策略梯度方法【Policy Gradient】
强化学习笔记系列目录
第一章 强化学习基本概念
第二章 贝尔曼方程
第三章 贝尔曼最优方程
第四章 值迭代和策略迭代
第五章 强化学习实例分析:GridWorld
第六章 蒙特卡洛方法
第七章 Robbins-Monro算法
第八章 多臂老虎机
第九章 强化学习实例分析:CartPole
第十章 时序差分法
第十一章 值函数近似【DQN】
第十二章 基于强化学习DQN的股票预测
第十三章 策略梯度方法
文章目录
- 强化学习笔记系列目录
- 一、参数化策略函数
- 二、最优策略的度量方式
- (一)平均状态值
- (1)定义
- (2)d(s)的选取
- (3)等价形式
- (二)平均奖励
- (1)定义
- (2)等价形式
- (三)总结
- 三、策略梯度
- (一)策略梯度定理
- (二)Discount case 结论
- (三)Undiscount Case 结论
- 四、REINFORCE
- 参考资料
本文主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门.
在上一篇文章中值函数近似【DQN】,我们介绍了用参数化的函数来近似值函数 q ( s , a ) q(s,a) q(s,a),比如DQN中用一个神经网络来表示 q ( s , a ) q(s,a) q(s,a),利用学习到的 q ( s , a ) q(s,a) q(s,a),我们可以通过贪婪的方法得到最优策略.本章我们介绍策略梯度的方法,直接用一个参数化的函数来表示策略,通过梯度上升的方法更新策略函数,最后直接得到策略 π θ \pi_\theta πθ.
一、参数化策略函数
函数近似的思想不仅可以应用于表示状态/动作值,也可以应用于表示策略。前面介绍的方法,如经典的值迭代、策略迭代,或者是蒙特卡洛方法和时序差分方法中,我们的策略都可以用如下的表格来表示:
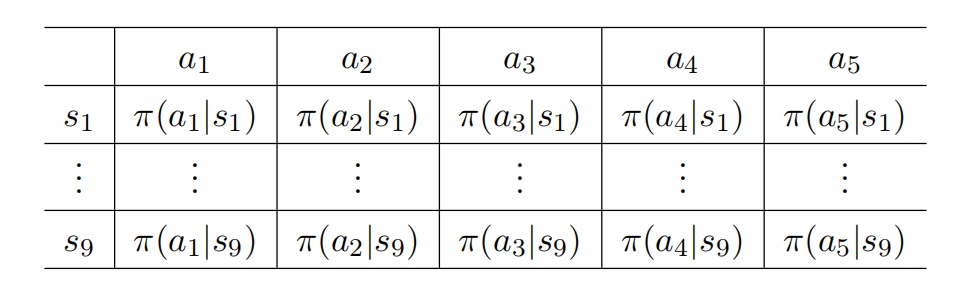
显然当状态空间和动作空间很大时,这个表格会非常大,计算所需内存会急剧上升,并且泛化能力一般。 所以同值函数的近似一样,我们也可以参数化地表示策略函数: π ( a ∣ s , θ ) \pi(a|s,\theta) π(a∣s,θ),其中 θ ∈ R m \theta\in\mathbb{R}^m θ∈Rm是一个参数向量。 π ( a ∣ s , θ ) \pi(a|s,\theta) π(a∣s,θ)也可以写为 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)或者 π ( a , s , θ ) \pi(a,s,\theta) π(a,s,θ).
如下图所示:
- 策略用一个函数来表示时,输入 s , a s,a s,a,会直接输出当前状态 s s s下采取动作 a a a一个概率.
- 或者如右图所示,输入当前状态 s s s,输出采取每个动作 a a a的概率分布.
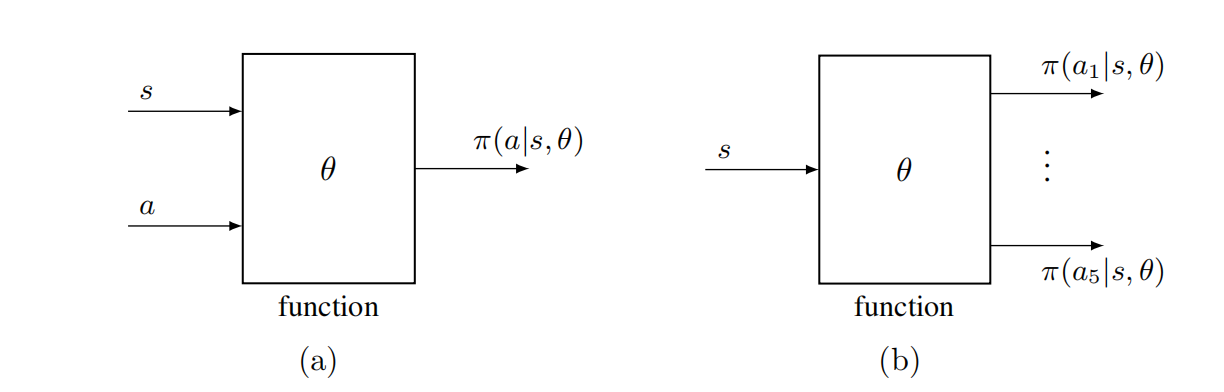
当前最有效的方法是用神经网络来近似策略函数,下面给出一个策略网络结构示意图:

通过参数化的函数来表示策略会出现一个问题,怎么衡量一个策略是不是最优策略?回顾贝尔曼最优方程的知识,我们知道,当策略用表格方法表示时,如果策略可以最大化每个状态值,则将其定义为最优策略。
当策略用一个 θ \theta θ的函数来表示时,如何定义最优策略呢?我们需要引入一个度量来衡量,如果某个策略能最大化这个度量,则定义其为最优策略。
二、最优策略的度量方式
(一)平均状态值
(1)定义
如果一个策略很好,那么其状态价值 v π ( s ) v_\pi(s) vπ(s) 的均值应当很大。因此可以定义度量函数为:
J ( θ ) = E s ∼ d [ v π θ ( s ) ] , (1) J(\theta)=\mathbb{E}_{s\sim d}\left[v_{\pi_\theta} (s)\right], \tag{1} J(θ)=Es∼d[vπθ(s)],(1)
为什么这么定义,因为我们知道 v π θ ( s ) v_{\pi_\theta}(s) vπθ(s) 依赖于当前状态和策略,因此对状态进行期望操作得到目标函数 J ( θ ) J(\theta) J(θ) ,这样 J ( θ ) J(\theta) J(θ) 就只依赖于策略 π θ \pi_\theta πθ 的参数 θ \theta θ ——策略越好, 则 J ( θ ) J(\theta) J(θ) 越大。 我们将对状态值函数的期望展开:
v ˉ π ≐ E s ∼ d [ v π θ ( s ) ] = ∑ s ∈ S d ( s ) v π ( s ) \bar{v}_\pi \doteq\mathbb{E}_{s\sim d}\left[v_{\pi_\theta} (s)\right]=\sum_{s \in \mathcal{S}} d(s) v_\pi(s) vˉπ≐Es∼d[vπθ(s)]=s∈S∑d(s)vπ(s)
