GPU 学习笔记四:GPU多卡通信(基于nccl和hccl)
文章目录
- 一、前沿
- 1.1 背景回顾
- 1.2 XCCL在AI通信架构中的位置和作用
- 二、英伟达GPU通信 nccl
- 2.1 NCCL简介
- 2.2 通信模式
- 2.3 NCCL算法与逻辑拓扑结构
防止遗忘和后续翻找的麻烦,记录下平时学到和用到的GPU知识,较为琐碎,不考虑连贯性和严谨性,如有欠妥的地方,欢迎指正。
GPU 学习笔记一:从A100与910B分析中,学习GPU参数的意义。
GPU 学习笔记二:GPU单机多卡组网和拓扑结构分析(基于A100的单机多卡拓扑结构分析)
GPU 学习笔记三:GPU多机多卡组网和拓扑结构分析(基于数据中心分析)
GPU 学习笔记四:GPU多卡通信(基于nccl和hccl)
GPU 学习笔记五:大模型分布式训练实例(基于PyTorch和Deepspeed)
GPU 学习笔记六:NVIDIA GPU架构分析(基于技术演进时间线,持续更新)
GPU 学习笔记七:华为 NPU架构分析(基于技术演进时间线,持续更新)
GPU 学习笔记八:GPU参数对比统计表(记录GPU参数,持续更新)
一、前沿
1.1 背景回顾
在前面几章中,记录了多机多卡的网络物理拓扑结构,这篇文章将基于上述拓扑结构,详细介绍GPU通信模式。
防止忘记,再来回顾一下。
1)数据中心网络拓扑:
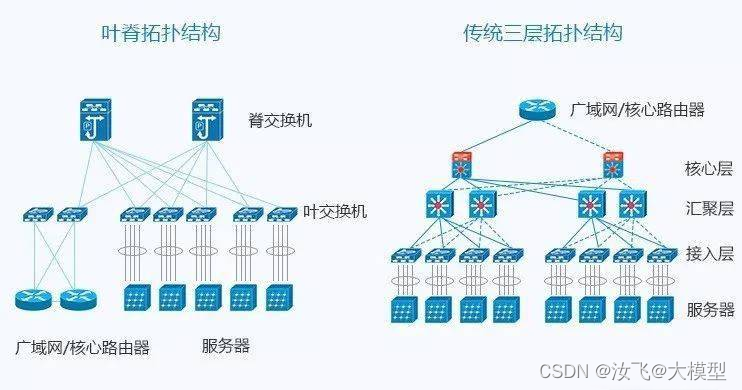
2)英伟达多机多卡拓扑:
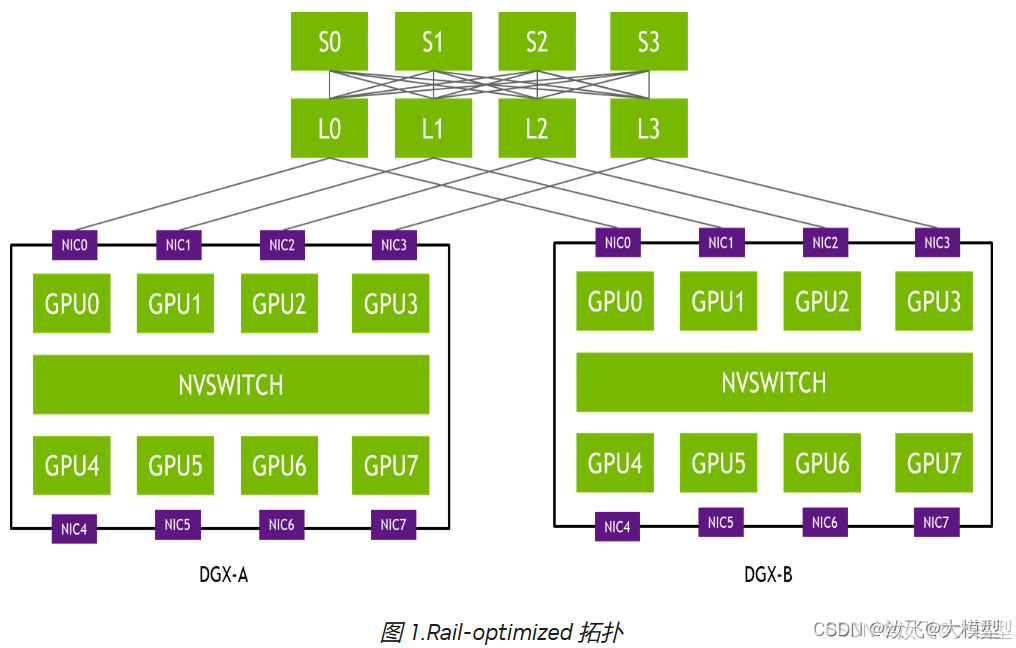
3)英伟达单机多卡拓扑:
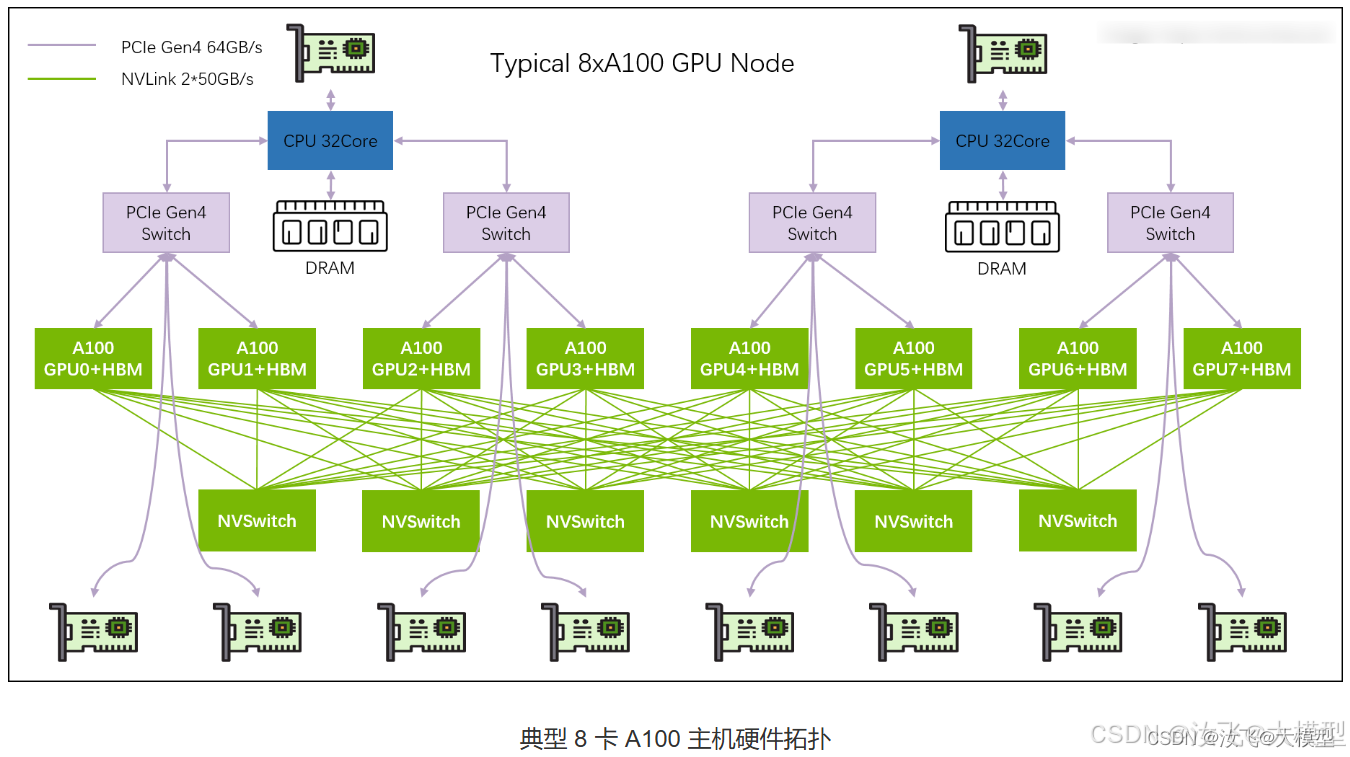
4)GPU跨机通信模式:
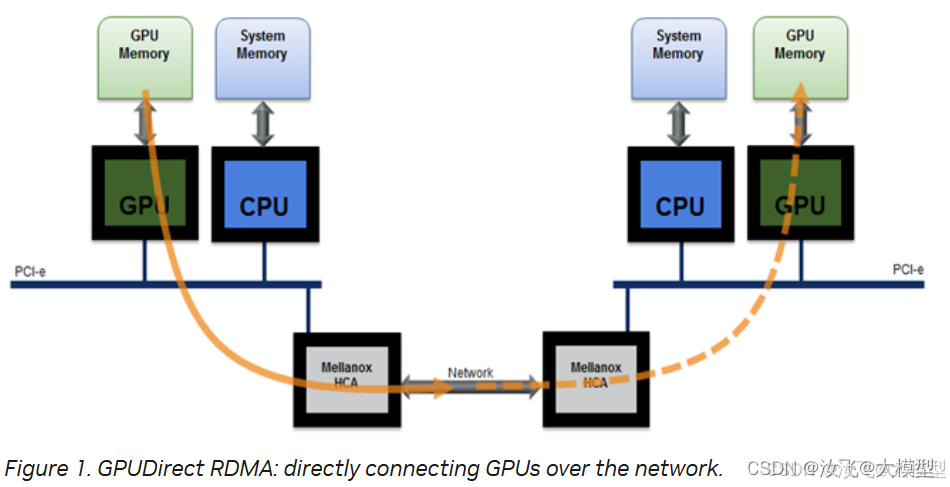
1.2 XCCL在AI通信架构中的位置和作用
XCCL:X产品的集合通信库,包括英伟达的nccl、华为的hccl等,是面向GPU通信的专用高性能通信库,遵循MPI协议,同时也做了一些个性化设置。
XCCL位置图:
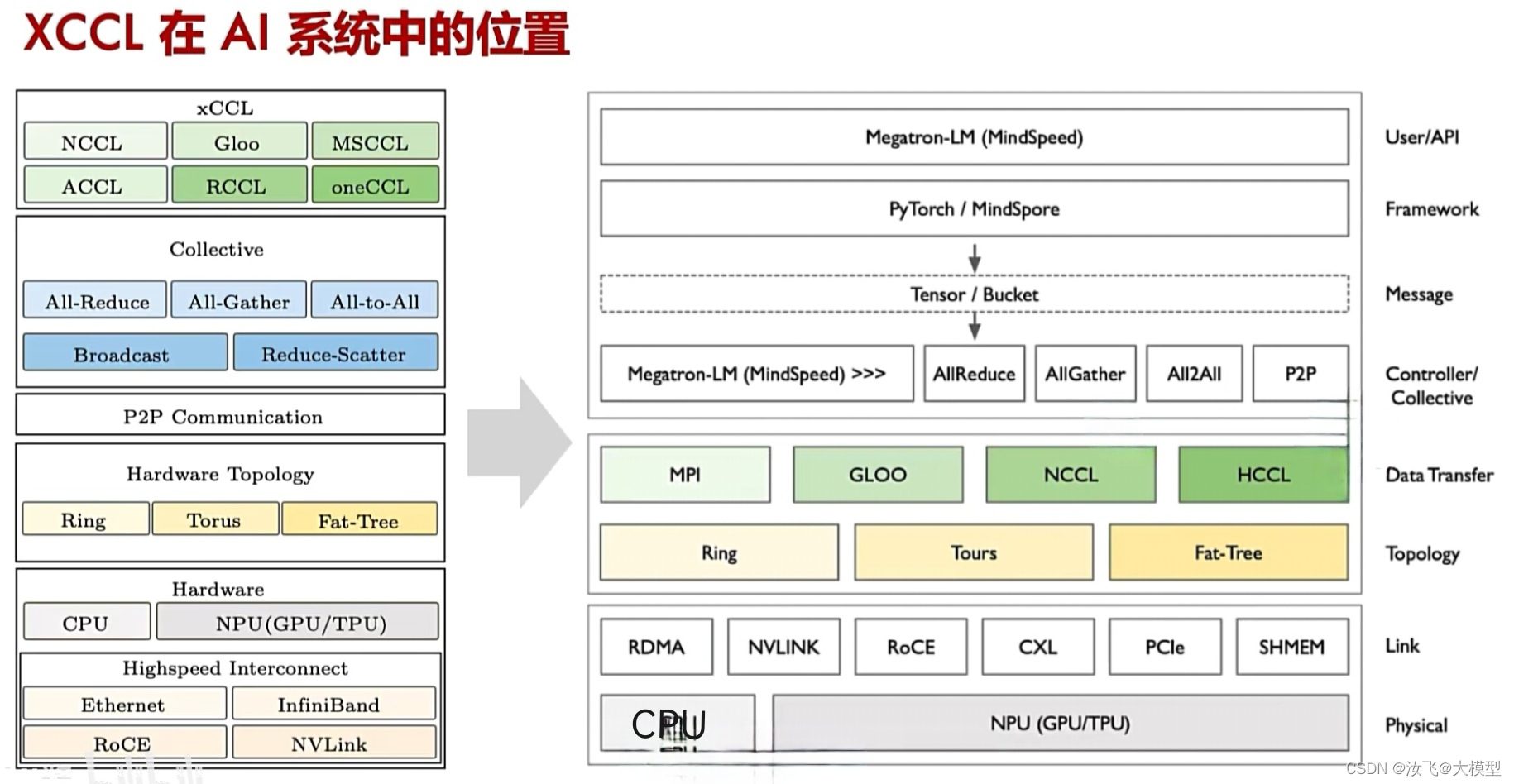
二、英伟达GPU通信 nccl
2.1 NCCL简介
NCCL文档索引
1)NCCL介绍
NCCL,全称“NVIDIA Collective Communication Linrary”,英伟达集合通信库,发音为“Nickel”。
