Redis学习文档(Redis基本数据类型【Hash、Set】)
Hash(哈希)
介绍
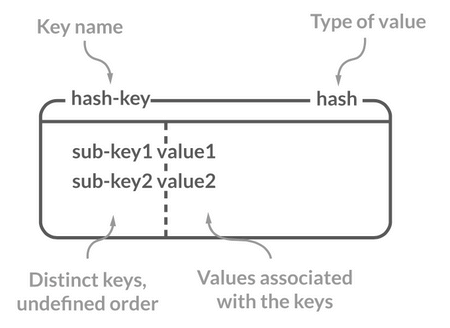
Redis 中的 Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。
Hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 Hash 做了更多优化。
常用命令
| 命令 | 介绍 |
|---|---|
| HSET key field value | 设置指定哈希表中指定字段的值 |
| HSETNX key field value | 只有指定字段不存在时设置指定字段的值 |
| HMSET key field1 value1 field2 value2 ... | 同时将一个或多个 field-value (域-值)对设置到指定哈希表中 |
| HGET key field | 获取指定哈希表中指定字段的值 |
| HMGET key field1 field2 ... | 获取指定哈希表中一个或者多个指定字段的值 |
| HGETALL key | 获取指定哈希表中所有的键值对 |
| HEXISTS key field | 查看指定哈希表中指定的字段是否存在 |
| HDEL key field1 field2 ... | 删除一个或多个哈希表字段 |
| HLEN key | 获取指定哈希表中字段的数量 |
| HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
模拟对象数据存储:
> HMSET userInfoKey name "guide" description "dev" age 24
OK
> HEXISTS userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
(integer) 1
> HGET userInfoKey name # 获取存储在哈希表中指定字段的值。
"guide"
> HGET userInfoKey age
"24"
> HGETALL userInfoKey # 获取在哈希表中指定 key 的所有字段和值
1) "name"
2) "guide"
3) "description"
4) "dev"
5) "age"
6) "24"
> HSET userInfoKey name "GuideGeGe"
> HGET userInfoKey name
"GuideGeGe"
> HINCRBY userInfoKey age 2
(integer) 26应用场景
对象数据存储场景
- 举例:用户信息、商品信息、文章信息、购物车信息。
- 相关命令:
HSET(设置单个字段的值)、HMSET(设置多个字段的值)、HGET(获取单个字段的值)、HMGET(获取多个字段的值)。
Set(集合)
介绍
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程

常用命令
| 命令 | 介绍 |
|---|---|
| SADD key member1 member2 ... | 向指定集合添加一个或多个元素 |
| SMEMBERS key | 获取指定集合中的所有元素 |
| SCARD key | 获取指定集合的元素数量 |
| SISMEMBER key member | 判断指定元素是否在指定集合中 |
| SINTER key1 key2 ... | 获取给定所有集合的交集 |
| SINTERSTORE destination key1 key2 ... | 将给定所有集合的交集存储在 destination 中 |
| SUNION key1 key2 ... | 获取给定所有集合的并集 |
| SUNIONSTORE destination key1 key2 ... | 将给定所有集合的并集存储在 destination 中 |
| SDIFF key1 key2 ... | 获取给定所有集合的差集 |
| SDIFFSTORE destination key1 key2 ... | 将给定所有集合的差集存储在 destination 中 |
| SPOP key count | 随机移除并获取指定集合中一个或多个元素 |
| SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
基本操作:
> SADD mySet value1 value2
(integer) 2
> SADD mySet value1 # 不允许有重复元素,因此添加失败
(integer) 0
> SMEMBERS mySet
1) "value1"
2) "value2"
> SCARD mySet
(integer) 2
> SISMEMBER mySet value1
(integer) 1
> SADD mySet2 value2 value3
(integer) 2mySet:value1、value2。mySet2:value2、value3。
求交集:
> SINTERSTORE mySet3 mySet mySet2
(integer) 1
> SMEMBERS mySet3
1) "value2"求并集:
> SUNION mySet mySet2
1) "value3"
2) "value2"
3) "value1"求差集:
> SDIFF mySet mySet2 # 差集是由所有属于 mySet 但不属于 A 的元素组成的集合
1) "value1"应用场景
需要存放的数据不能重复的场景
- 举例:网站 UV 统计(数据量巨大的场景还是
HyperLogLog更适合一些)、文章点赞、动态点赞等场景。 - 相关命令:
SCARD(获取集合数量) 。

需要获取多个数据源交集、并集和差集的场景
- 举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
- 相关命令:
SINTER(交集)、SINTERSTORE(交集)、SUNION(并集)、SUNIONSTORE(并集)、SDIFF(差集)、SDIFFSTORE(差集)。
需要随机获取数据源中的元素的场景
- 举例:抽奖系统、随机点名等场景。
- 相关命令:
SPOP(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、SRANDMEMBER(随机获取集合中的元素,适合允许重复中奖的场景