其中, d ( s ) d(s) d(s)是概率分布,也可以理解为是状态 s s s的权重, Σ s d ( s ) = 1 \Sigma_s d(s) =1 Σsd(s)=1.当我们定义出 J ( θ ) J(\theta) J(θ),那么策略学习可以描述为优化问题:
max θ J ( θ ) . \max_\theta J(\theta). θmaxJ(θ).
然后就可以利用梯度上升的方法来求最大值,从而得到最优策略 π θ \pi_\theta πθ.
(2)d(s)的选取
对于 d ( s ) d(s) d(s) 怎么选取, 分为两种情况:
(一) d d d 独立于策略 π \pi π
在这种情况下,我们特别将 d d d表示为 d 0 d_0 d0, v ˉ π \bar{v}_\pi vˉπ表示为 v ˉ π 0 \bar{v}_\pi^0 vˉπ0,以表示分布与策略无关。那么这种情况下 d 0 d_0 d0怎么选择呢?
- 一种情况是将所有状态认为同等重要,可以取 d 0 ( s ) = 1 ∣ S ∣ , ∀ s ∈ S d_0(s)=\frac{1}{|S|},\forall s\in S d0(s)=∣S∣1,∀s∈S .
- 另一种情况是当我们只对特定状态 s 0 s_0 s0感兴趣时(例如,Agent总是从 s 0 s_0 s0出发)。在这种情况下,我们可以设计
d 0 ( s 0 ) = 1 , d 0 ( s ≠ s 0 ) = 0. d_0(s_0)=1,d_0(s\neq s_0)=0. d0(s0)=1,d0(s=s0)=0.
(二) d d d 依赖于策略 π \pi π
在这种情况下,通常表示 d d d为 d π d_\pi dπ, d π d_\pi dπ是 π \pi π下的一个平稳分布。平稳分布反映了给定策略下马尔可夫决策过程的长期行为。
- 如果一个状态 s s s长期被频繁访问,那么它就更重要,应该得到更高的权重;
- 如果一个状态 s s s很少被访问,那么它的重要性很低,应该得到较低的权重。
d π d_\pi dπ的一个基本性质是它满足
d π T P π = d π T , d_\pi^T P_\pi=d_\pi^T, dπTPπ=dπT,
其中 P π P_\pi Pπ为状态转移概率矩阵。
总之, v ˉ π \bar{v}_\pi vˉπ是状态值的加权平均值。不同的 θ \theta θ值会得到不同的 v ˉ π \bar{v}_\pi vˉπ值。我们的最终目标是找到一个最优策略(或等价的最优 θ \theta θ)来最大化 v ˉ π \bar{v}_\pi vˉπ。上面两种不同 d ( s ) d(s) d(s)的选择,主要的区别,就在于求后面梯度的时候,计算有所不同。
(3)等价形式
假设Agent通过遵循给定策略 π θ \pi_\theta πθ 获得奖励 { R t + 1 } t = 0 ∞ \{ R_{t+1} \}_{t=0}^{\infty} {Rt+1}t=0∞,有时我们会看到如下的度量函数:
J ( θ ) = lim n → ∞ E [ ∑ t = 0 n γ t R t + 1 ] = E [ ∑ t = 0 ∞ γ t R t + 1 ] (2) J(\theta) = \lim_{n \to \infty} \mathbb{E} \left[ \sum_{t=0}^n \gamma^t R_{t+1} \right] = \mathbb{E} \left[ \sum_{t=0}^\infty \gamma^t R_{t+1} \right] \tag{2} J(θ)=n→∞limE[t=0∑nγtRt+1]=E[t=0∑∞γtRt+1](2)
这个度量标准乍看之下可能不容易理解,事实上,它等价于 v ˉ π \bar{v}_{\pi} vˉπ. 由上面的公式,我们有:
E [ ∑ t = 0 ∞ γ t R t + 1 ] = ∑ s ∈ S d ( s ) E [ ∑ t = 0 ∞ γ t R t + 1 ∣ S 0 = s ] = ∑ s ∈ S d ( s ) v π ( s ) = v ˉ π . \begin{aligned} \mathbb{E} \left[ \sum_{t=0}^\infty \gamma^t R_{t+1} \right] &= \sum_{s \in \mathcal{S}} d(s) \mathbb{E} \left[ \sum_{t=0}^\infty \gamma^t R_{t+1} | S_0 = s \right] \\ &= \sum_{s \in \mathcal{S}} d(s) v_{\pi}(s) \\ &= \bar{v}_{\pi}. \end{aligned} E[t=0∑∞γtRt+1]=s∈S∑d(s)E[t=0∑∞γtRt+1∣S0=s]=s∈S∑d(s)vπ(s)=vˉπ.
