新版本发布丨向企业级实时计算平台迈进!支持存算分离、FICC 函数库大更新!
一直以来,金融领域的业务开发都有着专业性极强、多要素融合波及面广的特点,这些特点对金融领域的基础软件和开发工具建设提出了很大挑战。为了应对这一行业难题,DolphinDB 差异化地以“引擎、函数、模块、插件”四大工具构成业务中间件的概念,为金融业务团队开发效率大幅提速;同时,DolphinDB 将通过多个版本的迭代,打造一个集全局数据目录、分布式集群调度、多业务模块于一体的企业级实时计算平台,从深度和广度两个方面为金融业务的二次开发提供企业级的服务与保障。
在此次新版本 V3.00.2&V2.00.14 的更新中,DolphinDB 引入计算组的概念,实现了存算分离的基础架构,同时支持了单点登录和多集群管理功能。
业务支持方面,新版本对 FICC 相关的业务工具进行了大量补充,开发了估值定价和曲线拟合两大引擎,以及包含现金流、收益率、利率互换估值、信用违约互换估值等在内的十多个优化函数。
除了上述亮点,此次更新还推出了针对物联网行业的点位管理引擎(IOTDB),通过引入 IOTANY 可变数据类型,开创性地解决了点位表中不同测点因数据类型不一致而不得不采用 STRING 进行低效存储和计算的问题,同时,测点最新值查询的性能也得到大幅提升;此外,还有 TextDB 的推出,大幅提升了 DolphinDB 与 AI 大模型融合应用的能力。下文将为大家逐个详细介绍。
DolphinDB V3.00.2 重磅功能
完善企业级实时计算平台架构
存算分离:资源/故障隔离,节点弹性扩展
传统数据库架构通常将数据存储与计算紧密耦合。这样的设计随着数据量的快速增长,会出现诸如资源利用不均衡、数据访问延迟增加等问题。因此,存算分离架构应运而生。该架构将存储和计算资源相互独立,使系统可以灵活地调配资源,还能避免数据过于集中的问题,防止出现某个存储节点故障导致的业务中断甚至数据永久丢失的问题。
在以前的版本中,DolphinDB 虽然有计算节点,但部分计算任务还是下推到存储节点完成。在这一版本中,DolphinDB 引入了计算组的概念,对存算分离的支持更彻底。
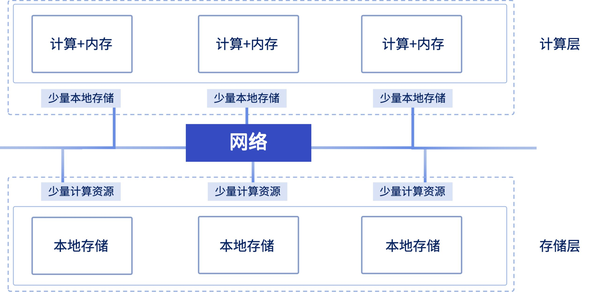
计算组可以理解为 n 个计算节点组成的节点组,用户可以根据需求自由配置。作为资源和故障隔离的基本单位,每个计算组能够承担不同类型的计算任务,如 SQL 查询、流计算、内存计算等。用户可以灵活增减计算节点,实现弹性扩展。其中,计算组的规模决定了算力的大小。
引入计算组后,用户可以充分利用存算分离架构的混合查询优势,将写入频繁的分区查询调度到存储节点进行原地执行,将写入不频繁的分区查询调度到计算组。计算组能够通过缓存分区数据,加快查询速度。此外,将用户安排在不同的计算组,可以实现用户层面的计算资源隔离,有效降低节点宕机的风险。
集群管理:单点登录+多集群管理
一个面向企业级应用的平台必须具备统一权限管理的能力,单点登录(SSO)是实现这一目标的重要功能之一。
单点登录允许用户通过一次登录,即可访问多个企业内部系统,无需为每个应用程序重复输入用户名和密码,优化工作流程,提升整体工作效率。同时,单点登录通过集中管理用户身份信息,减少 IT 团队在权限管理上的负担。在合规管理方面,单点登录也提供了更好的审计和监控能力,通过集中记录用户的登录和访问行为,帮助企业遵循相关法规和政策。
在此次的新版本中,通过支持 oauthLogin 函数,DolphinDB 能够使用户实现 DolphinDB 与内部软件系统之间的单点登录,提高操作便捷性和工作效率。为增强安全性,系统提供了 "IP + 用户" 模式,用于限制用户的登录地址。此外,DolphinDB 还支持 Haproxy HTTP/TCP 模式下的 IP 透传,确保用户真实 IP 的准确传递。
除了单点登录,多集群管理功能在企业级管理平台的构建中同样重要,它允许用户在不同环境中灵活配置和利用计算与存储资源。
在 DolphinDB 中,用户可以定义一个 MoM(Master of Master)节点或集群,作为多个集群的集中管理中心,进行权限管理、资源监控及跨集群数据访问等操作。
例如,用户可以使用命令 grant("user1@cluster1", TABLE_READ, "trading.stock.quote@cluster2") 来授权集群 1 的用户访问集群 2 的特定数据。经过授权的用户只需通过 select * from trading.stock.quote@cluster1 的方式,便可轻松访问其他集群的数据。这样的设计不仅提高了管理的灵活性,也确保了数据的安全性。
FICC 业务功能上新:曲线拟合引擎+估值定价引擎+多个业务函数
