算法题总结(二十)——并查集
并查集理论基础
并查集常用来解决集合连通性问题,两个节点在不在一个集合,也可以将两个节点添加到一个集合中。
大白话就是当我们需要判断两个元素是否在同一个集合里的时候,我们就要想到用并查集。
并查集主要有两个功能:
- 将两个元素添加到一个集合中。
- 判断两个元素在不在同一个集合
路径压缩
如果这棵多叉树高度很深的话,每次find函数 去寻找跟的过程就要递归很多次。
我们的目的只需要知道这些节点在同一个根下就可以,所以对这棵多叉树的构造只需要这样就可以了,如图:

代码模板
int[] father =new int[n];
//初始化
public void init()
{for(int i=0;i<father.length;i++){father[i]=i; //每个元素单独一个集合}
}
//寻根
public int find(int u)
{
return father[u]==u? u: find(father[u]); //因为根节点的father[u]是等于u的}
//判断是否是同一个集合
public boolean isSame(int u,int v)
{return find(u)==find(v); //判断根是否一样
}
//加入
public void join(int u,int v)
{u=find(u); //寻找u的根v=find(v); //寻找v的根if(u==v) return;father[v]=u; //把v的根挂到u的根下面
}
通过模板,我们可以知道,并查集主要有三个功能。
- 寻找根节点,函数:find(int u),也就是判断这个节点的祖先节点是哪个
- 将两个节点接入到同一个集合,函数:join(int u, int v),将两个节点连在同一个根节点上
- 判断两个节点是否在同一个集合,函数:isSame(int u, int v),就是判断两个节点是不是同一个根节点
复杂度分析
这里对路径压缩版并查集来做分析。
空间复杂度: O(n) ,申请一个father数组。
路径压缩后的并查集时间复杂度在O(logn)与O(1)之间,且随着查询或者合并操作的增加,时间复杂度会越来越趋于O(1)。
了解到这个程度对于求职面试来说就够了。
在第一次查询的时候,相当于是n叉树上从叶子节点到根节点的查询过程,时间复杂度是logn,但路径压缩后,后面的查询操作都是O(1),而 join 函数 和 isSame函数 里涉及的查询操作也是一样的过程。
1971、寻找图中是否存在路径
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] = [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接,并且没有顶点存在与自身相连的边。
请你确定是否存在从顶点 source 开始,到顶点 destination 结束的 有效路径 。
给你数组 edges 和整数 n、source 和 destination,如果从 source 到 destination 存在 有效路径 ,则返回 true,否则返回 false 。
示例 1:

输入:n = 3, edges = [[0,1],[1,2],[2,0]], source = 0, destination = 2
输出:true
解释:存在由顶点 0 到顶点 2 的路径:
- 0 → 1 → 2
- 0 → 2
示例 2:

输入:n = 6, edges = [[0,1],[0,2],[3,5],[5,4],[4,3]], source = 0, destination = 5
输出:false
解释:不存在由顶点 0 到顶点 5 的路径.
为什么说这道题目是并查集基础题目,题目中各个点是双向图链接,那么判断 一个顶点到另一个顶点有没有有效路径其实就是看这两个顶点是否在同一个集合里。
使用join(int u, int v)将每条边加入到并查集。
最后 isSame(int u, int v) 判断是否是同一个根 就可以了。
可以把father数据理解为指向父节点的指针。
给出了一个边的数组,一个边对应着两个结点。
