最经典知识库问答数据集
知识库问答(KB-QA)是一种基于知识库的问答系统,它通过理解自然语言问题并从结构化的知识库中提取答案。这种系统能够处理简单到复杂的查询,包括单一事实和多跳推理问题。技术原理涉及知识表示、问题理解、答案生成等关键技术。应用领域广泛,包括搜索引擎、问答系统等,但也面临数据规模、多样性和推理能力等挑战。未来发展方向可能包括提升模型的可解释性、融合更多知识源以及构建更健壮的问答系统。
一、背景意义
知识库问答的背景意义在于其能够将非结构化自然语言问题转化为结构化查询,从而从知识库中检索出精确答案。这对于提升信息检索的准确性和效率至关重要,尤其是在需要处理大量数据和复杂查询的场景中。知识库问答系统的发展对于推动人工智能在自然语言处理领域的应用具有重要意义
二、技术原理
知识库问答的技术原理主要包括:
-
知识表示与存储:将知识以三元组形式存储在知识库中,便于计算机处理和理解。
-
问题理解和答案生成:通过自然语言处理技术理解问题意图,并从知识库中检索或生成答案。
-
知识融合与推理:结合不同来源的知识,进行复杂的推理和逻辑运算以回答复杂问题。
-
检索器与生成器:RAG模型中的两个主要模块,分别负责从知识库中检索相关信息和基于检索内容生成自然语言答案。
知识库问答(knowledge base question answering,KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。如下图所示
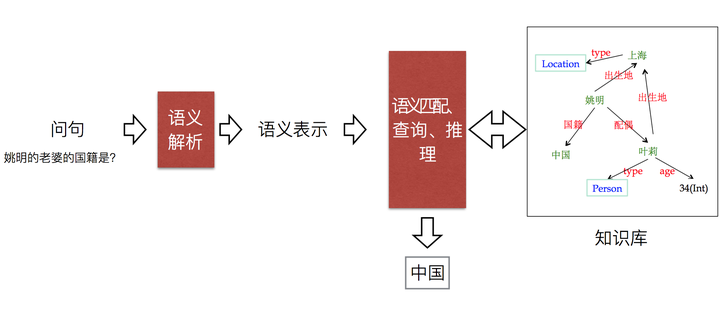
注:该图片来自中科院刘康老师在知识图谱与问答系统前沿技术研讨会中的报告
与对话系统、对话机器人的交互式对话不同,KB-QA具有以下特点:
-
答案:回答的答案是知识库中的实体或实体关系,或者no-answer(即该问题在KB中找不到答案),当然这里答案不一定唯一,比如 中国的城市有哪些 。而对话系统则回复的是自然语言句子,有时甚至需要考虑上下文语境。
-
评价标准:回召率 (Recall),精确率 (Precision) ,F1-Score。而对话系统的评价标准以人工评价为主,以及BLEU和Perplexity。
知识库问答的主流方法
关于KB-QA的方法,传统的主流方法可以分为三类:
-
语义解析(Semantic Parsing):该方法是一种偏linguistic的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似lambda-Caculus)在知识库中进行查询,从而得出答案。下图红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
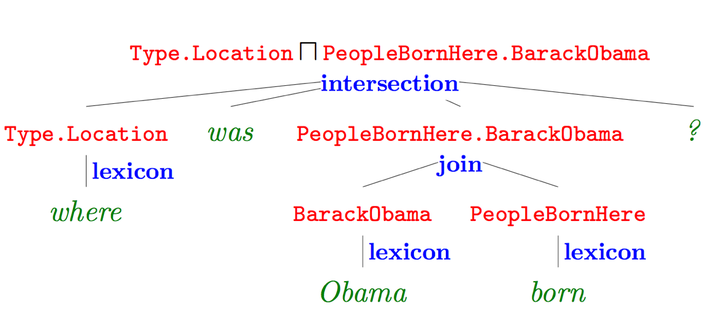
-
信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。信息抽取的代表论文Yao X, Van Durme B. Information Extraction over Structured Data: Question Answering with Freebase[C]//ACL (1). 2014: 956-966.