FICC 业务是金融市场的重要组成部分,交易品种多,数据量大,对数据处理的速度和精度要求极高。为满足用户在 FICC 场景下对数据处理的需求,DolphinDB 推出了两大流计算引擎——实时曲线拟合引擎和估值定价引擎。同时还新增了多个业务函数,旨在为用户提供更高效、更精准的计算支持。
曲线拟合引擎
利率曲线拟合是 FICC 业务中的一项关键技术,它通过数学模型描述不同期限债券利率之间的关系。借助精确的利率曲线拟合,投资者和金融机构可以洞察市场对未来利率变动的预期,从而做出更明智的投资决策,并实施更为有效的风险管理策略。
此前 DolphinDB 研发了很多曲线拟合、优化求解的函数,本次推出的曲线拟合引擎就是将之前开发的函数整合成一个适用于不同业务场景、品种以及数据频率的工具。
该引擎可以根据不同的标的资产,结合资产类别、清算速度、产品类型等多个维度的信息,在动态市场环境下实时计算出最优曲线。它支持对不同资产应用不同的拟合算法,支持算法包括分段线性拟合、Nelson-Siegel 模型拟合、三次样条曲线拟合、线性插值拟合、多项式曲线拟合等。
以下是曲线拟合引擎的简单用例:
// 环境清理
try{dropStreamEngine("engine2")}catch(ex){print(ex)}
try{unsubscribeTable(tableName="inputTable", actionName="appendForengine2")}catch(ex){print(ex)}//指定传入表结构、资产类型、拟合算法
share streamTable(1:0, `symbol`sendingtime`askDirtyPrice1`bidDirtyPrice1`midDirtyPirce1`askyield1`bidyield1`midyield1`timetoMaturity`assetType`datasource`clearRate, [SYMBOL, TIMESTAMP,DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DOUBLE,INT,INT,STRING]) as inputTable
assetType=[0,1,2]
fitMethod=[<piecewiseLinFit(timetoMaturity, midyield1, 10)>,<nss(timetoMaturity,bidyield1,"nm")>,<piecewiseLinFit(timetoMaturity, askyield1, 5)>]//指定模型输出表和预测结果输出表
share streamTable(1:0, `time`assetType`dataSource`clearRate`model,[TIMESTAMP,INT,INT,SYMBOL,BLOB]) as modelOutput
share streamTable(1:0, `time`assetType`dataSource`clearRate`x`y,[TIMESTAMP,INT,INT,SYMBOL,DOUBLE,DOUBLE]) as predictOutput//基于上述参数创建曲线拟合引擎
engine = createYieldCurveEngine(name="engine2", dummyTable=inputTable, assetType=assetType, fitMethod=fitMethod,keyColumn=`assetType`dataSource`clearRate, modelOutput=modelOutput,frequency=10, predictInputColumn=`timetoMaturity, predictTimeColumn=`sendingtime, predictOutput=predictOutput, fitAfterPredict=true)subscribeTable(tableName="inputTable", actionName="appendForengine2", offset=0, handler=getStreamEngine("engine2"), msgAsTable=true);//创建数据,进行拟合
n = 100
data = table(take(`a`b`c, n) as symbol, take(now(), n) as time, decimal32(rand(10.0, n),3) as p1, decimal32(rand(10.0, n),3) as p2, decimal32(rand(10.0, n),3) as p3, decimal32(rand(10.0, n),3) as p4, decimal32(rand(10.0, n),3) as p5, decimal32(rand(10.0, n),3) as p6, (rand(10.0, n)+10).sort() as timetoMaturity, take(0 1 2, n) as assetType, take([1], n) as datasource, take("1", n) as clearRate)// 使用 replay 模拟流数据注入