上面等式中的第一个等号是基于全概率公式,第二个等号是基于状态值函数的定义。
v ˉ π \bar{v}_{\pi} vˉπ 也可以写成两个向量的内积。特别地,设
v π = [ … , v π ( s ) , … ] T ∈ R ∣ S ∣ , v_{\pi} = \left[ \dots, v_{\pi}(s), \dots \right]^T \in \mathbb{R}^{|\mathcal{S}|}, vπ=[…,vπ(s),…]T∈R∣S∣,
d = [ … , d ( s ) , … ] T ∈ R ∣ S ∣ . d = \left[ \dots, d(s), \dots \right]^T \in \mathbb{R}^{|\mathcal{S}|}. d=[…,d(s),…]T∈R∣S∣.
于是,我们有
v ˉ π = d T v π . \bar{v}_{\pi} = d^T v_{\pi}. vˉπ=dTvπ.
当我们分析其梯度时,该表达式将会很有用。
(二)平均奖励
(1)定义
第二种度量最优策略的目标函数为平均奖励,定义如下:
r ˉ π ≐ ∑ s ∈ S d π ( s ) r π ( s ) = E S ∼ d π [ r π ( S ) ] , (3) \begin{aligned} \bar{r}_\pi & \doteq \sum_{s \in \mathcal{S}} d_\pi(s) r_\pi(s) \\ & =\mathbb{E}_{S \sim d_\pi}\left[r_\pi(S)\right], \end{aligned}\tag{3} rˉπ≐s∈S∑dπ(s)rπ(s)=ES∼dπ[rπ(S)],(3)
其中 d π d_\pi dπ是平稳分布, r π ( s ) r_\pi(s) rπ(s)的定义如下:
r π ( s ) ≐ ∑ a ∈ A π ( a ∣ s , θ ) r ( s , a ) = E A ∼ π ( s , θ ) [ r ( s , A ) ∣ s ] , r_\pi(s) \doteq \sum_{a \in \mathcal{A}} \pi(a \mid s, \theta) r(s, a)=\mathbb{E}_{A \sim \pi(s, \theta)}[r(s, A) \mid s], rπ(s)≐a∈A∑π(a∣s,θ)r(s,a)=EA∼π(s,θ)[r(s,A)∣s],
是对即时回报的期望。其中, r ( s , a ) ≐ E [ R ∣ s , a ] = ∑ r r p ( r ∣ s , a ) r(s, a) \doteq \mathbb{E}[R \mid s, a]=\sum_r r p(r \mid s, a) r(s,a)≐E[R∣s,a]=∑rrp(r∣s,a)。
(2)等价形式
假设Agent通过遵循给定策略 π θ \pi_\theta πθ 获得奖励 { R t + 1 } t = 0 ∞ \{ R_{t+1} \}_{t=0}^{\infty} {Rt+1}t=0∞。我们可能会在文献中看到以下常用的度量标准:
J ( θ ) = lim n → ∞ 1 n E [ ∑ t = 0 n − 1 R t + 1 ] . (4) J(\theta) = \lim_{n \to \infty} \frac{1}{n} \mathbb{E} \left[ \sum_{t=0}^{n-1} R_{t+1} \right]. \tag{4} J(θ)=n→∞limn1E[t=0∑n−1Rt+1].(4)
这个度量标准,等价于 r ˉ π \bar{r}_{\pi} rˉπ:
lim n → ∞ 1 n E [ ∑ t = 0 n − 1 R t + 1 ] = ∑ s ∈ S d π ( s ) r π ( s ) = r ˉ π . \lim_{n \to \infty} \frac{1}{n} \mathbb{E} \left[ \sum_{t=0}^{n-1} R_{t+1} \right] = \sum_{s \in \mathcal{S}} d_{\pi}(s) r_{\pi}(s) = \bar{r}_{\pi}. n→∞limn1E[t=0∑n−1Rt+1]=s∈S∑dπ(s)rπ(s)=rˉπ.
证明参考1.平均奖励 r ˉ π \bar{r}_{\pi} rˉπ 也可以写成两个向量的内积。特别地,设
r π = [ … , r π ( s ) , … ] T ∈ R ∣ S ∣ , r_{\pi} = \left[ \dots, r_{\pi}(s), \dots \right]^T \in \mathbb{R}^{|\mathcal{S}|}, rπ=[…,rπ(s),…]T∈R∣S∣,
d π = [ … , d π ( s ) , … ] T ∈ R ∣ S ∣ , d_{\pi} = \left[ \dots, d_{\pi}(s), \dots \right]^T \in \mathbb{R}^{|\mathcal{S}|}, dπ=[…,dπ(s),…]T∈R∣S∣,
于是,很明显有
r ˉ π = ∑ s ∈ S d π ( s ) r π ( s ) = d π T r π . \bar{r}_{\pi} = \sum_{s \in \mathcal{S}} d_{\pi}(s) r_{\pi}(s) = d_{\pi}^T r_{\pi}. rˉπ=s∈S∑dπ(s)rπ(s)=dπTrπ.
当我们推导其梯度时,该表达式将会很有用。
(三)总结
上面介绍的两种度量方式总结如下:

Note:
- 两个度量函数都是策略 π \pi π的函数,而策略又是 θ \theta θ的函数,所以两个度量函数都是 θ \theta θ的函数.
