假设检验简介
一、介绍
许多问题需要我们决定是接受还是拒绝某个参数。该陈述通常称为假设,有关假设的决策过程称为假设检验。这是统计推断最有用的概念之一,因为许多类型的决策问题都可以表述为假设检验问题。
如果工程师必须根据样本数据决定某种轮胎的真实平均寿命是否至少为 42,000 英里,或者农艺师是否必须根据实验决定一种肥料是否比另一种肥料产生更高的大豆产量,以及药品制造商是否必须根据样本决定所有接受新药的患者中的 90% 是否会从无论是否患有某种疾病,所有这些问题都可以转化为假设的统计检验的语言。
在第一种情况下,我们可以说工程师必须检验指数总体的参数 θ 至少为 42,000 的假设,而在第二种情况下,我们可以说农艺师必须决定是否μ1>μ2,其中 μ1和 μ2是两个正常总体的均值,在第三种情况下,我们可以说制造商必须决定二项式总体的参数 θ 是否等于 0.90。当然,在每种情况下,都必须假设所选分布正确地描述了实验条件;也就是说,分布提供了正确的统计模型。
二、关键要点
- 假设检验用于通过使用样本数据来评估假设的合理性。
- 根据数据,该检验提供了有关假设合理性的证据。
- 统计分析师通过测量和检查所分析总体的随机样本来检验假设。
- 假设检验的四个步骤包括陈述假设、制定分析计划、分析样本数据和分析结果。
本文作为 Data Science Blogathon 的一部分发布。
三、什么是假设检验?
假设检验是一种统计方法,用于使用实验数据做出统计决策。假设检验基本上是我们对总体参数所做的假设。它评估有关群体的两个互斥的语句,以确定样本数据最支持哪个语句。
3.1 假设检验的工作原理
在假设检验中,分析人员检验统计样本,旨在提供证据证明原假设的合理性。统计分析师测量和检查所分析的总体的随机样本。所有分析师都使用随机总体样本来检验两个不同的假设:原假设和备择假设。
原假设通常是总体参数之间相等的假设;例如,原假设可能声明总体平均回报率等于零。备择假设实际上与零假设相反。因此,它们是互斥的,只有一个可以是 true。但是,这两个假设中的一个将永远是正确的。
假设我们想证明一种矿石的铀含量百分比高于另一种矿石,我们可能会提出两个百分比相同的假设;如果我们想证明一种产品的质量变化比另一种产品的质量变化更大,我们可以提出没有差异的假设;也就是说,σ1= σ2.鉴于“无差异”的假设,诸如此类的假设导致了术语零假设。从符号上讲,我们将使用符号 H0对于我们要检验的原假设和 H1或 H一个对于替代假设。
3.2 四步流程
- 陈述假设。
- 制定分析计划,其中概述了如何评估数据。
- 执行计划并分析样本数据。
- 分析结果并拒绝原假设,或者声明给定数据原假设是合理的。
四、假设检验示例
如果一个人想检验一分钱正好有 50% 的机会正面朝上,原假设是 50% 是正确的,而备选假设是 50% 是不正确的。在数学上,原假设表示为 Ho:P = 0.5。备择假设显示为 “Ha”,与原假设相同,只是等号划线划线,这意味着它不等于 50%。
随机抽取 100 次抛硬币,并检验原假设。如果发现 100 次抛硬币分布为 40 次正面和 60 次反面,分析师将假设一分钱没有 50% 的机会正面朝上,并将拒绝零假设并接受备择假设。
如果有 48 个正面和 52 个反面,那么硬币可能是公平的并且仍然产生这样的结果是合理的。在这样的情况下,原假设被“接受”,分析师指出预期结果(50 个正面和 50 个反面)与观察到的结果(48 个正面和 52 个反面)之间的差异“仅凭偶然性就可以解释”。
五、假设检验是什么时候开始的?
一些统计学家将第一个假设检验归因于讽刺作家约翰·阿布斯诺特 (John Arbuthnot) 在 1710 年,他在观察到几乎每年男性出生率都略高于女性出生率后,研究了英格兰的男性和女性出生率。阿巴斯诺特计算出这种情况偶然发生的概率很小,因此这是由于“上帝的旨意”。
六、假设检验有什么好处?
假设检验通过根据数据测试新想法或理论来帮助评估新想法或理论的准确性。这使研究人员能够确定证据是否支持他们的假设,从而有助于避免虚假的声明和结论。假设检验还提供了一个基于数据而不是个人意见或偏见的决策框架。通过依靠统计分析,假设检验有助于减少机会和混杂变量的影响,为得出明智的结论提供了一个强大的框架。
七、假设检验的局限性是什么?