replay(inputTables=data, outputTables=inputTable, dateColumn="time", replayRate=10, absoluteRate=true)估值定价引擎
无论是做市业务或是自营业务,手动交易或是量化交易,投资或是风控,估值定价都是贯穿整个 FICC 业务流程的一大核心需求。为帮助用户高效、精准地完成估值定价,DolphinDB 推出了估值定价引擎。
该引擎能够根据动态的市场行情信息和静态的合约信息,实时计算并更新债券、期权等金融资产的估值和价格,帮助用户判断市场动向、管理市场风险、做出更优决策。它支持将多种债券和期权的估值算法作为其算子,包含但不限于含息价格、应计利息、麦考利久期、债券凸性、欧式期权等指标的计算。
以下是估值定价引擎的简单用例:
// 环境清理
try{dropStreamEngine("engine1")}catch(ex){print(ex)}
try{unsubscribeTable(tableName="inputTable", actionName="appendForengine1")}catch(ex){print(ex)}//指定传入表结构、合约基础信息、输出表结构
share streamTable(1:0, `tradeTime`Symbol`realTimeX`predictY`price,[TIMESTAMP,SYMBOL, DOUBLE, DOUBLE, DOUBLE]) as inputTable
securityReference = table(take(0 1 2, 100) as type, take(1 2 3 4, 100) as assetType,"s"+string(1..100) as symbol, 2025.07.25+1..100 as maturity, rand(10.0, 100) as coupon, rand(10,100) as frequency,take([1],100) as basis )
outputTable = table(1:0, `tradeTime`type`symbol`result`factor1`factor2,[TIMESTAMP, INT, SYMBOL, DOUBLE[], DOUBLE, DOUBLE])//指定需要定价的债券类型、有价证券的购买日期、证券票面值、债券定价算法和参数
securityList=[0,1,2]
date=2024.07.25
par=100
method=[<bondDirtyPrice(date, maturity, coupon, predictY, frequency,basis)>,<bondAccrInt(date, maturity, coupon, frequency,par,basis)>,<bondDuration(date, maturity, coupon, predictY, frequency, basis)>]//基于上述参数创建估值定价引擎
createPricingEngine(name="engine1", dummyTable=inputTable, timeColumn=`tradeTime, typeColumn=`type, securityType=securityList, method=method, outputTable=outputTable, securityReference=securityReference, keyColumn=`Symbol, extraMetrics=[<price * predictY>, <coupon+price>])
// 订阅流表注入引擎
subscribeTable(tableName="inputTable", actionName="appendForengine1", offset=0, handler=getStreamEngine("engine1"), msgAsTable=true);// 使用 replay 模拟流数据注入
data = table(take(now(), 100)as tradeTime,"s"+string(1..100) as symbol, rand(10.0, 100) as realTimeX, rand(10.0, 100) as predictY, rand(10.0, 100) as price)
replay(inputTables=data, outputTables=inputTable, dateColumn="tradeTime", replayRate=50, absoluteRate=true)新增业务函数