- 当 γ < 1 \gamma<1 γ<1时, v ˉ π \bar{v}_\pi vˉπ和 r ˉ π \bar{r}_\pi rˉπ是等价的,并且可以证明 r ˉ π = ( 1 − γ ) v ˉ π \bar{r}_\pi=(1-\gamma)\bar{v}_\pi rˉπ=(1−γ)vˉπ.
- 当 γ = 1 \gamma = 1 γ=1时,也就是公式(4).
三、策略梯度
(一)策略梯度定理
通过上面的介绍,我们知道,当定义出 J ( θ ) J(\theta) J(θ)后,剩下的问题就是求解下面的优化问题:
max θ J ( θ ) . (5) \max_\theta J(\theta). \tag{5} θmaxJ(θ).(5)
一个很自然的想法就是用梯度上升法来做:
θ t + 1 = θ t + α ∇ J ( θ t ) (6) \theta_{t+1} = \theta_t+\alpha \nabla J(\theta_t) \tag{6} θt+1=θt+α∇J(θt)(6)
所以一个关键的问题是 J ( θ ) J(\theta) J(θ)的梯度怎么求?下面给出策略梯度定理.
定理【策略梯度定理】
J ( θ ) J(\theta) J(θ) 的梯度为
∇ θ J ( θ ) = ∑ s ∈ S η ( s ) ∑ a ∈ A ∇ θ π ( a ∣ s , θ ) q π ( s , a ) , (7) \nabla_{\theta} J(\theta) = \sum_{s \in S} \eta(s) \sum_{a \in A} \nabla_{\theta} \pi(a|s, \theta) q_{\pi}(s, a), \tag{7} ∇θJ(θ)=s∈S∑η(s)a∈A∑∇θπ(a∣s,θ)qπ(s,a),(7)
其中, η \eta η 是状态分布函数, ∇ θ π \nabla_{\theta} \pi ∇θπ 是 π \pi π关于 θ \theta θ 的梯度。此外,上式可以通过期望的形式简化为:
∇ θ J ( θ ) = E S ∼ η , A ∼ π ( S , θ ) [ ∇ θ ln π ( A ∣ S , θ ) q π ( S , A ) ] , (8) \nabla_{\theta} J(\theta) = \mathbb{E}_{S \sim \eta, A \sim \pi(S, \theta)} \left[ \nabla_{\theta} \ln \pi(A | S, \theta) q_{\pi}(S, A) \right], \tag{8} ∇θJ(θ)=ES∼η,A∼π(S,θ)[∇θlnπ(A∣S,θ)qπ(S,A)],(8)
其中 ln \ln ln 表示自然对数。
其中:
- J ( θ ) J(\theta) J(θ) 可以是 v ˉ π \bar{v}_{\pi} vˉπ、 r ˉ π \bar{r}_{\pi} rˉπ 或 v ˉ π 0 \bar{v}_{\pi}^0 vˉπ0
- 也就是说 J ( θ ) J(\theta) J(θ)取不同值,会导出不同的梯度表达式;
- η ( s ) \eta(s) η(s)取法不同,也会导致梯度不一样.
- “ = = =” 可能表示严格相等、近似相等或成比例,这个取决于 γ \gamma γ的取值.
- 所以在导出更具体的形式时,需要对上面几种情况进行区分,(7)和(8)是策略梯度的统一形式.
写成式(8)这种期望形式很有用,因为在进行梯度上升算法的过程中,我们可以用一个采样来替代期望(随机梯度下降原理)。那么为什么式 (7) 可以表示为式 (8)?证明如下。根据期望的定义,(7) 可以重写为
∇ θ J ( θ ) = ∑ s ∈ S η ( s ) ∑ a ∈ A ∇ θ π ( a ∣ s , θ ) q π ( s , a ) = E S ∼ η [ ∑ a ∈ A ∇ θ π ( a ∣ S , θ ) q π ( S , a ) ] . (9) \nabla_{\theta} J(\theta) = \sum_{s \in S} \eta(s) \sum_{a \in A} \nabla_{\theta} \pi(a|s, \theta) q_{\pi}(s, a) = \mathbb{E}_{S \sim \eta} \left[ \sum_{a \in A} \nabla_{\theta} \pi(a|S, \theta) q_{\pi}(S, a) \right]. \tag{9} ∇θJ(θ)=s∈S∑η(s)a∈A∑∇θπ(a∣s,θ)qπ(s,a)=ES∼η[a∈A∑∇θπ(a∣S,θ)qπ(S,a)].(9)
我们知道 ln π ( a ∣ s , θ ) \ln \pi(a|s, \theta) lnπ(a∣s,θ) 的梯度为
∇ θ ln π ( a ∣ s , θ ) = ∇ θ π ( a ∣ s , θ ) π ( a ∣ s , θ ) , \nabla_{\theta} \ln \pi(a|s, \theta) = \frac{\nabla_{\theta} \pi(a|s, \theta)}{\pi(a|s, \theta)}, ∇θlnπ(a∣s,θ)=π(a∣s,θ)∇θπ(a∣s,θ),
因此
∇ θ π ( a ∣ s , θ ) = π ( a ∣ s , θ ) ∇ θ ln π ( a ∣ s , θ ) . (10) \nabla_{\theta} \pi(a|s, \theta) = \pi(a|s, \theta) \nabla_{\theta} \ln \pi(a|s, \theta). \tag{10} ∇θπ(a∣s,θ)=π(a∣s,θ)∇θlnπ(a∣s,θ).(10)
将 (10) 代入 (9) 得
∇ θ J ( θ ) = E [ ∑ a ∈ A π ( a ∣ S , θ ) ∇ θ ln π ( a ∣ S , θ ) q π ( S , a ) ] = E S ∼ η , A ∼ π ( S , θ ) [ ∇ θ ln π ( A ∣ S , θ ) q π ( S , A ) ] . \nabla_{\theta} J(\theta) = \mathbb{E} \left[ \sum_{a \in A} \pi(a|S, \theta) \nabla_{\theta} \ln \pi(a|S, \theta) q_{\pi}(S, a) \right] = \mathbb{E}_{S \sim \eta, A \sim \pi(S, \theta)} \left[ \nabla_{\theta} \ln \pi(A | S, \theta) q_{\pi}(S, A) \right]. ∇θJ(θ)=E[a∈A∑π(a∣S,θ)∇θlnπ(a∣S,θ)qπ(S,a)]=ES∼η,A∼π(S,θ)[∇θlnπ(A∣S,θ)qπ(S,A)].