NCCL是专门用于加速GPU间通讯的高性能通信库,用来加速多机多卡间的并行计算速度,提升通信和数据传输性能。
NCCL具有拓扑感知的能力,可以自动感知数据中心的扑结结构,通过优化通信模式来最大化的减少通信延迟和带宽损耗。
NCCL提供了丰富的原语,可基于linux系统直接运行,可以轻松的集成到应用程序中。
官网提供了两种下载方式,一种是作为NVIDIA NPC SDK的一部分下载,另一种是作为ubuntu、redhat等linux系统的单独软件包下载,目前不支持windows平台。
2)NCCL架构设计:
NCCL对上提供了丰富的API,供上层框架调用。如:Caffe2、Chainer、MxNet、Pytorch、Tensorflow、Deepspeed等领先的深度学习框架都已经集成了NCCL,用来加速多GPU多节点上的模型训练和推理。
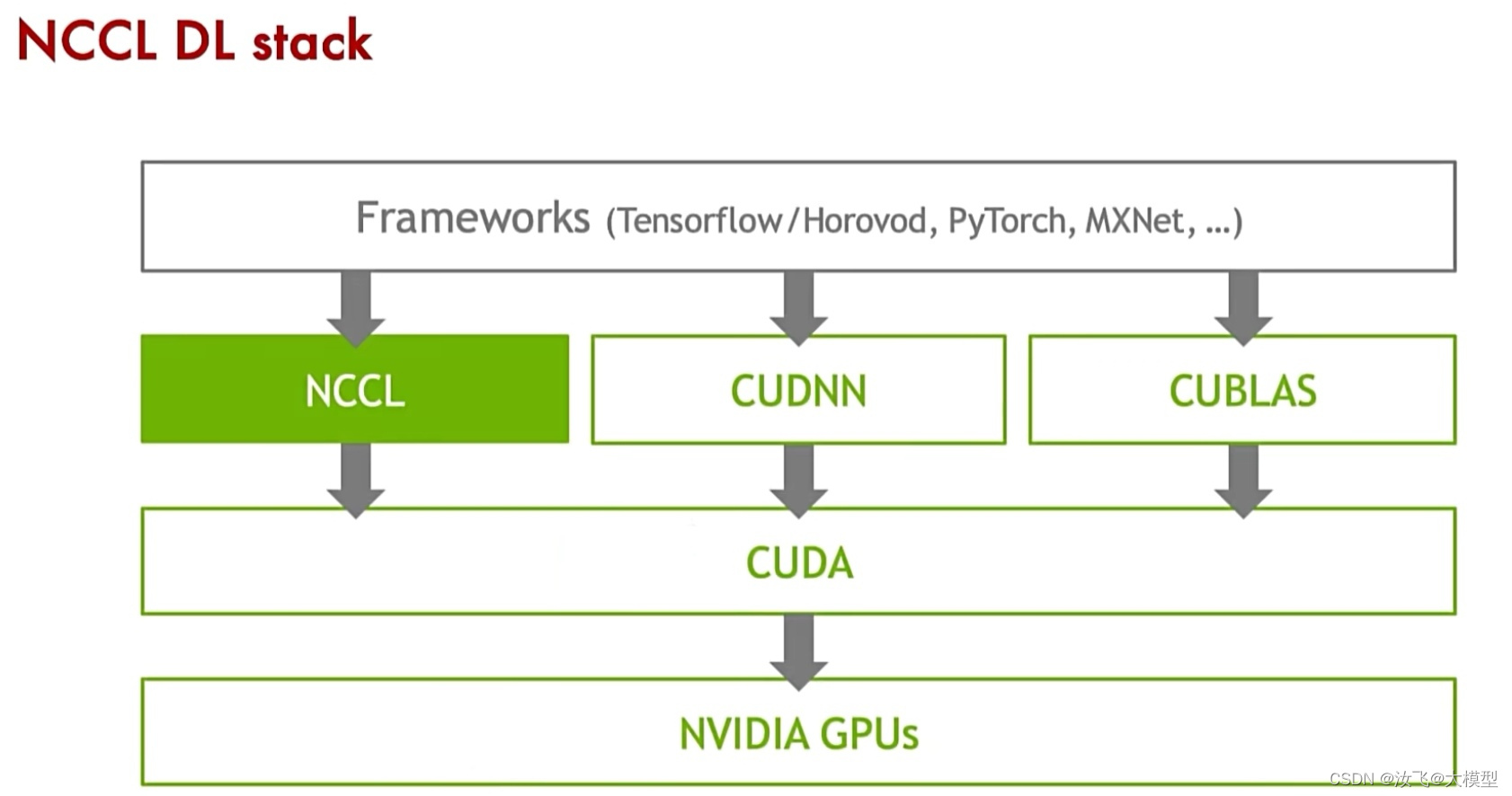
NCCL对下操作cuda,进行内存操作、内核调用、并行计算等。
它的API继承了MPI协议,但是没有像MPI那样提供进程启动器和管理器的并行环境,因此,NCCL依赖应用程序的进程管理系统和GPU端通信系统,来实现自己引导程序。与MPI另一个不同之处在于,NCCL采用了“stream”参数,该参数可以与cuda编程模型直接集成。
与MPI和其他针对性能优化的库类似,NCCL不提供安全网络通信机制,用户需要确保NCCL在安全的网络中运行。
2.2 通信模式
NCCL开发文档
在一个具有n个CUDA设备(GPU)的网络中,每个CUDA设备都会被分配一个介于0到n-1之间的唯一rank。
1)通信模式分类
NCCL提供了broadcast、scatter、gather、all-gather、reduce、all-reduce、reduce-scatter以及点对点通信的发送/接受原语。
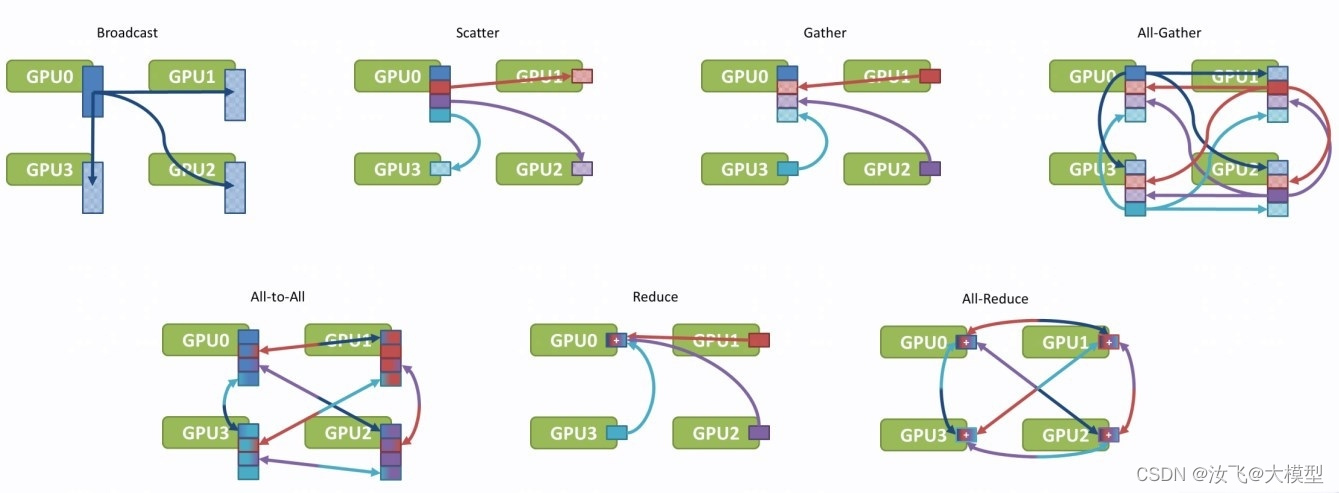
通信模式:集体通信和点对点通信。
-
集体通信
必须为每个rank(cuda设备)都执行相同的集合操作,使用相同的数据类型和计数,以形成一个完整的集体操作。否则,将会出现未知错误,比如挂起、数据损坏和崩溃等。集体通信模式:broadcast、all-gather、reduce、all-reduce、reduce-scatter。