除了曲线拟合引擎和估值定价引擎,DolphinDB 进一步扩展了业务函数库,以更好满足用户在 FICC 场景下的复杂需求。
- 新增
differentialEvolution函数,用于差分进化算法求解多元函数的全局最小值。 - 新增
maxDrawdown函数,用于计算最大回撤率。 - 新增
cummdd函数,用于计算累计最大回撤。 - 新增
bondCashflow函数,用于计算现金流。 - 新增
bondYield函数,用于计算收益率。 - 新增
irs函数,用于实现利率互换估值。 - 新增
crmwCBond函数,用于短期债券的信用风险缓释凭证估值。 - 新增
cds函数,用于信用违约互换估值。 - 新增
treasuryConversionFactor函数,用于计算国债期货估值中的转换因子。 - 新增
vanillaOption函数,用于香草期权定价。 - 在时间序列模型中新增向量自回归移动平均模型函数
varma和广义自回归条件异方差模型函数garch。 - 新增两个插值函数:多项式插值函数
kroghInterpolateFit和线性插值函数linearInterpolateFit。 - 拓展拟合利率曲线
nss和piecewiseLinFit的参数接口,支持指定最优化算法、最大迭代次数、随机数种子、初始估计值、上下边界。
打造 RAG 技术底座:新增文本存储引擎 TextDB
AI 和大模型是当下最热门的技术趋势之一。当谈到大模型与数据库的结合时,RAG (检索增强生成)是不可忽略的一项技术。它通过将检索得到的具体信息与生成模型的生成能力相结合,提高生成内容的准确性和信息丰富度。对于数据库而言,只有具备了强大的信息检索能力,才能成为 RAG 的技术底座。
这种检索能力主要体现在两方面:密集检索和稀疏检索。
密集检索能力也就是向量检索能力。DolphinDB 已在 3.00.1 版本中推出了以 TSDB 作为底层存储引擎的向量数据库 VectorDB,能够支持高效的向量检索、索引持久化以及混合搜索。它能够快速从知识库中找到与查询相关的信息,为生成模型提供丰富的上下文支持。
稀疏检索也被称为文本检索,它依赖于关键词检索技术,通过统计文本中的词频和逆文档频率(TF-IDF)来找到与查询最相关的文档。DolphinDB 在这一版本中推出了 TextDB,进一步完善了信息检索能力。
TextDB:利用倒排索引加速文本检索
倒排索引是一种将文档中出现的每个单词映射到包含该单词的文档列表的数据结构。它的优势在于能够快速定位包含特定关键词的文档,极大提升全文搜索效率,尤其适合处理大量非结构化文本数据。相比传统的逐字匹配,倒排索引在搜索速度和性能上表现更优。
TextDB 通过对文本数据字段建立高效的倒排索引,使用户在检索文本字段时,获得显著的加速效果,其性能相较 like 文本匹配可有几十倍提升。
TextDB 支持多种类型的检索方式,包含:
- 支持关键词检索、短语检索。
- 支持前后缀检索,支持在检索短语时指定词距。
- 支持中文、英文及中英文混合检索。
目前,主键存储引擎 PKEY 已支持文本索引,后续会扩展到其他存储引擎。以下是该引擎的简单用例:
// 建库建表
drop database if exists "dfs://textDB_1"
// 建库指定 engine="PKEY"
create database "dfs://textDB_1" partitioned by VALUE(2023.01.01..2023.01.01), engine='PKEY'
// 建表时指定 indexes 配置索引字段
create table "dfs://textDB_2"."tb"( date DATE,time TIME,source SYMBOL,txt STRING [indexes="textindex(parser=english, full=false, lowercase=true, stem=true)"]
)
partitioned by date,
primaryKey=["date", "time", "source"]// 模拟数据写入
txt= ["Greetings to you all! As energy rises after the Winter Solstice, we are about to bid farewell to the old year and usher in the new. From Beijing, I extend my best New Year wishes to each and every one of you!",
