flink sink kafka的事务提交现象猜想
现象
查看flink源码时 sink kafka有事务提交机制,查看源码发现是使用两阶段提交策略,而事务提交是checkpoint完成后才执行,那么如果checkpoint设置间隔时间比较长时,事务未提交之前,后端应该消费不到数据,而观察实际现象为写入kafka的消费数据可以立马消费。
测试用例
测试流程
- 编写任务1,设置较长的checkpoint时间,并且指定 CheckpointingMode.EXACTLY_ONCE,输出输出到kafka。
- 编写任务2消费任务的结果topic,打印控制台,验证结果。
- 根据现象查看源码,分析原因。
测试用例
测试任务1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(1000*60l, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointStorage("file:///flink/checkpoint");// 超时时间,checkpoint没在时间内完成则丢弃env.getCheckpointConfig().setCheckpointTimeout(50000L); //10秒env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(1);//最小间隔时间(前一次结束时间,与下一次开始时间间隔)env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
// 当 Flink 任务取消时,保留外部保存的 checkpoint 信息KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("test001").setGroupId("my-group")
// .setStartingOffsets(OffsetsInitializer()).setStartingOffsets(OffsetsInitializer.committedOffsets()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");// 从文件读取数据
// DataStream<SensorReading> dataStream = env.addSource( new SourceTest4.MySensorSource() );DataStream<String> map = kafkaSource.map(new MapFunction<String, String>() {@Overridepublic String map(String s) throws Exception {return s;}});Properties properties = new Properties();
// 根据上面的介绍自己计算这边的超时时间,满足条件即可properties.setProperty("transaction.timeout.ms","900000");
// properties.setProperty("bootstrap.servers", "127.0.0.1:9092");KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("192.168.65.128:9092").setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("test002").setValueSerializationSchema(new SimpleStringSchema()).build()).setKafkaProducerConfig(properties).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("flink-xhaodream-").build();map.sinkTo(sink);// 打印输出env.execute();测试任务2
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(1000*150l, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointStorage("file:///flink/checkpoint");
// 当 Flink 任务取消时,保留外部保存的 checkpoint 信息Properties properties1 = new Properties();
// properties1.put("isolation.level","read_committed");KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("test002").setGroupId("my-group2").setProperties(properties1).setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST)).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");kafkaSource.print(" test2接受数据");// 打印输出env.execute();测试结果分析
测试结果:
任务1开启后,无论是否执行checkpoint,任务checkpoint都可以正常消费数据,与预期不符合。
原因排查
查看kafkaSink 的源码,找到跟与两阶段提交相关的代码,1.18源码中TwoPhaseCommittingSink有重构。kafkasink实现TwoPhaseCommittingSink接口实现,创建Commiter和Writer。
@PublicEvolving
public interface TwoPhaseCommittingSink<InputT, CommT> extends Sink<InputT> {PrecommittingSinkWriter<InputT, CommT> createWriter(Sink.InitContext var1) throws IOException;Committer<CommT> createCommitter() throws IOException;SimpleVersionedSerializer<CommT> getCommittableSerializer();@PublicEvolvingpublic interface PrecommittingSinkWriter<InputT, CommT> extends SinkWriter<InputT> {Collection<CommT> prepareCommit() throws IOException, InterruptedException;}
}--------------------------------------
public class KafkaSink<IN>implements StatefulSink<IN, KafkaWriterState>,TwoPhaseCommittingSink<IN, KafkaCommittable> {private final DeliveryGuarantee deliveryGuarantee;private final KafkaRecordSerializationSchema<IN> recordSerializer;private final Properties kafkaProducerConfig;private final String transactionalIdPrefix;KafkaSink(DeliveryGuarantee deliveryGuarantee,Properties kafkaProducerConfig,String transactionalIdPrefix,KafkaRecordSerializationSchema<IN> recordSerializer) {this.deliveryGuarantee = deliveryGuarantee;this.kafkaProducerConfig = kafkaProducerConfig;this.transactionalIdPrefix = transactionalIdPrefix;this.recordSerializer = recordSerializer;}/*** Create a {@link KafkaSinkBuilder} to construct a new {@link KafkaSink}.** @param <IN> type of incoming records* @return {@link KafkaSinkBuilder}*/public static <IN> KafkaSinkBuilder<IN> builder() {return new KafkaSinkBuilder<>();}