class Solution {int[] father;public boolean validPath(int n, int[][] edges, int source, int destination) {father=new int[n];init(); //初始化for(int i=0;i<edges.length;i++){join(edges[i][0],edges[i][1]); }return isSame(source,destination);}//初始化public void init(){for(int i=0;i<father.length;i++){father[i]=i; //每个元素单独一个集合}}//寻根public int find(int u){return father[u]==u? u: find(father[u]); //因为根节点的father[u]是等于u的}//判断是否是同一个集合public boolean isSame(int u,int v){return find(u)==find(v); //判断根是否一样}//加入public void join(int u,int v){u=find(u); //寻找u的根v=find(v); //寻找v的根if(u==v) return;father[v]=u; //把v的根挂到u的根下面 }
}
684、冗余连接
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:
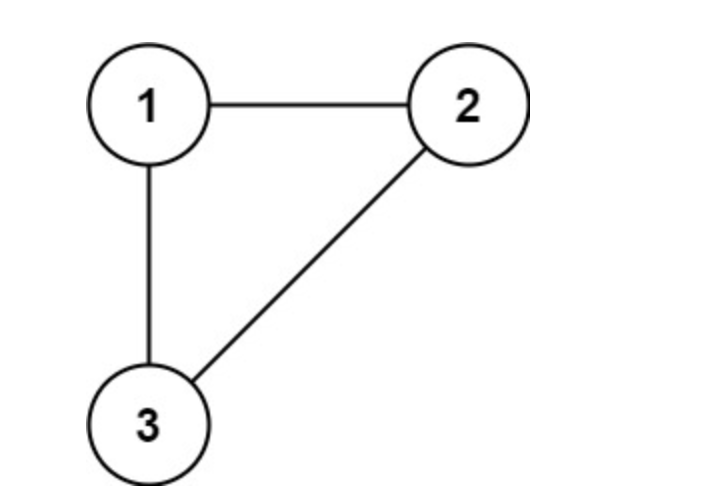
输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
题目说是无向图,返回一条可以删去的边,使得结果图是一个有着N个节点的树(即:只有一个根节点)。
如果有多个答案,则返回二维数组中最后出现的边。
那么我们就可以从前向后遍历每一条边(因为优先让前面的边连上),边的两个节点如果不在同一个集合,就加入集合(即:同一个根节点)。如果边的两个节点已经出现在同一个集合里,说明边的两个节点已经连在一起了,再加入这条边一定就出现环了,所以要把这条边删去。因为从前往后,优先把前面的边连上,所以删除的一定是最后可行的结果,如果要求删除最前面出现的边,那么从后向前遍历即可。
一定不要忘记初始化,否则father都是0,都会判定为同一个集合
class Solution {int[] father=new int[1005];public int[] findRedundantConnection(int[][] edges) {init(); //一定不要忘记初始化,否则father都是0,都会判定为同一个集合for(int i=0;i<edges.length;i++){//在一个集合了,就不能加入了if(isSame(edges[i][0],edges[i][1])) return edges[i];else //说明没有在一个集合,就合并join(edges[i][0],edges[i][1]); //说明没有在一个集合,就合并}return null;}//初始化public void init(){for(int i=0;i<father.length;i++){father[i]=i;}}//寻根public int find(int u){ return father[u]==u? u:find(father[u]); //因为根节点的father[u]是等于u的}//判断是否在通一个集合public boolean isSame(int v,int u){return find(u)==find(v);}//合并public void join(int u,int v){u=find(u);v=find(v);if(u==v)return;father[v]=u;}}
685、冗余连接 II
在本问题中,有根树指满足以下条件的 有向 图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。
输入一个有向图,该图由一个有着 n 个节点(节点值不重复,从 1 到 n)的树及一条附加的有向边构成。附加的边包含在 1 到 n 中的两个不同顶点间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组 edges 。 每个元素是一对 [ui, vi],用以表示 有向 图中连接顶点 ui 和顶点 vi 的边,其中 ui 是 vi 的一个父节点。
返回一条能删除的边,使得剩下的图是有 n 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
示例 1:

输入:edges = [[1,2],[1,3],[2,3]]
输出:[2,3]
示例 2:
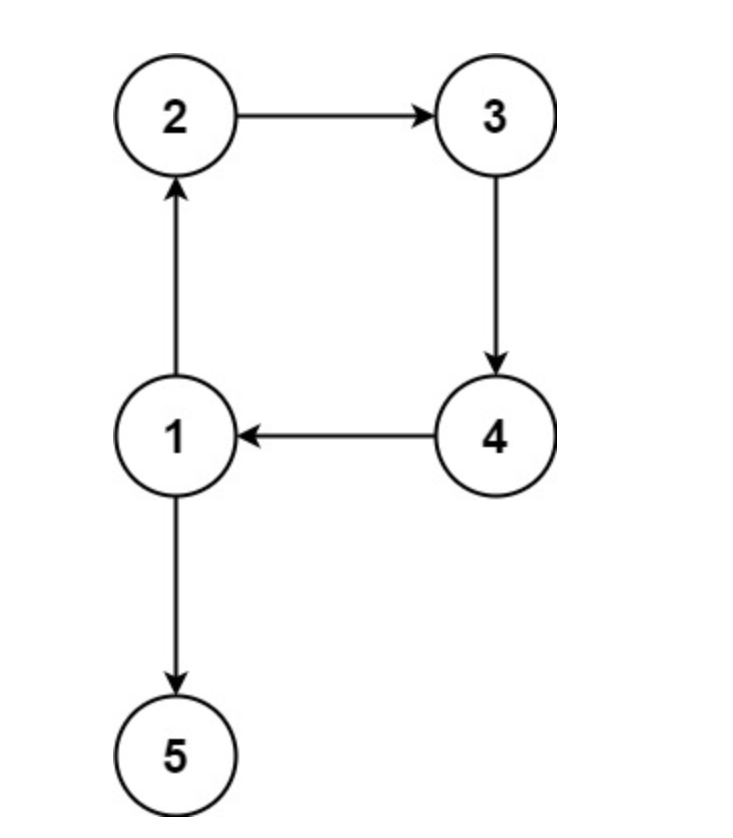
输入:edges = [[1,2],[2,3],[3,4],[4,1],[1,5]]
输出:[4,1]
先重点读懂题目中的这句该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
这说明题目中的图原本是是一棵树,只不过在不增加节点的情况下多加了一条边!
