【建议收藏】大数据Flink入门专栏-v1.0,配套B站视频教程1小时速通
大数据Flink入门专栏-v1.0
文章目录
- 大数据Flink入门专栏-v1.0
- 配套视频
- 什么是 Apache Flink?
- 核心概念
- 主要组件
- 部署模式
- 应用场景
- 环境搭建与启动
- 基本使用:batch-wordcount
- 基本使用:stream-socket-wordcount
- 数据源
- 内置数据源
- 基于集合:
- 基于文件
- 基于 Socket
- 自定义数据源
- 连接kafka(新版本方法)
- 常用算子:DataStream
- 算子分类
- 算子使用
- 带状态计算
- 时间策略
- 作者与版本更新计划
配套视频
B站传送门:https://www.bilibili.com/video/BV1MKyWYAECg/
什么是 Apache Flink?
Apache Flink 是一个开源的流处理框架和分布式处理引擎,专门用于处理无边界和有边界的数据流。它能够在各种集群环境中运行,并且以高吞吐量和低延迟的方式进行数据处理。Flink 的设计目标是提供一个统一的流处理和批处理平台,使得用户能够用相同的 API 编写和执行流式和批量数据处理任务。
核心概念
-
流处理与批处理:
- 流处理:处理无边界数据流,即数据源不断产生数据,处理过程持续进行。Flink 支持事件时间(event time)处理和有状态流处理,确保数据处理的准确性和一致性。
- 批处理:处理有边界数据流,即数据源是固定的,处理过程在所有数据到达后开始。Flink 通过优化的算法和数据结构来高效处理批量数据。
-
有状态流处理:
- Flink 支持有状态流处理,允许在处理每个事件时访问和更新状态。状态可以是简单的计数器,也可以是复杂的机器学习模型。Flink 提供了精确一次(exactly-once)语义,确保状态的一致性和容错性。
-
事件时间与水位线(Watermark):
- Flink 使用事件时间来处理乱序事件,通过水位线机制确定何时处理窗口内的数据,确保数据按事件发生的实际时间进行处理。
-
状态管理与容错机制:
- Flink 通过状态快照(checkpointing)和流重放机制实现容错,确保作业在故障发生后能够恢复到一致状态。状态可以存储在内存、文件系统或 RocksDB 中。
主要组件
- JobManager:负责作业的调度、资源分配和故障恢复。
- TaskManager:执行实际的任务,管理任务的状态和资源。
- ResourceManager:管理集群中的资源,协调 JobManager 和 TaskManager。
部署模式
Flink 支持多种部署模式,包括:
- Session Mode:一个长期运行的集群,可接受多个作业提交,资源共享。
- Per-Job Mode:为每个作业启动独立的集群,资源隔离好,但开销较大。
- Application Mode:为每个应用程序启动一个集群,
main()方法在集群上运行,资源利用率高。
应用场景
Flink 广泛应用于各种实时数据处理场景,包括:
- 事件驱动型应用:如实时监控、报警系统。
- 数据分析应用:批处理和流处理的数据分析。
- 数据管道和 ETL:数据的提取、转换和加载。
- 复杂事件处理(CEP):如网络入侵检测、欺诈检测。
- 实时数仓:如实时销售数据分析、实时推荐系统。
- 实时报表:如双十一大屏展示、实时业务监控。
Apache Flink 是一个功能强大的流处理框架,能够高效地处理大规模数据流任务,提供高可用性和动态扩展能力,是构建实时数据处理应用的理想选择。
环境搭建与启动
使用playground安装flink。
playground install flink
启动命令
start-cluster.sh
停止命令
stop-cluster.sh
访问web界面:
http://192.168.56.151:8081/#/overview
基本使用:batch-wordcount
flink支持离线数据处理,离线数据获取后会保存为DataSource进行处理。以下是从数组中获取英文文本,并进行词频统计的过程。
首先创建maven工程,org.shuzhou.flinkapp。
1、添加maven依赖,在pom文件中分别添加以下3部分内容即可。
<!-- 1. 添加jdk版本、flink版本变量,并将source\target均改为1.8 --><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><!--JDK版本--><java.version>1.8</java.version><!--Flink版本--><flink.version>1.17.2</flink.version></properties><!-- 2. 添加以下flink依赖 --><dependencies><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><!-- 在本地运行时,scope更换为compile --><!-- 打包上生产环境时,scope更换为provided --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- Add logging framework, to produce console output when running in the IDE. --><!-- These dependencies are excluded from the application JAR by default. --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><!--alibabafastjson--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.42</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency></dependencies><!-- 3. 修改maven-jar-plugin用于打包 --><build><plugin><artifactId>maven-jar-plugin</artifactId><version>3.0.2</version><configuration><archive><manifest><addClasspath>true</addClasspath><classpathPrefix>lib/</classpathPrefix><mainClass>org.shuzhou.WordCount</mainClass></manifest></archive></configuration></plugin></plugins></pluginManagement></build>
</project>
2、编写代码,完成wordcount词频统计(数据源为数组)。
package org.shuzhou;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;public class WordCount {public static void main(String[] args) throws Exception {// 从参数中获取配置变量final ParameterTool params = ParameterTool.fromArgs(args);// 初始化Flink运行对象final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 传入配置信息env.getConfig().setGlobalJobParameters(params);// 数据源,这里WORDS为一个数组env.fromElements(WORDS)// 将英文切分为单词,并标记为1.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {// 这里的\\W+表示非字母数字字符String[] splits = value.toLowerCase().split("\\W+");for (String split : splits) {if (split.length() > 0) {out.collect(new Tuple2<>(split, 1));}}}})// 按照key进行分组,0,1代表序号,在Tuple元组中,0为key,1为value.groupBy(0).reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return new Tuple2<>(value1.f0, value1.f1 + value2.f1);}}).print();}private static final String[] WORDS = new String[]{"To be, or not to be,--that is the question:--","Whether 'tis nobler in the mind to suffer","The slings and arrows of outrageous fortune","Or to take arms against a sea of troubles,","And by opposing end them?