LRU缓存算法
首先是一个单链表的结果,key存储的是位置。val存储的是值。 链表的一个节点有两个值。
1.需要解决的几个问题
1.为什么使用双链表,在内存中找到某个节点,想要删除当前的节点需要找到前一个内存的地址,这样效率太低了。使用双链表可以原地的删除一个节点。
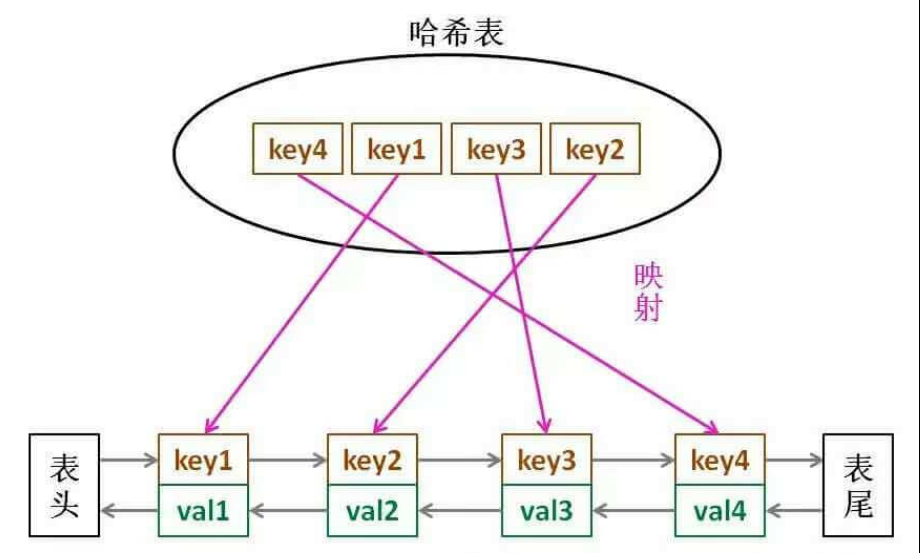
2.如何快速找到某个节点呢?通过哈希表,时间复杂度是o(1) 可以快速找到内存的地址。
对于LRU
1.每次查询过后的节点,应该题为到队尾。保存最近的使用。具体就是先删除当前的节点,再插入到队列末端。
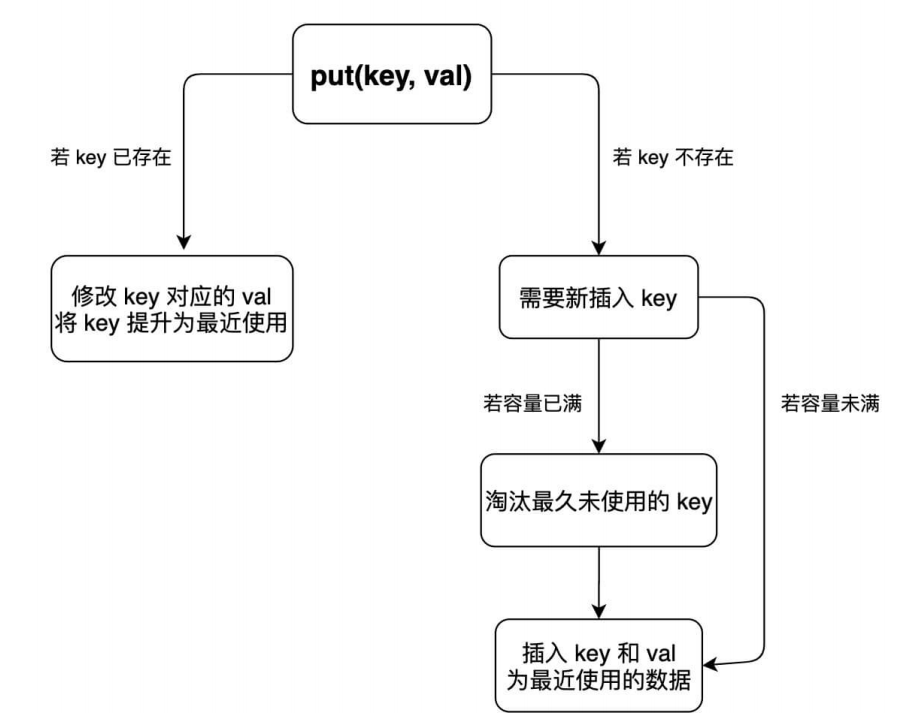
2.对于put的逻辑,如果已经存在,将key提升为最近使用的
如果不存在,插入新的key。 如果容量满了,淘汰最久没有使用的key。再插入进去。
public class Node {public int key, val;public Node prev;public Node next;public Node() {}public Node(int key, int value) {this.key = key;this.val = value;}
}
public class DoubleList {public Node head, tail;public int size;public DoubleList() {head = new Node(0, 0);tail = new Node(0, 0);head.next = tail;tail.prev = head;size = 0;}//添加新的页面进来 图1public void addLast(Node x) {x.prev = tail.prev;x.next = tail;tail.prev.next = x;tail.prev = x;size++;}//删除一个节点public void remove(Node x) {x.prev.next = x.next;x.next.prev = x.prev;size--;}// 返回链表⻓度,时间 O(1)public int size() {return size;}// 删除链表中第⼀个节点,并返回该节点,时间 O(1)public Node removeFirst() {if (head.next == tail)return null;Node first = head.next;remove(first);return first;}//public void print() {Node cur=this.head.next;while (cur.next!=null){System.out.print(cur.key+" ");cur=cur.next;}System.out.println();}
}package 操作系统代码.页面置换算法.lru;import java.util.HashMap;
import java.util.Map;public class LRUCache {// key -> Node(key, val)private HashMap<Integer, Node> map;// Node(k1, v1) <-> Node(k2, v2)...private DoubleList cache;// 最⼤容量private int cap; //多少块public LRUCache(int capacity) {this.cap = capacity;map = new HashMap<>();cache = new DoubleList();}/* 将某个 