-
点对点通信
自NCCL2.7起,点对点通信可在ranks之间发送任意通信模式。任何点对点通信都需要两个NCCL调用:在一个rank上调用ncclSend(),另一个rank上调用对应的ncclRecv(),以此来发送和接受相同计数和数据类型的数据报文。针对不同GPU对端多次ncclSend()和ncclRecv()的调用,可以融合在一起,使用ncclGroupStart()和ncclGroupEnd()将复杂的通信模式整合在一个通信Group内。
点对点通信模式:scatter(one-to-all)、gather(all-to-one)、all-to-all或者n维空间的neighbors通信。
Group内的点对点接口调用会阻塞,直到组内的普通calls执行完成。Group内的calls是独立运行的,不会相互阻塞,所以,将需要并发运行的calls进行合并,可以避免死锁。
2)通信模式分析
以下表示中,
K表示rank数量,N表示数组大小。
-
broadcast
该操作将A元素,从指定缓冲区(通常为root rank缓冲区)复制到所有指定的rank的缓冲区。
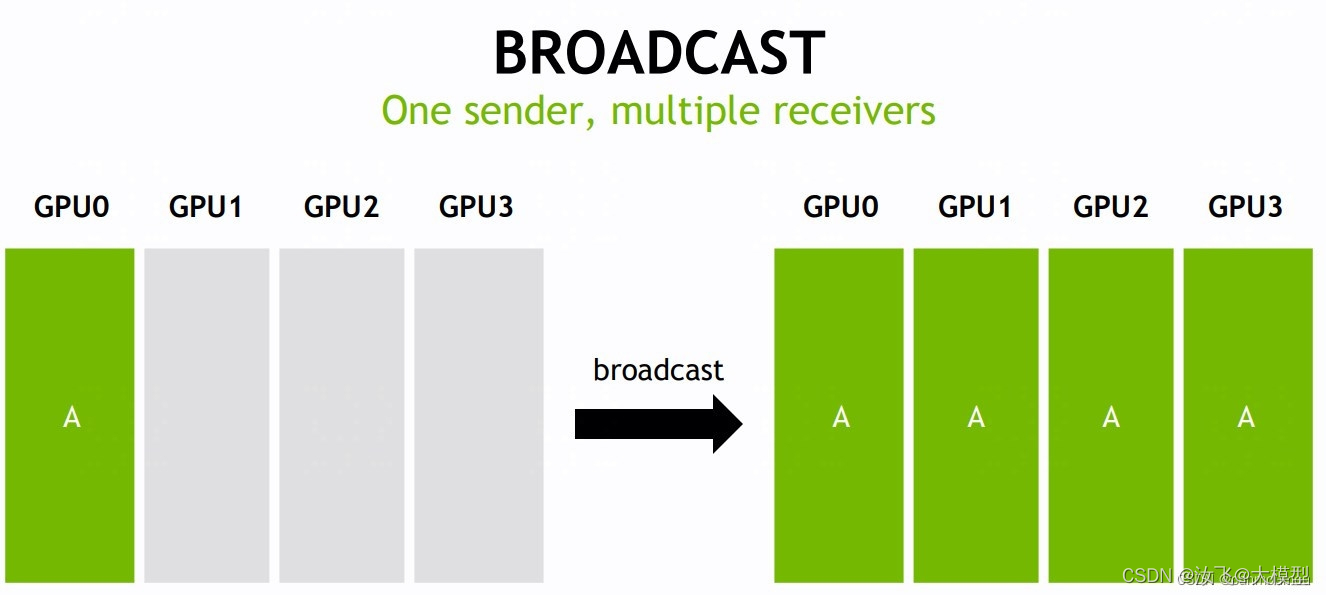
该网络中有4个GPU,对应 K=4 个 rank,即 rank0~rank3。root rank提供一个大小为N的数组A。经过 broadcast 操作后,每个 rank 都会接受到数组A。 -
scatter one-to-all 点对点通信
该操作根据网络中的所有指定的rank数量,将A元素平分,然后分布到所有指定的rank中。
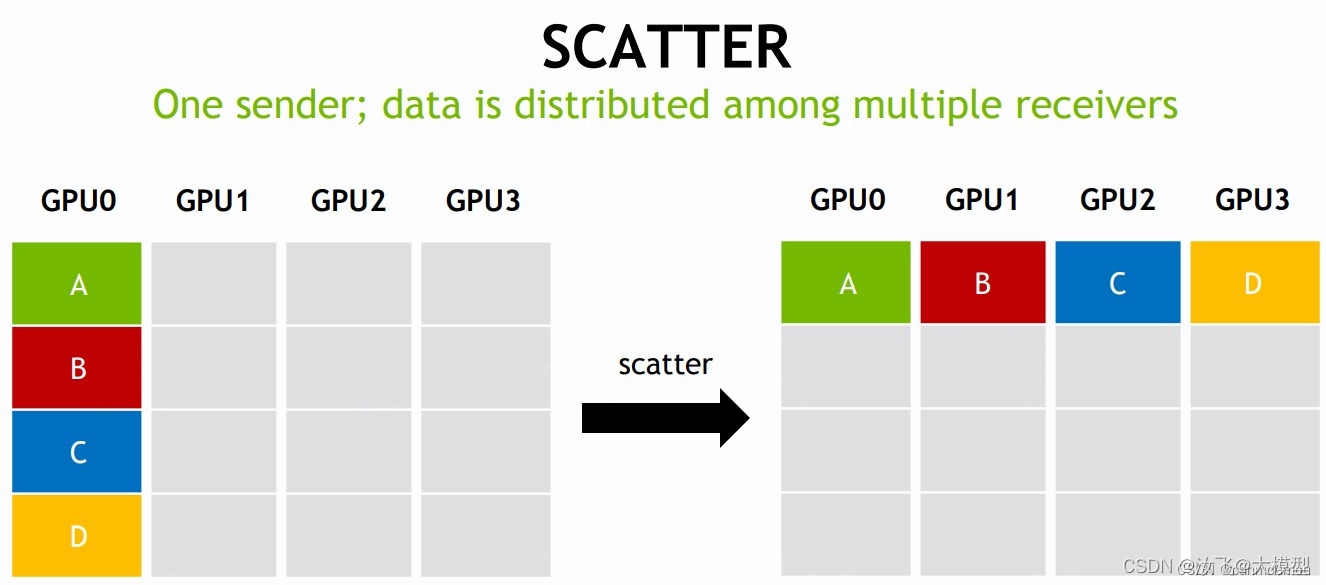
该网络中有4个GPU,对应 K=4 个rank,root rank 提供了K * N的数组,分别为A、B、C、D四个数组。经过 scatter 操作后,会按照 rank index 顺序将数组A/B/C/D分布到每个rank的缓冲区中。 -
gather all-to-one 点对点通信
该操作将分布在所有指定的rank中的数据,收集到指定rank输出缓冲区(通常为root rank缓冲区)中。
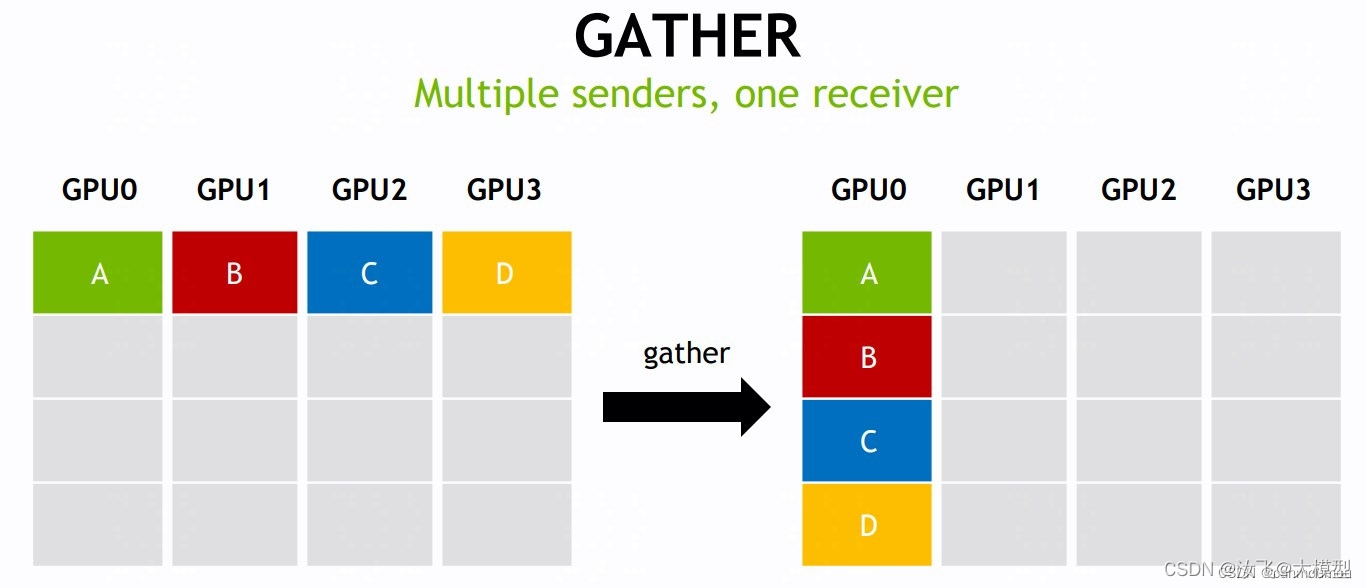
