时序论文19|ICML24 : 一篇很好的时序模型轻量化文章,用1k参数进行长时预测

论文标题:SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters
论文链接:https://arxiv.org/pdf/2402.01533
代码链接:https://github.com/lss-1138/SparseTSF
前言
最近读论文发现时间序列研究中,模型的轻量化是目前一个比较热门的方向。
这篇论文提出了SparseTSF,一种极其轻量的长时间序列预测(LTSF)模型,旨在解决在有限计算资源下建模复杂时间依赖关系的挑战。SparseTSF的核心是跨周期稀疏预测技术,该技术通过将时间序列数据的周期性和趋势解耦,简化了预测任务。具体来说,该技术通过对原始序列进行降采样,专注于跨周期趋势预测,从而有效提取周期性特征,同时最大限度地减少模型的复杂性和参数数量。基于这种技术,SparseTSF模型使用不到1000个参数就能实现与最先进模型相媲美甚至更优的性能。此外,SparseTSF表现出卓越的泛化能力,使其非常适合于计算资源有限、小样本或低质量数据的场景。
研究背景
01 参数量与均方误差
尽管较长的预测视野带来了便利,但也引入了更大的不确定性。因为这要求模型能够从更长的历史窗口中提取更广泛的时间依赖性。因此,为了捕捉这些长期时间依赖性,建模变得更加复杂。例如,基于Transformer的模型通常拥有数百万甚至数千万个参数,这限制了它们的实际可用性,尤其是在计算资源有限的情况下。
事实上,准确的长期时间序列预测的基础在于数据固有的周期性和趋势。周期性模式可以转化为子序列间的动态,而趋势模式则被重新解释为子序列内的特征。这种分解为设计轻量级LTSF模型提供了新的视角。
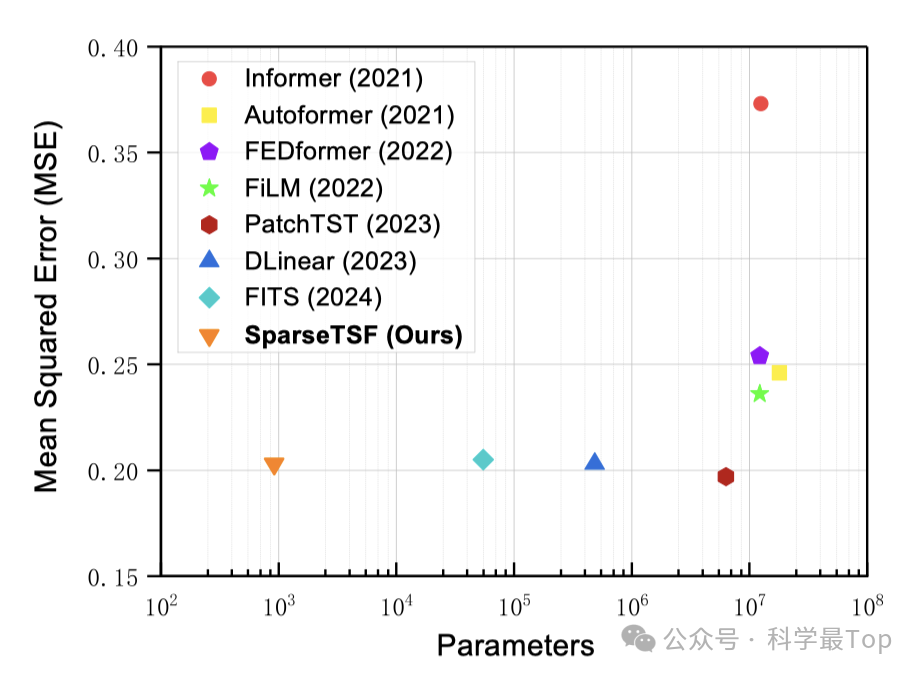
如图所示,左下角橘黄色的小三角就是本文模型对应的参数量和均方误差,从图中可以看出,本文模型在均方误差与sota模型基本一致的情况下,做到了参数量少2个以上数量级。
02 通道独立
LTSF领域很多SOTA工作都基于频道独立(CI)方法,通过建模单变量序列中的长期依赖关系(包括周期性和趋势)来实现有效预测。具体来说,CI方法为每个单变量序列找到一个共享函数。然后为每个通道提供一个更具针对性和简化的预测模型,减少了对通道间关系的复杂考虑。像DLinear、如PatchTST、TiDE都是在单个通道上采用更复杂的结构来提取时间依赖性,旨在实现卓越的预测性能。本文同样采用这种CI策略,并专注于创建一个更轻量级但有效的方法捕捉单通道时间序列中的长期依赖关系。
本文工作