值得注意的是,为了确保 ln π ( a ∣ s , θ ) \ln \pi(a|s, \theta) lnπ(a∣s,θ) 有效,对于所有 ( s , a ) (s, a) (s,a), π ( a ∣ s , θ ) \mathbf{\pi(a|s, \theta)} π(a∣s,θ) 必须为正。这可以通过 softmax 函数来实现:
π ( a ∣ s , θ ) = e h ( s , a , θ ) ∑ a ′ ∈ A e h ( s , a ′ , θ ) , a ∈ A , (11) \pi(a|s, \theta) = \frac{e^{h(s, a, \theta)}}{\sum_{a' \in A} e^{h(s, a', \theta)}}, \quad a \in A, \tag{11} π(a∣s,θ)=∑a′∈Aeh(s,a′,θ)eh(s,a,θ),a∈A,(11)
其中 h ( s , a , θ ) h(s, a, \theta) h(s,a,θ) 是指示在状态 s s s 下选择动作 a a a 的偏好函数。
- 式 (11) 中的策略满足 π ( a ∣ s , θ ) ∈ [ 0 , 1 ] \pi(a|s, \theta) \in [0, 1] π(a∣s,θ)∈[0,1],且对于任意 s ∈ S s \in S s∈S, ∑ a ∈ A π ( a ∣ s , θ ) = 1 \sum_{a \in A} \pi(a|s, \theta) = 1 ∑a∈Aπ(a∣s,θ)=1.
- 这种策略函数可以通过神经网络实现。网络的输入为 s s s,输出层为一个 softmax 层,因此网络对所有 a a a 输出 π ( a ∣ s , θ ) \pi(a|s, \theta) π(a∣s,θ),且输出的和为 1.
由于 π ( a ∣ s , θ ) > 0 \pi(a|s, \theta) > 0 π(a∣s,θ)>0 对所有 a a a 成立,因此该策略是随机的,具有探索性。策略并不直接告诉采取哪一个动作,而是根据策略的概率分布来选择动作。
(二)Discount case 结论
接下来我们将给出有折扣因子情况下度量函数的梯度,其中 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ∈(0,1)。有折扣因子情况下,状态值和动作值定义为
v π ( s ) = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ ∣ S t = s ] , v_{\pi}(s) = \mathbb{E}[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots \mid S_t = s], vπ(s)=E[Rt+1+γRt+2+γ2Rt+3+⋯∣St=s],
q π ( s , a ) = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ ∣ S t = s , A t = a ] . q_{\pi}(s, a) = \mathbb{E}[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots \mid S_t = s, A_t = a]. qπ(s,a)=E[Rt+1+γRt+2+γ2Rt+3+⋯∣St=s,At=a].
有 v π ( s ) = ∑ a ∈ A π ( a ∣ s , θ ) q π ( s , a ) v_{\pi}(s) = \sum_{a \in A} \pi(a|s, \theta) q_{\pi}(s, a) vπ(s)=∑a∈Aπ(a∣s,θ)qπ(s,a),并且状态值满足Bellman方程。首先,我们证明 v ˉ π ( θ ) \bar{v}_{\pi}(\theta) vˉπ(θ) 和 r ˉ π ( θ ) \bar{r}_{\pi}(\theta) rˉπ(θ) 是等价的度量。
引理 1【 v ˉ π ( θ ) \bar{v}_{\pi}(\theta) vˉπ(θ) 和 r ˉ π ( θ ) \bar{r}_{\pi}(\theta) rˉπ(θ) 之间的等价性】。
在有折扣因子情况下,当 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ∈(0,1) 时,有
r ˉ π = ( 1 − γ ) v ˉ π . (12) \bar{r}_{\pi} = (1 - \gamma) \bar{v}_{\pi}. \tag{12} rˉπ=(1−γ)vˉπ.(12)证明:注意 v ˉ π ( θ ) = d π T v π \bar{v}_{\pi}(\theta) = d_{\pi}^T v_{\pi} vˉπ(θ)=dπTvπ 和 r ˉ π ( θ ) = d π T r π \bar{r}_{\pi}(\theta) = d_{\pi}^T r_{\pi} rˉπ(θ)=dπTrπ,其中 v π v_{\pi} vπ 和 r π r_{\pi} rπ 满足Bellman方程 v π = r π + γ P π v π v_{\pi} = r_{\pi} + \gamma P_{\pi} v_{\pi} vπ=rπ+γPπvπ。在Bellman方程两边乘以 d π T d_{\pi}^T dπT 得
v ˉ π = r ˉ π + γ d π T P π v π = r ˉ π + γ d π T v π = r ˉ π + γ v ˉ π , \bar{v}_{\pi} = \bar{r}_{\pi} + \gamma d_{\pi}^T P_{\pi} v_{\pi} = \bar{r}_{\pi} + \gamma d_{\pi}^T v_{\pi} = \bar{r}_{\pi} + \gamma \bar{v}_{\pi}, vˉπ=rˉπ+γdπTPπvπ=rˉπ+γdπTvπ=rˉπ+γvˉπ,
注意前面提到 d ( s ) d(s) d(s)有一个性质 d π T P π = d π T d_\pi^T P_\pi=d_\pi^T dπTPπ=dπT.