假设检验完全依赖于数据,不能提供对所研究主题的全面理解。此外,结果的准确性取决于可用数据的质量和所使用的统计方法。不准确的数据或不适当的假设表述可能会导致错误的结论或失败的检验。假设检验还可能导致错误,例如分析师在不应该接受或拒绝原假设的情况下接受或拒绝原假设。这些错误可能会导致错误的结论或错失识别数据中的重要模式或关系的机会
八、关于 P – 值
8.1 什么是 P 值?
p 值或概率值是假设检验中使用的一种统计度量,用于评估反对零假设的证据强度。它表示在假设原假设为真的情况下,获得与观测结果一样极端或更极端的结果的概率。
8.2 P 值是如何计算的?
计算 p 值通常涉及以下步骤:
- 制定原假设 (H0):清楚地陈述原假设,该假设通常指出变量之间没有显著关系或影响。
- 选择备择假设 (H1):定义备择假设,该假设提出变量之间存在显著关系或影响。
- 确定检验统计量:计算检验统计量,该统计量是观测数据与原假设下预期值之间差异的度量。检验统计量的选择取决于数据类型和具体的研究问题。
- 确定检验统计量的分布:确定原假设下检验统计量的适当抽样分布。如果原假设为 true,则此分布表示检验统计量的预期值。
- 计算临界值:根据观测到的检验统计量和抽样分布,找到获得观察到的检验统计量或更极端的检验统计量的概率(假设原假设为真)。
在我们收集或查看我们选择的任何数据之前,将我们的显著性水平设置为 ∝ 取决于各种错误的后果。
九、假设检验中的 P 值
下表显示了 p 值的重要性,并显示了假设检验期间发生的各种错误。
| 真相 /决定 | 接受 h0 | 拒绝 h0 |
| h0 -> true | 基于 给定 p 值 (1-α) 的正确决策 | I 类错误 (α) |
| h0 -> false | II 类错误 (β) | 基于 给定 p 值 (1-β) 的决策错误 |
I 类错误: 错误地否定了原假设。它用 α(显著性水平)表示。
类型 II 错误:不正确地接受原假设。它由 β (功率级别) 表示
十、如何解释 p 值?
要解释 p 值,您需要将其与选定的显著性水平进行比较。在假设检验期间,我们假设显著性水平 (α),通常为 5% (α = 0.05)。它是当原假设为真时拒绝原假设的概率。据观察,p 值越低,否定原假设的概率就越高。什么时候:
- p ≤ (α = 0.05):否定原假设。有足够的证据得出结论,观察到的效果或关系在统计上是显著的,这意味着它不太可能仅仅是偶然发生的。
- p > (α = 0.05):拒绝备择假设(或接受原假设)。观察到的效应或关系没有提供足够的证据来否定原假设。这并不一定意味着没有效果;它只是意味着样本数据没有提供足够有力的证据来排除这种影响是由于偶然性的可能性。
如果未指定显著性水平,请在解释结果时考虑以下一般推论。
- 如果 p > .10:不显著
- 如果 p ≤ .10:略微显著
- 如果 p ≤ .05:显著
- 如果 p ≤ .001:高度显著
从图形上看,p 值位于任何置信区间的尾部。
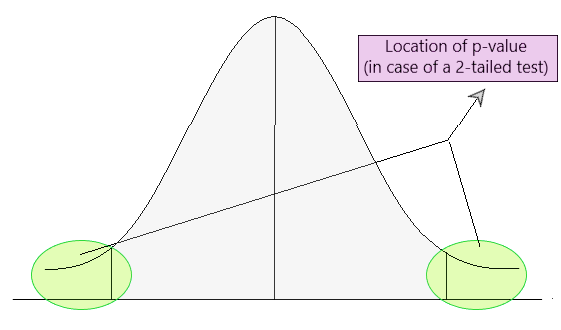
10.1 P 值的显著性
