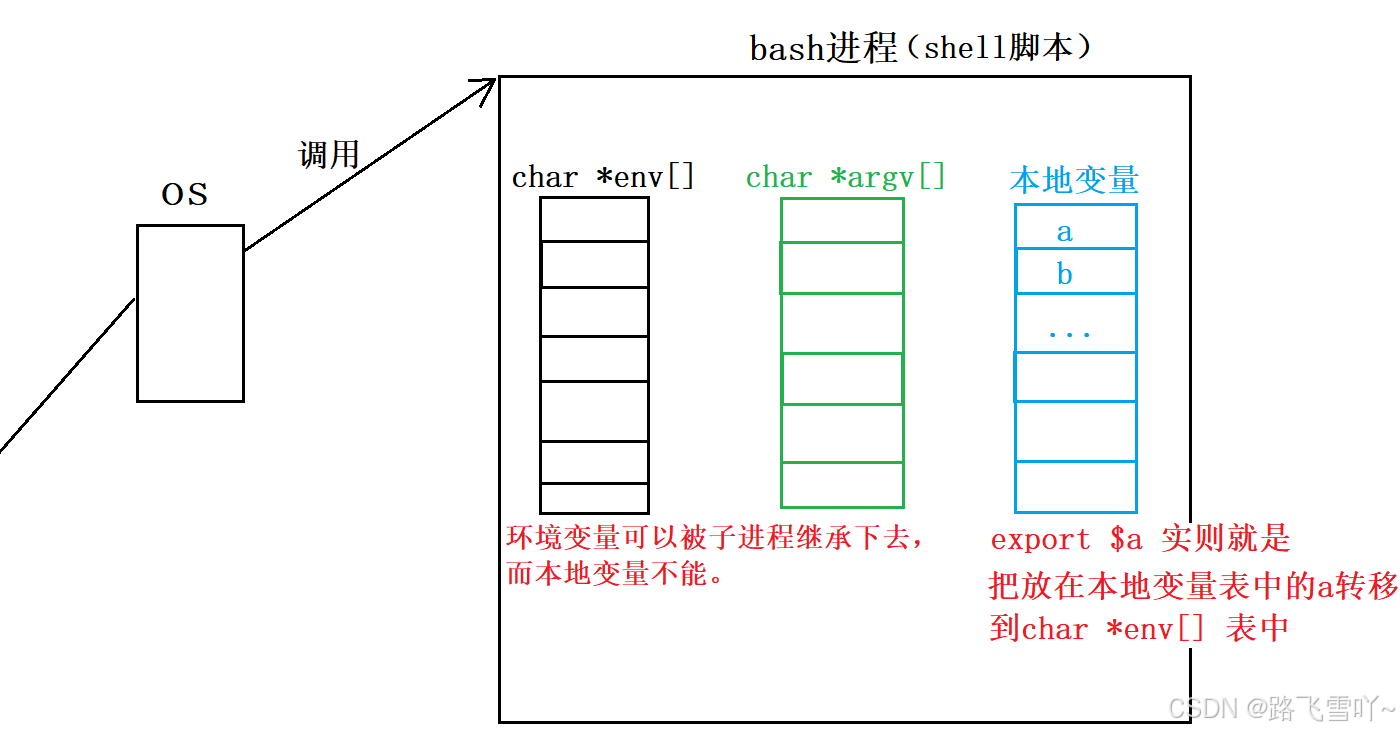
🌠小贴士:
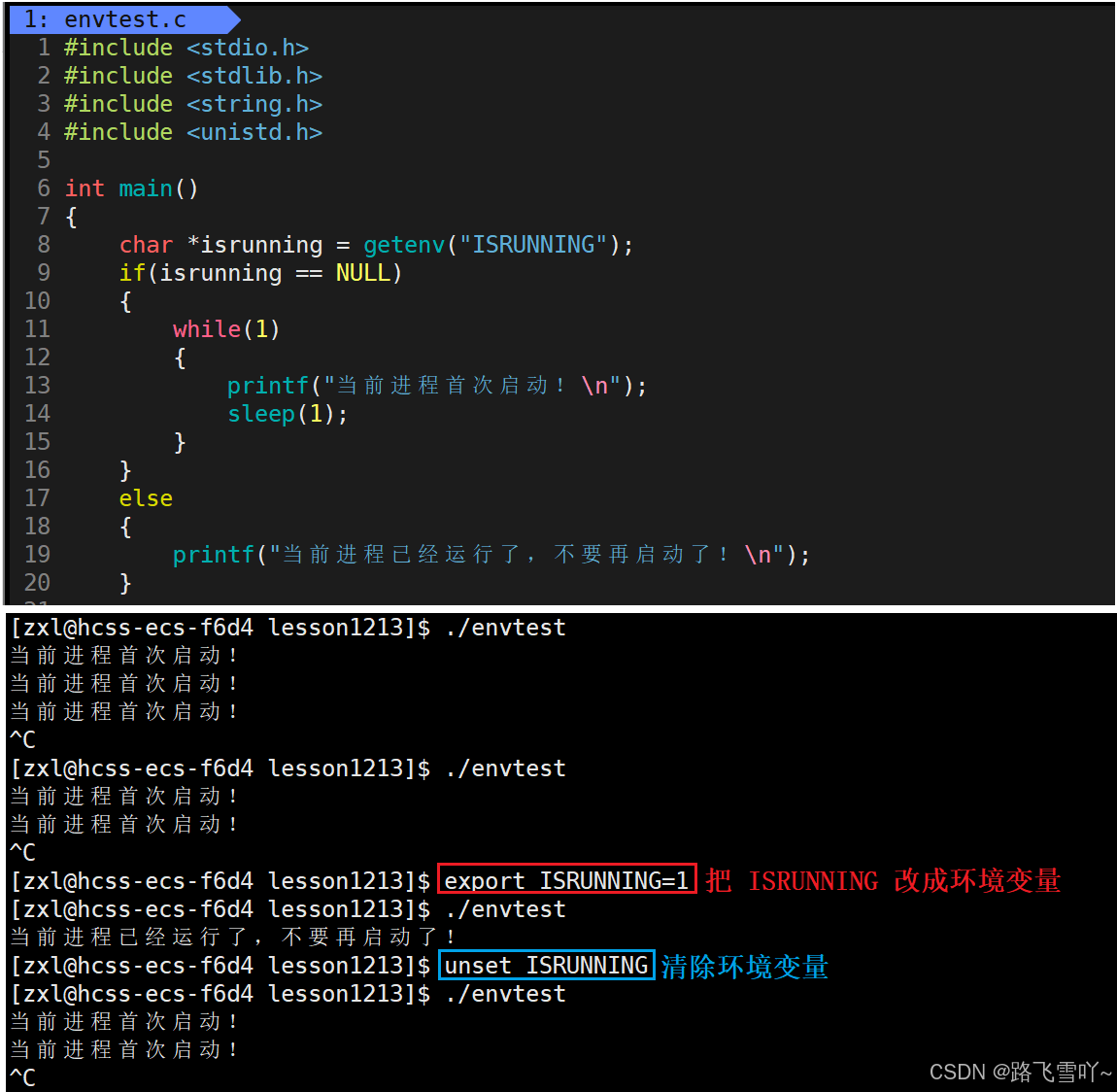
环境变量是系统配置的一大批的基本信息。环境变量是一种系统当中"全局"有效的基本信息,这种配置信息主要是用来,让每一个子进程都能获得配置信息,当需要获得系统的配置信息,我们可以通过获取 "getenv()" 的方式来进行获取。