-- 创建Committer@Internal@Overridepublic Committer<KafkaCommittable> createCommitter() throws IOException {return new KafkaCommitter(kafkaProducerConfig);}@Internal@Overridepublic SimpleVersionedSerializer<KafkaCommittable> getCommittableSerializer() {return new KafkaCommittableSerializer();}
-- 创建writer@Internal@Overridepublic KafkaWriter<IN> createWriter(InitContext context) throws IOException {return new KafkaWriter<IN>(deliveryGuarantee,kafkaProducerConfig,transactionalIdPrefix,context,recordSerializer,context.asSerializationSchemaInitializationContext(),Collections.emptyList());}@Internal@Overridepublic KafkaWriter<IN> restoreWriter(InitContext context, Collection<KafkaWriterState> recoveredState) throws IOException {return new KafkaWriter<>(deliveryGuarantee,kafkaProducerConfig,transactionalIdPrefix,context,recordSerializer,context.asSerializationSchemaInitializationContext(),recoveredState);}@Internal@Overridepublic SimpleVersionedSerializer<KafkaWriterState> getWriterStateSerializer() {return new KafkaWriterStateSerializer();}@VisibleForTestingprotected Properties getKafkaProducerConfig() {return kafkaProducerConfig;}
}KafkaWriter和KafkaCommitter源码,
在KafkaWriter中snapshotState方法中发现如果deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE的开启事务的判断逻辑。
class KafkaWriter<IN>implements StatefulSink.StatefulSinkWriter<IN, KafkaWriterState>,TwoPhaseCommittingSink.PrecommittingSinkWriter<IN, KafkaCommittable> {
.... 省略代码 @Overridepublic Collection<KafkaCommittable> prepareCommit() {if (deliveryGuarantee != DeliveryGuarantee.EXACTLY_ONCE) {return Collections.emptyList();}// only return a KafkaCommittable if the current transaction has been written some dataif (currentProducer.hasRecordsInTransaction()) {final List<KafkaCommittable> committables =Collections.singletonList(KafkaCommittable.of(currentProducer, producerPool::add));LOG.debug("Committing {} committables.", committables);return committables;}// otherwise, we commit the empty transaction as is (no-op) and just recycle the producercurrentProducer.commitTransaction();producerPool.add(currentProducer);return Collections.emptyList();}@Overridepublic List<KafkaWriterState> snapshotState(long checkpointId) throws IOException {
-- 开启事务判断
if (deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE) {currentProducer = getTransactionalProducer(checkpointId + 1);currentProducer.beginTransaction();}return Collections.singletonList(kafkaWriterState);}
。。。。。
}查看 KafkaCommitter的commit()方法发现producer.commitTransaction();操作
/*** Committer implementation for {@link KafkaSink}** <p>The committer is responsible to finalize the Kafka transactions by committing them.*/
class KafkaCommitter implements Committer<KafkaCommittable>, Closeable {private static final Logger LOG = LoggerFactory.getLogger(KafkaCommitter.class);public static final String UNKNOWN_PRODUCER_ID_ERROR_MESSAGE ="because of a bug in the Kafka broker (KAFKA-9310). Please upgrade to Kafka 2.5+. If you are running with concurrent checkpoints, you also may want to try without them.\n"+ "To avoid data loss, the application will restart.";private final Properties kafkaProducerConfig;@Nullable private FlinkKafkaInternalProducer<?, ?> recoveryProducer;KafkaCommitter(Properties kafkaProducerConfig) {this.kafkaProducerConfig = kafkaProducerConfig;}@Overridepublic void commit(Collection<CommitRequest<KafkaCommittable>> requests)throws IOException, InterruptedException {for (CommitRequest<KafkaCommittable> request : requests) {final KafkaCommittable committable = request.getCommittable();final String transactionalId = committable.getTransactionalId();LOG.debug("Committing Kafka transaction {}", transactionalId);Optional<Recyclable<? extends FlinkKafkaInternalProducer<?, ?>>> recyclable =committable.getProducer();FlinkKafkaInternalProducer<?, ?> producer;try {producer =recyclable.<FlinkKafkaInternalProducer<?, ?>>map(Recyclable::getObject).orElseGet(() -> getRecoveryProducer(committable));--- 事务提交producer.commitTransaction();producer.flush();recyclable.ifPresent(Recyclable::close);} catch (RetriableException e) {LOG.warn("Encountered retriable exception while committing {}.", transactionalId, e);request.retryLater();} catch (ProducerFencedException e) {......}}}