- p 值提供了反对原假设的证据强度的定量度量。
- 假设检验中的决策
- P 值用作解释统计检验结果的指南。较小的 p 值表明观察到的效果或关系在统计上显著,但并不一定意味着它具有实际或临床意义。
10.2 p 值的应用
- 在正向传播和向后传播期间: 拟合模型(例如多元线性回归模型)时,我们使用 p 值来查找对预测输出有重要贡献的最重要变量。
- 各种药物的作用: 它在医学研究领域被广泛用于确定任何药物的成分是否会对人类产生预期的效果。P 值是假设检验中使用的非常强大的统计工具。它在做出重要决策时提供了大量有价值的信息,例如做出商业智能推断或确定是否应该将药物用于人类等。如有任何疑问/疑问,请在下面评论。
10.3 I 类和 II 类错误:

获得类型 I 错误的概率是显著性水平,因为如果我们的原假设为真,则假设我们的显著性水平为 5%。嗯,5% 的情况下,即使我们的原假设是正确的,我们也会得到一个统计数据,让你拒绝原假设。因此,考虑 I 类错误概率的一种方法是我们的显著性水平。
类型 I 错误:拒绝原假设 H0,即使它是真的。因为假设原假设为真,不太可能获得这样的统计数据,所以我们决定拒绝原假设。
10.4 功率
这是当原假设不为真时您做正确事情的概率,即如果原假设不为真,我们应该拒绝原假设。
因此,幂 = P(拒绝 H0 |H0 为 false)
= 1- P(不排斥 H0 |H0 为 false)—>这称为 II 类错误
= P( 不犯 II 类错误 )
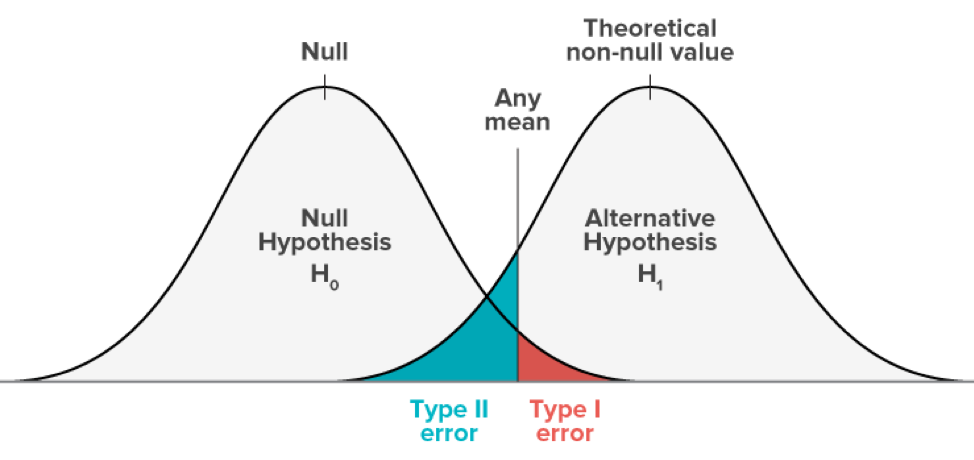
示例:设 H0:μ = μ1
公顷:μ ≠ μ1
注意:
1. 如果我们增加 ∝( 显著性水平 ),功率会增加,即 ∝⇧ —> 功率 ⇧
但它也会增加 I 型错误,即 P(I 型错误) ⇧
2. 如果我们增加 n(样本量),功效会增加,即 n ⇧ —> 功效 ⇧
一般来说,这总是一件好事。增加n会导致曲线变窄,而两条曲线之间的重叠会减少.3.数据集中较小的可变性(即 σ2 或 σ)也使采样分布更窄,因此它增加了功效。如果 true 参数比 null 假设所说的更远,则功效增加。
10.5 . 错误概率和∝ :
1. I 类错误是指我们拒绝一个真正的零假设。较低的 ∝ 值会使否定原假设变得更加困难,因此选择较低的值∝可以降低类型 I 误差的概率。这里的结果是,如果原假设为 false,则可能很难使用较低的值∝拒绝。因此,使用较低的值∝会增加类型 II 错误的可能性。
2. II 类错误是指我们未能拒绝假零假设。∝值越高,越容易否定原假设,因此选择较高的值∝可以降低类型 II 误差的概率。这里的结果是,如果原假设为真,则增加 ∝ 会使我们更有可能犯下 I 类错误(拒绝真原假设)。
十一、总结
假设检验可以使用以下步骤进行总结:
1. 制定 H0 和 H1,并指定 α。
2. 使用适当检验统计量的抽样分布,确定大小为 α 的关键区域。
3. 从样本数据中确定检验统计量的值。
4. 检查检验统计量的值是否落入临界区域,并相应地拒绝原假设或保留判断。(请注意,我们不接受原假设,因为 β(错误接受的概率)未在显著性检验中指定。