"In 2023, we have continued to forge ahead with resolve and tenacity. We have gone through the test of winds and rains, have seen beautiful scenes unfolding on the way, and have made plenty real achievements. We will remember this year as one of hard work and perseverance. Going forward, we have full confidence in the future.",
"This year, we have marched forward with solid steps. We achieved a smooth transition in our COVID-19 response efforts. The Chinese economy has sustained the momentum of recovery. Steady progress has been made in pursuing high-quality development."]t = table(take(2024.01.01, 3) as date, 00:00:01.000 00:00:03.051 00:00:05.100 as time, ["cnn", "bbc", "ap"] as source, txt)
tb.append!(t)// 文本查询
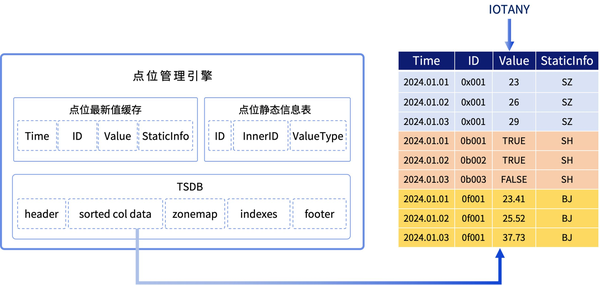
select * from tb where matchAny(textCol=txt,terms="farewell")点位管理引擎:单表管理不同类型点位数据
除了深耕金融领域,DolphinDB 也为其他行业的用户提供领先的数据治理解决方案。
此次更新针对物联网行业推出了一项重要功能 —— 点位管理引擎。点位即设备上用于采集、监测和控制的各类传感器和执行器,是物联网应用场景中最重要的数据单位,通过对众多点位进行管理,企业可以实现设备监控预警、实时监测等方案。
在点位管理中,不同测点的数据类型可能不一致。为解决这一问题,往往会采用两种方法。一种是将每一类测点分别存储在不同的表中。但由于测点类型较多,所以需要多张数据表,不便于管理。第二种是将测点值以字符串的形式存储,但这种方法会导致数据存储和计算的效率较低。
而 DolphinDB 新推出的点位管理引擎,支持可变类型 IOTANY。IOTANY 类型支持存储不同类型的属性值,可以实现一张表存储、管理所有类型的点位,大幅降低数据库管理和维护成本,同时保持数据存储和计算的高效。
同时,点位最新状态的查询性能也是点位管理场景中十分重要的考量点。DolphinDB 点位管理引擎内部维护了一张点位最新值缓存表,对所有点位数据最新值进行缓存,可以大幅提升点位最新状态的查询性能。
DolphinDB V3.00.2 & V2.00.14 升级功能一览
除了上述重点新功能,本次版本更新还对 DolphinDB 流数据处理、数据库管理、数据分析能力以及运维管理等多方面进行了优化升级,进一步提升了整体性能和用户体验。
流数据功能扩展与优化
流数据表/流订阅功能优化
在一些业务场景中,用户对流表的订阅需要按 or 的逻辑过滤多个字段。为满足这一需求,DolphinDB 在流数据订阅函数 subscribeTable 中支持用户配置 filter 参数为自定义函数,对消息进行更加灵活的过滤处理。
为进一步优化流数据处理,DolphinDB 新增了最新键值流表 (Latest Keyed Stream Table)。与 Keyed Stream Table 不同,向最新键值流表中添加新记录时,系统会自动检查新记录的时间戳。只有当新记录的时间戳大于该键值的最大时间戳时,记录才会被写入。此特性可用于多源行情数据的采集。
自定义窗口时序聚合引擎+快照连接引擎
DolphinDB 原有的时序聚合引擎 time series engine 支持用户指定窗口和步长,在计算时通过下一个窗口的首条数据触发前一个窗口的计算。然而,在某些场景下(例如由 1 分钟 K 线合成 5 分钟 K 线),这一方式可能会带来较高的计算延迟。
为解决这一问题,最新版本引入了 time bucket engine,用户可以通过参数 timeCutPoints 自定义每个计算窗口的范围。当时间戳≥窗口边界的数据到来时,系统立即触发计算并关闭窗口,后续到达的数据将被丢弃,从而降低计算延时,提升数据处理效率。
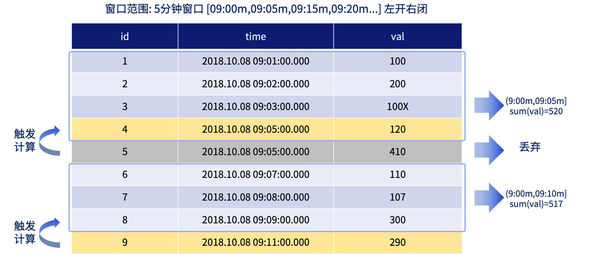
DolphinDB 还新增了快照连接引擎 snapshot join engine,用于两张流数据表的实时连接,支持内连接和全外连接。当左右表任意一方有数据更新时,都会触发连接计算。这一功能非常适用于风控场景,例如实时连接账户资产表与资产市价表,计算杠杆率、净值等关键指标,帮助评估和管理风险。