。。。。
}分析结果
发现除了设置checkpoint还需要kafkasink单独设置.才会实现输出端的开启事务,因此在任务1中添加设置setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("192.168.65.128:9092").setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("test002").setValueSerializationSchema(new SimpleStringSchema()).build()).setKafkaProducerConfig(properties).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("flink-xhaodream-").build();再次验证任务任务2依然可以正常消费。这是有一点头大,不明白为什么?想到既然开启事务肯定有事务的隔离级别,查询了kafka的事务隔离级别,有两种,分别是读已提交和读未提交,默认消费事务是读未提交。
kafka的事务隔离级别:
读已提交(Read committed):此隔离级别保证消费者只能读取已经提交的消息。这意味着事务中的消息在提交之前对消费者是不可见的。使用此隔离级别可以避免消费者读取到未提交的事务消息,确保消费者只读取到已经持久化的消息。读未提交(Read Uncommitted):此隔离级别允许消费者读取未提交的消息。这意味着事务中的消息在提交之前就对消费者可见。使用此隔离级别可以实现更低的延迟,但可能会导致消费者读取到未提交的事务消息。在任务2中添加isolation.level="read_committed",设定读取消费事务级别为读已提交,再次测试,发现任务1执行完checkpoint前任务2消费不到数据。而命令行可以及时消费任务1的输出topic可可以消费到数据。结果与预期相同。
Properties properties1 = new Properties();properties1.put("isolation.level","read_committed");KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("test002").setGroupId("my-group2").setProperties(properties1)注意事项
Kafka | Apache Flink
FlinkKafkaProducer 已被弃用并将在 Flink 1.15 中移除,请改用 KafkaSink。
官网文档信息
Kafka | Apache Flink
Kafka Consumer 提交 Offset 的行为配置 #
Flink Kafka Consumer 允许有配置如何将 offset 提交回 Kafka broker 的行为。请注意:Flink Kafka Consumer 不依赖于提交的 offset 来实现容错保证。提交的 offset 只是一种方法,用于公开 consumer 的进度以便进行监控。
配置 offset 提交行为的方法是否相同,取决于是否为 job 启用了 checkpointing。
-
禁用 Checkpointing: 如果禁用了 checkpointing,则 Flink Kafka Consumer 依赖于内部使用的 Kafka client 自动定期 offset 提交功能。 因此,要禁用或启用 offset 的提交,只需将
enable.auto.commit或者auto.commit.interval.ms的Key 值设置为提供的Properties配置中的适当值。 -
启用 Checkpointing: 如果启用了 checkpointing,那么当 checkpointing 完成时,Flink Kafka Consumer 将提交的 offset 存储在 checkpoint 状态中。 这确保 Kafka broker 中提交的 offset 与 checkpoint 状态中的 offset 一致。 用户可以通过调用 consumer 上的
setCommitOffsetsOnCheckpoints(boolean)方法来禁用或启用 offset 的提交(默认情况下,这个值是 true )。 注意,在这个场景中,Properties中的自动定期 offset 提交设置会被完全忽略。
kafkasink支持语义保证
kafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)。对于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必须启用。默认情况下 KafkaSink 使用 DeliveryGuarantee.NONE。 以下是对不同语义保证的解释:
DeliveryGuarantee.NONE不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
推荐查看1.14版本和1.18版本结合起来看,在一些细节处理上有差异。
Kafka | Apache Flink
其他源码简介
如果查看1.18版本源码不太好理解两阶段提交,可以查看1.14.5的源码,发现FlinkKafkaProducer被标记废除请改用 KafkaSink,并将在 Flink 1.15 中移除, 在1.14.5中TwoPhaseCommitSinkFunction为抽象类,有明确定开启事务、预提交和提交的抽象方法,比较好理解。

查看1.14.5版本的KafkaSink 的依赖,发现没有直接使用TwoPhaseCommitSinkFunction,但是查看源码可以看到使用了commiter和kafkawriter对象

public class KafkaSink<IN> implements Sink<IN, KafkaCommittable, KafkaWriterState, Void> { public static <IN> KafkaSinkBuilder<IN> builder() {return new KafkaSinkBuilder<>();}
-- KafkaWriter 中会判断是否需要开启事务@Overridepublic SinkWriter<IN, KafkaCommittable, KafkaWriterState> createWriter(InitContext context, List<KafkaWriterState> states) throws IOException {final Supplier<MetricGroup> metricGroupSupplier =() -> context.metricGroup().addGroup("user");return new KafkaWriter<>(deliveryGuarantee,kafkaProducerConfig,transactionalIdPrefix,context,recordSerializer,new InitContextInitializationContextAdapter(context.getUserCodeClassLoader(), metricGroupSupplier),states);}-- 事务提交在kafkaCommitter@Overridepublic Optional<Committer<KafkaCommittable>> createCommitter() throws IOException {return Optional.of(new KafkaCommitter(kafkaProducerConfig));}@Overridepublic Optional<GlobalCommitter<KafkaCommittable, Void>> createGlobalCommitter()throws IOException {return Optional.empty();}...
