使用AMD GPU进行图像分类的ResNet模型
ResNet for image classification using AMD GPUs — ROCm Blogs

2024年4月9日,作者:Logan Grado。
在这篇博客中,我们演示了如何使用ROCm在AMD GPU上训练一个简单的ResNet模型来进行CIFAR10数据集的图像分类。在AMD GPU上训练ResNet模型非常简单,仅需安装ROCm和适当的PyTorch库,无需额外的工作。
介绍
ResNet 模型最初由Kaiming He等人在 2015 年发表于Deep Residual Learning for Image Recognition 中,主要用于图像分类。该论文的关键贡献是引入了残差连接(residual connections),它允许训练比以往网络更深的网络(参见下图)。ResNet 模型被用于多种情境中,如图像分类、目标检测等。
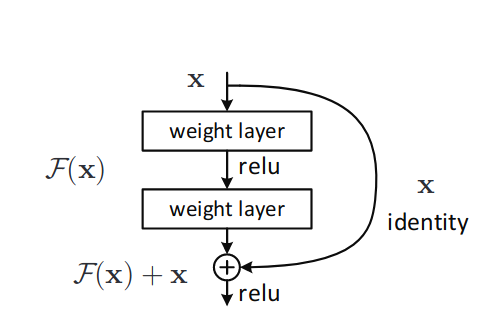
残差连接示意图,来自原始论文。残差连接(右)绕过计算块。
先决条件
要跟随本博客的内容,您需要以下条件:
-
硬件
-
AMD GPU - 参见兼容GPU列表
-
-
操作系统
-
Linux - 参见受支持的Linux发行版
-
-
软件
-
ROCm - 参见安装说明
-
运行本文代码
本文代码有两种运行方式。首先,您可以使用Docker(推荐),或者您可以构建自己的Python环境(参见附录中的在主机上运行)。
在 Docker 中运行
使用 Docker 是构建所需环境的最简单和最可靠的方法。
-
确保你已经安装了 Docker。如果没有,请参阅安装说明
-
确保您在主机上安装了
amdgpu-dkms(随 ROCm 一起提供),以便从 Docker 内部访问 GPU。请参阅ROCm Docker 说明。 -
克隆仓库,并进入博客目录
git clone git@github.com:ROCm/rocm-blogs.git cd rocm-blogs/blogs/artificial-intelligence/resnet
-
构建并启动容器。有关构建过程的详细信息,请参阅
dockerfile。这将启动一个 jupyter lab 服务器。cd docker docker compose build docker compose up
-
在浏览器中导航到 http://localhost:8888,以笔记本格式打开文件
resnet_blog.py(right click -> open with -> notebook)注意
注意:此笔记本是一个JupyText 配对笔记本,采用 py-percent 格式
在 CIFAR10 数据集上训练 ResNet 18
下面,我们将逐步讲解训练代码。
导入
首先,导入所需的包
import random import datetimeimport torch import torchvision from torchvision.transforms import v2 as transforms from datasets import load_dataset import matplotlib.pyplot as plt
数据集
任务中,我们将使用 CIFAR10 ,数据集,该数据集可以从 huggingface下载。CIFAR10数据集由60,000张32x32的图像组成,分为10个类别。
我们定义一个函数来获取训练和测试的dataloader。在这个函数中,我们将 (1) 下载数据集,(2) 设置数据格式为torch,(3) 构建训练和测试数据加载器。
def get_dataloaders(batch_size=256):"""返回cifar10数据集的测试/训练数据加载器"""# 下载数据集,并设置格式为torchdataset = load_dataset("cifar10")dataset.set_format("torch")# 构建训练/测试加载器train_loader = torch.utils.data.DataLoader(dataset["train"], shuffle=True, batch_size=batch_size)test_loader = torch.utils.data.DataLoader(dataset["test"], batch_size=batch_size)return train_loader, test_loader
数据变换
该数据集中的图像像素编码格式为 uint8,因此我们需要将其转换为 float32 并进行归一化。以下函数构造了一个组合变换,用于准备训练数据。
在下面的函数中,我们构造了一个组合的 torchvision transform,具体执行以下操作:
-
重新排列通道维度,使得我们的一批图像是“通道优先”的格式,这是
pytorch所要求的 -
转换为
float32类型 -
将值缩放到 [0,1] 范围
-
将值归一化到均值 0,标准差 1
def get_transform():"""构建并返回一个变换链,将加载的图像转换为正确的格式/数据类型,并进行归一化"""# CIFAR10 数据集的均值和标准差stats = ((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))transform = transforms.Compose([# 该数据集是通道最后格式 (B, H, W, C),需要将其重新排列为通道优先格式 (B, C, H, W) transforms.Lambda(lambda x: x.permute(0, 3, 1, 2)),# 转换为 float32 类型transforms.ToDtype(torch.float32),# 除以 255 将 uint8 转换为 [0,1] 范围transforms.Lambda(lambda x: x / 255),# 归一化transforms.Normalize(*stats, inplace=True),])return transform
构建模型、损失函数和优化器
接下来,我们需要构建在训练过程中使用的模型、损失函数以及优化器。
-
模型: 我们将使用`torchvision`中的 ResNet18, 并将`num_classes`设置为10,以匹配CIFAR10数据集。`ResNet18`是较小规模的ResNet模型之一(由18个卷积层组成),适合进行较简单的任务,如CIFAR10分类。
-
损失函数: 交叉熵损失, 标准的分类问题损失函数
-
优化器: Adam 优化器
def build_model():"""构建模型、损失函数和优化器"""# ResNet18, 具有10个类别model = torchvision.models.resnet18(num_classes=10)# 标准的交叉熵损失loss_fn = torch.nn.CrossEntropyLoss()# Adam优化器optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)return model, loss_fn, optimizer
训练循环
最后,我们将使用 PyTorch 构建一个简单的训练循环。在这里,我们将训练模型经过预定数量的 epochs。在每个 epoch 中,我们对整个训练集进行一次完整的遍历,并计算训练损失。然后,我们对测试集进行一次完整的遍历,计算测试损失和准确率。
def train_model(model, loss_fn, optimizer, train_loader, test_loader, transform, num_epochs):"""根据预定的 epoch 数量进行模型训练"""# 声明训练设备print(f"Number of GPUs: {torch.cuda.device_count()}")print([torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())])device = torch.device("cuda" if torch.cuda.is_available() else "cpu")t0 = datetime.datetime.now()model.to(device)model.train()accuracy = []# 主训练循环for epoch in range(num_epochs):print(f"Epoch {epoch+1}/{num_epochs}")t0_epoch_train = datetime.datetime.now()# 迭代训练数据集train_losses, n_examples = [], 0for batch in train_loader:batch = {k: v.to(device) for k, v in batch.items()}optimizer.zero_grad()preds = model(transform(batch["img"]))loss = loss_fn(preds, batch["label"])loss.backward()optimizer.step()train_losses.append(loss)n_examples += batch["label"].shape[0]train_loss = torch.stack(train_losses).mean().item()t_epoch_train = datetime.datetime.now() - t0_epoch_train# 执行评估with torch.no_grad():t0_epoch_test = datetime.datetime.now()test_losses, n_test_examples, n_test_correct = [], 0, 0for batch in test_loader:batch = {k: v.to(device) for k, v in batch.items()}preds = model(transform(batch["img"]))loss = loss_fn(preds, batch["label"])test_losses.append(loss)n_test_examples += batch["img"].shape[0]n_test_correct += (batch["label"] == preds.argmax(axis=1)).sum()test_loss = torch.stack(test_losses).mean().item()test_accuracy = n_test_correct / n_test_examplest_epoch_test = datetime.datetime.now() - t0_epoch_testaccuracy.append(test_accuracy.cpu())# 打印指标print(f" Epoch time: {t_epoch_train+t_epoch_test}")print(f" Examples/second (train): {n_examples/t_epoch_train.total_seconds():0.4g}")print(f" Examples/second (test): {n_test_examples/t_epoch_test.total_seconds():0.4g}")print(f" Train loss: {train_loss:0.4g}")print(f" Test loss: {test_loss:0.4g}")print(f" Test accuracy: {test_accuracy*100:0.4g}%")total_time = datetime.datetime.now() - t0print(f"Total training time: {total_time}")return accuracy
训练模型Train the Model
最后,我们可以把所有组件组合起来放进主方法中。在这里,我们将:
-
设置随机种子以确保可重复性
-
构建所有组件(模型、数据加载器等)
-
调用我们的训练方法
seed = 0 random.seed(seed) torch.manual_seed(seed)model, loss, optimizer = build_model() train_loader, test_loader = get_dataloaders() transform = get_transform()test_accuracy = train_model(model, loss, optimizer, train_loader, test_loader, transform, num_epochs=8)
Epoch 1/8Epoch time: 0:00:15.129099Examples/second (train): 3639Examples/second (test): 7204Train loss: 1.796Test loss: 1.409Test accuracy: 48.88%...Epoch 8/8Epoch time: 0:00:07.136725Examples/second (train): 8182Examples/second (test): 9748Train loss: 0.6939Test loss: 0.7904Test accuracy: 72.87%Total training time: 0:00:57.931011
接下来,我们画出训练过程中准确率的变化情况。
fig,ax = plt.subplots()
ax.plot(test_accuracy)
ax.set_xlabel("epoch")
ax.set_ylabel("accuracy")
plt.show()

