文章目录
- AI大模型开发工程师
- 003 GPT大模型API实战
- 1 Completion API和Chat Completion API
- 学习OpenAI API的意义
- Completion API和Chat Completion API
- 代码实践
- 2 Chat Completion API详细参数
- messages可以包含多条信息
- messages角色设定
- message之Few-shot效果演示
- message之Zero-shot-CoT效果演示
- message之实现简易知识库
- 借助本地知识库实现简易版多轮对话机器人
- 3 Function Calling 函数调用
- Function Calling 运行流程
- Function Calling详细流程剖析
- Function Calling函数封装
- 定义自动输出function参数的函数
- 封装调用2轮response的函数
- 4 ChatGPT Plugin实践
- ChatGPT Plugin Store
- 智能TODO(代办)管理助手需求分析
- 上线Plugin的流程
- ChatGPT Plugin Vs Function Calling
AI大模型开发工程师
003 GPT大模型API实战
1 Completion API和Chat Completion API
学习OpenAI API的意义
- OpenAI定义了大模型标准
- OpenAI API的功能最全
Completion API和Chat Completion API
- Chat模型核心功能是对话能力,Completion模型本质是文本补齐模型,核心功能为根据提示(Prompt)进行提示语句的补全(即继续进行后续文本创作)
- 从模型发展顺序上来看,Chat模型是Completion模型的升级版模型。
- Chat模型的核心优势:理解人类意图的能力。理解人类意图带来的更低的交互门槛,同样也会为开发者带来巨大的便利。据OpenAI官网数据,自gpt-3.5 API发布以来,约97%的开发者更偏向于使用Chat模型API进行开发。
代码实践
completion = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "user", "content": "你好!请介绍一下你自己"}]
)
print(completion)
completion.choices[0].message.content
stream = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "user", "content": "你好!请介绍一下你自己"}],stream=True,
)
for chunk in stream:if chunk.choices[0].delta.content is not None:print(chunk.choices[0].delta.content, end="")
- 大模型交互方式3(对于执行结果进行处理的时候方便)
response = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "user", "content": "中国的首都是?"}]
)
print(response.choices[0].message.content)