--To die,--to sleep,--","No more; and by a sleep to say we end","The heartache, and the thousand natural shocks","That flesh is heir to,--'tis a consummation","Devoutly to be wish'd. To die,--to sleep;--","To sleep! perchance to dream:--ay, there's the rub;","For in that sleep of death what dreams may come,","When we have shuffled off this mortal coil,","Must give us pause: there's the respect","That makes calamity of so long life;","For who would bear the whips and scorns of time,","The oppressor's wrong, the proud man's contumely,","The pangs of despis'd love, the law's delay,","The insolence of office, and the spurns","That patient merit of the unworthy takes,","When he himself might his quietus make","With a bare bodkin? who would these fardels bear,","To grunt and sweat under a weary life,","But that the dread of something after death,--","The undiscover'd country, from whose bourn","No traveller returns,--puzzles the will,","And makes us rather bear those ills we have","Than fly to others that we know not of?","Thus conscience does make cowards of us all;","And thus the native hue of resolution","Is sicklied o'er with the pale cast of thought;","And enterprises of great pith and moment,","With this regard, their currents turn awry,","And lose the name of action.--Soft you now!","The fair Ophelia!--Nymph, in thy orisons","Be all my sins remember'd."};
}3、本地测试运行。

4、修改pom文件中的plugin,将主类改为org.shuzhou.WordCount。
<plugin><artifactId>maven-jar-plugin</artifactId><version>3.0.2</version><configuration><archive><manifest><addClasspath>true</addClasspath><classpathPrefix>lib/</classpathPrefix><mainClass>org.shuzhou.WordCount</mainClass></manifest></archive></configuration></plugin>
5、执行打包命令。
mvn package
6、将jar包上传到linux服务器中。
7、在服务器运行flink作业。
# 这里-p是指并行度为1
flink run -m node01:8081 -p 1 flinkapp-1.0-SNAPSHOT.jar
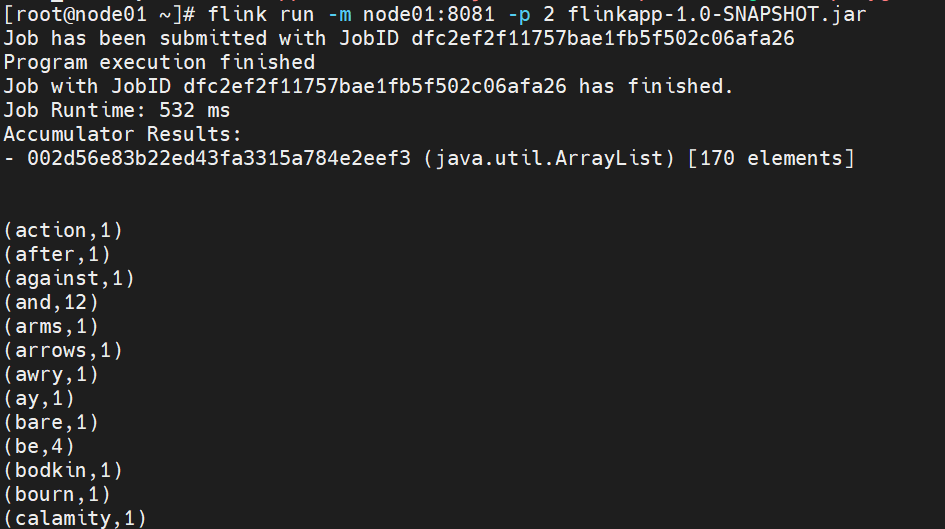
5、在flink web界面中提交会报错。
因为在分离模式(detached mode)中代码使用了 eager execution 函数,如 collect、print、printToErr 和 count。这些函数会立即触发作业执行,并尝试收集和打印结果,但在分离模式下是不支持的。
基本使用:stream-socket-wordcount
flink从实时数据源获取的数据,会转换为DataStreamSource进行实时处理。以下是从端口获取英文文本,进行实时词频统计。
代码编写:
package org.shuzhou;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class SocketWC {public static void main(String[] args) throws Exception {//参数检查if (args.length != 2) {System.err.println("USAGE:\nSocketTextStreamWordCount <hostname> <port>");return;}String hostname = args[0];Integer port = Integer.parseInt(args[1]);// set up the streaming execution environmentfinal StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//获取数据,数据源为Socket端口DataStreamSource<String> stream = env.socketTextStream(hostname, port);//计数SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream.flatMap(new LineSplitter()).keyBy(value -> value.f0).sum(1);// 支持使用lambda表达式
// stream.flatMap((s, collector) -> {
// for (String token : s.toLowerCase().split("\\W+")) {
// if (token.length() > 0) {
// collector.collect(new Tuple2<String, Integer>(token, 1));
// }
// }
// })
// // .returns((TypeInformation) TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class))
// .keyBy(0)
// .sum(1)
// .print();sum.print();env.execute("Java WordCount from SocketTextStream Example");}public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {String[] tokens = s.toLowerCase().split("\\W+");for (String token: tokens) {if (token.length() > 0) {collector.collect(new Tuple2<String, Integer>(token, 1));}}}}
}2、代码打包后在web界面提交,提交前需要监听9000端口。
yum install nc -y
nc -l 9000

3、在nc界面输入单词。
hello
flink
hello
world
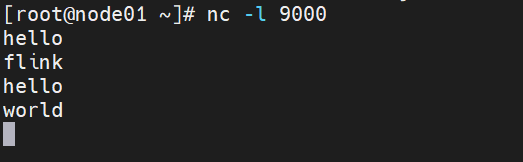
4、在web界面可以看到输出结果。

另. 可以通过命令行启动flink任务。
flink run -m node01:8081 -p 2 flinkapp-1.0-SNAPSHOT.jar node01 9000

数据源
Flink 添加数据源方法。
StreamExecutionEnvironment.addSource(sourceFunction)
注意:除了连接Kafka数据源,其它数据源连接方法快速浏览即可。
内置数据源
基于集合:
fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 获取数据,数据源为数组
DataStreamSource<String> stream1 = env.fromElements(
"王矗馨,女,汉族",
"万俊伟,男,阿昌族",
"包弓泰,男,东乡族",
"庞金豪,女,汉族",
"靳伟腾,女,汉族"
);stream1.print();
fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
基于文件
1、readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = env.readTextFile("file:///path/to/file");
2、readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
3、readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType(监听数据方式,定期扫描或者只扫描一次),这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);
在具体实现上,Flink 把文件读取过程分为两个子任务,即目录监控和数据读取。每个子任务都由单独的实体实现。目录监控由单个非并行(并行度为1)的任务执行,而数据读取由并行运行的多个任务执行。后者的并行性等于作业的并行性。单个目录监控任务的作用是扫描目录(根据 watchType 定期扫描或仅扫描一次),查找要处理的文件并把文件分割成切分片(splits),然后将这些切分片分配给下游 reader。reader 负责读取数据。每个切分片只能由一个 reader 读取,但一个 reader 可以逐个读取多个切分片。
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,则当文件被修改时,其内容将被重新处理。这会打破“exactly-once”语义,因为在文件末尾附加数据将导致其所有内容被重新处理。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,则 source 仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续阅读,直到读取所有的文件内容。关闭 source 后就不会再有检查点。这可能导致节点故障后的恢复速度较慢,因为该作业将从最后一个检查点恢复读取。
基于 Socket
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999) // 监听 localhost 的 9999 端口过来的数据
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
自定义数据源
通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
