智慧医疗——提出了一种基于敌对领域适应症预测候选抗癌药物的方法
导言
本方法的研究背景和要点
据估计,未来每两个日本人中就有一人会患上癌症,它是现代人最难以治愈的疾病之一。众所周知,癌症的发生和发展是由于人类和其他动物的细胞生长机制遭到破坏,细胞变成了被称为癌细胞的特殊细胞。
癌症干细胞是一种特别特殊的癌细胞。干细胞是一种特化细胞,具有自我复制或转变为具有多种功能的细胞(这被称为分化)的能力。癌症干细胞既有作为癌细胞的特性(细胞调节功能被破坏),也有作为干细胞的特性。
众所周知,这些癌症干细胞对癌症转移和****复发有重大影响。特别是近年来,为治疗癌症而开发的药物改变了癌症干细胞的分化方式,并诱导它们抑制癌症的发展。
本文介绍了一种新模型的开发情况,该模型利用一种称为对抗性领域适应的技术来识别新的候选药物,尤其侧重于乳腺癌和其他癌症。
模型结构
关于该模型中使用的敌域适应
领域适应是计算机视觉领域广为熟知的一种方法,用于将在一个领域(如摄影)训练的模型应用到另一个领域(如绘画)。
在本文中,我们利用了这一技术的进一步发展,即对抗性域适应(详见下文)。研究表明,这种方法可用于消除不同数据集的特定偏差,并训练跨不同平台利用大量信息的模型。
学习工作流程
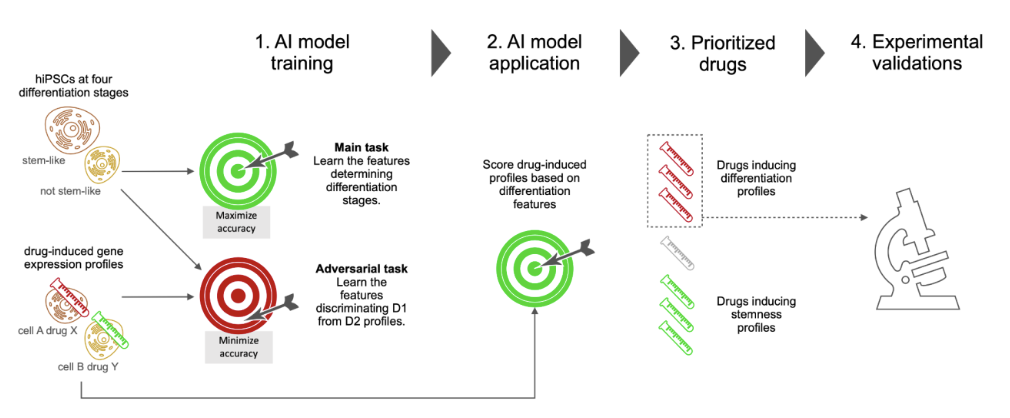
该模型中的任务包括两类**:主要任务(图中用主要任务表示)和对抗任务(图中用对抗任务表示)**。
前一项任务(主要任务)使用源域来学习细胞所处的四个分化阶段。在这项任务中,要对模型进行训练,使预测分化阶段的四值分类准确率尽可能高。