}KafkaWriter源码
@Overridepublic List<KafkaCommittable> prepareCommit(boolean flush) {if (deliveryGuarantee != DeliveryGuarantee.NONE || flush) {currentProducer.flush();}if (deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE) {final List<KafkaCommittable> committables =Collections.singletonList(KafkaCommittable.of(currentProducer, producerPool::add));LOG.debug("Committing {} committables, final commit={}.", committables, flush);return committables;}return Collections.emptyList();}
-- 快照状态开启事务@Overridepublic List<KafkaWriterState> snapshotState(long checkpointId) throws IOException {if (deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE) {currentProducer = getTransactionalProducer(checkpointId + 1);currentProducer.beginTransaction();}return ImmutableList.of(kafkaWriterState);}
1.14.5 版本TwoPhaseCommitSinkFunction是一个抽象类 在1.18 中是接口
/*** Flink Sink to produce data into a Kafka topic. By default producer will use {@link* FlinkKafkaProducer.Semantic#AT_LEAST_ONCE} semantic. Before using {@link* FlinkKafkaProducer.Semantic#EXACTLY_ONCE} please refer to Flink's Kafka connector documentation.** @deprecated Please use {@link org.apache.flink.connector.kafka.sink.KafkaSink}.*/
@Deprecated
@PublicEvolving
public class FlinkKafkaProducer<IN>extends TwoPhaseCommitSinkFunction<IN,FlinkKafkaProducer.KafkaTransactionState,FlinkKafkaProducer.KafkaTransactionContext> {。。。}
-- 1.14 版本TwoPhaseCommitSinkFunction 为抽象类@PublicEvolving
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT> extends RichSinkFunction<IN>implements CheckpointedFunction, CheckpointListener { }-- 1.18 版本
@PublicEvolving