2 Chat Completion API详细参数
- https://platform.openai.com/docs/api-reference/chat/create?lang=python
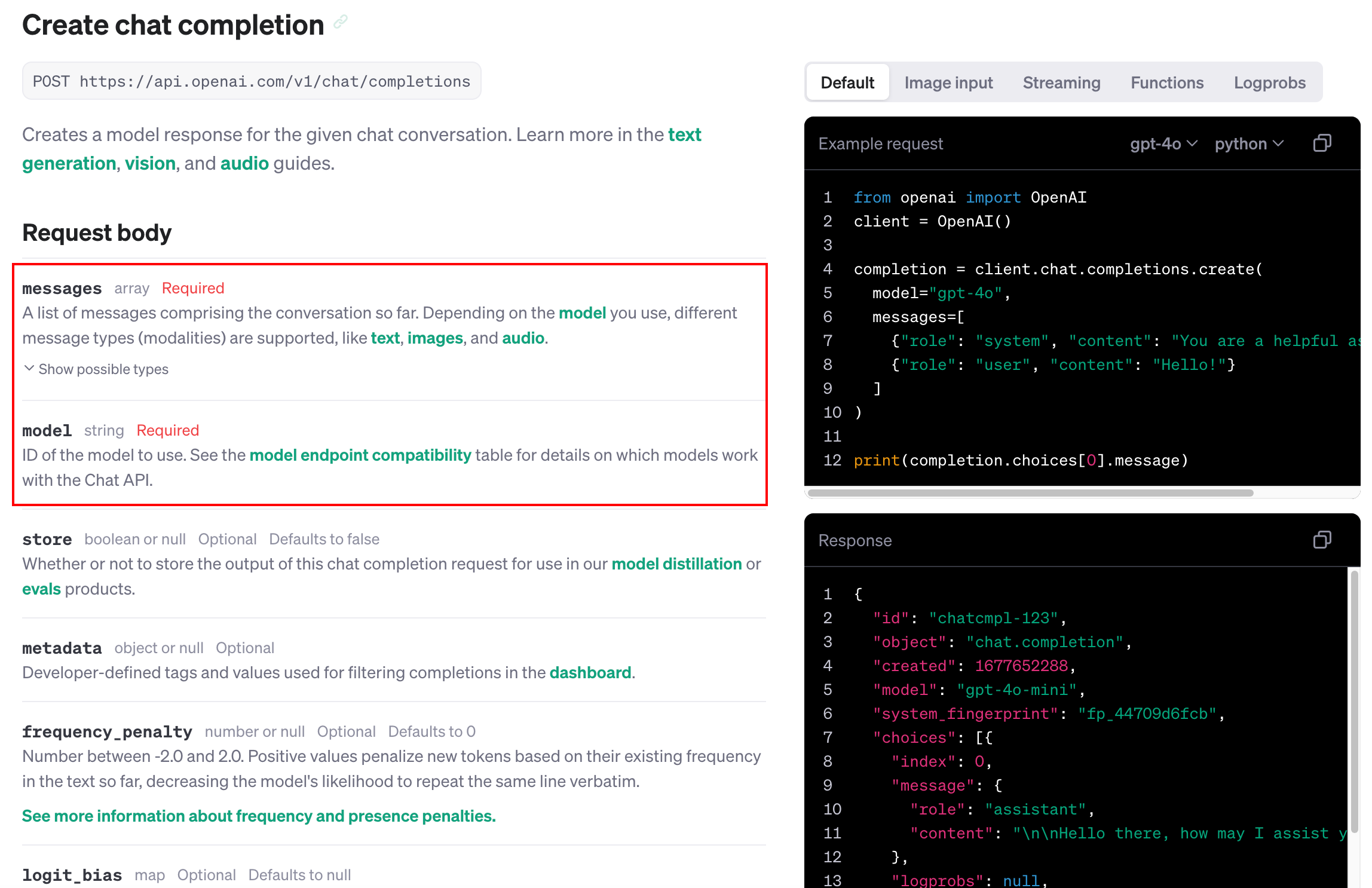
- model:必选参数,大模型的名称
- messages:必选参数,提示词;(里面可以指定角色)
- max_tokens:可选参数,代表返回结果的token数量;
- temperature:可选参数,取值范围为0-2,默认值为1。参数代表采样温度,数值越小,则模型会倾向于选择概率较高的词汇,生成的文本会更加保守;而当temperature值较高时,模型会更多地选择概率较低的词汇,生成的文本会更加多样;
- top_p:可选参数,取值范围为0-1,默认值为1,和temperature作用类似,用于控制输出文本的随机性,数值越趋近与1,输出文本随机性越强,越趋近于0文本随机性越弱;通常来说若要调节文本随机性,top_p和temperature两个参数选择一个进行调整即可;这里更推荐使用temperature参数进行文本随机性调整;
- n:可选参数,默认值为1,表示一个提示返回几个Completion;
- stream:可选参数,默认值为False,表示回复响应的方式,当为False时,模型会等待返回结果全部生成后一次性返回全部结果,而为True时,则会逐个字进行返回;
- logprobs:可选参数,默认为null,该参数用于指定模型返回前N个概率最高的token及其对数概率。例如,如果logprobs设为10,那么对于生成的每个token,API会返回模型预测的前10个token及其对数概率;
- stop:可选参数,默认为null,该参数接受一个或多个字符串,用于指定生成文本的停止信号。当模型生成的文本遇到这些字符串中的任何一个时,会立即停止生成。这可以用来控制模型的输出长度或格式;
- presence_penalty:可选参数,默认为0,取值范围为[-2, 2],该参数用于调整模型生成新内容(例如新的概念或主题)的倾向性。较高的值会使模型更倾向于生成新内容,而较低的值则会使模型更倾向于坚持已有的内容,当返回结果篇幅较大并且存在前后主题重复时,可以提高该参数的取值;
- frequency_penalty:可选参数,默认为0,取值范围为[-2, 2],该参数用于调整模型重复自身的倾向性。较高的值会使模型更倾向于避免重复,而较低的值则会使模型更可能重复自身;当返回结果篇幅较大并且存在前后语言重复时,可以提高该参数的取值;
- logit_bias:该参数接受一个字典,用于调整特定token的概率。字典的键是token的ID,值是应用于该token的对数概率的偏置;在GPT中我们可以使用tokenizer tool查看文本Token的标记。一般不建议修改;
- tools:可以调用的函数;
- tool_choice:调用函数的策略;
- 废弃的参数 functions:可以调用的函数;
- 废弃的参数 function_call:调用函数的策略。
messages可以包含多条信息
- messages可以包含多条信息,但模型只会对于最后一条用户信息进行回答

messages角色设定
- role:assistant消息和user消息是一一对应的,system:全局角色设置