后一种任务(对抗性任务)学习如何区分源域和目标域。换句话说,它学习如何使这些数据集的识别准确率尽可能小。通过引入这种学习机制,可以消除每个数据集的偏差。
然后,根据药物诱导分化的能力,使用训练有素的模型对源域和靶域进行评分,如图 2 所示。
然后,如图3所示,利用刚刚获得的分数来确定促进细胞分化和保持干细胞特征的合适候选药物。
最后,我们选择了六个优先代理在真实细胞上进行测试,如图 4 所示。
因此,在进行实验之前利用深度学习来缩小候选药物的范围,相信可以大大降低估算候选药物所需的时间和****成本。
整体模型
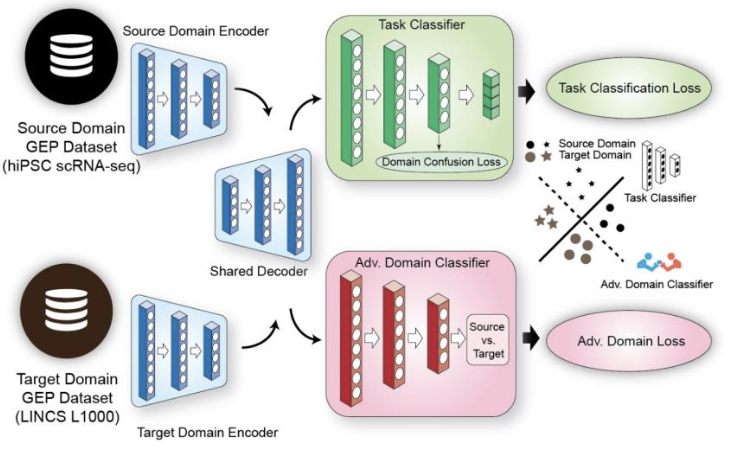
该图概述了模型的实际训练过程。如图所示,模型首先使用源域数据集和目标****域数据集进行训练,每个数据集使用不同的编码器。
然后将两种编码器获得的各自特征进行整合,并将其作为训练解码器的输入。
解码器的输出被用作后续任务分类器(绿色)和对抗域分类器(红色)的输入。
任务分类器****使用 MLP 层来预测它将属于四个分化阶段中的哪一个。在训练过程中,会**使用一个损失函数(****任务分类损失)来提高预测的准确性,并使用一个损失函数(领域混淆损失)**来减少领域固有的偏差。
另一方面,对抗域分类器通过使用损失函数(Adv. Domain Loss)来学习如何在源域和目标域之间进行判别,从而最大限度地降低判别的准确性。
关于数据集
源域数据集是关于人类诱导多能干细胞(源自成人体细胞的干细胞,缩写为hiPSCs)的信息的系统汇编,使用一种技术(scRNA-seq)进行分析,以确定源自细胞的基因的功能。
而目标域数据集(LINCS L1000)则是根据基因如何影响细胞功能,对细胞如何对所有刺激做出反应进行的大规模分析和系统汇编。
