面试中如何回答“怎样实现 RPC 框架”的问题?
在微服务架构大行其道的当下,远程调用已成为开发微服务不可或缺的能力,而作为微服务体系底层支撑的 RPC 框架,也成为日常开发的必备工具。如今,RPC 框架不仅是实现远程调用的基础工具,还需具备路由、服务发现、负载均衡、容错等功能。今天,我们就以“如何实现 RPC 框架”为切入点,从设计者的视角来探讨如何设计一个 RPC 框架。
一、基础能力设计
RPC(Remote Procedure Call)即远程过程调用,其最基本的能力无疑是远程调用一个过程。在如今面向对象的编程语言中,实则是调用一个远程的方法。在远程环境中,我们必须先定义这个方法,而后才能通过 RPC 框架来调用它。远程调用不仅能够传递参数、获取返回值,还能捕捉调用过程中的异常,让远程调用如同本地调用一般。
假设我们实现了一个 rpc 对象,其中的 invoke 方法可实现远程调用。以下这段伪代码便是调用远程的 greetings 方法(即 RPC 调用),并向远程方法传递参数 arg1、arg2 等,然后接收远程的返回值。
var result = rpc.invoke("greetings", arg1, arg2,...)
这段程序将本地视为 RPC 的客户端,将远程视为 RPC 的服务端。如下图所示:
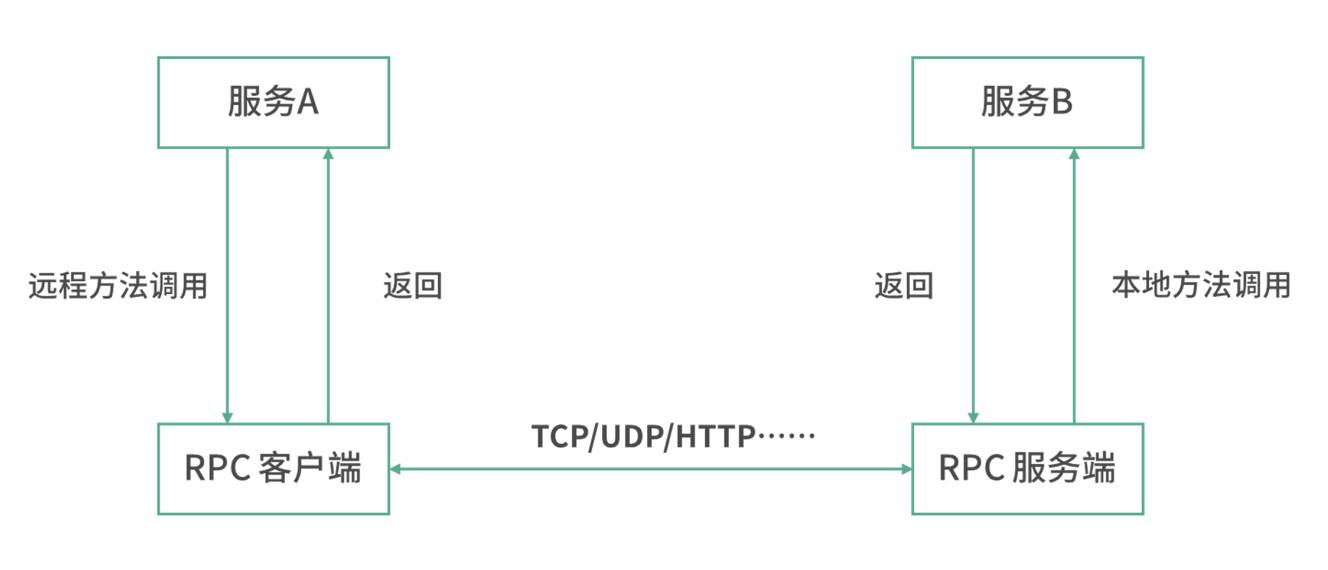
服务 A 发起远程方法调用,RPC 客户端通过某种协议将请求发送至服务 B,服务 B 解析请求,进行本地方法的调用,将结果返回至服务 B 的 RPC 服务端,最终返回至服务 A。对于服务 A 而言,调用的是一个函数,从接口到返回值的设计,与调用本地函数差别不大。当然,程序员不能完全忽视这是一次远程方法调用,毕竟远程调用存在较大的开销。如果程序员未意识到 rpc.invoke 是一次远程调用且存在网络开销,可能会写出如下程序:
for(int i = 0; i < 1000000; i++) {rpc.invoke(...)