🌟程序地址空间
在C语言中程序的空间地址是这样的:
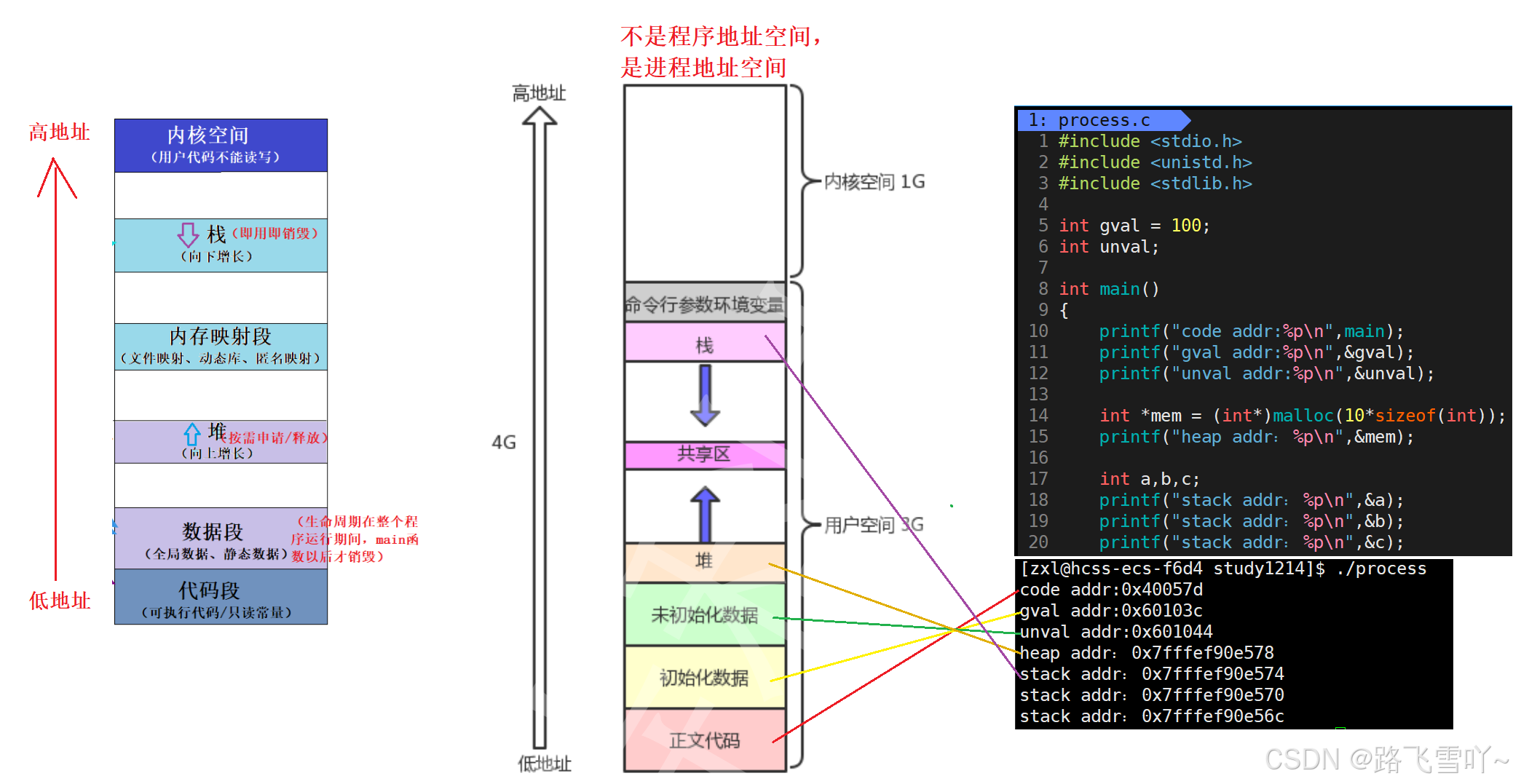
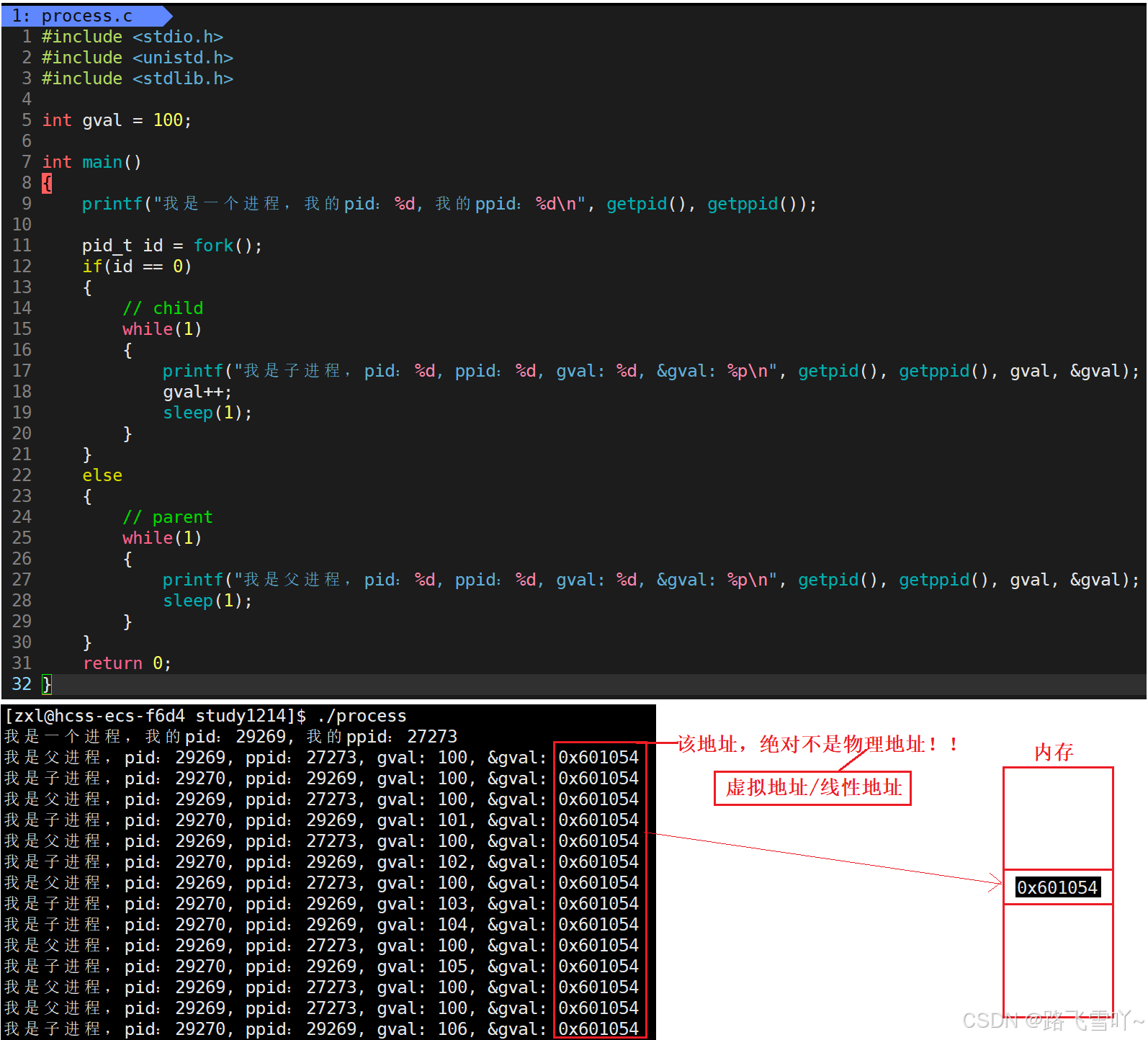 我们知道父子进程的代码是共用的,数据是私有一份的,那为什么父子进程所指向的全局变量的地址都是一样的?