Nat Med病理AI系列|哈佛大学团队发表研究,探讨深度学习在病理诊断中的公平性问题及解决方案|顶刊精析·24-11-02
小罗碎碎念
今天分析Nature Medicine病理AI系列的第四篇文章——《Demographic bias in misdiagnosis by computational pathology models》,来自哈佛大学 Faisal Mahmood课题组。
这篇文章很有意思,是他们课题组发了几篇基础模型以后,附赠的一篇产物。为什么这么说呢?因为这篇文章研究的是数据集的偏差问题,或者说模型的公平性问题,最后用他们发表的基础模型的来做测试,发现通过基础模型提取特征,可以缓解这种偏差程度。

| 作者类型 | 作者姓名 | 作者单位(中文) |
|---|---|---|
| 第一作者 | Anurag Vaidya | 哈佛医学院布里格姆和妇女医院病理科 |
| 第一作者 | Richard J. Chen | 哈佛医学院布里格姆和妇女医院病理科 |
| 第一作者 | Drew F. K. Williamson | 哈佛医学院布里格姆和妇女医院病理科 |
| 通讯作者 | Faisal Mahmood | 哈佛医学院布里格姆和妇女医院病理科 |
文章探讨了在计算病理学模型中,由于人口统计因素对模型性能的影响,可能导致的诊断偏差问题。
主要内容包括:
-
问题背景:尽管基于深度学习的计算病理系统获得了越来越多的监管批准,但这些系统往往忽视了人口统计因素对性能的影响,可能导致偏差。尤其是在使用大型公共数据集时,这些数据集往往不能充分代表某些人口群体。
-