public interface TwoPhaseCommittingSink<InputT, CommT> extends Sink<InputT> {PrecommittingSinkWriter<InputT, CommT> createWriter(Sink.InitContext var1) throws IOException;Committer<CommT> createCommitter() throws IOException;SimpleVersionedSerializer<CommT> getCommittableSerializer();@PublicEvolvingpublic interface PrecommittingSinkWriter<InputT, CommT> extends SinkWriter<InputT> {Collection<CommT> prepareCommit() throws IOException, InterruptedException;}
}
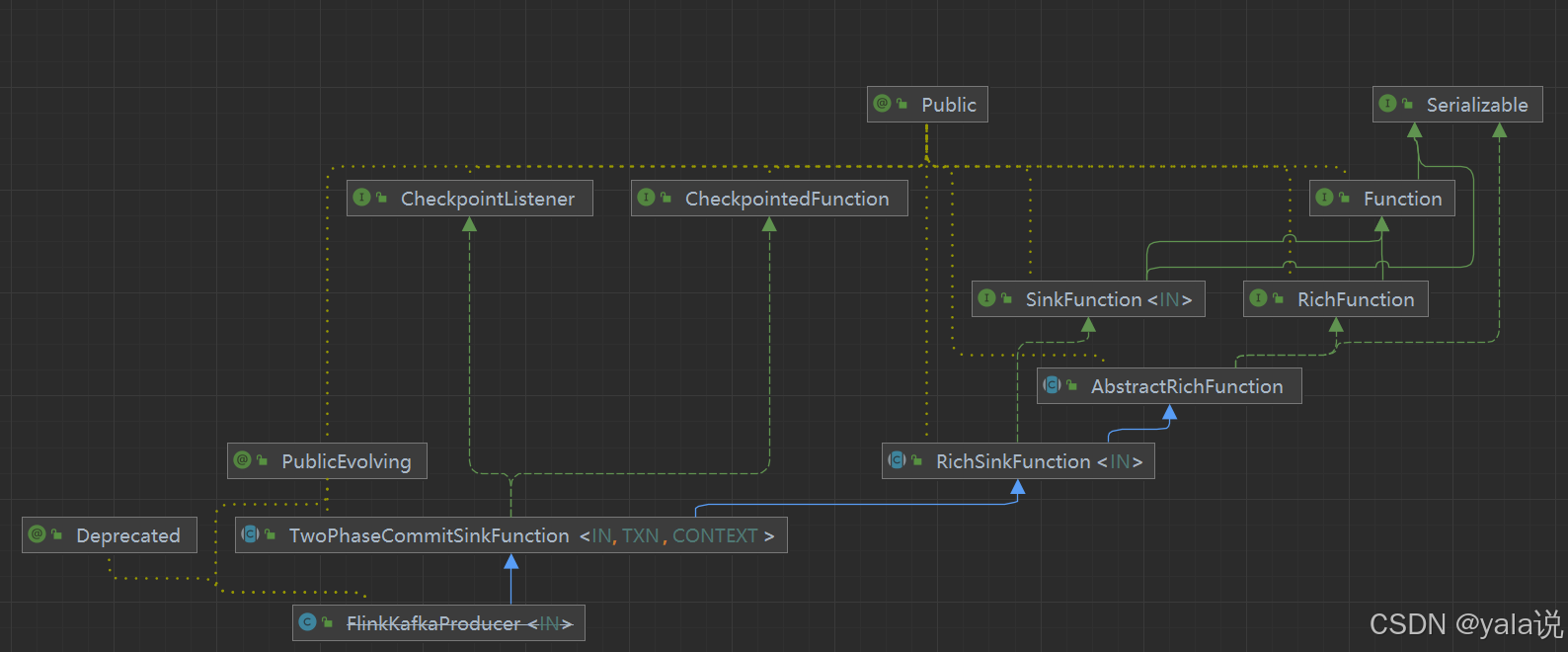
FlinkKafkaProducer继承TwoPhaseCommitSinkFunction,会重写其中的方法,查看重写开启事务的方法
-- FlinkKafkaProducer 中重写beginTransaction 方法@Overrideprotected FlinkKafkaProducer.KafkaTransactionState beginTransaction()throws FlinkKafkaException {switch (semantic) {case EXACTLY_ONCE:FlinkKafkaInternalProducer<byte[], byte[]> producer = createTransactionalProducer();
-- 开启kafka的procder的事务producer.beginTransaction();return new FlinkKafkaProducer.KafkaTransactionState(producer.getTransactionalId(), producer);case AT_LEAST_ONCE:case NONE:// Do not create new producer on each beginTransaction() if it is not necessaryfinal FlinkKafkaProducer.KafkaTransactionState currentTransaction =currentTransaction();if (currentTransaction != null && currentTransaction.producer != null) {return new FlinkKafkaProducer.KafkaTransactionState(currentTransaction.producer);}return new FlinkKafkaProducer.KafkaTransactionState(initNonTransactionalProducer(true));default:throw new UnsupportedOperationException("Not implemented semantic");}}只有当FlinkKafkaProducer.Semantic 为EXACTLY_ONCE时才会开启事务,查看其构造方法
public FlinkKafkaProducer(String topicId,SerializationSchema<IN> serializationSchema,Properties producerConfig,@Nullable FlinkKafkaPartitioner<IN> customPartitioner,FlinkKafkaProducer.Semantic semantic,int kafkaProducersPoolSize) {this(topicId,null,null,new KafkaSerializationSchemaWrapper<>(topicId, customPartitioner, false, serializationSchema),producerConfig,semantic,kafkaProducersPoolSize);}