我们只能确定该地址,绝对不是物理地址!!---> 虚拟地址/线性地址。
我们知道父子进程的代码是共用的,数据是私有一份的,那为什么父子进程所指向的全局变量的地址都是一样的?我们只能确定该地址,绝对不是物理地址!!---> 虚拟地址/线性地址。
🌠虚拟地址/线性地址:
<1> 地址空间
• 进程对虚拟地址空间“先描述,再组织”,虚拟地址空间本质是一个内核数据结构对象(类似PCB)。
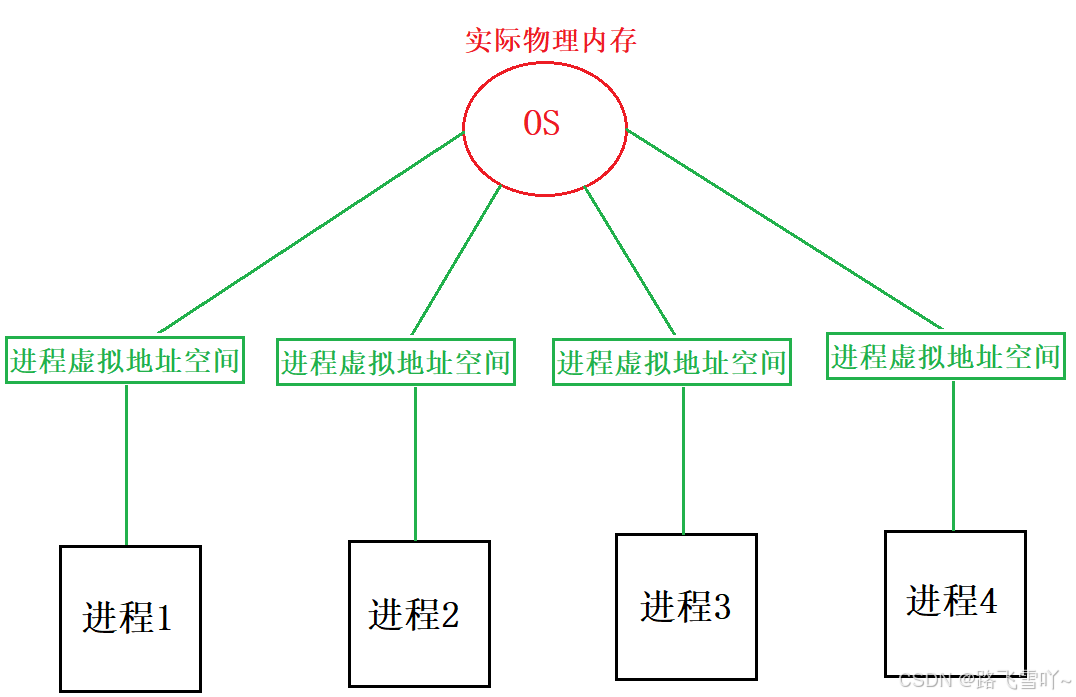
操作系统分别告诉所有进程自己有多少的内存空间,然后对每个进程的内容进行"先描述,再组织”对进程进行管理,即:让每个进程都认为自己是独占系统物理内存大小,进程彼此之间不知道,不关心对方的存在,从而实现一定程度的隔离!