}
之所以写出上述程序,是因为技术人员可能未意识到 rpc.invoke 是一次远程调用。在实际操作中,rpc.invoke 可能被封装在某个业务方法中,导致程序员在调用时容易忽略这是一次远程操作。所以在 RPC 调用时,要求技术人员对性能有清晰的认知。
二、多路复用的优化
RPC 本质上是数据的传递,而提供远程方法调用,就必须处理一个基本问题——提升吞吐量(单位时间传递的数据量)。若为每个远程调用(请求)都建立一个连接,会造成资源的浪费,因此通常会考虑多个请求复用一个连接,即多路复用。
在具体实现多路复用时,存在不同的策略。假设要发送数据 A、B、C、D,一种方式是建立一个连接,依次发送 A、B、C、D,如下图所示:

在这种结构中,利用一个连接顺序发送 A、B、C、D,节省了多次握手、挥手的时间,但由于 A、B、C、D 并非真正并行发送,而是顺序发送,当某个请求的体积较大时,容易阻塞其他请求。比如在 A 体积较大时,B、C、D 就只能等待 A 完全传送完成才能开始传送。这种模型对于 RPC 请求/响应大小不均衡的网络不太友好,体积小的请求/响应可能会因大体积的请求/响应而延迟。
因此,还有另一种常见的多路复用方案,即将 A、B、C、D 切片一起传输,如下图所示:
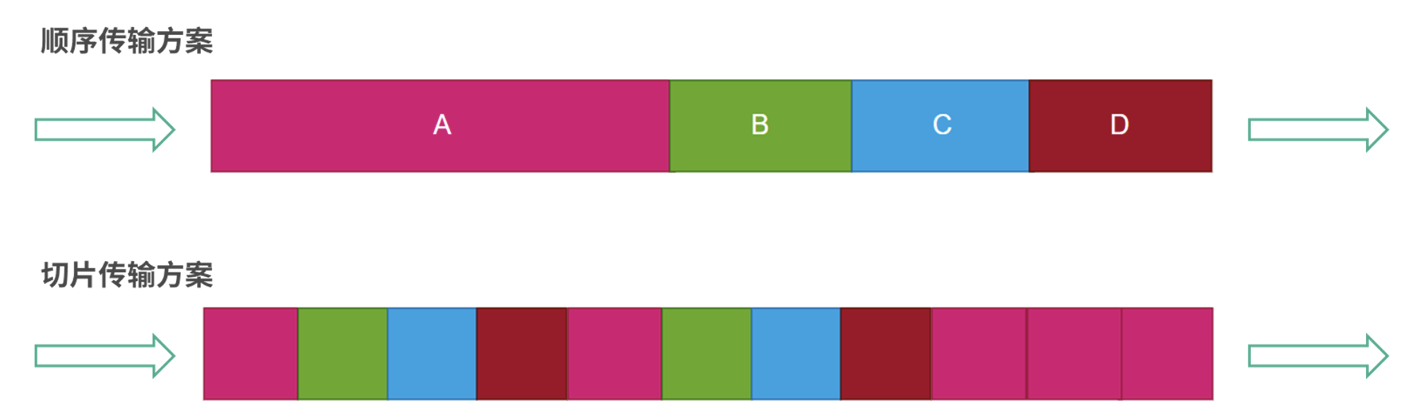
上图中,我们用不同颜色代表不同的传输任务。采用顺序传输方案将 A、B、C、D 用一个连接传输节省了握手、挥手的成本。切片传输的方案在此基础上,将数据切片能够保证大、小任务并行,不会因大任务阻塞小任务。
此外,还需考虑的一点是,单个 TCP 连接的极限传输速度受窗口大小、缓冲区等因素制约,未必能充分利用网络资源。若传输量特别大,可能需要考虑提供多个连接,每个连接再进行多路复用。
三、调用约定和命名
接下来,我们思考一下服务的命名。远程调用一个函数,命名空间+类名+方法名是不错的选择,简而言之,每个可远程调用的方法就是一个字符串。
比如远程调用一个支付服务对象 PayService 的 pay 方法,命名空间可能是 trade.payment,对象名称是 PayService,方法名称是 pay。组合起来可以是一个完整的字符串,例如用 # 分割:trade.payment#PayService#pay。
在进行远程调用时,给远程方法命名属于调用约定的一部分。我们通过调用命名空间下完整的名称来调用远程方法。在面向对象的语言中,还有一种常见做法是先不具体指定调用的方法,而是先通过 RPC 框架创建一个远程对象的实例。比如上述例子中先构造一个 PayService 对象的实例。这会用到一些特殊的编程技巧,如代理设计模式、动态接口生成等。
但归根结底,我们调用的本质就是字符串名称。而要实现这个调用,需要知晓两件事:
IP 是多少,即方法在哪个机器上调用;
端口是多少,即哪个服务提供这个调用。
四、注册和发现
在调用时,我们需要根据字符串(命名)获取 IP 和端口(机器和服务)。
机器可以是虚拟机、容器、实体机,也可以是某个拥有虚拟网卡的代理。在网络世界中,所需的只是网络接口和 IP 地址。而操作系统区分应用依靠的是端口。所以,在调用过程中,我们需要一个注册表,用于存储字符串和 IP + 端口的对应关系。
大家可能很快会想到,用 Redis 的 hash 对象存储这个对应关系就很好。当上线一个服务时,就在 Redis 的某个 hash 对象中存储它及其对应的 IP 地址 + 端口列表。为何存一个列表?因为一个服务可能由多台机器提供。