研究方法:研究者使用了来自癌症基因组图谱(The Cancer Genome Atlas, TCGA)和EBRAINS脑肿瘤图谱的公开数据,以及内部患者数据,展示了在用于乳腺癌和肺癌亚型分类以及预测胶质瘤中IDH1突变的全切片图像分类模型在不同人口统计群体间显示出显著的性能差异。
-
研究发现:例如,在乳腺癌亚型分类中,白人和黑人患者之间的性能差距(以接收者操作特征曲线下面积表示)为3.0%,肺癌亚型分类为10.9%,胶质瘤中IDH1突变预测为16.0%。研究发现,从自监督视觉基础模型获得的更丰富的特征表示可以减少群体间性能差异。
-
研究意义:尽管自监督视觉基础模型不能完全消除这些差异,但它们在减少偏差方面显示出潜力,这强调了在计算病理学中继续努力减轻偏差的必要性。研究还表明,结果不仅限于种族,还扩展到其他人口统计因素。
-
政策建议:鉴于这些发现,研究者鼓励监管和政策机构在评估指南中纳入按人口统计分层的评估。
文章强调了在开发和部署计算病理学模型时,需要考虑和解决模型可能存在的人口统计偏差,以确保所有患者群体都能获得公平和准确的诊断。
一、数据集特征、公平性指标和建模选择研究
TCGA、MGB队列和EBRAINS脑肿瘤图谱
这张图展示了模型的开发和验证过程,特别是在不同种族和数据集上的表现。
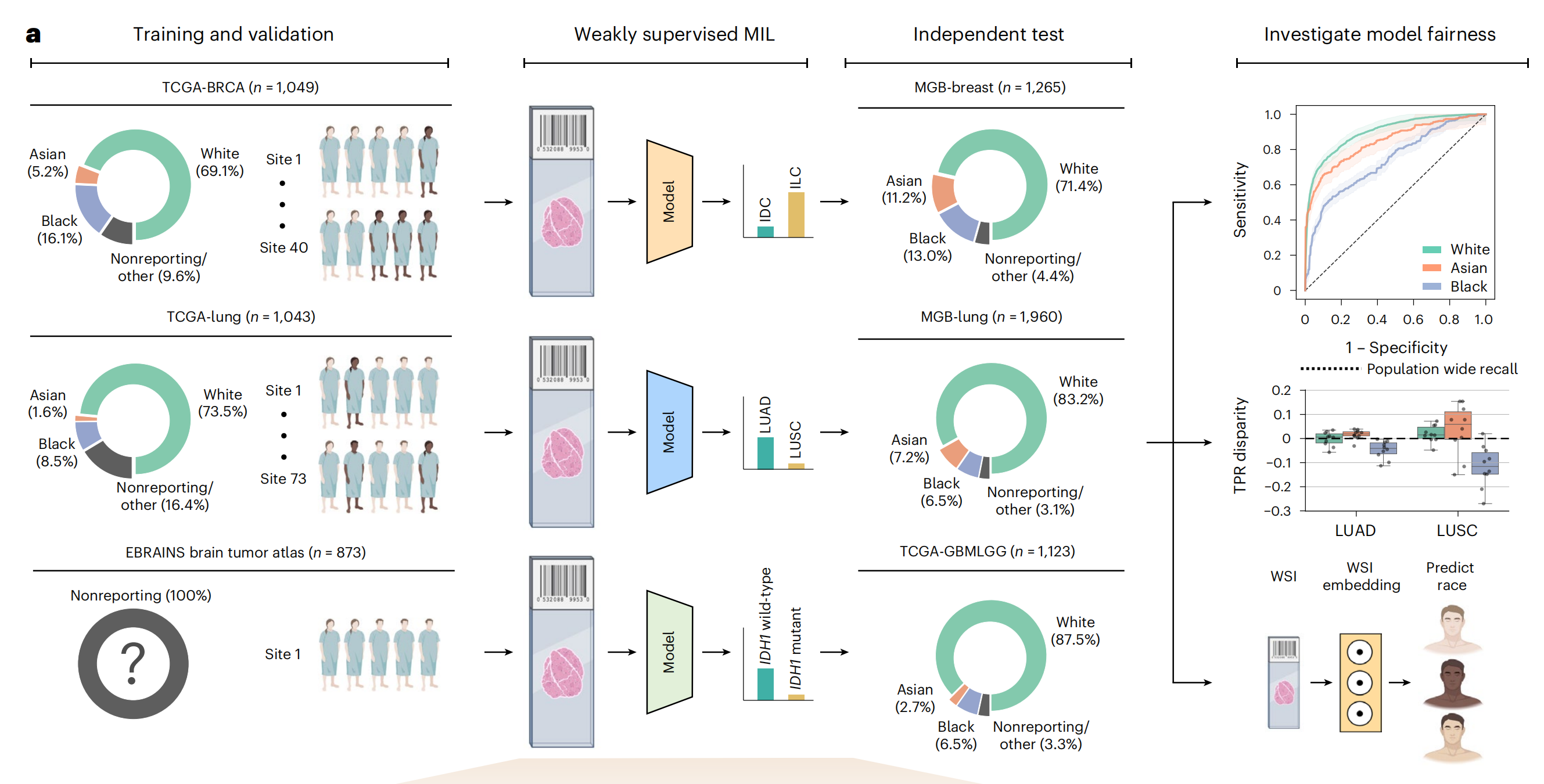
以下是对图中各部分的详细分析:
训练和验证 (Training and validation)
- TCGA-BRCA (n = 1,049): 这是乳腺癌数据集,包含1,049个样本。种族分布为:亚洲人(5.2%)、黑人(16.1%)、白人(69.1%)和其他(9.6%)。