当我们创建一个进程的时候,会有一个 task_struct ,我们不能让task_struct直接去访问物理内存,因为会直接访问到物理地址,为此操作系统就在进程和物理内存之间设计了一种数据结构struct mm_struct,task_struct 内部会有一个指向 struct mm_struct 的指针,struct mm_struct 当前进程的进程地址空间,即每一个进程都是通过 struct mm_struct 来进行访问物理内存的。
<2> 区域划分
空间区域划分的本质:只需知道开始和结束的两个整型变量即可。
<3> 地址空间上的地址
• 地址本质就是一个数字,可以被保存在unsigned long (4字节);
• 空间范围内的地址,我们可以随便用,暂时不需要记录它的地址。
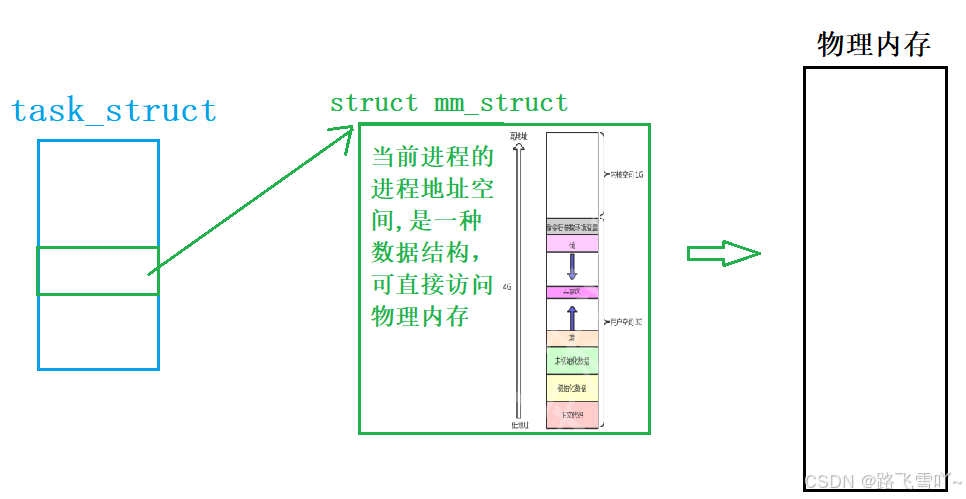
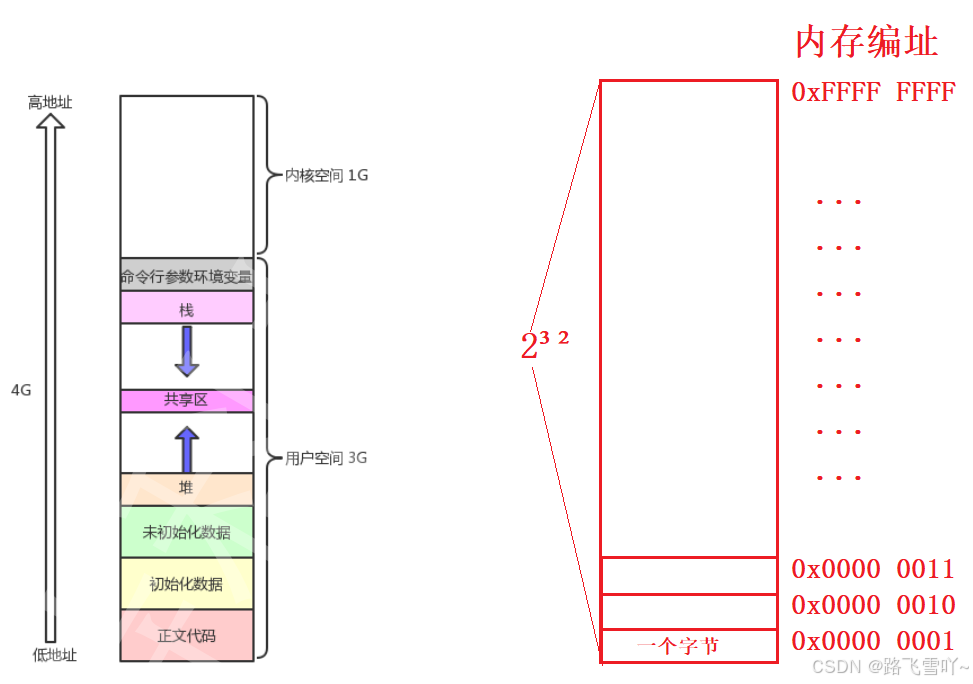
🌟进程地址空间
每个进程都有自己的 task_struct (PCB),里面存在struct mm_struct(进程的虚拟地址空间),struct mm_struct 会记录下来一个进程所对应的各个代码区域的信息,一个进程的所有代码数据都应该保存在物理内存当中,即可执行程序被加载到内存当中,每一行代码都有自己的物理地址。