该网络中有4个GPU,对应 K=4 个rank,每个 rank 提供了 1 个大小为N的数组,分别为A、B、C、D四个数组。经过 gather 操作后,会按照 rank index 顺序将数组A/B/C/D收集到 root rank 的缓冲区中,形成K * N维度的结果。 -
all-gather
该操作将分布在所有指定的rank中的数据,收集到输出缓冲区(通常为root rank缓冲区)中,然后将结果分发到所有指定的rank。
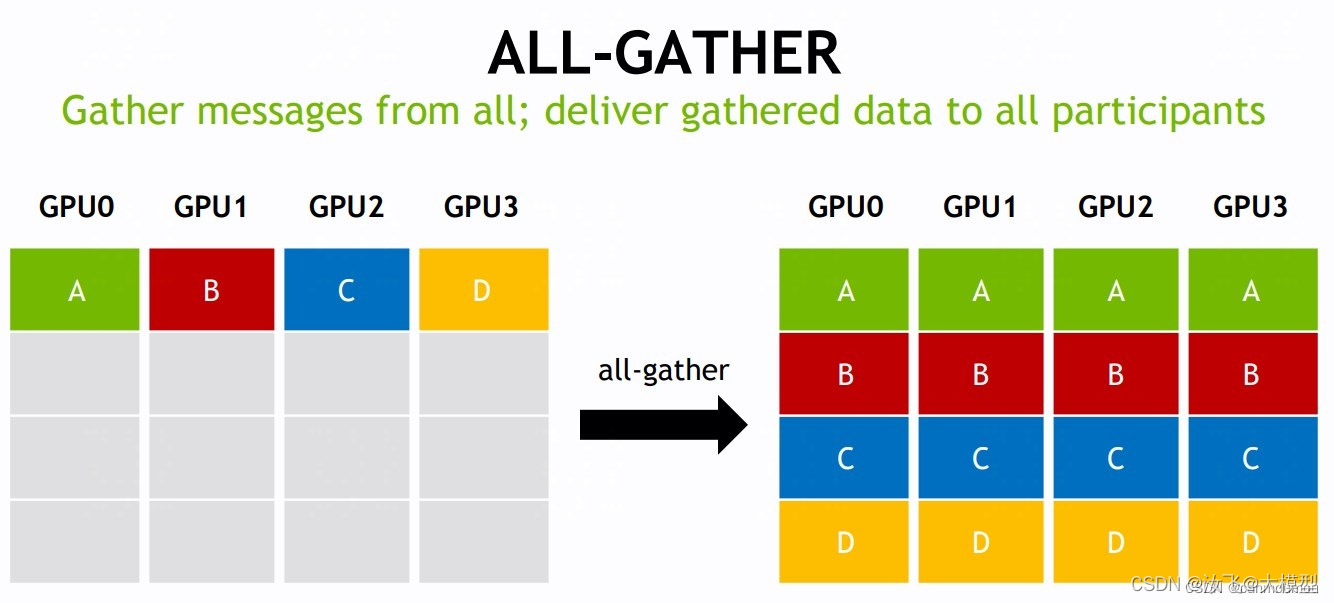
该网络中有4个GPU,对应 K=4 个rank,每个 rank 提供了 1 个大小为N的数组,分别为A、B、C、D四个数组。经过 all-gather 操作后,会按照 rank index 顺序将数组A/B/C/D收集到 root rank 的缓冲区中,形成K * N维度的结果,然后将结果分发到所有指定的rank中。 -
reduce
该操作将分布在所有指定的rank中的数据,以reduce函数的形式收集到输出缓冲区(通常为root rank缓冲区)中。常见reduce函数:sum、min、max等。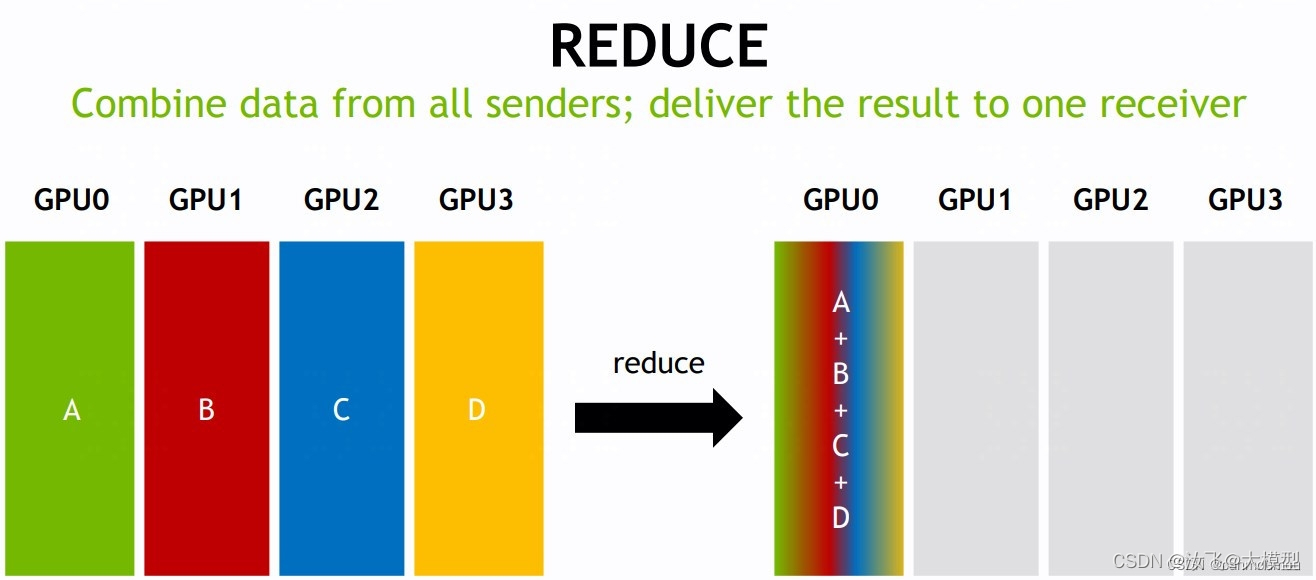
该网络中有4个GPU,对应 K=4 个rank,每个 rank 提供了 1 个大小为N的数组,分别为A、B、C、D四个数组。经过 reduce 操作后,会按照rank index顺序将数组A/B/C/D收集到 root rank 的缓冲区中,形成N维度的结果,图示中使用的是sum([A,B,C,D])函数,会将4个数组对位相加。 -
all-reduce
该操作执行与reduce相同的操作,区别在于将结果分发到所有指定的rank缓冲区中。
reduce后跟broadcast的效果,等同于all-reduce操作。

该网络中有4个GPU,对应 K=4 个rank,每个 rank 提供了 1 个大小为N的数组,分别为A、B、C、D四个数组。经过 all-reduce 操作后,会按照rank index顺序将数组A/B/C/D收集到 root rank 的缓冲区中,形成N维度的结果,图示中使用的是sum([A,B,C,D])函数,会将4个数组对位相加。然后将结构分发到所有指定的rank中。 -
reduce-scatter
该操作执行与reduce相同的操作,区别在于将结果平均分散到所有指定的rank缓冲区中。