-
向量建模(Vector Modeling): 该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示。模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。
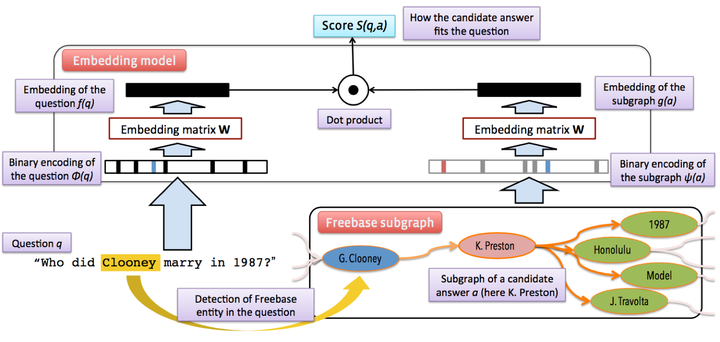
注:该图片来自论文Question answering with subgraph embeddings
三、应用和挑战
应用:
-
搜索引擎:提供更准确的搜索结果。
-
问答系统:直接回答用户的问题。
-
对话系统:在对话中提供信息支持。
挑战:
-
数据规模和多样性:现有数据集规模较小,问题多样性不足。
-
复杂推理能力:对于复杂问题,需要更强的推理和逻辑处理能力。
-
知识库的丰富性和覆盖度:知识库中知识的类型和覆盖度限制了问答系统的能力。
未来知识库问答的发展方向可能包括:
-
提升模型的可解释性,打破神经网络的黑盒特性。
-
结合神经网络与符号机器,提升复杂推理模型的解释能力。
-
融合更多类型的知识源,如文本、图像、音频等,以支持更实用和健壮的问答系统。
-
推动人工智能的边界,使KB-QA任务成为推动AI发展的重要领域。
像谷歌、微软和斯坦福大学这样的大机构,都在这方面做了不少研究,取得了不少成果。他们的努力不仅提升了系统的性能,还为整个行业树立了标准。这些技术的实际应用,不仅让用户的使用体验大大提升,还为企业带来了实实在在的经济效益。
接下来,我们来看看这些数据集都有哪些,它们又是如何为知识库问答系统的研究和应用提供灵感和支持的。这些数据集就像是一块块拼图,帮助我们拼出一个更完整、更智能的问答系统。
数据集:WebQuestions
-
发布时间:2015-07-04
-
数据集内容:WebQuestions是一个流行的数据集,用于基准测试QA引擎,特别是那些在结构化知识库上工作的引擎。该数据集通过为每个问题分配唯一ID并提供额外的注释来使其更加组织化和易于使用。此外,还提供了几个基于主题的分割。
-
数据集地址:WebQuestions QA Benchmarking Dataset|问答系统数据集|基准测试数据集
数据集:SQuAD
-
发布时间:2016-06
-
数据集内容:SQuAD(Stanford Question Answering Dataset)是一个用于机器阅读理解的数据集,包含超过10万个问题和对应的答案,这些问题和答案是从维基百科文章中提取的。数据集的目标是评估模型在给定一段文本的情况下回答问题的能力。
-
数据集地址:SQuAD
数据集:TriviaQA
-
发布时间:2017-05
-
数据集内容:TriviaQA是一个大规模的问答数据集,包含超过65万个问答对。数据集分为两个主要部分:一个是从网页和书籍中提取的证据文件,另一个是与这些证据相关的问题和答案。TriviaQA旨在测试机器阅读理解系统的能力,要求系统能够从长篇文档中提取信息并回答问题。
-
数据集地址:TriviaQA|自然语言处理数据集|机器学习数据集
数据集:HotpotQA
-
发布时间:2018-09
-
数据集内容:HotpotQA是一个问答数据集,旨在测试机器在多跳推理任务中的能力。数据集包含超过113,000个问题,这些问题需要从多个文档中提取信息并进行推理才能正确回答。
-
数据集地址:HotpotQA|问答系统数据集|自然语言处理数据集
数据集:Natural Questions
-
发布时间:2019-01
-
数据集内容:Natural Questions 是一个用于问答系统的数据集,包含从Google搜索查询中提取的真实问题。每个问题都附有长答案和短答案,以及相关的文档和段落。数据集旨在帮助开发和评估问答系统的性能。
-
数据集地址:Natural Questions|问答系统数据集|搜索引擎优化数据集
数据集:CoQA
-
发布时间:2018-10
-
数据集内容:CoQA(Conversational Question Answering)是一个用于对话式问答任务的数据集,包含8000多个对话,每个对话平均有15轮。数据集涵盖了多种文本类型,包括新闻文章、文学作品、科学文章等。CoQA旨在评估模型在对话环境中理解和回答问题的能力。
-
数据集地址:CoQA|对话问答数据集|多领域数据集
数据集:QuAC
-
发布时间:2018-05
-
数据集内容:QuAC(Question Answering in Context)是一个用于上下文问答的数据集,旨在模拟真实世界中的对话式问答场景。数据集包含对话历史和问题,要求模型在给定的上下文中生成答案。