key 提升为最近使⽤的 */private void makeRecently(int key) {Node x = map.get(key);// 先从链表中删除这个节点cache.remove(x);// 重新插到队尾cache.addLast(x);}/* 添加最近使⽤的元素 */private void addRecently(int key, int val) {Node x = new Node(key, val);// 链表尾部就是最近使⽤的元素cache.addLast(x);// 别忘了在 map 中添加 key 的映射map.put(key, x);}/* 删除某⼀个 key */private void deleteKey(int key) {Node x = map.get(key);// 从链表中删除cache.remove(x);// 从 map 中删除map.remove(key);}/* 删除最久未使⽤的元素 */private void removeLeastRecently() {// 链表头部的第⼀个元素就是最久未使⽤的Node deletedNode = cache.removeFirst();// 同时别忘了从 map 中删除它的 keyint deletedKey = deletedNode.key;map.remove(deletedKey);}//一个是get方法 一个是put方法public int get(int key) {if (!map.containsKey(key)) {return -1;}// 将该数据提升为最近使⽤的makeRecently(key);return map.get(key).val;}public void put(int key, int val) {if (map.containsKey(key)) {// 删除旧的数据deleteKey(key);// 新插⼊的数据为最近使⽤的数据addRecently(key, val);return;}if (cap == cache.size()) {// 删除最久未使⽤的元素removeLeastRecently();}// 添加为最近使⽤的元素addRecently(key, val);}public static void main(String[] args) {LRUCache cache = new LRUCache(2);cache.put(1, 1);cache.cache.print();
// cache = [(1, 1)]cache.put(2, 2);
// cache = [(2, 2), (1, 1)]cache.cache.print();cache.get(1); // 返回 1
// cache = [(1, 1), (2, 2)]
// 解释:因为最近访问了键 1,所以提前⾄队头
// 返回键 1 对应的值 1cache.cache.print();cache.put(3, 3);
// cache = [(3, 3), (1, 1)]
// 解释:缓存容量已满,需要删除内容空出位置
// 优先删除久未使⽤的数据,也就是队尾的数据
// 然后把新的数据插⼊队头cache.get(2); // 返回 -1 (未找到)cache.cache.print();
// cache = [(3, 3), (1, 1)]
// 解释:cache 中不存在键为 2 的数据cache.put(1, 4);cache.cache.print();
// cache = [(1, 4), (3, 3)]
// 解释:键 1 已存在,把原始值 1 覆盖为 4
// 不要忘了也要将键值对提前到队头}
}