有一些常用的数据源,官方已经完成实现,例如FlinkKafkaConsumer011。
addSource - 添加一个新的 source function。例如,你可以用 addSource(new FlinkKafkaConsumer011<>(…)) 从 Apache Kafka 读取数据。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<KafkaEvent> input = env
.addSource(
new FlinkKafkaConsumer011<>(
parameterTool.getRequired("input-topic"), //从参数中获取传进来的 topic
new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()));
连接kafka(新版本方法)
创建kafka topic
./kafka-topics.sh --create --topic persion --zookeeper node01:2181,node02:2181,node03:2181 --partitions 1 --replication-factor 2
控制台生产者
kafka-console-producer.sh --topic persion --broker-list node01:9092,node02:9092,node03:9092
发送数据
邓鸣任,男,汉族,450411195001010014,19500101,187207735815,px6b1tr4j3@163.com,湖北省宜昌市LRP路795号
瞿俯琮,女,哈尼族,210124195001010023,19500101,156058130373,73y2nys6t5@163.com,辽宁省营口市市辖区DIR路391号
顾主飚,女,布朗族,320683195001010018,19500101,133440514969,0yn3x7rlxu@163.com,北京市崇文区TGD路735号
竺姣姬,女,鄂温克族,440500195001010019,19500101,180193530821,gy1rk7paqx@qq.com,吉林省白山市八道江区QFM路43号
吉君晷,女,柯尔克孜族,540124195001010038,19500101,159194361769,hwwuom3n8i@qq.com,山东省泰安市肥城市ANF路847号
朱佐钧,女,汉族,140427195001010012,19500101,187836461366,a8glxa18dn@qq.com,山西省太原市阳曲县CWF路22号
1、添加依赖。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency>
2、消费kafka数据。
package org.shuzhou.b_source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** 从kafka数据源获取数据*/
public class KafkaData {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.56.151:9092,192.168.56.152:9092,192.168.56.153:9092").setTopics("persion").setGroupId("root").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStream<String> ds = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");ds.print();env.execute("Flink add data source");}
}
flink支持 Kafka、ElasticSearch、Socket、RabbitMQ、JDBC、Cassandra POJO、File、Print 等 Sink 的方式。
常用算子:DataStream
算子分类
Source: 数据源:本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义 source。
Transformation: 数据转换操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等。
Sink:写入文件、标准输出流(打印)、写入 Socket 、自定义的 Sink。
算子使用
1、**map:**一对一转换
/*** 获取数据,数据源为Kafka,避免从端口获取中文数据乱码* 数据格式* 王矗馨,女,汉族,411424195001010028,19500101,150977754190,kk4jlw850x@sina.com,甘肃省临夏回族自治州和政县CNR路884号*/
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.56.151:9092,192.168.56.152:9092,192.168.56.153:9092")
.setTopics("persion")
.setGroupId("root")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> people = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");// map操作,提取数据中的民族
// 方法1:直接提取
SingleOutputStreamOperator<String> res = people.map(new MapFunction<String, String>(){@Overridepublic String map(String value) throws Exception {String nation = value.split(",")[2];return nation;}});res.print();/*** 方法2:将数据直接封装到一个对象中,之后再进行提取*/
SingleOutputStreamOperator<PersonalInfo> ds = people.map(new MapFunction<String, PersonalInfo>(){@Overridepublic PersonalInfo map(String value) throws Exception {String[] fields = value.split(",");PersonalInfo info = new PersonalInfo(fields[0], fields[1], fields[2], fields[3], fields[4], fields[5], fields[6], fields[7]);return info;}
});
ds.print();// PersonalInfo类定义
public class PersonalInfo {private String name;private String gender;private String ethnicity;private String idNumber;private String dateOfBirth;private String phoneNumber;private String email;private String address;public PersonalInfo(String name, String gender, String ethnicity, String idNumber, String dateOfBirth, String phoneNumber, String email, String address) {this.name = name;this.gender = gender;this.ethnicity = ethnicity;this.idNumber = idNumber;this.dateOfBirth = dateOfBirth;this.phoneNumber = phoneNumber;this.email = email;this.address = address;}// getter and setter methods for each fieldpublic String getName() {return name;}public void setName(String name) {this.name = name;}public String getGender() {return gender;}public void setGender(String gender) {this.gender = gender;}public String getEthnicity() {return ethnicity;}public void setEthnicity(String ethnicity) {this.ethnicity = ethnicity;}public String getIdNumber() {return idNumber;}public void setIdNumber(String idNumber) {this.idNumber = idNumber;}public String getDateOfBirth() {return dateOfBirth;}public void setDateOfBirth(String dateOfBirth) {this.dateOfBirth = dateOfBirth;}public String getPhoneNumber() {return phoneNumber;}public void setPhoneNumber(String phoneNumber) {this.phoneNumber = phoneNumber;}public String getEmail() {return email;}public void setEmail(String email) {this.email = email;}public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}
}
对DataStream操作后返回SingleOutputStreamOperator,继承自 DataStream,(这里只做了解)。