其次,下面的引理给出了任何 s s s 下 v π ( s ) v_{\pi}(s) vπ(s) 的梯度,详细证明见1的第9章.
引理 2【 v π ( s ) v_{\pi}(s) vπ(s) 的梯度】
在有折扣因子情况下,对于任何 s ∈ S s \in S s∈S,有
∇ θ v π ( s ) = ∑ s ′ ∈ S Pr π ( s ′ ∣ s ) ∑ a ∈ A ∇ θ π ( a ∣ s ′ , θ ) q π ( s ′ , a ) , (13) \nabla_{\theta} v_{\pi}(s) = \sum_{s' \in S} \operatorname{Pr}_{\pi}(s'|s) \sum_{a \in A} \nabla_{\theta} \pi(a|s', \theta) q_{\pi}(s', a), \tag{13} ∇θvπ(s)=s′∈S∑Prπ(s′∣s)a∈A∑∇θπ(a∣s′,θ)qπ(s′,a),(13)
其中
Pr π ( s ′ ∣ s ) ≐ ∑ k = 0 ∞ γ k [ P π k ] s s ′ = [ ( I n − γ P π ) − 1 ] s s ′ \operatorname{Pr}_{\pi}(s'|s) \doteq \sum_{k=0}^{\infty} \gamma^k [P_{\pi}^k]_{ss'} = [(I_n - \gamma P_{\pi})^{-1}]_{ss'} Prπ(s′∣s)≐k=0∑∞γk[Pπk]ss′=[(In−γPπ)−1]ss′
是在策略 π \pi π 下从 s s s 转移到 s ′ s' s′ 的折扣总概率。这里, [ ⋅ ] s s ′ [\cdot]_{ss'} [⋅]ss′ 表示矩阵中第 s s s 行和第 s ′ s' s′ 列的元素, [ P π k ] s s ′ [P_{\pi}^k]_{ss'} [Pπk]ss′ 是在策略 π \pi π 下从 s s s 到 s ′ s' s′ 用 k k k 步转移的概率。
由上面两个引理,我们可以导出两个定理,也就是两种不同情况下 J ( θ ) J(\theta) J(θ)的梯度,详细证明见1的第9章.
定理 2【折扣情况下 v ˉ π 0 \bar{v}^{0}_{\pi} vˉπ0 的梯度】
在折扣因子 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ∈(0,1) 的情况下, v ˉ π 0 \bar{v}^{0}_{\pi} vˉπ0 的梯度 d 0 T v π d^{T}_0v_{\pi} d0Tvπ 为
∇ θ v ˉ π 0 = E [ ∇ θ ln π ( A ∣ S , θ ) q π ( S , A ) ] = ∑ s ∈ S ρ π ( s ) ∑ a ∈ A π ( a ∣ s , θ ) ∇ θ ln π ( a ∣ s , θ ) q π ( s , a ) . \begin{aligned} \nabla_{\theta} \bar{v}^{0}_{\pi} &= \mathbb{E} \left[ \nabla_{\theta} \ln \pi (A|S, \theta) q_{\pi} (S, A) \right]\\ &=\sum_{s\in S}\rho_\pi(s)\sum_{a\in A}\pi(a|s,\theta)\nabla_{\theta} \ln \pi (a|s, \theta) q_{\pi} (s, a). \end{aligned} ∇θvˉπ0=E[∇θlnπ(A∣S,θ)qπ(S,A)]=s∈S∑ρπ(s)a∈A∑π(a∣s,θ)∇θlnπ(a∣s,θ)qπ(s,a).
其中 S ∼ ρ π S \sim \rho_{\pi} S∼ρπ 且 A ∼ π ( A ∣ S , θ ) A \sim \pi(A|S, \theta) A∼π(A∣S,θ)。这里,状态分布 ρ π \rho_{\pi} ρπ 为
ρ π ( s ) = ∑ s ′ ∈ S d 0 ( s ′ ) Pr π ( s ∣ s ′ ) , s ∈ S , \rho_{\pi}(s) = \sum_{s' \in \mathcal{S}} d_{0}(s') \operatorname{Pr}_{\pi}(s | s'), \quad s \in \mathcal{S}, ρπ(s)=s′∈S∑d0(s′)Prπ(s∣s′),s∈S,
其中
Pr π ( s ∣ s ′ ) = ∑ k = 0 ∞ γ k [ P π k ] s ′ / s = [ ( I − γ P π ) − 1 ] s ′ / s \operatorname{Pr}_{\pi}(s | s') = \sum_{k=0}^{\infty} \gamma^{k} \left[ P_{\pi}^{k} \right]_{s' / s} = \left[ (I - \gamma P_{\pi})^{-1} \right]_{s' / s} Prπ(s∣s′)=k=0∑∞γk[Pπk]s′/s=[(I−γPπ)−1]s′/s
为在策略 π \pi π 下,从状态 s ′ s' s′ 以折扣概率转移至状态 s s s 的总概率。
定理 3【折扣情况下 r ˉ π \bar{r}_{\pi} rˉπ 和 v ˉ π \bar{v}_{\pi} vˉπ 的梯度】
在折扣因子 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ∈(0,1) 的情况下, r ˉ π \bar{r}_{\pi} rˉπ 和 v ˉ π \bar{v}_{\pi} vˉπ 的梯度为
∇ θ r ˉ π = ( 1 − γ ) ∇ θ v ˉ π ≈ ∑ s ∈ S d π ( s ) ∑ a ∈ A ∇ θ π ( a ∣ s , θ ) q π ( s , a ) \nabla_{\theta} \bar{r}_{\pi} = (1 - \gamma) \nabla_{\theta} \bar{v}_{\pi} \approx \sum_{s \in \mathcal{S}} d_{\pi}(s) \sum_{a \in \mathcal{A}} \nabla_{\theta} \pi(a | s, \theta) q_{\pi}(s, a) ∇θrˉπ=(1−γ)∇θvˉπ≈s∈S∑dπ(s)a∈A∑∇θπ(a∣s,θ)qπ(s,a)= E [ ∇ θ ln π ( A ∣ S , θ ) q π ( S , A ) ] , = \mathbb{E} \left[ \nabla_{\theta} \ln \pi(A | S, \theta) q_{\pi}(S, A) \right], =E[∇θlnπ(A∣S,θ)qπ(S,A)],
其中 S ∼ d π S \sim d_{\pi} S∼dπ 且 A ∼ π ( A ∣ S , θ ) A \sim \pi(A|S, \theta) A∼π(A∣S,θ)。当 γ \gamma γ 趋近于 1 时,此近似更为精确。
(三)Undiscount Case 结论
也就是 γ = 1 \gamma=1 γ=1时的情况,我们考虑公式(4)的梯度,也就是
J ( θ ) = lim n → ∞ 1 n E [ ∑ t = 0 n − 1 R t + 1 ] = r ˉ π . J(\theta) = \lim_{n \to \infty} \frac{1}{n} \mathbb{E} \left[ \sum_{t=0}^{n-1} R_{t+1} \right]=\bar{r}_\pi. J(θ)=n→∞limn1E[t=0∑n−1Rt+1]=rˉπ.