- TCGA-lung (n = 1,043): 这是肺癌数据集,包含1,043个样本。种族分布为:亚洲人(1.6%)、黑人(8.5%)、白人(73.5%)和其他(16.4%)。
- EBRAINS brain tumor atlas (n = 873): 这是脑肿瘤数据集,包含873个样本。所有样本均为非报告种族。
弱监督多实例学习 (Weakly supervised MIL)
- 模型在训练数据上进行训练,使用弱监督多实例学习(MIL)方法。这种方法允许模型从包含多个实例的数据集中学习,即使这些实例的标签不完全准确。
独立测试 (Independent test)
- MGB-breast (n = 1,265): 这是乳腺癌的独立测试数据集,包含1,265个样本。种族分布为:亚洲人(11.2%)、黑人(13.0%)、白人(71.4%)和其他(4.4%)。
- MGB-lung (n = 1,960): 这是肺癌的独立测试数据集,包含1,960个样本。种族分布为:亚洲人(7.2%)、黑人(6.5%)、白人(83.2%)和其他(3.1%)。
- TCGA-GBMLGG (n = 1,123): 这是胶质母细胞瘤数据集,包含1,123个样本。种族分布为:亚洲人(2.7%)、黑人(6.5%)、白人(87.5%)和其他(3.3%)。
调查模型公平性 (Investigate model fairness)
- 敏感性 (Sensitivity): 图表显示了模型在不同种族(白人、亚洲人、黑人)上的敏感性。敏感性是指模型正确识别正例的能力。
- 特异性 (Specificity): 图表显示了模型在不同种族上的特异性。特异性是指模型正确识别负例的能力。