name():该方法可以设置当前数据流的名称,如果设置了该值,则可以在 Flink UI 上看到该值;uid() 方法可以为算子设置一个指定的 ID,该 ID 有个作用就是如果想从 savepoint 恢复 Job 时是可以根据这个算子的 ID 来恢复到它之前的运行状态;
setParallelism() :该方法是为每个算子单独设置并行度的,这个设置优先于你通过 env 设置的全局并行度;
setMaxParallelism() :该为算子设置最大的并行度;
setResources():该方法有两个(参数不同),设置算子的资源,但是这两个方法对外还没开放(是私有的,暂时功能性还不全);
forceNonParallel():该方法强行将并行度和最大并行度都设置为 1;
setChainingStrategy():该方法对给定的算子设置 ChainingStrategy;
disableChaining():该这个方法设置后将禁止该算子与其他的算子 chain 在一起;
getSideOutput():该方法通过给定的 OutputTag 参数从 side output 中来筛选出对应的数据流。
2、FlatMap:获取一个元素并生成多个(包含0或1个)元素
//之前的wordcount案例就使用了flatmap
env.fromElements(WORDS)
// 将英文切分为单词,并标记为1
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {// 这里的\\W+表示非字母数字字符String[] splits = value.toLowerCase().split("\\W+");for (String split : splits) {if (split.length() > 0) {out.collect(new Tuple2<>(split, 1));}}}
})
3、Filter:条件过滤,返回为 true 的元素。
/*** filter数据过滤,获取民族为汉族的数据*/
SingleOutputStreamOperator<PersonalInfo> filter = ds.filter(new FilterFunction<PersonalInfo>() {@Overridepublic boolean filter(PersonalInfo persion) throws Exception {return persion.getEthnicity().equals("汉族") ;}
});// lambda 表达式简化代码
// SingleOutputStreamOperator<PersonalInfo> filter = ds.filter(persion -> persion.getGender().equals("汉族"));// 将结果输出到控制台
filter.addSink(new SinkFunction<PersonalInfo>() {
@Override
public void invoke(PersonalInfo personalInfo, Context context) throws Exception {String info = personalInfo.getName();System.out.println(new String(info.getBytes("UTF-8"), "UTF-8"));
}
});
4、KeyBy:相同的 Key 会被分到一个分区,使用hash取模进行分区。
// 返回 KeyedDataStream 数据流
// 根据民族进行分区
KeyedStream<PersonalInfo, String> keyBy = ds.keyBy(new KeySelector<PersonalInfo, String>(){@Overridepublic String getKey(PersonalInfo product) throws Exception {return product.getEthnicity();}
});// 简化写法
// KeyedStream<PersonalInfo, String> keyBy = ds.keyBy(value -> value.getEthnicity());// 如果是数组,则可以使用f0、f1选择元素,对象则不允许此操作
// dataStream.keyBy(value -> value.f0);
对DataStream完成一些列对key操作后返回KeyedStream,是 DataStream 在根据 KeySelector 分区后的数据流。DataStream 中常用的方法在 KeyedStream 后也可以用(除了 shuffle、forward 和 keyBy 等分区方法),在该类中的属性分别是 KeySelector 和 TypeInformation。
DataStream 中的窗口方法只有 timeWindowAll、countWindowAll 和 windowAll 这三种全局窗口方法,但是在 KeyedStream 类中的种类就稍微多了些,新增了 timeWindow、countWindow 方法,并且是还支持滑动窗口。
除了窗口方法的新增外,还支持大量的聚合操作方法,比如 reduce、fold、sum、min、max、minBy、maxBy、aggregate 等方法(列举的这几个方法都支持多种参数的)。
最后就是它还有 asQueryableState() 方法,能够将 KeyedStream 发布为可查询的 ValueState 实例。
5、Reduce:在相同 key 的数据流上“滚动”执行 reduce,返回处理结果。
// 官方代码
// 返回的结果是SingleOutputStreamOperator类型
keyedStream.reduce(new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2)throws Exception {return value1 + value2;}
});// 小案例:统计每个民族的年龄总和
/*** 先使用map计算每个人的年龄,得到元组(民族,age)* 然后使用keyBy对民族进行分组*/
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = ds.map(new MapFunction<PersonalInfo, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(PersonalInfo personalInfo) throws Exception {long age = calculateAge(personalInfo.getDateOfBirth());return Tuple2.of(personalInfo.getEthnicity(), (int) age);}
}).keyBy(0);/*** reduce聚合案例:对每个民族(已分组)的年龄进行累加,输出元组(民族,年龄总和)*/
keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return Tuple2.of(value1.f0, value1.f1 + value2.f1);}
}).print();// 计算年龄的函数
import java.time.LocalDate;
import java.time.Period;
import java.time.format.DateTimeFormatter;public static int calculateAge(String dateOfBirth) {DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMdd");LocalDate birthDate = LocalDate.parse(dateOfBirth, formatter);LocalDate currentDate = LocalDate.now();Period period = Period.between(birthDate, currentDate);return period.getYears();
}
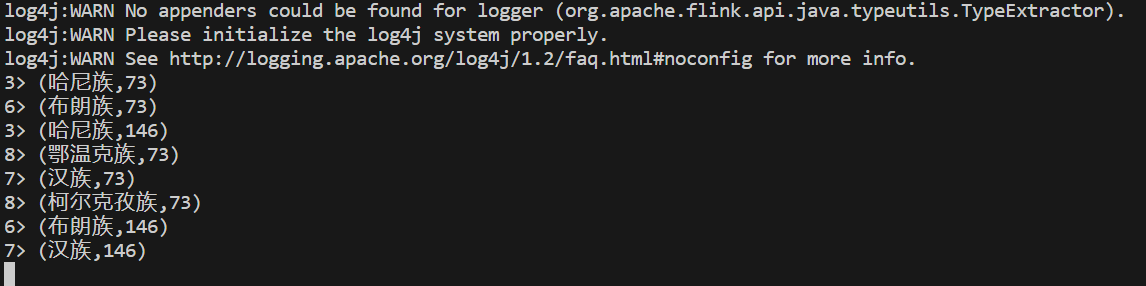
6、Aggregations:聚合,例如 min、max、sum 等。
// 返回的是SingleOutputStreamOperator<T>类型KeyedStream.sum(0)
KeyedStream.sum("key")
KeyedStream.min(0)
KeyedStream.min("key")
# max 返回流中的最大值,但 maxBy 返回具有最大值的键
KeyedStream.max(0)
KeyedStream.max("key")
KeyedStream.minBy(0)
KeyedStream.minBy("key")
KeyedStream.maxBy(0)
KeyedStream.maxBy("key")/*** 年龄累加案例,可以使用Aggregations算子中的sum完成*/
ds.map(new MapFunction<PersonalInfo, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(PersonalInfo personalInfo) throws Exception {long age = calculateAge(personalInfo.getDateOfBirth());return Tuple2.of(personalInfo.getEthnicity(), (int) age);}
}).keyBy(0).sum(1).print();
7、Window:窗口函数
# 10 秒的时间窗口聚合
inputStream.keyBy(0).window(Time.seconds(10));
8、WindowAll:将元素按照某种特性聚集在一起,不支持并行操作,默认的并行度是 1
inputStream.keyBy(0).windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
9、Union:多流合并
# 与自身结合,则会有2份相同数据
final DataStream<Integer> stream1 = env.addSource(...);
final DataStream<Integer> stream2 = env.addSource(...);stream1.union(stream2, stream3, ...);