后者是一个数据集,其中汇集了特定药物如何影响功能的信息,如图所示,详细说明了给细胞 A(或细胞 B)注射药物 X(或药物 Y)最终会如何影响其功能。如图所示,数据集详细说明了给细胞 A(或细胞 B)注射药物 X(或药物 Y)最终会如何影响其功能。
在这项研究中,首先利用域适应来学习细胞从源域分化的模式,然后利用这一知识来预测每种药剂诱导分化的能力。
学习进度示意图。
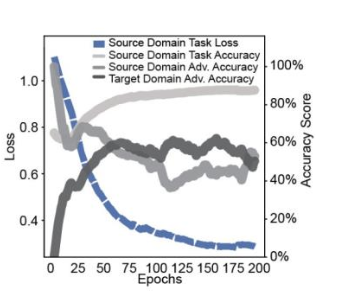
该图显示了学习的进展情况,横轴代表学习中的历时,纵轴代表损失。源域任务分类器的损失变化以蓝色显示,该分类器的准确率变化以浅灰色显示,对抗分类器的源域准确率变化以灰色显示,目标域准确率变化以深灰色显示。
任务分类器(浅灰色)的准确率达到 86.7%。至于对抗分类器的准确率,预计使用源域的准确率(灰色)和使用目标域的准确率(深灰色)都将接近50%,因为我们的目标是尽可能降低区分两类数据集的能力,但图中确实收敛到了这一数值。从图中可以看出,它们确实趋近于该值。
领域调整前后的比较
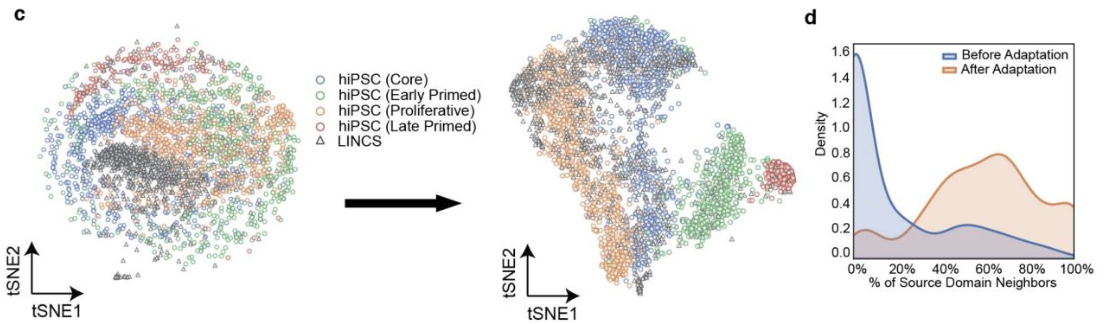
在上图 c 中,显示了tSNE分析结果在域适应之前(左侧面板)和之后(右侧面板)的情况。蓝色、绿色、黄色和红色显示的是将源域聚类为四类后得到的分布,黑色显示的是目标域所用数据集得到的分布。
研究表明,在域适应之前,处于不同分化阶段的细胞非常分散,而在域适应之后,它们的区分度更高,目标域的分布遍布源域的分布。
实验结果
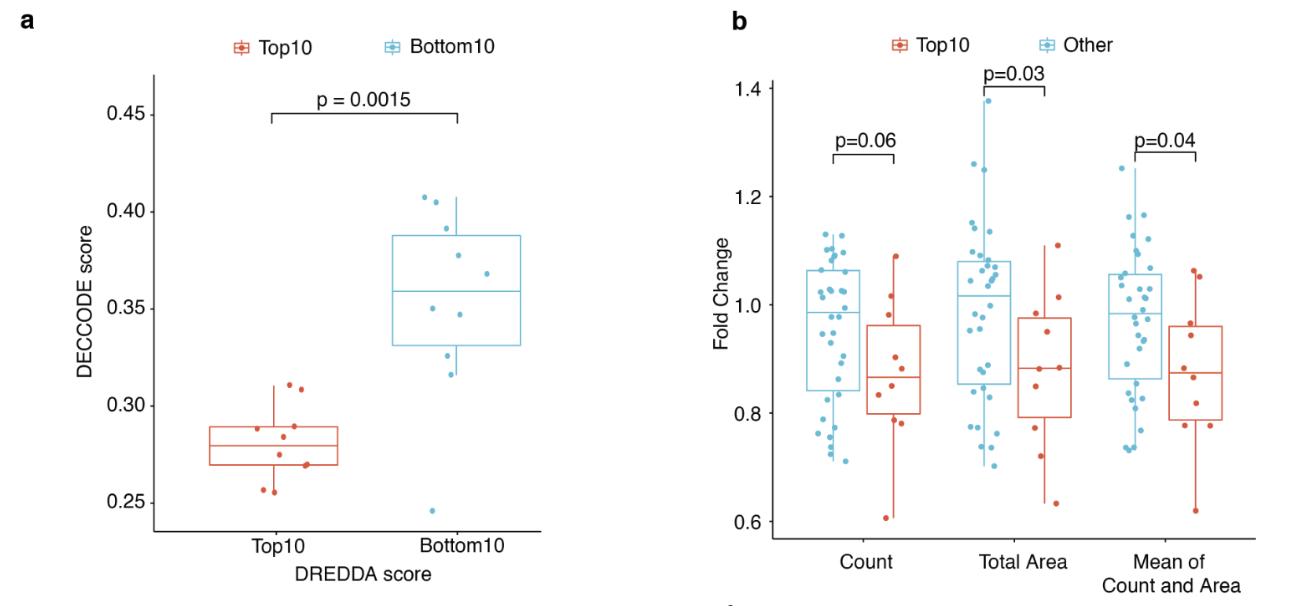