该网络中有4个GPU,对应 K=4 个rank,每个 rank 提供了 1 个大小为K * N的数组,分别为Ak、Bk、Ck、Dk,(0 <= k <= 3)。经过 reduce-scatter 操作后,会按照rank index顺序将数组Ak/Bk/Ck/Dk收集到 root rank 的缓冲区中,形成K * N维度的结果,图示中使用的是sum([Ak,Bk,Ck,Dk])函数,会分别将4个数组对位相加。然后将结果平均分散到所有指定的rank中。 -
all-to-all 点对点通信
该操作将各自的信息,以scatter的方式发送给彼此。
效果等同于scatter/gather
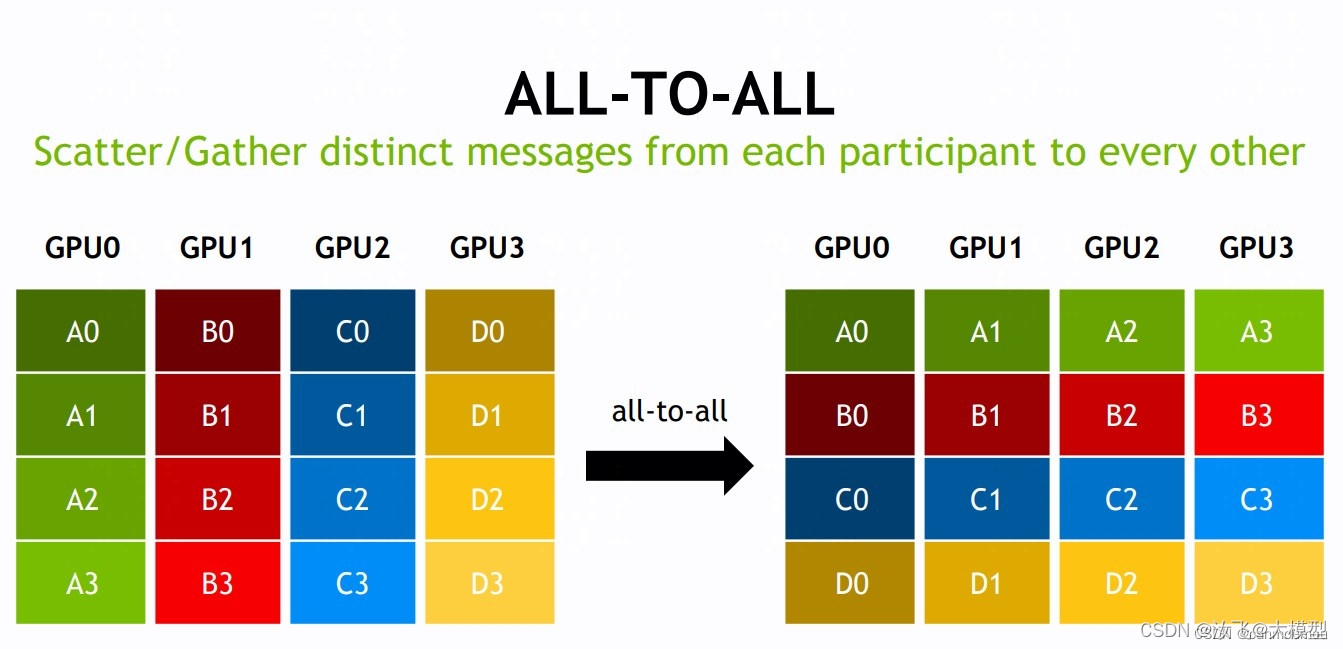
该网络中有4个GPU,对应 K=4 个rank,每个 rank 提供了 1 个大小为K * N的数组,分别为Ak、Bk、Ck、Dk,(0 <= k <= 3)。经过 gather 操作后,会按照rank index顺序将数组Ak/Bk/Ck/Dk收集到 root rank 的缓冲区中,形成K*(K*N)维度的结果。然后将结果平均分散到所有指定的rank中。 -
neighbor exchange
该操作交换N-dims空间中的neighbors的数据。
3)通信nccl编程实例
这一部分做一个了解即可,了解一下怎么通过nccl原语进行通信。
-
创建Communicator通信器
- 首先为每个cuda设备设置一个0~n-的rank,这些设备都是Communicator通信的一部分。
- 使用ncclCommInitRank(), ncclCommInitRankConfig() 和 ncclCommInitAll()方法可以创建Communicator objects。每一个communicator object都与固定的rank和cuda设备绑定,这些objects会被用来实现通信操作。
- 在执行ncclCommInitRank()之前,需要先创建一个唯一的communicator
object,作为root节点,被所有的通信进程使用,用来进行通信识别和接入2,以组成通信网络。 - ncclGetUniqueId()方法会返回一个ID,这个ID必须广播到所有参与通信的进程。
- ncclCommInitAll()方法可以替代上述那些繁杂的步骤。但是它仅限于单个进程中使用,不能在节点间通信。