10、Window Join:数据join窗口
# 在 5 秒的窗口中连接两个流
# 第一个流的第一个属性的连接条件等于另一个流的第二个属性
inputStream.join(inputStream1)
.where(0).equalTo(1)
.window(Time.seconds(5))
.apply (new JoinFunction () {...});
11、Split:根据条件将流拆分为两个或多个流
# 将偶数数据流放在 even 中,将奇数数据流放在 odd 中
# 在 1.7 版本以后建议使用 Side Output 来实现分流操作SplitStream<Integer> split = inputStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
});# 分流法
DataStreamSource<MetricEvent> data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SplitStream<MetricEvent> splitData = data.split(new OutputSelector<MetricEvent>() {
@Override
public Iterable<String> select(MetricEvent metricEvent) {
List<String> tags = new ArrayList<>();
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
tags.add("machine");
break;
case "docker":
tags.add("docker");
break;
case "application":
tags.add("application");
break;
case "middleware":
tags.add("middleware");
break;
default:
break;
}
return tags;
}
});DataStream<MetricEvent> machine = splitData.select("machine");
DataStream<MetricEvent> docker = splitData.select("docker");
DataStream<MetricEvent> application = splitData.select("application");
DataStream<MetricEvent> middleware = splitData.select("middleware");
filter分流
DataStreamSource<MetricEvent> data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator<MetricEvent> machineData = data.filter(m -> "machine".equals(m.getTags().get("type"))); //过滤出机器的数据
SingleOutputStreamOperator<MetricEvent> dockerData = data.filter(m -> "docker".equals(m.getTags().get("type"))); //过滤出容器的数据
SingleOutputStreamOperator<MetricEvent> applicationData = data.filter(m -> "application".equals(m.getTags().get("type"))); //过滤出应用的数据
SingleOutputStreamOperator<MetricEvent> middlewareData = data.filter(m -> "middleware".equals(m.getTags().get("type"))); //过滤出中间件的数据
Side Output分流:
//创建 output tag
private static final OutputTag<MetricEvent> machineTag = new OutputTag<MetricEvent>("machine") {
};
private static final OutputTag<MetricEvent> dockerTag = new OutputTag<MetricEvent>("docker") {
};
private static final OutputTag<MetricEvent> applicationTag = new OutputTag<MetricEvent>("application") {
};
private static final OutputTag<MetricEvent> middlewareTag = new OutputTag<MetricEvent>("middleware") {
};# 定义好 OutputTag 后,可以使用下面几种函数来处理数据:
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction# 这里是否要加break,待测试
DataStreamSource<MetricEvent> data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator<MetricEvent> sideOutputData = data.process(new ProcessFunction<MetricEvent, MetricEvent>() {
@Override
public void processElement(MetricEvent metricEvent, Context context, Collector<MetricEvent> collector) throws Exception {
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
context.output(machineTag, metricEvent);
case "docker":
context.output(dockerTag, metricEvent);
case "application":
context.output(applicationTag, metricEvent);
case "middleware":
context.output(middlewareTag, metricEvent);
default:
collector.collect(metricEvent);
}
}
});DataStream<MetricEvent> machine = sideOutputData.getSideOutput(machineTag);
DataStream<MetricEvent> docker = sideOutputData.getSideOutput(dockerTag);
DataStream<MetricEvent> application = sideOutputData.getSideOutput(applicationTag);
DataStream<MetricEvent> middleware = sideOutputData.getSideOutput(middlewareTag);
12、Select:将数据流拆分成两个数据流(奇数、偶数)后选择特定流。
SplitStream<Integer> split;
DataStream<Integer> even = split.select("even");
DataStream<Integer> odd = split.select("odd");
DataStream<Integer> all = split.select("even","odd");
13、connect:连接datastream,返回新的连接数据流,两个DataStream连接返回 ConnectedStreams,连接BroadcastStream(广播数据流)返回 BroadcastConnectedStream。
//1、连接 DataStream
DataStream<Tuple2<Long, Long>> src1 = env.fromElements(new Tuple2<>(0L, 0L));
DataStream<Tuple2<Long, Long>> src2 = env.fromElements(new Tuple2<>(0L, 0L));
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connected = src1.connect(src2);//2、连接 BroadcastStream
DataStream<Tuple2<Long, Long>> src1 = env.fromElements(new Tuple2<>(0L, 0L));
final BroadcastStream<String> broadcast = srcTwo.broadcast(utterDescriptor);
BroadcastConnectedStream<Tuple2<Long, Long>, String> connect = src1.connect(broadcast);案例2:
DataStream<Tuple2<Long, Long>> src1 = env.fromElements(new Tuple2<>(0L, 0L)); //流 1
DataStream<Tuple2<Long, Long>> src2 = env.fromElements(new Tuple2<>(0L, 0L)); //流 2
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connected = src1.connect(src2); //连接流 1 和流 2//使用连接流的六种 keyBy 方法
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup1 = connected.keyBy(0, 0);
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup2 = connected.keyBy(new int[]{0}, new int[]{0});