操作系统给每个进程构建一张页表,操作系统在创建进程加载代码的时候,它会把当前地址空间的虚拟地址和物理地址构建映射关系 这张页表会把代码的物理地址和虚地址给映射到一起,作为用户我们看不到物理地址,只能看到虚拟地址,即当我们写入一个 gval = 100, 编译器会拿到的是虚拟地址,然后去写入100,当前进程会根据这个虚拟地址,查找对应页表,根据虚拟地址映射对应的物理地址,然后在物理内存的空间当中写入数据100,此时就写入完成。

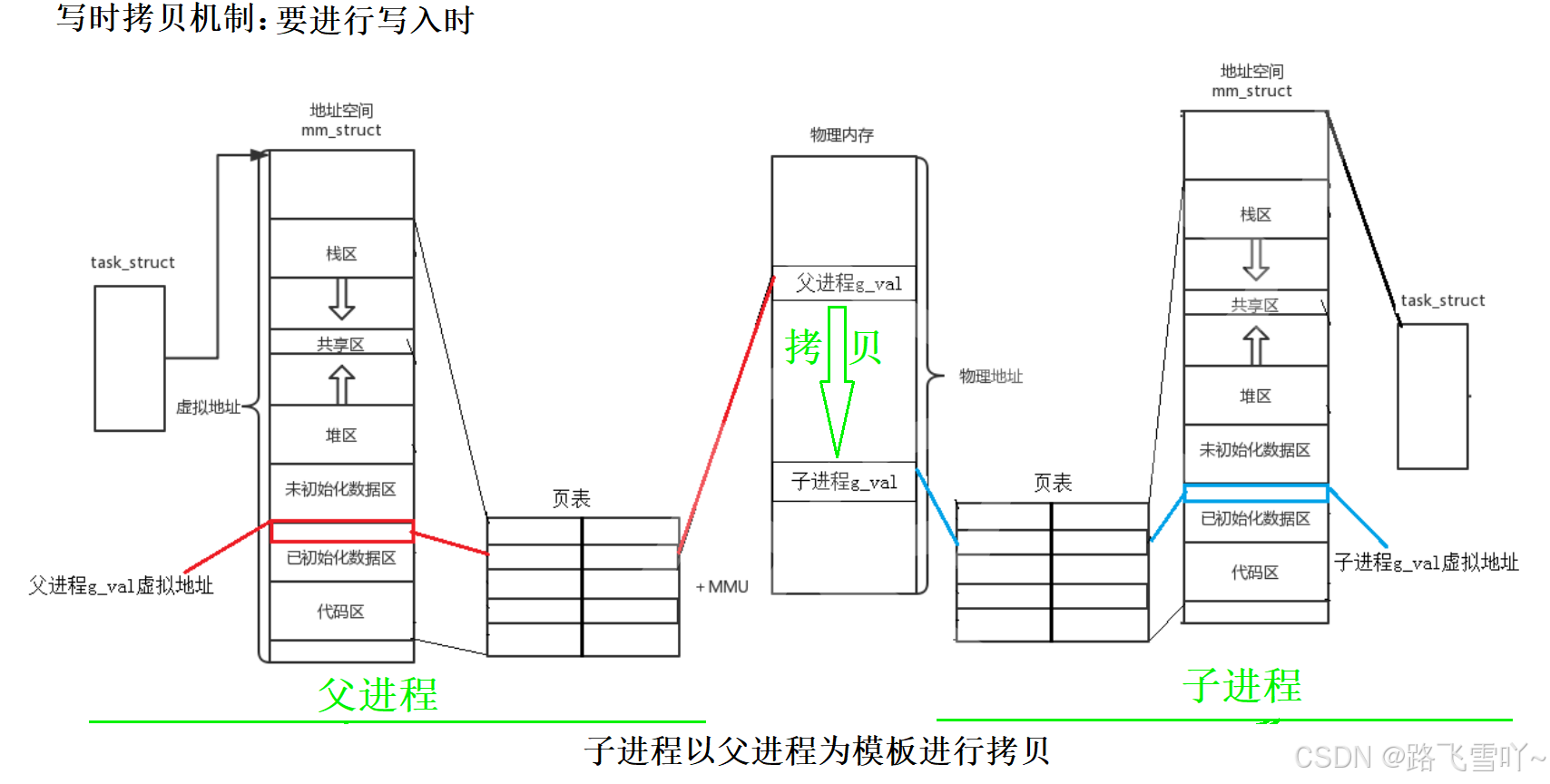
当创建子进程的时候,以父进程为模板进行创建:struct task_struct 、struct mm_struct ,此时struct mm_struct里面的虚拟地址也是可以被父进程看到的,刚开始时子进程被创建没有代码没有数据它只能从父进程继承下来(继承父进程PCB和父进程所有的虚拟地址空间、父进程所对应的页表),页表里面的内容映射到父进程的代码区域,所以父进程和子进程指向同样的区域(父子代码共享),在父子进程不修改变量时,数据其实也是共享的!当父/子进程修改变量时,即写入时,进程是具有独立性的,操作系统就会在内存里面重新申请一份内存空间,然后把没被修改的内存空间里面的内容拷贝到新申请的内存空间,接着修改页表的物理地址(改为新申请的物理地址),子进程就不再指向父进程没修改内容的空间,转而指向新申请的内存空间的地址。拷贝修改的这种机制由操作系统自主完成,称为操作系统的写时拷贝机制!即默认不会进行拷贝,当需要修改时,才会进行拷贝。