各项引擎优化
新版本除了增加上述两大引擎外,还对其他的流计算引擎进行了优化,具体如下:
订单簿快照引擎(orderbookSnapshotEngine)优化:
- 新增
setOrderbookSnapshotEngineStaticData函数,支持指定静态字段prevClose、maxPrice、minPrice、outputCodeMap。 - 当
useSystemTime = true时,skipCrossedMarket可以设置为false。 - 调整交易所休盘时段的输出。
- 增加即使在没有任何逐笔数据进来的窗口内也能输出快照的功能。
- 支持将
int[],long[]类型的字段输出为double[]类型。 - 优化输出,不输出
msgType为 -1 的记录。 - 支持本币利率互换品种。
- 增加衍生字段:剩余委托明细。
规则引擎优化:
- 新增
getRules函数,用于获取规则引擎中所有生效的规则。
响应式状态引擎(reactiveStateEngine)增强:
- 支持累计最大回撤函数
cummdd。 - 状态函数中的
percentChange、deltas新增可变更间隔大小的可选参数。 - 流处理场景下的
moving函数支持多个返回值。
时间序列引擎(TimeSeriesEngine)改进:
createDailyTimeSeriesEngine允许输出不完整的窗口。- DailyTimeSeriesEngine 增加参数,支持每天分组不清理。
- TimeSeriesEngine 支持
updateTime为 0。
流数据连接引擎:
- 支持左右表实时更新需求的流数据连接。
横截面引擎(cross-section engine):
- 支持数组向量(array vector)输入。
数据库管理优化
除了引入文本存储引擎 TextDB 外,新版本还从权限管理、集群管理、存储引擎三方面对 DolphinDB 进行了优化。
权限管理
- 新增函数
getTableAccess和gettDBAccess,查询用户对库与表的权限。
集群管理
- agent 支持登录。
- 支持细粒度的登录限制。
存储引擎
- 在 TSDB 的
KEEP_ALL模式下,upsert操作允许keyColNames中只包含部分排序列(sortColumns),而不需要列出所有的排序列,使用户可以更灵活地更新数据。 - 主键引擎现支持 VectorIndex,可以通过向量索引来加速数据检索,提升查询效率。
数据分析能力再增强
新版本从 JIT、SQL 和函数三方面进一步提升了 DolphinDB 的数据分析能力。
JIT 现已支持更多的数据类型,包括类(class)和时间类型(如 DATE、DATETIME 等),能够显著提升回测插件的性能。SQL 查询也得到了强化,大内存表的关联和分组计算性能得到了提升,尤其是通过新增基于 HASH join 的并行实现,大幅提高内存表的 join 效率。同时,系统还引入了标准 SQL 的 outer join(外联接)语法,增强了复杂查询的能力。
在函数方面,此版本:
- 新增
histogram2d函数,类似于 NumPy 的numpy.histogram2d,用于生成二维直方图。 - 新增
JSONExtract函数,用于提取 JSON 数据中的信息。
还对一些函数参数进行了扩展和优化:
generateTextFromTable函数增加默认参数,提高函数的易用性。runSQL函数增加可选参数variables,允许用户在执行 SQL 查询时传递变量。twindow函数扩展参数prevailing为INTEGER类型,实现在特殊场景下可以选择以左边界或右边界为当前行。mcount和mrank函数增加minPeriod参数,提供更灵活的窗口计算选项。
除了上述更新外,DolphinDB 还优化了多项 SQL、函数的相关性能,包括 SQL join、SQL group by、hash join、class getMember、piecewiseLinFit 函数等。此版本也实现了二级兼容,可以兼容旧版本的全部函数和脚本。同时还能实现插件和 SDK 的代码兼容,插件在升级二进制文件后,用插件写的脚本能继续运行。
未完待续……
接下来的版本中,DolphinDB 将会推出的重点功能如下:
- 继续完善企业级实时计算平台架构,包括:增强流表跨地区订阅的能力;流计算支持试算,以满足风控等需求;流计算支持声明式 API,提升易用性。
- 进一步优化多表连接性能。
- Shark 平台支持使用 GPU 执行自定义的 DolphinDB 脚本,加速复杂指标计算、曲线拟合、衍生品定价等较为耗时的计算任务。
- 插件市场支持上传和下载以 DolphinDB 脚本开发的插件和模块。