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup3 = connected.keyBy("f0", "f0");
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup4 = connected.keyBy(new String[]{"f0"}, new String[]{"f0"});
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector());
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector(), Types.STRING);//使用连接流的 map 方法
connected.map(new CoMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Object>() {
private static final long serialVersionUID = 1L;@Override
public Object map1(Tuple2<Long, Long> value) {
return null;
}@Override
public Object map2(Tuple2<Long, Long> value) {
return null;
}
});//使用连接流的 flatMap 方法
connected.flatMap(new CoFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>>() {@Override
public void flatMap1(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {}@Override
public void flatMap2(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {}}).name("testCoFlatMap")//使用连接流的 process 方法
connected.process(new CoProcessFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>>() {
@Override
public void processElement1(Tuple2<Long, Long> value, Context ctx, Collector<Tuple2<Long, Long>> out) throws Exception {
if (value.f0 < 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout1-" + String.valueOf(value));
}
}@Override
public void processElement2(Tuple2<Long, Long> value, Context ctx, Collector<Tuple2<Long, Long>> out) throws Exception {
if (value.f0 >= 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout2-" + String.valueOf(value));
}
}
});
14、自定义分区:partitionCustom
使用自定义分区器在指定的 key 字段上将 DataStream 分区,这个 partitionCustom 有 3 个不同参数的方法,分别要传入的参数有自定义分区 Partitioner 对象、位置、字符和 KeySelector。它们内部也都是调用了私有的 partitionCustom 方法。
15、广播:broadcast
// 广播后,下游所有task均可获取数据
// 1. 无参数,它返回的数据是 DataStream
DataStream<Tuple2<Integer, String>> source = env.addSource(...).broadcast();// 2. 参数MapStateDescriptor,返回 BroadcastStream
// BroadcastStream 后面不能使用算子去操作这些流,唯一可以做的就是使用 KeyedStream/DataStream 的 connect 方法去连接 BroadcastStream,连接之后的话就会返回一个 BroadcastConnectedStream 数据流。final MapStateDescriptor<Long, String> utterDescriptor = new MapStateDescriptor<>(
"broadcast-state", BasicTypeInfo.LONG_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO
);
final DataStream<String> srcTwo = env.fromCollection(expected.values());final BroadcastStream<String> broadcast = srcTwo.broadcast(utterDescriptor);案例补充:
public BroadcastStream<T> broadcast(final MapStateDescriptor<?, ?>... broadcastStateDescriptors) {
Preconditions.checkNotNull(broadcastStateDescriptors); //检查是否为空
final DataStream<T> broadcastStream = setConnectionType(new BroadcastPartitioner<>());
return new BroadcastStream<>(environment, broadcastStream, broadcastStateDescriptors); //构建 BroadcastStream 对象,传入 env 环境、broadcastStream 和 broadcastStateDescriptors
}上面方法传入的参数 broadcastStateDescriptors,我们可以像下面这样去定义一个 MapStateDescriptor 对象:final MapStateDescriptor<Long, String> utterDescriptor = new MapStateDescriptor<>(
"broadcast-state", BasicTypeInfo.LONG_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO
);
BroadcastConnectedStream:类定义是表示 keyed 或者 non-keyed 数据流和 BroadcastStream 数据流进行连接后组成的数据流。比如在 DataStream 中执行 connect 方法就可以连接两个数据流了,那么在 DataStream 中 connect 方法实现如下。
public <R> BroadcastConnectedStream<T, R> connect(BroadcastStream<R> broadcastStream) {
return new BroadcastConnectedStream<>( //构造 BroadcastConnectedStream 对象
environment,
this,
Preconditions.checkNotNull(broadcastStream),
broadcastStream.getBroadcastStateDescriptor());
}
16、process:
在输入流上应用给定的 ProcessFunction,从而创建转换后的输出流,通过该方法返回的是 SingleOutputStreamOperator
DataStreamSource<Long> data = env.generateSequence(0, 0);//定义的 ProcessFunction
ProcessFunction<Long, Integer> processFunction = new ProcessFunction<Long, Integer>() {
private static final long serialVersionUID = 1L;@Override
public void processElement(Long value, Context ctx,
Collector<Integer> out) throws Exception {
//具体逻辑
}@Override
public void onTimer(long timestamp, OnTimerContext ctx,
Collector<Integer> out) throws Exception {
//具体逻辑
}
};DataStream<Integer> processed = data.keyBy(new IdentityKeySelector<Long>()).process(processFunction);
其它方法:assignTimestampsAndWatermarks、join、shuffle、forward、addSink、rebalance、iterate、coGroup、project、timeWindowAll、countWindowAll、windowAll、print
带状态计算
对于KeyedStream,支持中间状态(计算结果)保存,以便让指标实时累加。
在使用上的区别是,使用RichFunction,如RichReduceFunction来完成算子逻辑的编写。在类实现时添加private transient ValueState<T>属性用于保存中间结果状态。
// 这里对于reduce的实现使用了RichReduceFunction,而非ReduceFunction
keyedStream.reduce(new RichReduceFunction<Tuple2<String, Integer>>() {// 定义ValueState用来保存中间结果状态private transient ValueState<Tuple2<Integer, Integer>> sum;...
