使用Dask在多块AMD GPU上加速XGBoost
Accelerating XGBoost with Dask using multiple AMD GPUs — ROCm Blogs

2024年1月26日 由Clint Greene撰写。
XGBoost 是一个用于分布式梯度提升的优化库。它已经成为解决回归和分类问题的领先机器学习库。如果您想深入了解梯度提升的工作原理,推荐阅读 Introduction to Boosted Trees。
在这篇博客中,我们将向您展示如何构建和安装支持 ROCm 的 XGBoost,以及如何使用 Dask 在多个 AMD GPU 上加速 XGBoost 训练。为了在多个 GPU 上加速 XGBoost,我们利用了 AMD 加速云(AAC),这是一个提供按需 GPU 云计算资源的平台。具体来说,我们使用了装有四个 GPU 的 AAC Dask Docker 容器来加速 XGBoost 训练。需要访问 AAC 才能跟随文中的步骤进行操作。
安装
启动 AAC 上的 Dask 工作负载后,克隆 XGBoost ROCm 仓库并进入该目录。
git clone https://github.com/ROCmSoftwarePlatform/xgboost.git
cd xgboost
git submodule update --init --recursive接下来,从源码构建 XGBoost。我们在 MI 200 Instinct 系列 GPU 上进行构建,因此将 DCMAKE_HIP_ARCHITECTURES 设置为 gfx90a。如果您使用的是不同架构,请相应地修改此项。您可以使用以下命令查找您的架构:rocminfo | grep gfx。
mkdir build
cd build
cmake -DUSE_HIP=ON -DCMAKE_HIP_ARCHITECTURES="gfx90a" -DUSE_RCCL=1 ../
make -j现在您可以将 XGBoost 编译成 Python 包。它将安装 XGBoost 的 2.1.0-dev 版本。
cd python-package
pip install .完成带有 ROCm 支持的 XGBoost 安装后,您可以使用 Dask 在 AMD GPU 上进行分布式训练和推理。
入门指南
下载一个训练数据集,以衡量分布在多个 GPU 上的计算所获得的加速效果。我们使用希格斯玻色子数据集,其目标是区分产生希格斯玻色子的信号过程和不产生希格斯玻色子的过程。
wget http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz
gunzip HIGGS.csv.gz导入 XGBoost 训练所需的库。
import time
import os
import dask
import pandas as pd
import xgboost as xgb
from distributed import Client
from dask import dataframe as dd
from dask_hip import LocalHIPCluster
from xgboost.dask import DaskDMatrix分布式环境
要使用 XGBoost 进行多 GPU 训练,您需要使用 Dask 设置分布式环境。Dask 集群由三个不同的组件组成:一个集中的调度器、一个或多个工作节点(GPU),以及一个用于向集群提交任务的客户端。
为了将 XGBoost 计算分布到 Dask 集群上:
将 num_gpus 设置为您想要使用的 GPU 数量。这将用于指定要使用的设备。然后,使用 LocalHIPCluster 以单节点模式创建集群,并将客户端连接到该集群。
num_gpus = 4
devices = ','.join([str(i) for i in range(num_gpus)])
cluster = LocalHIPCluster(HIP_VISIBLE_DEVICES=devices)
client = Client(cluster)您的分布式环境现已设置完毕,可以进行计算。
加载数据
数据集已经预先平衡、清理和标准化。为了进行基准测试,我们将使用完整的数据集,并将其加载为一个 Dask 数据框。
colnames = ['label'] + ['feature-%02d' % i for i in range(1, 29)]
fn = 'HIGGS.csv'
df = dd.read_csv(fn, header=None, names=colnames, dtype='float32')
X = df[df.columns.difference(['label'])]
y = df['label']训练
我们接着创建一个 xgboost.dask.DaskDMatrix 对象,并将其与其他参数一起传递给 xgboost.dask.train(),这与XGBoost的常规非Dask接口非常相似。与常规接口不同的是,数据和标签必须是Dask DataFrame或Dask Array实例。
dtrain = xgb.dask.DaskDMatrix(client, X, y)start_time = time.time()
param = {'max_depth': 8,'objective': 'reg:squarederror','tree_method': 'gpu_hist','device': 'gpu'}
print('Training')
bst = xgb.dask.train(client, param, dtrain, num_boost_round=1000)
print("[INFO]: ------ Training is completed in {} seconds ------".format((time.time() - start_time)))使用XGBoost的Dask训练接口时,我们将Dask客户端作为额外的参数传递,以便进行计算。
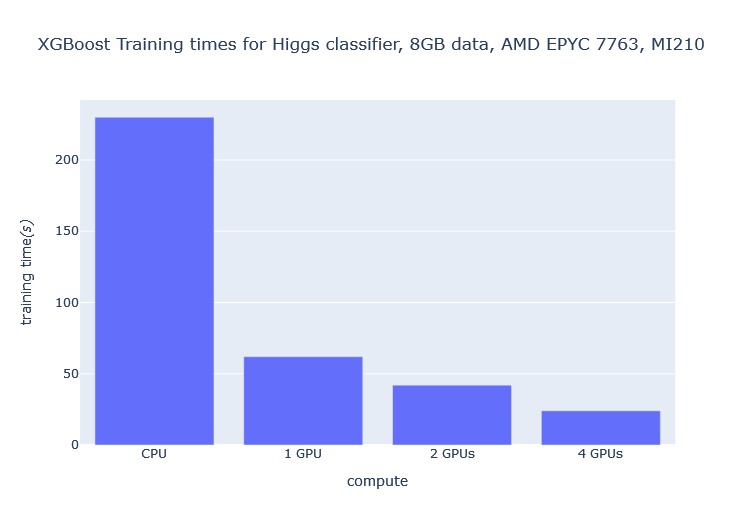
[INFO]: ------ Training is completed in 24.53920841217041 seconds ------推理
Dask接口有两个预测函数:`predict` 和 inplace_predict。我们使用 predict 函数。在获得训练好的模型 booster 后,可以通过以下代码进行推理:
booster = bst['booster']
# Set to use GPU for inference.
booster.set_param({'device': 'gpu'})
# dtrain is the DaskDMatrix defined above.
prediction = xgb.dask.predict(client, booster, dtrain)性能
可以看到,随着GPU数量的增加,训练时间显著减少。例如,将GPU数量从1增加到4,训练时间减少了2.6倍,相对于使用CPU进行训练,训练时间减少了超过10倍。