下面直接给出 r ˉ π \bar{r}_\pi rˉπ的梯度,具体证明参考1的第9章.
定理 4【非折扣情况下 r ˉ π \bar{r}_{\pi} rˉπ 的梯度】
在非折扣情况下,平均奖励 r ˉ π \bar{r}_{\pi} rˉπ 的梯度为
∇ θ r ˉ π = ∑ s ∈ S d π ( s ) ∑ a ∈ A ∇ θ π ( a ∣ s , θ ) q π ( s , a ) \nabla_{\theta} \bar{r}_{\pi} = \sum_{s \in \mathcal{S}} d_{\pi}(s) \sum_{a \in \mathcal{A}} \nabla_{\theta} \pi(a | s, \theta) q_{\pi}(s, a) ∇θrˉπ=s∈S∑dπ(s)a∈A∑∇θπ(a∣s,θ)qπ(s,a)= E [ ∇ θ ln π ( A ∣ S , θ ) q π ( S , A ) ] , = \mathbb{E} \left[ \nabla_{\theta} \ln \pi(A | S, \theta) q_{\pi}(S, A) \right], =E[∇θlnπ(A∣S,θ)qπ(S,A)],
其中 S ∼ d π S \sim d_{\pi} S∼dπ 且 A ∼ π ( S , θ ) A \sim \pi(S, \theta) A∼π(S,θ)。相比于定理 3中的折扣情况,非折扣情况下 r ˉ π \bar{r}_{\pi} rˉπ 的梯度更为简洁,因为上式严格成立,且 S S S 满足平稳分布。
总的来说,定理2,3,4是定理1在不同情况下的具体版本.
四、REINFORCE
上一小节我们介绍了如何计算 J ( θ ) J(\theta) J(θ)的梯度,我们接下来展示如何使用基于梯度的方法来优化度量函数,以获得最优策略。用于最大化 J ( θ ) J(\theta) J(θ) 的梯度上升算法为
θ t + 1 = θ t + α ∇ θ J ( θ t ) = θ t + α E [ ∇ θ ln π ( A ∣ S , θ t ) q π ( S , A ) ] , \begin{aligned} \theta_{t+1} &= \theta_{t} + \alpha \nabla_{\theta} J(\theta_{t})\\ &= \theta_{t} + \alpha \mathbb{E} \left[ \nabla_{\theta} \ln \pi(A | S, \theta_{t}) q_{\pi}(S, A) \right], \end{aligned} θt+1=θt+α∇θJ(θt)=θt+αE[∇θlnπ(A∣S,θt)qπ(S,A)],
其中 α > 0 \alpha > 0 α>0 是一个常数学习率。由于上式中的真实梯度未知(期望不好求),我们可以用随机梯度替代真实梯度,以获得以下算法:
θ t + 1 = θ t + α ∇ θ ln π ( a t ∣ s t , θ t ) q t ( s t , a t ) , \theta_{t+1} = \theta_{t} + \alpha \nabla_{\theta} \ln \pi(a_{t} | s_{t}, \theta_{t}) q_{t}(s_{t}, a_{t}), θt+1=θt+α∇θlnπ(at∣st,θt)qt(st,at),
其中 q t ( s t , a t ) q_{t}(s_{t}, a_{t}) qt(st,at) 是 q π ( s t , a t ) q_{\pi}(s_{t}, a_{t}) qπ(st,at) 的一个近似值。 q t ( s t , a t ) q_{t}(s_{t}, a_{t}) qt(st,at)主要有两种方法得到:
- 蒙特卡洛估计;
- TD 方法.
如果 q t ( s t , a t ) q_{t}(s_{t}, a_{t}) qt(st,at) 是通过蒙特卡罗估计得到的,那么该算法称为 REINFORCE或蒙特卡罗策略梯度,这是最早且最简单的策略梯度算法之一。REINFORCE算法的伪代码如下:

核心思想就是:
- 利用累计奖励值 G t G_t Gt作为 q t ( s t , a t ) q_t(s_t,a_t) qt(st,at)的无偏采样,然后再根据这个采样更新策略函数的参数 θ \theta θ.