该图显示了对模型预测的候选药物进行化学实验的结果。
首先,在图a中,该模型预测的前10种候选药物的DECODE得分显示为红色,表明它们**作为干细胞的特征,**而后10种候选药物的得分显示为蓝色。
DECODE 分数越高,干细胞特征就越强,从图中可以预测,优先级较高的候选药物具有较高的干细胞特征。
图b显示了药物治疗前后三项指标值的比率:干细胞群数量、干细胞群形成的总面积及其平均值。这表明,使用模型预测的候选药物会对干细胞特性的各项指标产生影响。
此外,论文还评估了优先候选药物对乳腺癌干细胞的影响,结果显示这些药物能抑制这些细胞的生长和自我更新能力。换句话说,这证实了每种药物都非常有效。
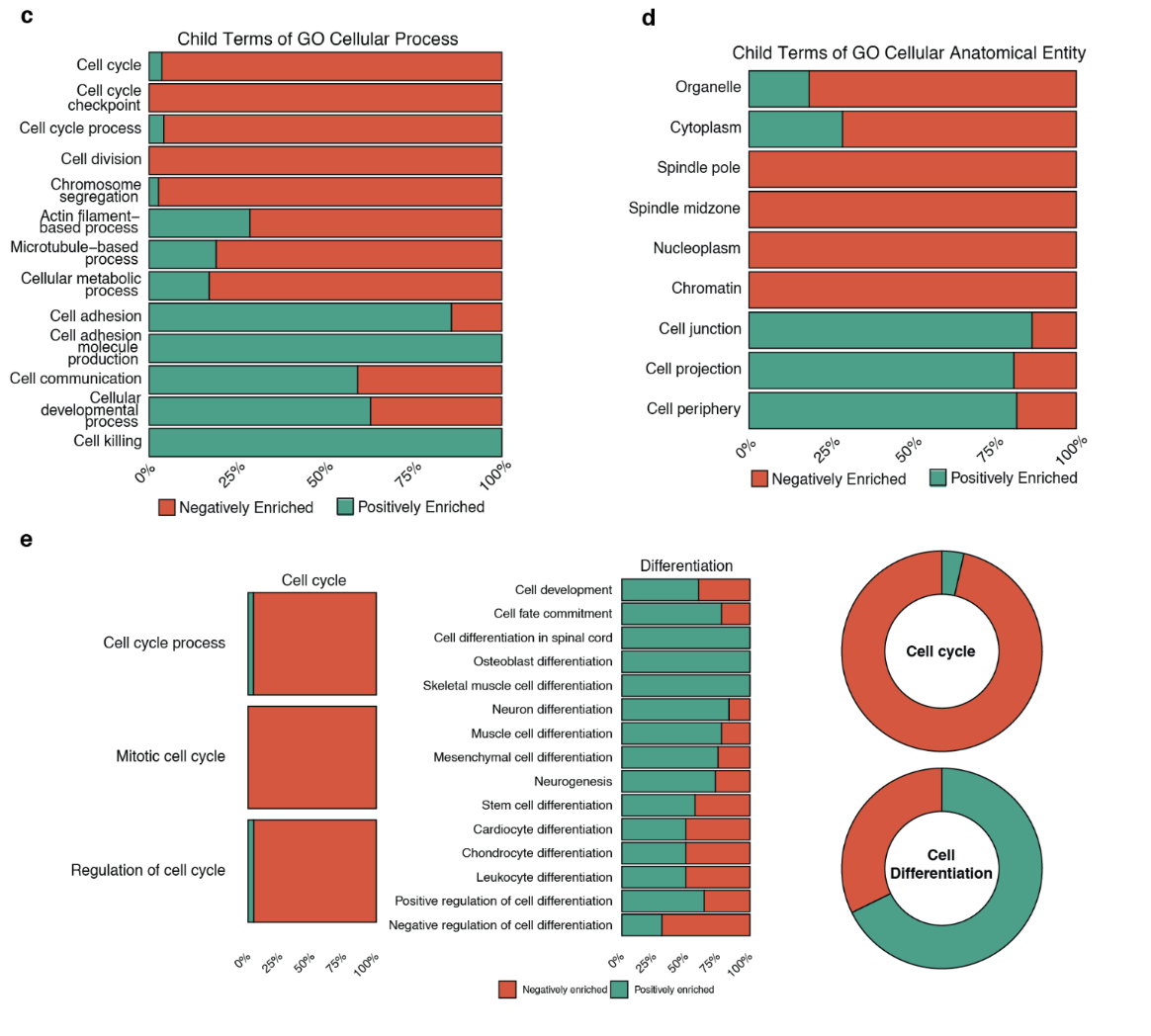 图 c 至图 e 显示了模型预测的 30 种候选药物中抑制或促进细胞功能和细胞结构相关过程的百分比。红色表示抑制功能,绿色表示促进功能。
图 c 至图 e 显示了模型预测的 30 种候选药物中抑制或促进细胞功能和细胞结构相关过程的百分比。红色表示抑制功能,绿色表示促进功能。
这些数据表明,模型预测的候选药物抑制了细胞周期相关基因的功能,同时促进了细胞分化。换句话说,这表明候选药物能够以明确的方式调节癌症干细胞的特性。
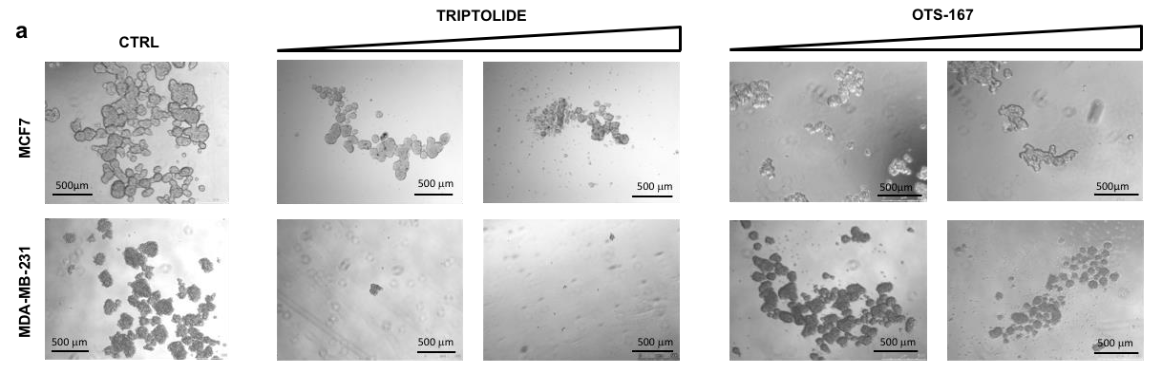

上图 a 至 c 说明了模型预测的药剂如何影响乳腺癌干细胞自我生长和复制的能力。
图a直观地显示了药物的作用。上下两行显示了实验中使用的癌症干细胞的代表性实例。五列中最左边的一列显示了不使用药物时干细胞特性受到的影响,左起第二列和第三列分别显示了药物"TRIPROLIDE “的浓度以及模型预测得到的药物"OTS-167**”**的浓度逐渐增加的情况。下表显示