# 1. 创建通用的Communicator ncclResult_t ncclCommInitAll(ncclComm_t* comm, int ndev, const int* devlist) {ncclUniqueId Id;ncclGetUniqueId(&Id); # 返回ID,必须通过broadcast发送到所有线程和所有GPU通信进程,发送方式有socket、MPI等并行环境。ncclGroupStart(); # 开始一个群组for (int i=0; i<ndev; i++) {cudaSetDevice(devlist[i]); ncclCommInitRank(comm+i, ndev, Id, i); # 给每个设备分配rank。}ncclGroupEnd(); # 结束一个群组 }# 2. 创建具有选项的Communicator ncclConfig_t config = NCCL_CONFIG_INITIALIZER; # 自定义参数config config.blocking = 0; # nccl在任何调用中都不会阻塞。 config.minCTAs = 4; config.maxCTAs = 16; config.cgaClusterSize = 2; config.netName = "Socket"; CHECK(ncclCommInitRankConfig(&comm, nranks, id, rank, &config)); do {CHECK(ncclCommGetAsyncError(comm, &state)); # 异常处理// Handle outside events, timeouts, progress, ... } while(state == ncclInProgress); -
使用多个ncclUniqueId创建通信器
- ncclCommInitRankScalable()函数支持多ncclUniqueIds创建通信器。
- 所有的 nccl rank 都必须使用相同的ncclUniqueIds数组(ncclUniqueIds顺序也要相同)。
- 为了最佳性能,应尽可能的将ncclUniqueId平均分配给nccl rank。
例如,如果要将 3 个 ncclUniqueId 分布在 7 个 NCCL 等级中,则第一个 ncclUniqueId 将与等级 0-2 相关联,而其他 ncclUniqueId 将与等级 3-4 和 5-6 相关联。因此,此函数将在排名 0、3 和 5 上返回 true,否则返回 false。