}
然后需要在open方法中实现初始化工作。
@Overridepublic void open(Configuration config) throws IOException{ValueStateDescriptor<Tuple2<String, Integer>> descriptor = new ValueStateDescriptor<>("sum", // 状态名TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}), // 状态类型Tuple2.of("", 0)); // 默认的状态值sum = getRuntimeContext().getState(descriptor);}
定义之后,就可以在方法中使用。
@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {// 获取sum状态Tuple2<String, Integer> currentSum = sum.value();currentSum.f0 = value1.f0;// 进行处理逻辑currentSum.f1 += value1.f1;currentSum.f1 += value2.f1;// 更新sum状态sum.update(currentSum);// 返回结果return Tuple2.of(value1.f0, value1.f1 + value2.f1);}
完整案例(源码d_stateful\PersonStateful.java):
/*** 用到的数据集为data/people.txt* 累加每个民族的男女生人数,得到的结果为(男生人数,女生人数)*/
public class PersonStateful {public static void main(String[] args) throws Exception {// set up the streaming execution environmentfinal StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/*** 获取数据,数据源为Kafka,避免从端口获取中文数据乱码* 数据格式* 王矗馨,女,汉族,411424195001010028,19500101,150977754190,kk4jlw850x@sina.com,甘肃省临夏回族自治州和政县CNR路884号*/KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.56.151:9092,192.168.56.152:9092,192.168.56.153:9092").setTopics("persion").setGroupId("root").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStream<String> people = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");/*** 将数据使用map,一对一封装为PersonalInfo对象*/SingleOutputStreamOperator<PersonalInfo> ds = people.map(new MapFunction<String, PersonalInfo>() {@Overridepublic PersonalInfo map(String value) throws Exception {// System.out.println(value.toString());String encode = new String(value.getBytes("UTF-8"), "UTF-8");String[] fields = encode.split(",");PersonalInfo info = new PersonalInfo(fields[0], fields[1], fields[2], fields[3], fields[4], fields[5],fields[6], fields[7]);return info;}});/*** 使用map,将数据转换为(PersonalInfo对象,Tuple2(0,0))* 其中Tuple2(0,0)用于保存后续的计算结果,用于记录每个民族的男女生人数,最终结果为(男生人数,女生人数)* 然后使用keyBy对民族进行分区*/KeyedStream<Tuple2<PersonalInfo, Tuple2<Integer, Integer>>, Object> keyedStream = ds.map(new MapFunction<PersonalInfo,Tuple2<PersonalInfo,Tuple2<Integer,Integer>>>() {@Overridepublic Tuple2<PersonalInfo,Tuple2<Integer,Integer>> map(PersonalInfo value) throws Exception {// 转换为(PersonalInfo对象,Tuple2(0,0))return Tuple2.of(value, Tuple2.of(0, 0));}}).keyBy(value -> value.f0.getEthnicity());/*** reduce聚合案例:记录每个民族的男女总数,记录到一个元组中(男生人数,女生人数)* 使用有状态算子 keyed state*/keyedStream.reduce(new RichReduceFunction<Tuple2<PersonalInfo, Tuple2<Integer, Integer>>>() {// sum用于记录状态,f0=男生总数,f1=女生总数private transient ValueState<Tuple2<Integer, Integer>> sum;@Overridepublic Tuple2<PersonalInfo, Tuple2<Integer, Integer>> reduce(Tuple2<PersonalInfo, Tuple2<Integer, Integer>> value1, Tuple2<PersonalInfo, Tuple2<Integer, Integer>> value2) throws Exception {// 获取sum状态Tuple2<Integer, Integer> currentSum = sum.value();// 如果sum为空,则进行初始化if (currentSum == null) {currentSum = Tuple2.of(0,0);// 将value1进行累加if (value1.f0.getGender().equals("男")) {currentSum.f0 += 1;}if (value1.f0.getGender().equals("女")) {currentSum.f1 += 1;}}// 累加value2的值if (!value2.equals(null)) {// 将value2进行累加if (value2.f0.getGender().equals("男")) {currentSum.f0 += 1;}if (value2.f0.getGender().equals("女")) {currentSum.f1 += 1;}}sum.update(currentSum);// 将计算结果返回 (民族:人数,总年龄)return Tuple2.of(value1.f0,currentSum);}/** 对记录状态的ValueState<Tuple2<Integer, Integer>>进行构造* 源码中推荐写法*/@Overridepublic void open(Configuration config) throws IOException{// 构造时不初始化默认值ValueStateDescriptor<Tuple2<Integer, Integer>> descriptor = new ValueStateDescriptor<>("sum", // the state nameTypeInformation.of(new TypeHint<Tuple2<Integer, Integer>>() {})); sum = getRuntimeContext().getState(descriptor);// 在下面的代码中,判断如果state没有初始化则赋为默认值if (sum == null) {sum.update(Tuple2.of(0, 0));}}}).print();env.execute("Flink Operator Example");}// 计算年龄的函数public static int calculateAge(String dateOfBirth) {DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMdd");LocalDate birthDate = LocalDate.parse(dateOfBirth, formatter);LocalDate currentDate = LocalDate.now();Period period = Period.between(birthDate, currentDate);return period.getYears();}