可以看出,药物浓度越高,质量占据的比例越小(即药物抑制了癌症干细胞的功能,或者换句话说,药物作为一种治疗手段是有效的)。
图b进一步量化了这一点,显示了在使用三种不同药物时,左半边的一个癌症干细胞和右半边的另一个干细胞的特性有何不同(可以肯定的是,每个图的横轴代表药物浓度,纵轴代表癌症干细胞特性的强度)。).
未添加药物的情况显示为****蓝色,添加少量药物的情况显示为红色,添加大量药物的情况显示为绿色。该图证实,绿色在纵轴上的得分往往低于蓝色或红色(即癌症干细胞功能可以被抑制,换句话说,机器学习模型预测的药物作为一种治疗方法是适当有效的)。
总结
本研究提出了一种基于对抗域适应机器学习方法的模型,用于识别与抑制癌症干细胞功能相关的候选药物。具体来说,该模型引入了一个敌对域分类器,将两个数据集区分为源域和****目标域,并引入了一个损失函数来减少两个数据集之间的偏差,以便进行训练。
根据模型的预测得分选出的候选药物通过实验显示了对受癌症不利影响的细胞功能的作用,从而证实了模型的有效性。
为了进一步推动这项研究,作者希望通过临床试验评估药物的疗效和安全性,并从化学角度阐明分子机制。
不仅在这篇论文中,在其他论文中,机器学习也被广泛用于缩小大量候选药物的范围,并通过对这些候选药物进行成本高昂的实验验证来加速药物发现。如果有人感兴趣,我们建议您相关论文。
注:
论文地址:https://www.biorxiv.org/content/10.1101/2023.08.21.554075v1.full.pdf