bool rankHasRoot(const int rank, const int nRanks, const int nIds) {const int rmr = nRanks % nIds;const int rpr = nRanks / nIds;const int rlim = rmr * (rpr+1);if (rank < rlim) {return !(rank % (rpr + 1));} else {return !((rank - rlim) % rpr);} } -
创建子通信器
- ncclCommSplit 函数可用于基于现有通信器创建
子通信器。这允许将现有 communicator拆分为多个子分区,也可以复制现有父 communicator,甚至创建具有少量rank的单个 communicator。 - ncclCommSplit 函数需要被原始 communicator 中的所有rank调用。如果有些没有被分配到任何子组,当它们调用 ncclCommSplit,会被NCCL_SPLIT_NOCOLOR标识。
- 新创建的 communicator 继承父 communicator 的配置(例如非阻塞)。如果父通信器在非阻塞模式下运行,则可以通过在父通信器上调用 ncclCommAbort 来停止 ncclCommSplit 操作,然后在返回的所有的新通信器上调用。这是因为在对两个 communicator 中的任何一个进行操作期间都可能发生挂起。
# 复制现有communicator int rank; ncclCommUserRank(comm, &rank); ncclCommSplit(comm, 0, rank, &newcomm, NULL);# 将现有communicator分成两半 int rank, nranks; ncclCommUserRank(comm, &rank); ncclCommCount(comm, &nranks); ncclCommSplit(comm, rank/(nranks/2), rank%(nranks/2), &newcomm, NULL);# 创建一个仅包含前2个rank的communicator int rank; ncclCommUserRank(comm, &rank); ncclCommSplit(comm, rank<2 ? 0 : NCCL_SPLIT_NOCOLOR, rank, &newcomm, NULL); - ncclCommSplit 函数可用于基于现有通信器创建
-
