如何保证Redis与MySQL双写一致性
什么是双写一致性问题?
双写一致性主要指在一个数据同时存在于缓存(如Redis)和持久化存储(如MySQL)的情况下,任何一方的数据更新都必须确保另一方数据的同步更新,以保持双方数据的一致状态。这一问题的核心在于如何在高并发环境下正确处理缓存与数据库的读写交互,防止数据出现不一致的情况。
一致性通常可以分为以下几个类别:
强一致性:
所有节点在任何时间都看到相同的数据。任何更新操作都会立即对所有节点可见,保证了数据的强一致性。这意味着,如果一个节点完成了写操作,那么所有其他节点读取相同的数据之后,都将看到最新的结果。强一致性通常需要付出更高的代价,例如增加通信开销和降低系统的可用性。
弱一致性:
系统中的数据在某些情况下可能会出现不一致的状态,但最终会收敛到一致状态。弱一致性下的系统允许在一段时间内,不同节点之间看到不同的数据状态。弱一致性通常用于需要在性能和一致性之间进行权衡的场景,例如缓存系统等。
最终一致性:
是弱一致性的一种特例,它保证了在经过一段时间后,系统中的所有节点最终都会达到一致状态。尽管在数据更新时可能会出现一段时间的不一致,但最终数据会收敛到一致状态。最终一致性通常通过一些技术手段来实现,例如基于版本向量或时间戳的数据复制和同步机制。
1、缓存常见读取数据、写数据用法

2、缓存不一致产生的原因
如果数据一直没有变更,那么就不会出现Redis和MySQL数据不一致性的问题。
两者之间数据不一致是因为一者发生了数据的变更,另一者如何在短时间内同步数据的问题。因为每次数据变更需要同时操作数据库和缓存,而他们又属于不同的系统,无法做到同时操作成功或失败,总会有一个时间差。在并发读写的时候可能就会出现缓存不一致的问题。
保证数据一致性通常涉及5种策略
1、先更新数据库,再更新缓存
@Transactional
public void updateUser(User user) {// 1. 更新数据库userMapper.updateUser(user);// 2. 更新Redis缓存// 方式1:更新缓存redisTemplate.opsForValue().set("user:" + user.getId(), user);// 方式2:删除缓存(推荐)redisTemplate.delete("user:" + user.getId());
}
如上图所示,其可能执行的流程顺序为:
1.客户端1 触发更新数据A的逻辑
2.客户端2 触发查询数据A的逻辑
3.客户端3 触发查询数据A的逻辑
4.客户端1 更新数据库中数据A
5.客户端2 查询缓存中数据A,命中返回(旧数据)
6.客户端1 让缓存中数据A失效
7.客户端3 查询缓存中数据A,未命中
8.客户端3 查询数据库中数据A,并更新到缓存中
可见,最后缓存中的数据A和数据库中的数据A是一致的,理论上可能会出现一小段时间数据不一致,不过这种概率也比较低,大部分的业务也不会有太大的问题。
为什么操作缓存的时候是删除旧缓存而不是直接更新缓存?
举个例子:
线程A先发起一个写操作,第一步先更新数据库,然后更新缓存
线程B再发起一个写操作,第二步更新了数据库,然后更新缓存
当以上两个线程的执行,如果严格先后顺序执行,那么对于更新缓存还是删除缓存去操作缓存都可以,但是如果两个线程同时执行时,由于网络或者其他原因,导致线程B先执行完更新缓存,然后线程A才会更新缓存。这时候缓存中保存的就是线程A的数据,而数据库中保存的是线程B的数据。这时候如果读取到的缓存就是脏数据。但是如果使用删除缓存取代更新缓存,那么就不会出现这个脏数据。
2、先更新缓存,再更新数据库
@Transactional
public void updateUser(User user) {// 1. 删除Redis缓存redisTemplate.delete("user:" + user.getId());// 2. 更新MySQLuserMapper.updateUser(user);
}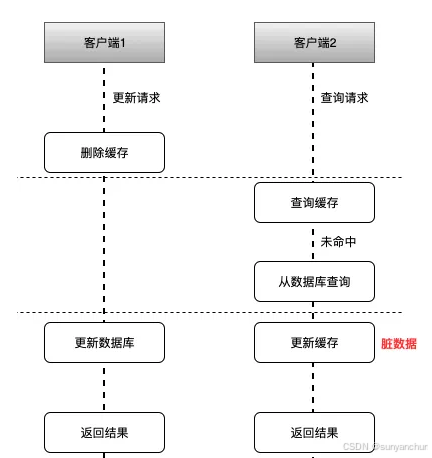
如上图所示,其可能执行的流程顺序为:
1.客户端1,发起一个写操作,第一步删除缓存
2.客户端2,发起一个读操作,缓存中没有,则继续读数据库,读出来一个老数据,然后客户端2把老数据放入缓存中
3.客户端1更新数据库数据
这样就会出现缓存中存储的是旧数据,而数据库中存储的是新数据,这样就出现脏数据,所以我们一般都采取先操作数据库,再操作缓存。这样后续的读请求从数据库获取最新数据并重新填充缓存。这样的设计降低了数据不一致的风险,提升了系统的可靠性。同时,这也符合CAP定理中对于一致性(Consistency)和可用性(Availability)权衡的要求,在很多场景下,数据一致性被优先考虑。因此一般不建议使用这种方式。
3、延时双删策略
@Transactional