- TPR差异 (TPR disparity): 图表显示了不同种族间的真阳性率(True Positive Rate, TPR)差异。TPR是敏感性的另一种说法。
- WSI embedding: 这部分涉及到使用全切片图像(Whole Slide Image, WSI)进行特征嵌入,以预测种族。
这张图强调了在机器学习模型开发中考虑种族多样性和模型公平性的重要性。
多实例学习的不同阶段
这张图展示了一个用于全切片图像(Whole Slide Image, WSI)分析的机器学习流程。
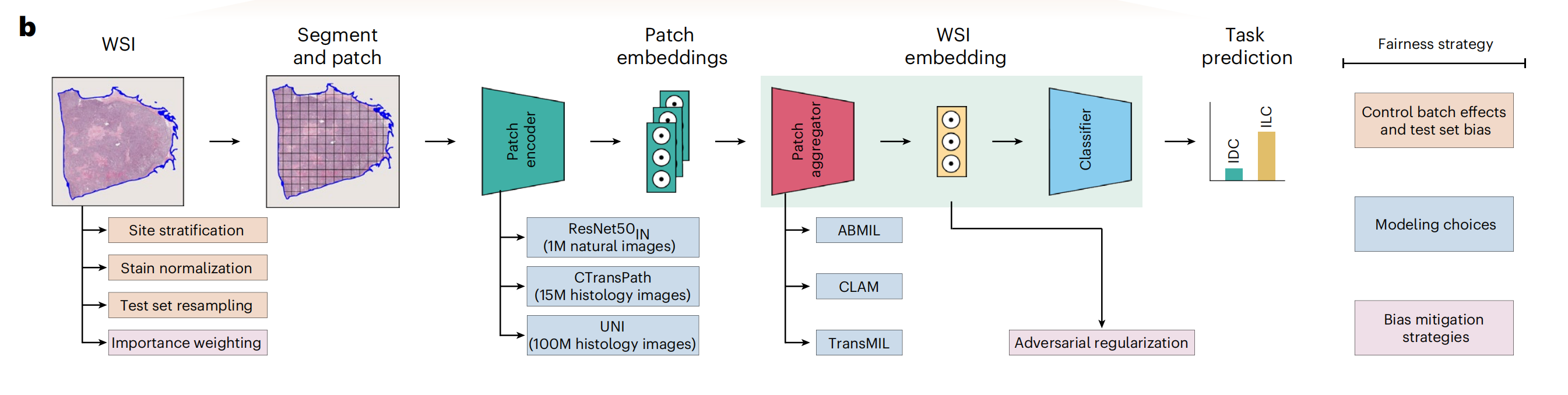
以下是对图中各部分的详细分析:
数据预处理和增强 (Data Preprocessing and Augmentation)
- WSI: 全切片图像,没啥好解释的。
- Site stratification: 根据图像来源的地点进行分层,以确保模型训练的多样性和代表性。
- Stain normalization: 标准化染色过程,因为不同的染色技术可能会影响图像的颜色和对比度。
- Test set resampling: 对测试集进行重新采样,以确保模型在未见过的数据上也能表现良好。
- Importance weighting: 根据样本的重要性进行加权,这可能涉及到对某些关键特征或区域给予更高的关注。
图像分割和打补丁 (Segment and Patch)
Segment and patch: 将WSI图像分割成多个小块(patches),这些小块随后被用于训练模型。
补丁编码 (Patch Encoding)