多个通信器同时使用
- NCCL 操作本身就是在执行 CUDA 调用,任何 CUDA 操作都会导致设备进行数据同步,但是NCCL 内核是阻塞的(等待数据到达),它需要等待所有的所有数据同步完成后才会进行下一步操作。所以在使用多个 NCCL 通信器的时候,需要设计好同步规则,防止死锁。
- 不同 communicator 上的nccl操作都应该在不同的 epoch 中使用,不能在同一个epoch中进行不同的communicator操作,还需要设计锁定机制,应用程序也应确保按照rank顺序提交操作。
- 假如多个通信操作(在不同的流上)可以适应 GPU,也可能会能进行通信工作。但是,如果 NCCL 操作使用多个 CUDA 块,或 NCCL 集合中使用的一些调用来操作设备同步(例如,动态分配一些 CUDA 内存),通信则会随时中断。
-
通信器工作状态
ncclCommFinalize会将通信器从 ncclSuccess 状态转换为 ncclInProgress 状态
当 ncclInProgress 状态时,开始在后台处理所有操作,并且,也会同步与其他rank通信相关的资源。所有未完成的操作和与 communicator 相关的网络资源也会调用该方法进行刷新和释放。- 当完成所有 NCCL 操作后,通信器将转换为 ncclSuccess 状态。
- 可以使用 ncclCommGetAsyncError 查询通信器工作状态。
- 如果 communicator 标记为非阻塞,则此操作为非阻塞;否则,它将阻塞。
-
销毁通信器
当 communicator 完成后,可以调用ncclCommDestory方法来释放所有资源,包括communicator本身。
当通信器状态为ncclSuccess,调用ncclCommDestory时,如果调用是阻塞的,调用则会被阻止执行,所以需要保证调用是非阻塞的。在任何情况下,ncclCommDestory的调用都会释放通信器资源并返回,并且在返回后不再访问通信器。
2.3 NCCL算法与逻辑拓扑结构
1)ring
2)double binary tree