- ∇ θ ln π ( a t ∣ s t , θ t ) \nabla_\theta \ln \pi(a_t|s_t,\theta_t) ∇θlnπ(at∣st,θt)的计算是比较方便的,比如策略函数是一个神经网络,那么在Pytorch里,我们可以根据输出,通过反向传播自动计算梯度.
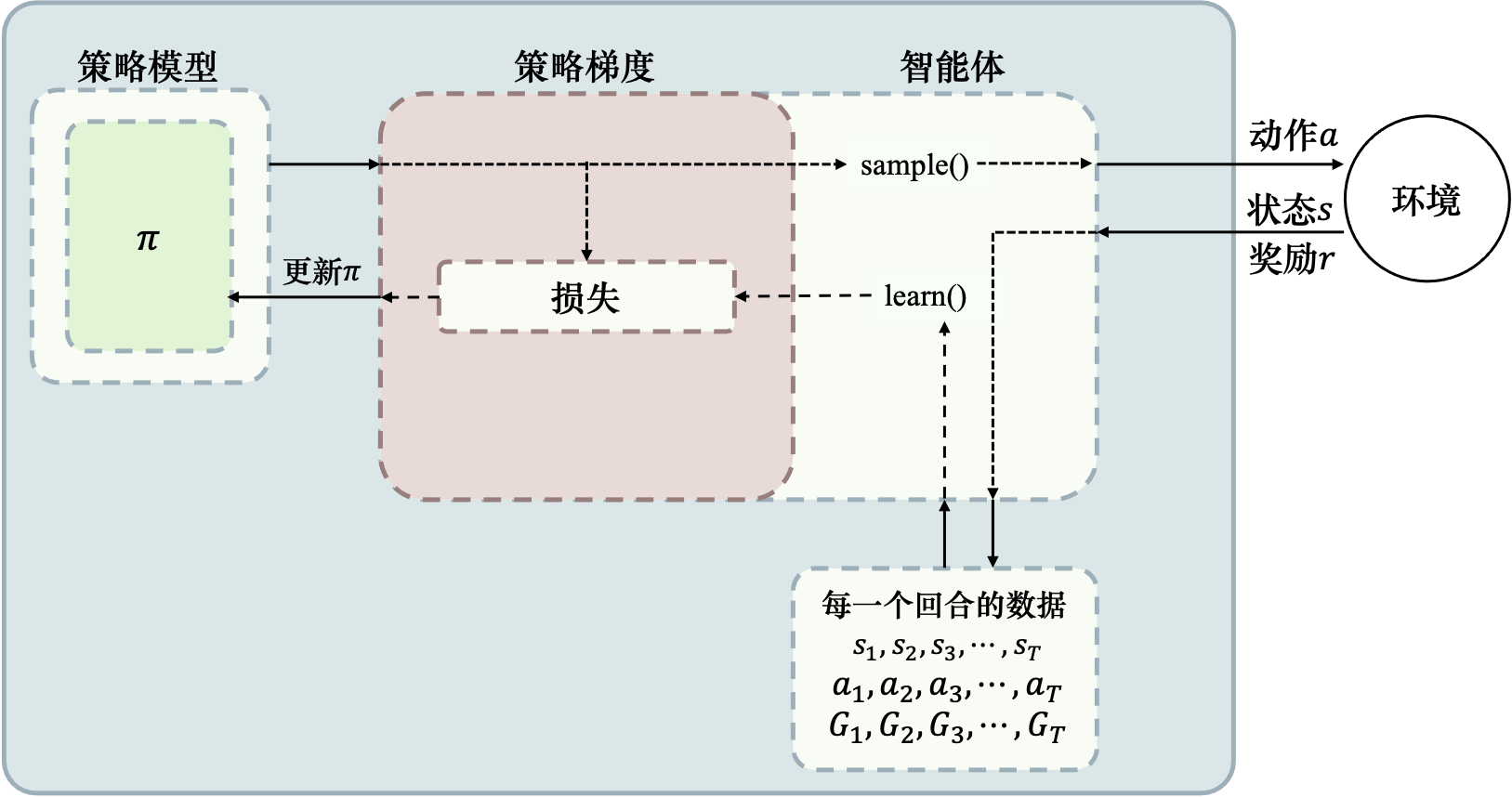
下图所示为REINFORCE 算法示意:
- 首先我们需要一个策略模型 π θ \pi_\theta πθ来与环境进行交互
- 首先从初始状态 s 0 s_0 s0输出动作概率,输出动作概率后,通过 sample() 函数得到一个具体的动作 a 0 a_0 a0,与环境交互后,得到一个奖励 r 1 r_1 r1,并转移到新的状态 s 1 s_1 s1……
- 循环直到整个episode结束,我们可以得到整个回合的数据。
- 得到回合数据之后,我们再去执行 learn() 函数,在 learn() 函数里 面,我们就可以用这些数据去构造损失函数,“扔”给优化器优化,更新我们的策略模型,也就是更新参数 θ \theta θ。
因为REINFORCE是基于蒙特卡洛采样,在蒙特卡洛方法文章里,我们也指出了蒙特卡洛方法的一些缺点,所以REINFORCE也有一些相同的问题:
- 适用于Episodic任务
- 通常情况下,任务需要有终止状态,REINFORCE才能直接计算累积折扣奖励
- 低数据利用效率
- 实际中,REINFORCE需要大量的训练数据
- 高训练方差
- 从单个或多个Episode采样得到的值函数具有很高的方差
- 下一章我们会介绍如何引入基线函数来降低样本方差
参考资料
Zhao, S… Mathematical Foundations of Reinforcement Learning. Springer Nature Press and Tsinghua University Press. ↩︎ ↩︎ ↩︎ ↩︎