}除了支持ValueState,flink支持以下所有状态:
-
ValueState<T>: 保存一个可以更新和获取的值(每个 Key 一个 value),可以用 update(T) 来更新 value,可以用 value() 来获取 value。
-
ListState<T>: 保存一个值的列表,用 add(T) 或者 addAll(List) 来添加,用 Iterable get() 来获取。
-
ReducingState<T>: 保存一个值,这个值是状态的很多值的聚合结果,接口和 ListState 类似,但是可以用相应的 ReduceFunction 来聚合。
-
AggregatingState<IN, OUT>: 保存很多值的聚合结果的单一值,与 ReducingState 相比,不同点在于聚合类型可以和元素类型不同,提供 AggregateFunction 来实现聚合。
-
MapState<UK, UV>: 保存一组映射,可以将 kv 放进这个状态,使用 put(UK, UV) 或者 putAll(Map) 添加,或者使用 get(UK) 获取。
这些状态不一定保存在内存中,也可以存储在磁盘或者其他地方。所有类型的状态都有一个 clear() 方法来清除当前的状态。
目前官方文档有一些滞后,在open方法的实现代码中,ValueStateDescriptor(TypeInformation<T> typeClass, T defaultValue)构造方法在将来会被移除,但文档中依旧是以下写法。
@Overridepublic void open(Configuration config) throws IOException{// 此构造方法会在将来版本中被移除ValueStateDescriptor<Tuple2<String, Integer>> descriptor = new ValueStateDescriptor<>("sum",TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}), Tuple2.of("", 0)); // 默认的状态值sum = getRuntimeContext().getState(descriptor);}
根据源码提示,推荐的写法是:
@Override
public void open(Configuration config) throws IOException{// 构造时不初始化默认值ValueStateDescriptor<Tuple2<String, Integer>> descriptor = new ValueStateDescriptor<>("sum", // the state nameTypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {})); sum = getRuntimeContext().getState(descriptor);// 在下面的代码中,判断如果state没有初始化则赋为默认值Tuple2<String, Integer> currentValue = sum.value();if (currentValue == null) {sum.update(Tuple2.of("", 0));}
}
至于原因,chatgpt给出的说法是:
具体来说,如果您使用被弃用的构造方法(例如 ValueStateDescriptor(TypeInformation<T> typeClass, T defaultValue)),则在读取状态时可能会出现问题。因为这种情况下,如果状态尚未初始化,将会返回默认值 defaultValue。但是,如果状态已经存在但内容为 null,则仍然会返回 defaultValue,这可能导致错误结果。因此,新的建议是使用 ValueStateDescriptor(String, TypeInformation) 构造方法,并手动检查状态是否为 null,以确保正确性。请注意,尽管新的构造方法需要手动检查默认值,但它提供了更好的可控性和灵活性,可以避免由于状态不一致导致的错误结果。建议您尽可能地使用新的构造方法,并根据具体情况进行适当的调整。
对以上案例,可以简化为只使用Integer类型的ValueState,统计年龄总和。
时间策略
Processing Time:事件被处理时机器的系统时间
Event Time:事件自身的时间
Ingestion Time:事件进入 Flink 的时间(进入source时间)
/*老版本设置方式*/
/*目前已经不需要以下方式指定,不设置事件时间与watermark,即系统时间,设置后为事件时间*/
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 其他两种:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
设置事件时间与水印生成:
/*** 使用事件时间,watermark案例* 数据格式:2023-12-14 08:30:12 - INFO 用户登录成功,用户名:JohnDoe*/
DataStream<String> processedLogStream = logStream.assignTimestampsAndWatermarks(getLogWatermarkStrategy()).map(log -> "Processed log: " + log);/*** 获取日志数据的 WatermarkStrategy,用于生成水印和指定事件时间。*/
private static WatermarkStrategy<String> getLogWatermarkStrategy() {return WatermarkStrategy// 最大乱序程度为 3 秒的水印策略.<String>forBoundedOutOfOrderness(Duration.ofSeconds(3))// 提供自定义的时间戳分配器.withTimestampAssigner((log, timestamp) -> {// 提取事件时间SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");Date eventTime;try {eventTime = format.parse(log.substring(0, 19));} catch (ParseException e) {throw new RuntimeException("Unable to parse event time from log: " + log, e);}return eventTime.getTime();});
}
作者与版本更新计划
关注公众号【数舟】,获取作者最新动态。

目前版本为v1.0,更新时间2024年10月22日。
后续此文档更新与版本发布会同步到知识星球【数舟】中。加入数舟,两倍咖啡的价格获取企业大数据实战经验。
知识整理与创作不易,感谢大家理解与支持!