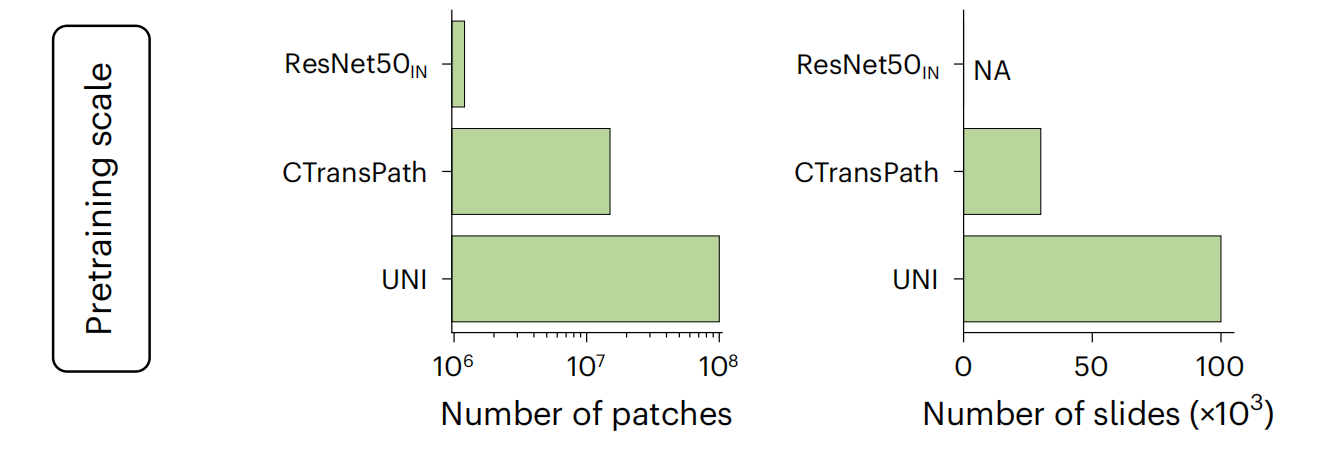
Patch encoder: 使用不同的模型(如ResNet50、CTransPath、UNI)对这些图像块进行编码,提取特征。
补丁聚合 (Patch Aggregation)
Patch aggregator: 将所有补丁的特征进行聚合,以形成一个综合的特征表示。这一步涉及到使用特定的算法(如ABML、CLAM、TransMIL)来整合信息。
WSI嵌入和分类 (WSI Embedding and Classification)
- WSI embedding: 将聚合后的特征转换为WSI级别的嵌入,这代表了整个图像的特征。
- Classifier: 使用分类器对WSI嵌入进行分类,预测癌症类型。
任务预测和公平性策略 (Task Prediction and Fairness Strategy)
- Task prediction: 根据模型的输出进行最终的癌症类型预测。
- Fairness strategy: 采取一系列策略来确保模型的预测是公平的,这包括控制批次效应和测试集偏差、建模选择以及偏差缓解策略。
常见的偏差缓解策略
这张图展示了两个主要概念:加权采样(Weighted sampling)和偏差缓解策略(Bias mitigation strategies),用于改善机器学习模型的公平性和准确性。
IW策略通过调整样本权重来确保每个种族在训练集中都有适当的代表性。AR策略旨在训练模型,使其无法从特征中识别出种族信息,从而减少种族偏见。
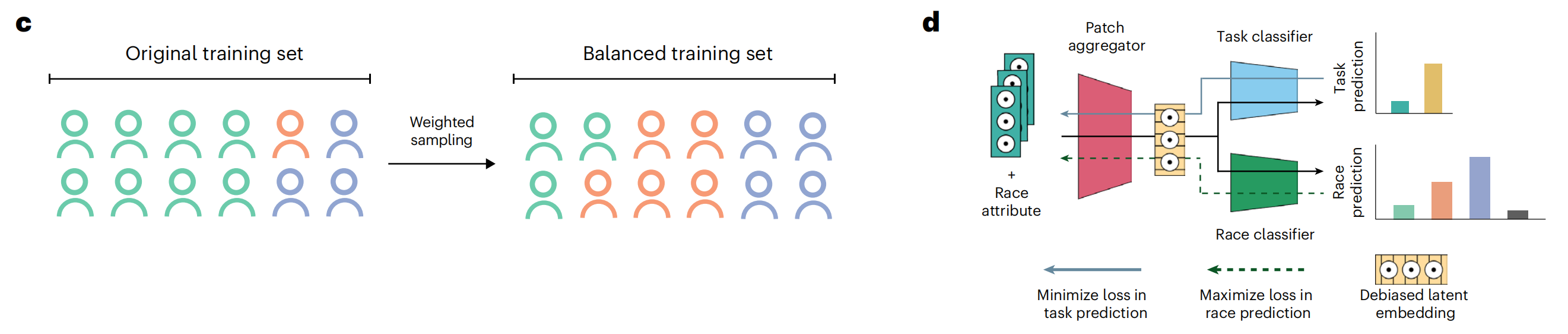