通常我们将写入这个 hash 对象的过程,即服务被记录的过程称为注册。当我们远程调用一个 RPC 服务时,调用端提供的是 RPC 服务的名称(例如:命名空间+对象+方法),根据名称查找到提供服务的 IP + 端口清单并指定某个 IP + 端口(提供服务)的过程称作发现。
当然,不能简单地认为:注册就是写一个共享的哈希表,发现就是查哈希表再决定服务的响应者。在实际设计中,需要考虑的因素更多。
比如基于 Redis 的实现,如果所有 RPC 调用都去 Redis 查询,会导致负责发现的中间件压力过大。实际操作中,往往会增加缓存,即 RPC 调用者会缓存上一次调用的 IP + 端口。但这样设计,缓存又可能与注册表产生数据不一致的问题。此时,可以考虑由分布式共识服务如 ZooKeeper 提供订阅,让 RPC 调用者订阅到服务地址的变更,及时更新自己的缓存。
设计注册和发现这两个功能的最大价值在于让客户端无需关注服务的部署细节,便于在全局动态调整服务的部署策略。
五、负载均衡的设计
在设计 RPC 框架时,负载均衡器的设计通常要与 RPC 框架一并考虑。因为 RPC 框架提供了注册、发现的能力,而提供发现能力的模块本身就是一个负载均衡器。因此,负载均衡可视为发现模块的一个子组件。当请求到达 RPC 的网关(或某个路由程序)后,发现组件会提供服务对应的所有实例(IP + 端口),然后负载均衡算法会指定其中一个来响应这个请求。
六、可用性和容灾
当一个服务实例崩溃(不可用)时,由于有发现模块的存在,可以及时从注册表中删除这个服务实例。只要服务本身有足够多的实例,比如多个容器且部署在不同的机器上,那么完全不可用的风险会大幅降低。当然,100%的可用性是无法实现的。
另外,注册表和 RPC 调用者之间必然存在不一致现象,而且注册表的更新本身也可能滞后。比如确认一个服务是否崩溃,可能需要一个心跳程序持续请求这个服务。因此,当 RPC 的调用者调用到一个不存在的服务,或者调用到一个已崩溃的服务时,需要自己重新向发现组件申请新的服务实例(地址 + 端口)。
如果遇到临时访问量剧增需要扩容的情况。此时只需上线更多的容器,并进行注册即可。当然这要求部署模块和注册模块之间有较高的协同,可通过自动化脚本来衔接。
设计一个 RPC 框架最基础的能力就是实现远程方法的调用。这需要一个调用约定,比如如何描述一个远程的方法,发送端怎样传递参数,接收方如何解析参数?若发生异常应如何处理?具体而言,这些事情实现起来并不困难,只是较为繁琐。实际上,不仅在 RPC 调用时有调用约定,编译器在实现函数调用时,也存在调用约定。此外,还有一些在 RPC 基础上构建的更复杂、更体系化的约定,比如面向服务架构(SOA)。
在实现了基本调用能力的基础上,接下来就是提供服务的注册、发现能力。有了这两个能力,就能够向客户端完全屏蔽服务的部署细节,并衍生出容灾、负载均衡的设计。
当然,设计人员还需思考底层具体网络的传输问题。若使用 TCP,要考虑多路复用以及连接数量的问题;如果是 UDP,需要增加对可靠性保证的思考。若使用了消息队列,还需考虑服务的幂等性设计等。
文章(专栏)将持续更新,欢迎关注公众号:服务端技术精选。欢迎点赞、关注、转发。
个人小工具程序上线啦,通过公众号(服务端技术精选)菜单【个人工具】即可体验,欢迎大家体验后提出优化意见!