-
数据集地址:QuAC
数据集:RACE
-
发布时间:2017-08
-
数据集内容:RACE数据集是一个用于评估阅读理解能力的大型数据集,包含从中国中学生英语考试中提取的阅读理解问题。数据集分为两个难度级别:初中(RACE-M)和高中(RACE-H)。每个问题都包含一篇短文和多个选择题,要求模型根据短文内容选择正确答案。
-
数据集地址:RACE|代码生成数据集|代码质量评估数据集
数据集:NewsQA
-
发布时间:2016-11
-
数据集内容:NewsQA是一个用于机器阅读理解的数据集,包含来自CNN的新闻文章和与之对应的人工生成的问题和答案。该数据集旨在测试模型在理解复杂文本并回答相关问题方面的能力。
-
数据集地址:NewsQA|机器阅读理解数据集|众包数据集数据集
数据集:DuReader
-
发布时间:2017-11
-
数据集内容:DuReader是一个大规模的中文阅读理解数据集,包含超过20万个真实的中文问题和对应的答案。数据集涵盖了多种类型的文档,包括新闻、网页、百科等,旨在评估模型在中文阅读理解任务中的表现。
-
数据集地址:DuReader|机器阅读理解数据集|中文信息处理数据集
数据集:BoolQ
-
发布时间:2019-02
-
数据集内容:BoolQ是一个用于自然语言推理的数据集,包含约159,000个真实世界的问题和对应的二元答案(是或否)。这些问题是从Google搜索查询中提取的,旨在评估模型在理解自然语言问题并判断其真假的能力。
-
数据集地址:BoolQ
数据集:DROP
-
发布时间:2019-05
-
数据集内容:DROP(Discourse-Oriented Reading Comprehension Dataset)是一个用于阅读理解任务的数据集,特别关注于基于文本的数学问题和推理。该数据集包含超过9万个问题和答案对,旨在测试模型在处理复杂文本和数学推理方面的能力。
-
数据集地址:DROP|阅读理解数据集|人工智能数据集
数据集:QASC
-
发布时间:2020-05
-
数据集内容:QASC是一个用于科学问答的数据集,包含8139个问题,每个问题都由两个事实和一个推理步骤组成。数据集旨在测试系统在科学领域中的知识整合和推理能力。
-
数据集地址:QASC|多跳问答数据集|科学教育数据集
数据集:CommonsenseQA
-
发布时间:2019-02
-
数据集内容:CommonsenseQA是一个用于常识问答的数据集,包含超过12000个问题,这些问题需要常识推理来回答。每个问题都有五个候选答案,其中只有一个正确答案。数据集旨在评估模型在常识推理方面的能力。
-
数据集地址:CommonsenseQA|常识推理数据集|自然语言处理数据集
数据集:OpenBookQA
-
发布时间:2018-09
-
数据集内容:OpenBookQA是一个用于科学问答的数据集,包含超过6000个多项选择题。每个问题都附有四个选项,其中一个是正确答案。数据集还包括一个“开放书”,即一组科学事实,可以用来帮助回答问题。
-
数据集地址:OpenBookQA|教育评估数据集|人工智能问答数据集
数据集:ARC
-
发布时间:2018-05
-
数据集内容:ARC(AI2 Reasoning Challenge)数据集是一个用于评估机器推理能力的挑战性数据集。它包含了来自小学科学考试的多项选择题,涵盖了科学、历史、地理等多个领域。数据集分为两个部分:ARC-Easy和ARC-Challenge,前者包含较简单的题目,后者包含更具挑战性的题目。
-
数据集地址:ARC
数据集:MultiRC
-
发布时间:2018-05
-
数据集内容:MultiRC是一个用于多选阅读理解任务的数据集,包含多个段落和相关问题,每个问题可能有多个正确答案。数据集旨在评估模型在复杂文本理解中的表现。
-
数据集地址:MultiRC
数据集:SocialIQA
-
发布时间:2019-05
-
数据集内容:SocialIQA是一个用于社会智能推理的数据集,包含超过14000个关于社交情境的多选题。每个问题都涉及一个情境、一个相关的问题和三个可能的答案。数据集旨在测试模型理解和推理社交情境的能力。
-
数据集地址:SocialIQA
数据集:CosmosQA
-
发布时间:2019-09
-
数据集内容:CosmosQA是一个用于阅读理解任务的数据集,包含超过30万个问题和答案对。该数据集主要用于评估模型在理解复杂文本和生成合理答案方面的能力。
-
数据集地址:CosmosQA|自然语言处理数据集|常识推理数据集