加权采样 (Weighted sampling)
- Original training set: 原始训练集包含不同类别的数据点,其中某些类别(如蓝色和橙色)可能比其他类别(如青色)更常见。
- Weighted sampling: 通过加权采样技术,模型在训练过程中给予较少见的类别更高的权重。这有助于平衡类别间的不平衡,确保模型不会偏向于多数类。
- Balanced training set: 结果是得到一个更平衡的训练集,其中所有类别的数据点在训练过程中具有相似的影响力。
偏差缓解策略 (Bias mitigation strategies)
- Patch aggregator: 从图像中提取的多个补丁(patches)被聚合以形成图像级别的特征表示。
- Race attribute: 在模型训练中加入种族属性,这可能是为了监控或调整模型对不同种族的预测行为。
- Task classifier: 主要的分类器负责任务预测,如癌症类型的识别。
- Race classifier: 辅助分类器尝试预测种族属性,这通常不是最终目标,但用于调整模型以减少种族偏见。
- Debiased latent embedding: 通过最大化种族预测的损失(即,使种族预测变得困难),同时最小化任务预测的损失,模型学习到一个去偏见的特征嵌入(latent embedding)。
- Maximize loss in race prediction: 通过增加种族分类器的预测难度,推动模型学习到一个更公平的表示。
- Minimize loss in task prediction: 确保模型在主要任务(如疾病诊断)上保持高准确性。