这种机制使得在上层用户拿到父/子进程的虚地址不变,但是父/子进程却访问到了不同的内容。因此我们上面写的代码明明子进程都修改了,但是打印出来的变量地址和父进程变量的地址是一样的,原因是因为我们看到的是 虚拟地址。
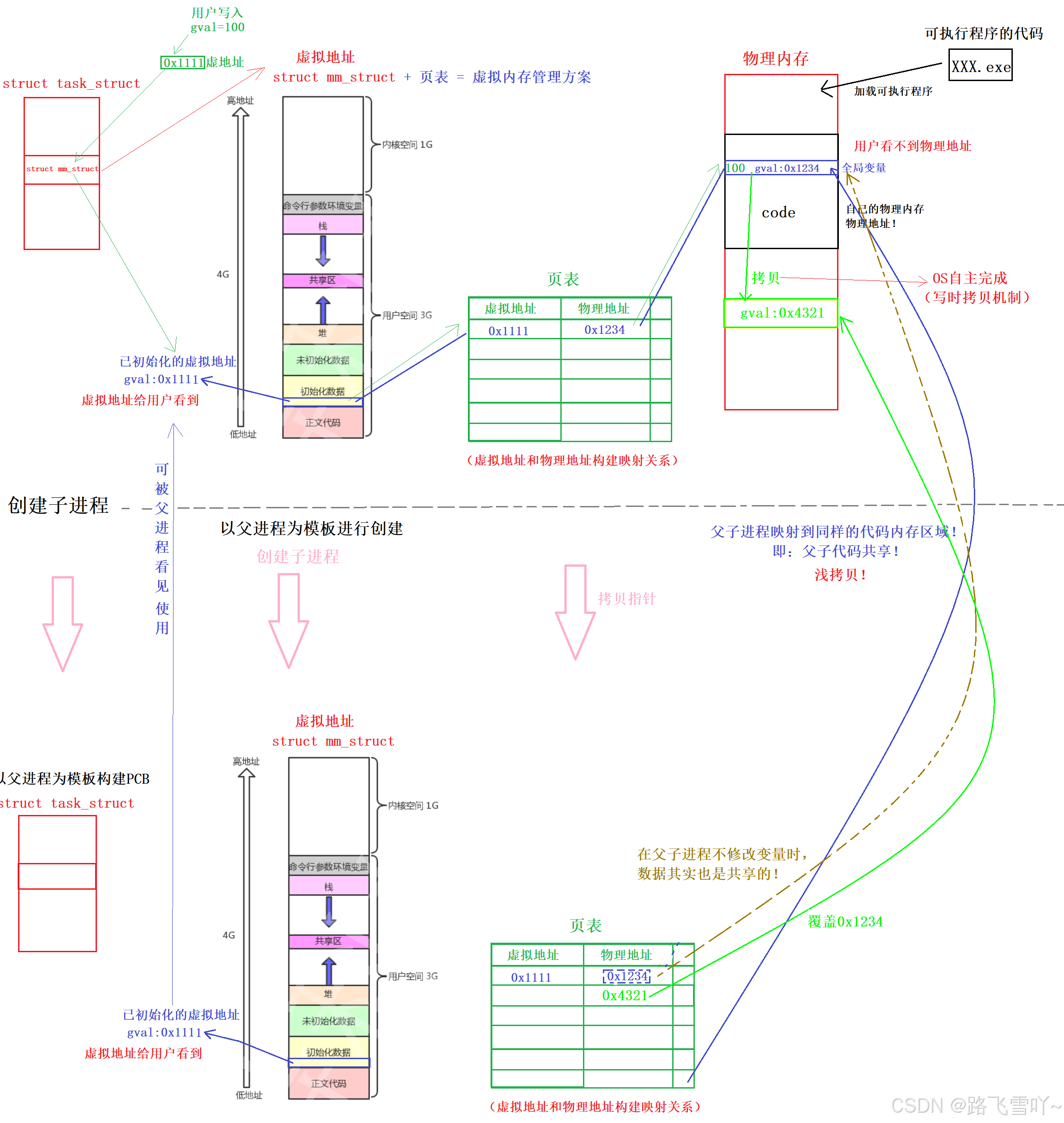
🌠小贴士:
(1)关于变量和地址
当我们在编译器里面写入变量(int a = 10)时,编译完后,这个变量名已经不在了,已经变成了地址。所以变量名在被我们使用时,它本质就是地址。
(2)进程和进程的独立性
• 进程 = 内核数据结构(task_struct、struuct mm_struct、页表)+ 自己的代码和数据
• 父进程和子进程中的 task_struct、struuct mm_struct、页表、[子进程修改后]数据 都是私有一份的,即 内核数据结构 和 自己的代码和数据 都是各自私有的一份。
✨页表
像某种数据结构(map)进行一一映射,页表里面有很多标记位。
(1)权限rwx:记录该进程的读写执行权限。
(2)isexists:记录目标内容是否在内存中
• 分批加载
• 挂起等操作
✨地址空间mm_struct
结构体变量,就必须初始化。每个区域在编译的时候,在磁盘中区域的大小就已经在自己的可执行程序中记录下来了,可执行程序在编译的时候,就已经按照特定的大小对可执行程序进行分段了。
🌠小贴士:
<1> 可执行程序:
• 本身就已经提前分区了,所以我们可以分区加载出来;