public void updateUser(User user) {// 1. 删除Redis缓存redisTemplate.delete("user:" + user.getId());// 2. 更新MySQLuserMapper.updateUser(user);// 3. 延迟一段时间后再次删除缓存CompletableFuture.runAsync(() -> {try {Thread.sleep(500); // 延迟500毫秒redisTemplate.delete("user:" + user.getId());} catch (InterruptedException e) {// 处理异常}});
}
延时双删策略主要用于解决在高并发场景下,由于网络延迟、并发控制等原因造成的数据库与缓存数据不一致的问题。
当更新数据库时,首先删除对应的缓存项,以确保后续的读请求会从数据库加载最新数据。
但是由于网络延迟或其他不确定性因素,删除缓存与数据库更新之间可能存在时间窗口,导致在这段时间内的读请求从数据库读取数据后写回缓存,新写入的缓存数据可能还未反映出数据库的最新变更。
所以为了解决这个问题,延时双删策略在第一次删除缓存后,设定一段短暂的延迟时间,如几百毫秒,然后在这段延迟时间结束后再次尝试删除缓存。这样做的目的是确保在数据库更新传播到所有节点,并且在缓存中的旧数据彻底过期失效之前,第二次删除操作可以消除缓存中可能存在的旧数据,从而提高数据一致性。
4、使用消息队列
@Transactional
public void updateUser(User user) {// 1. 更新MySQLuserMapper.updateUser(user);// 2. 发送消息到消息队列kafkaTemplate.send("user-update-topic", JSON.toJSONString(user));
}// 3. 在消费者服务中更新缓存
@KafkaListener(topics = "user-update-topic")
public void consumeUserUpdate(String message) {User user = JSON.parseObject(message, User.class);// 更新Redis缓存redisTemplate.opsForValue().set("user:" + user.getId(), user);
}
在高并发的业务场景中,消息队列是必不可少的技术之一。它不仅可以异步解耦,还能削峰填谷。对保证系统的稳定性是非常有意义的。
1.更新数据库
2.通过指定的topic发送到消息队列服务
3.然后消费者订阅该topic的消息,读取消息数据之后,再更新redis缓存。
5、使用 Canal 进行 MySQL binlog 同步
@Component
public class CanalClient {@Autowiredprivate RedisTemplate<String, String> redisTemplate;@PostConstructpublic void init() {CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");try {connector.connect();connector.subscribe(".*\\..*");while (true) {Message message = connector.getWithoutAck(100);long batchId = message.getId();List<CanalEntry.Entry> entries = message.getEntries();if (batchId != -1 && entries.size() > 0) {for (CanalEntry.Entry entry : entries) {if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());if (rowChange.getEventType() == CanalEntry.EventType.UPDATE) {for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {// 处理更新操作,更新Redis缓存updateRedisCache(rowData);}}}}}connector.ack(batchId);}} finally {connector.disconnect();}}private void updateRedisCache(CanalEntry.RowData rowData) {// 根据rowData更新Redis缓存// 这里需要根据具体的数据结构来实现}
}
在数据库发生写操作时,将变更记录在binlog或类似的事务日志中,然后使用一个专门的异步服务或者监听器订阅binlog的变化(比如Canal),一旦检测到有数据更新,便根据binlog中的操作信息定位到受影响的缓存项,删除或更新缓存中的对应数据,确保缓存与数据库保持一致。