这里需要说明本文的一个潜在假设:待预测的数据通常先验地表现出恒定的周期性。例如,电力消耗和交通流量通常具有固定的日周期。如图所示,本文提出了跨周期稀疏预测SparseTSF模型,以增强对长期序列依赖关系的提取,同时,使用单个线性层来建模LTSF任务,减少模型的参数规模。
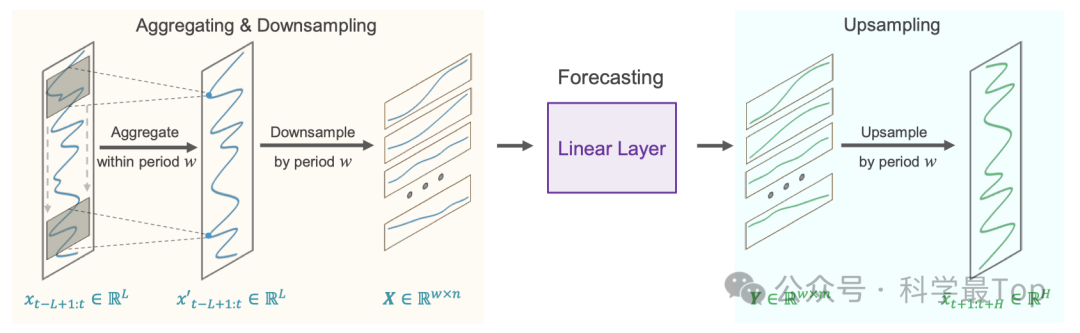
01 跨周期稀疏预测
假设时间序列具有已知的周期性,第一步是将原始序列下采样成 w个子序列。然后,将具有共享参数的模型应用于这些子序列进行预测。预测完成后,将子序列上采样回完整预测序列。
直观上,这个预测过程看起来像是一个具有稀疏间隔 w的滑动预测,由一个在固定周期 w内共享参数的全连接层执行。可以将其视为一个模型在周期之间进行稀疏滑动预测。
从技术上讲,下采样过程等同于将序列重塑为一个n×w的矩阵,然后将其转置为w×n矩阵。稀疏滑动预测等同于在矩阵的最后一个维度上应用一个大小为n×m的线性层,从而得到一个w×m的矩阵。上采样步骤则等同于将w×m矩阵转置并重塑回长度为H 的完整预测序列。
然而,这种方法目前仍然面临两个问题:(i)信息损失,因为每个周期内只有一个数据点用于预测,而其余数据点被忽略;(ii)异常值影响的放大,因为在下采样的子序列中存在的极端值可能直接影响预测结果。
为了解决这些问题,本文作者在执行稀疏预测之前,对原始序列进行滑动聚合,如图2所示。每个聚合数据点包含其周围周期内其他点的信息,从而解决问题(i)。此外,由于聚合值本质上是周围点的加权平均值,它减轻了异常值的影响,从而解决问题(ii)。技术上,这种滑动聚合可以使用零填充和核大小为2×⌊w/2⌋+1的一维卷积来实现。
02 实例归一化和损失函数
本文采用Instance Normalization策略,在序列进入模型之前先减去其均值,在模型输出后再加回来。
损失函数采用经典的均方误差(MSE)作为SparseTSF的损失函数。通过计算预测值与真实值之间的平方误差,来衡量模型的预测性能。
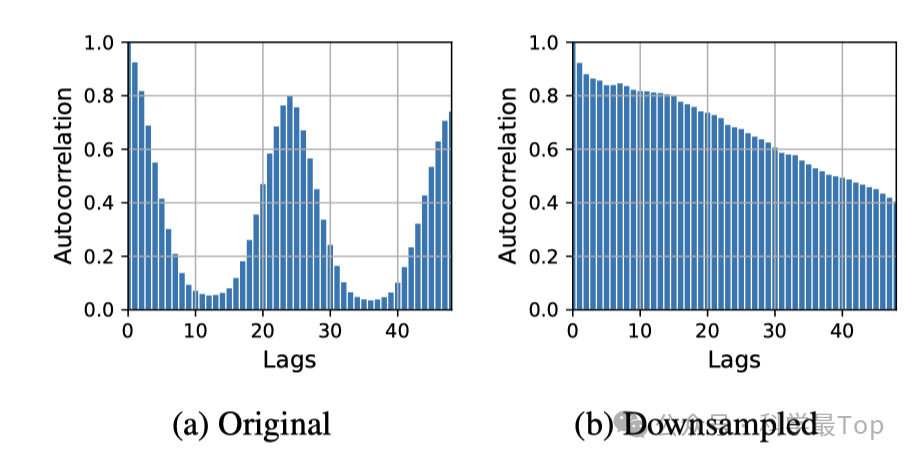
另外,本文的另一大工作是对SparseTSF模型进行了理论分析,重点关注其参数效率和稀疏技术的有效性。
实验和结论
本文不足之处:
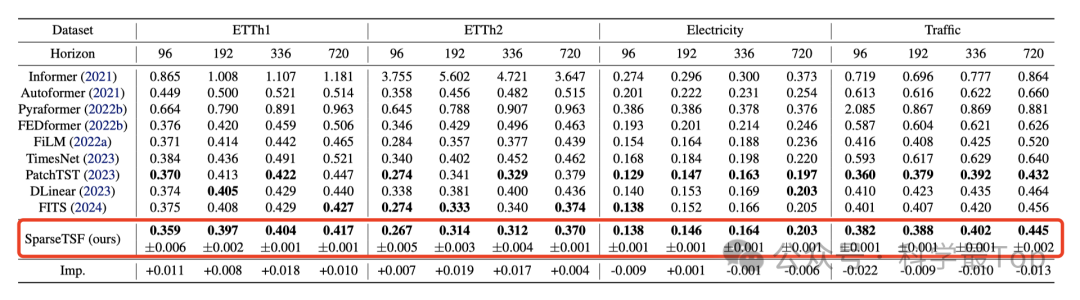
SparseTSF在参数规模极小的情况下实现了与当前最先进模型相竞争甚至超越的性能,使其成为计算资源受限环境中的强有力候选者,成为了长时间序列预测领域向轻量级模型迈进的又一个里程碑。
SparseTSF模型在处理超长周期、多重周期以及周期不明显的情况,可能会遇到困难,因为稀疏技术只能下采样和分解一个主要周期。未来可以考虑解决从超长周期和多周期数据中提取特征,力求在模型性能和参数规模之间实现最佳平衡。