最后,我们可以绘制一些预测图像来查看我们的结果。
label_dict = {0: 'airplane',1: 'automobile',2: 'bird',3: 'cat',4: 'deer',5: 'dog',6: 'frog',7: 'horse',8: 'ship',9: 'truck'}# 绘制前5张图片
N = 5
device='cuda'
for batch in test_loader:batch = {k: v.to(device) for k, v in batch.items()}preds = model(transform(batch["img"])).argmax(axis=1)labels = batch['label'].cpu()fig,ax = plt.subplots(1,N,tight_layout=True)for i in range(N):ax[i].imshow(batch['img'][i].cpu())ax[i].set_xticks([])ax[i].set_yticks([])ax[i].set_xlabel(f"Label: {label_dict[labels[i].item()]}\nPred: {label_dict[preds[i].item()]}")break

总结
在这篇博客中,我们展示了如何使用AMD GPU在CIFAR10数据集上训练ResNet图像分类器,并在不到一分钟的时间内实现了73%的准确率!所有这些都可以在搭载ROCm的AMD GPU上无缝运行。我们可以通过采用一些技术进一步提高性能,例如学习率调度器、数据增强和更多的训练轮数,这些技术将留给读者自己完成。
参考文献
-
图像识别的深度残差学习
-
huggingface cifar10数据集
-
CIFAR10CIFAR10 - 从微小图像中学习多层特征,Alex Krizhevsky,2009
附录
在主机上运行
如果您不想使用 Docker,也可以直接在您的机器上运行这篇博客 - 虽然这需要多一点工作。
-
先决条件:
-
安装ROCm 5.7.x
-
确保您已经安装了 Python 3.10
-
安装 PDM - 在这里用于创建可重复的 Python 环境
-
-
在博客的根目录下创建 Python 虚拟环境:
pdm sync
-
启动笔记本
pdm run jupyter-lab
导航到 https://localhost:8888 并运行博客