• 包含属性:分区多大,从哪开始,到哪里结束......
<2> 全局变量、字符常量 都是全局属性,在运行期间都会有效,因为在虚拟地址空间中,全局变量会随着进程一直存在,全局变量的虚拟地址,会一直被看到。

🌠 为什么要有虚拟地址空间和页表?
<1> 当在进行操作的时候,要在页表转化一次,成功之后才能访问到内存,不成功就不能访问内存,即:允许操作系统去拦截请求。虚拟地址空间和页表:保护内存。
我们写程序是遇到野指针,往往程序就会崩溃,根本原因是因为指向的虚拟地址在页表上根本就不对(相关的权限不对、没有形成相应的映射),系统就会杀掉这个进程,所以程序就会崩溃。
<2> 进程管理 和 内存管理 在系统层面上进行解耦合了。
当在内存申请空间时,内存只会给你开辟空间,并需要知道你要这个空间来做什么,进程被创建和内存管理关系不大。
<3> 让进程以统一的视角看待物理内存。
代码和数据加载到物理内存的任意地方,并不影响当前进程去运行,进程通过页表映射,进程的虚拟空间地址中的代码区、数据、堆区、栈区...永远都在一起,即只要有统一的虚拟地址空间通过页表映射的时候,即便把代码数据映射到物理内存的任意位置,在进程看来永远都是代码区、数据、堆区、栈区...,全都可以按照一定规则去统一呈现,只是大小有变化。即 把 “无序” 变为 “有序”。
如若对你有帮助,记得关注、收藏、点赞哦!您的支持是我最大的动力🌹🌹🌹🌹!!!
若有误,望各位,在评论区留言或者私信我 指点迷津!!!谢谢^ ^ ~