二、数据特征导致的偏差
肺、乳腺癌亚型分类及IDH1突变预测
这张图是一个雷达图,用于展示不同种族(白人、黑人、亚洲人)在三种不同任务(IDH1突变检测、肺亚型分类、乳腺亚型分类)上的表现,以及整体表现。
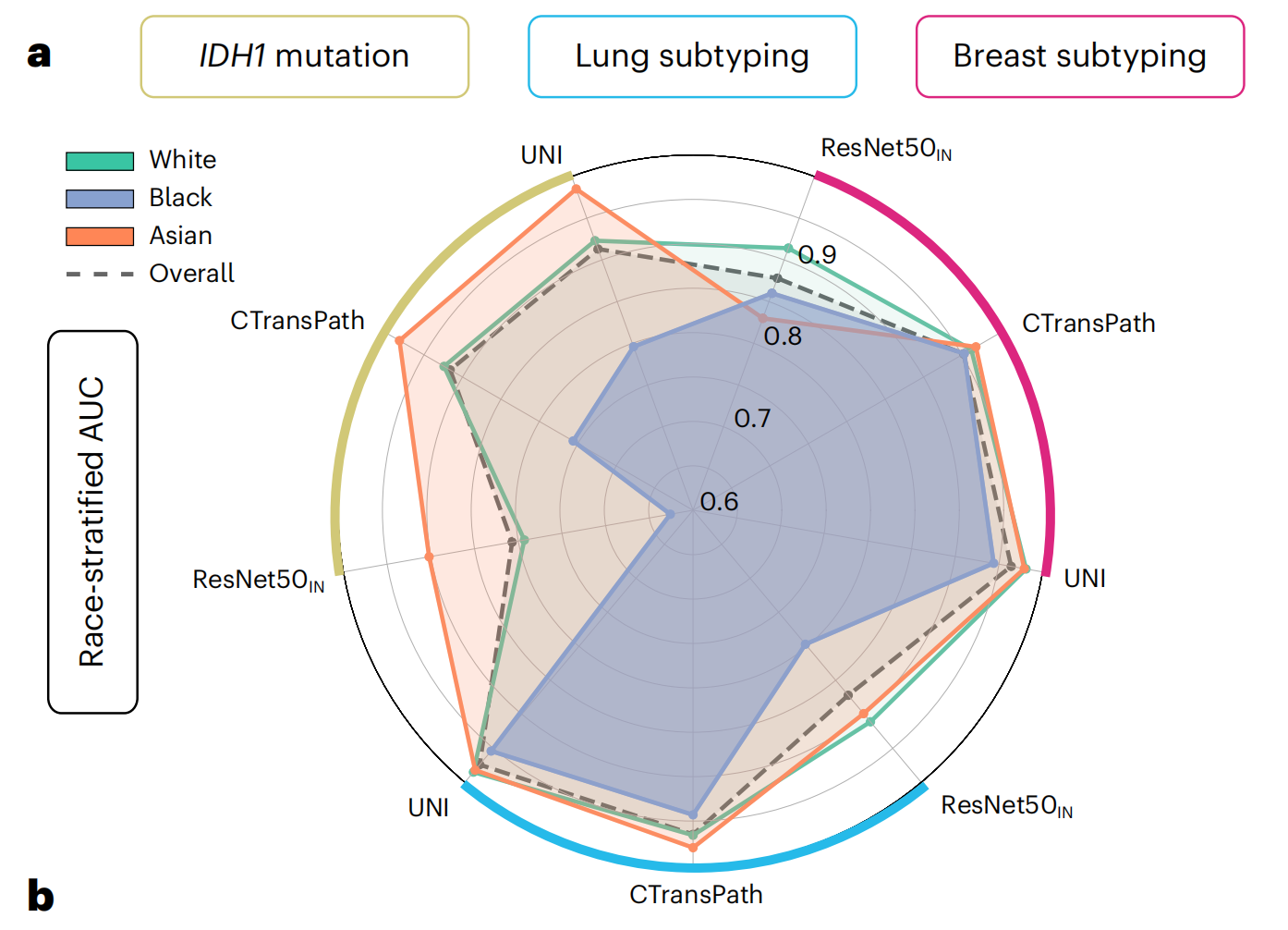
图中使用了三种不同的模型:ResNet50、CTransPath和UNI。以下是对图中各部分的详细分析:
种族和任务
- White (青色): 代表白人群体的表现。
- Black (蓝色): 代表黑人群体的表现。
- Asian (橙色): 代表亚洲人群体的表现。
- Overall (黑色虚线): 代表所有种族的总体表现。
任务
- IDH1 mutation: 检测IDH1基因突变的任务。
- Lung subtyping: 肺亚型分类任务。
- Breast subtyping: 乳腺亚型分类任务。
切块编码器预训练规模
每个任务的种族分层TPR差异
这张图展示了在不同癌症亚型和IDH1突变状态中,不同种族(白人、黑人、亚洲人)之间的真阳性率(TPR)差异。
将没有数据处理(称为“Base”)的UNI编码器的ABMIL与具有站点保留训练和染色归一化的变体进行了对比,使用重新采样的测试队列进行测试。IDH1突变预测不可用站点分层训练。
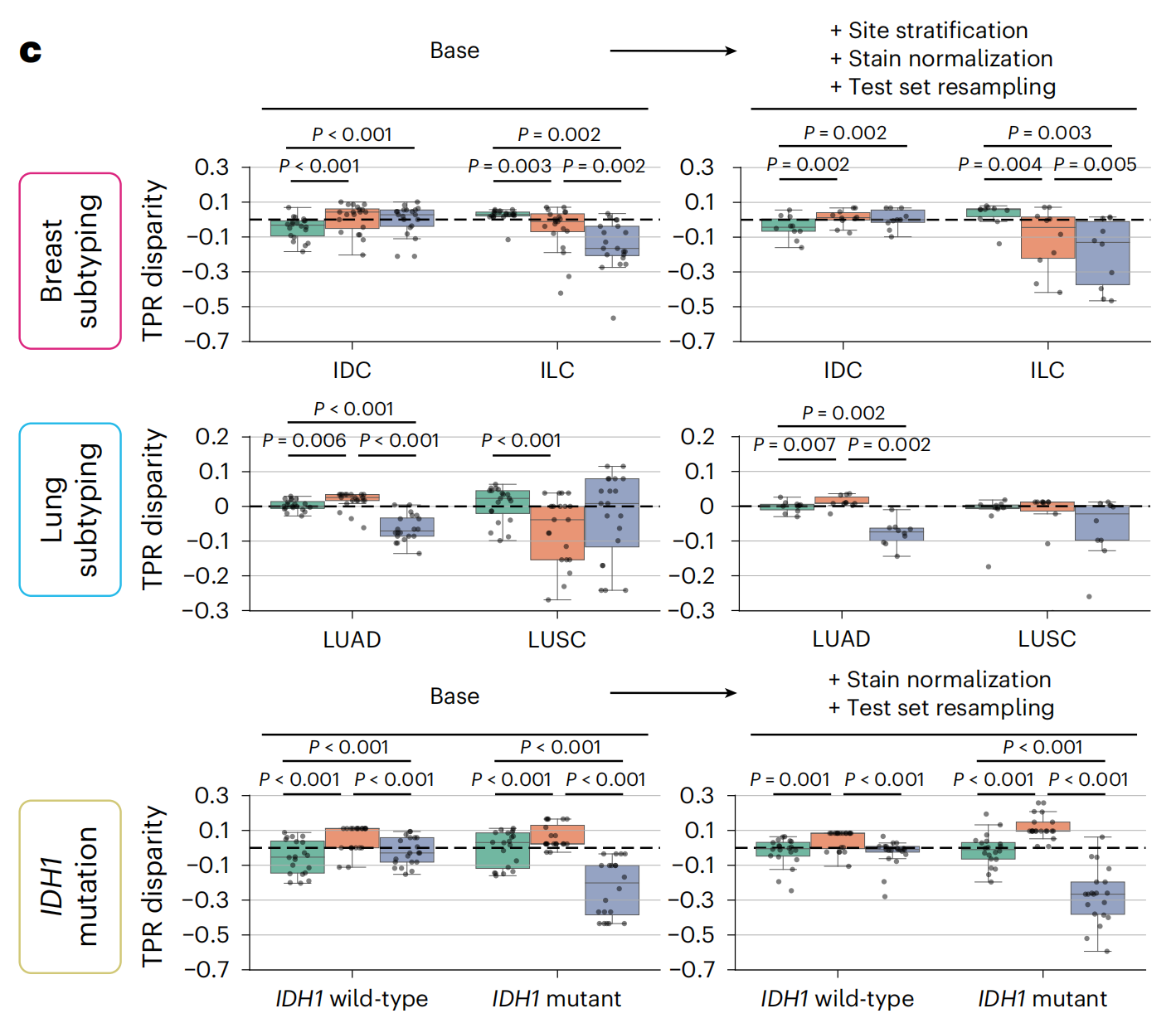
图中右侧的箱线图展示了在应用数据预处理和增强策略(如地点分层、染色标准化、测试集重采样)后,不同种族之间的TPR差异有所减少,表明这些策略有助于减少种族间的预测差异,提高模型的公平性。