因为原来是树,所以增加一条边后,要么出现入度为2的结点,要么出现了环。
那么有如下三种情况,前两种情况是出现入度为2的点,如图:
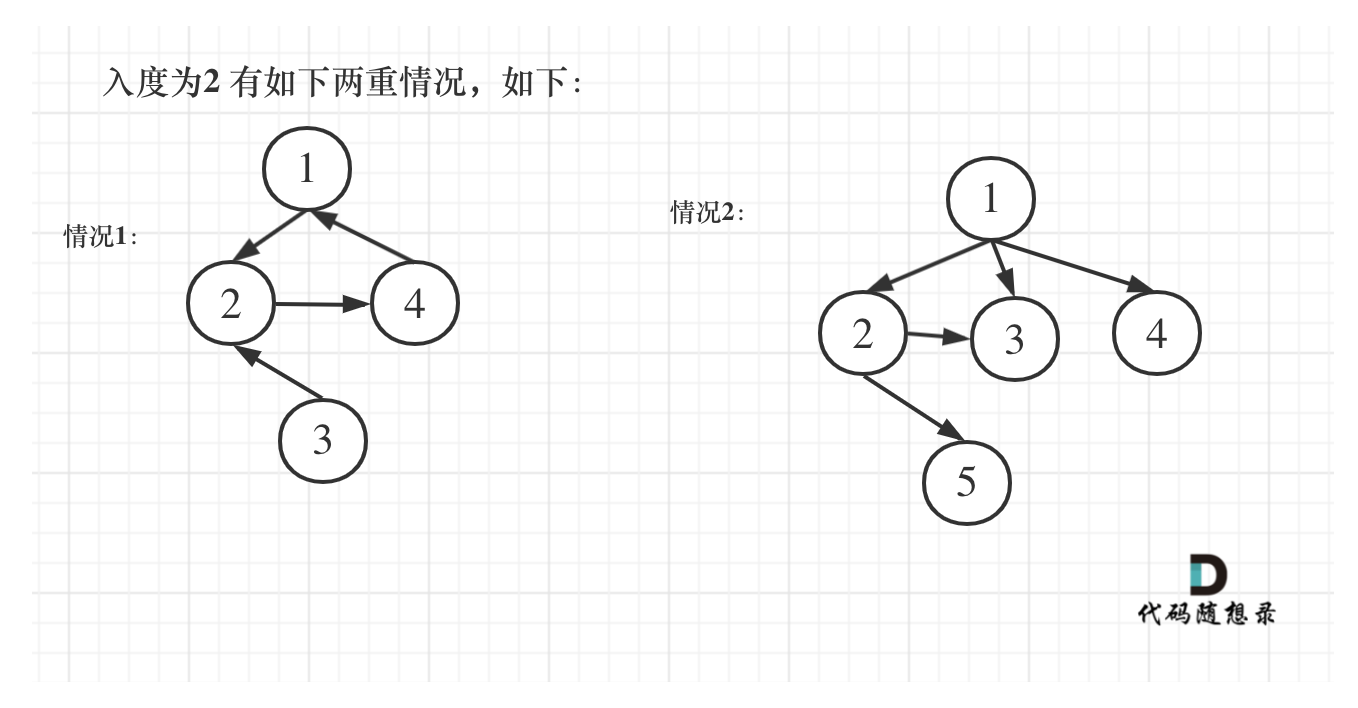
且只有一个节点入度为2,为什么不看出度呢,出度没有意义,一棵树中随便一个父节点就有多个出度。
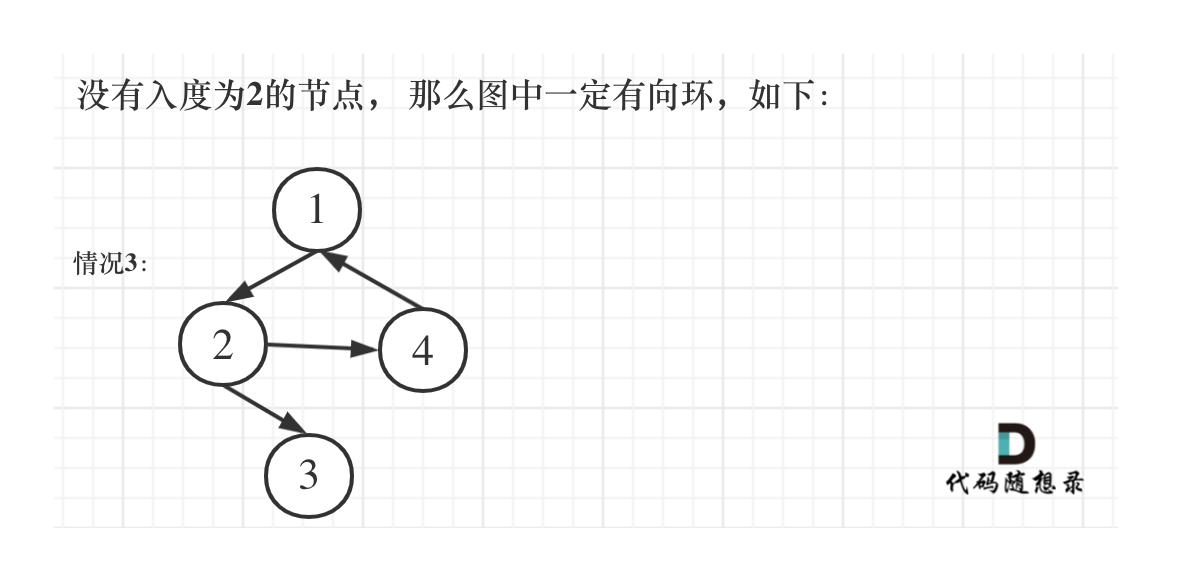
第三种情况是没有入度为2的点,那么图中一定出现了有向环(注意这里强调是有向环!)
如图:
前两种入度为2的情况,一定是删除指向入度为2的节点的两条边其中的一条,如果删了一条,判断这个图是一个树,那么这条边就是答案,同时注意要从后向前遍历,因为如果两条边删哪一条都可以成为树,就删最后那一条。
然后要实现的两个函数
- isTreeAfterRemoveEdge() 判断删一个边之后是不是树了
- getRemoveEdge 确定图中一定有了有向环,那么要找到需要删除的那条边
class Solution {int[] father=new int[1005];public int[] findRedundantDirectedConnection(int[][] edges) {int[] inDegree = new int[1005]; //存储每个结点的入度for(int i = 0; i < edges.length; i++){// 入度inDegree[ edges[i][1] ] += 1;}// 找入度为2的节点所对应的边,注意要倒序,因为优先返回删除最后出现在二维数组中的答案ArrayList<Integer> twoDegree = new ArrayList<Integer>(); //入度为2的节点所对应的边的位置序号for(int i = edges.length - 1; i >= 0; i--){if(inDegree[edges[i][1]] == 2) {twoDegree.add(i);}}// 处理图中情况1 和 情况2// 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树if(!twoDegree.isEmpty()){if(isTreeAfterRemoveEdge(edges, twoDegree.get(0))) {return edges[ twoDegree.get(0)];}return edges[ twoDegree.get(1)];}// 明确没有入度为2的情况,那么一定有有向环,找到构成环的边返回就可以了return getRemoveEdge(edges);}//删除一条边之后判断是不是树//不考虑删除的边,利用并查集判断有没有环,没有环就是树public boolean isTreeAfterRemoveEdge(int[][] edges,int deleteEdge){init();for(int i=0;i<edges.length;i++){if(i==deleteEdge) continue; //把要删除的边删除if(isSame(edges[i][0],edges[i][1])) //说明构成环了return false;elsejoin(edges[i][0],edges[i][1]);}return true;}//情况三:出现了环,找到要删除的边,因为是要删除后面的边,从前向后遍历//在有向图中找到删除的边,使其变成树public int[] getRemoveEdge(int[][] edges){init();for(int i=0;i<edges.length;i++){if(isSame(edges[i][0],edges[i][1])) //构成有向环了return edges[i];elsejoin(edges[i][0],edges[i][1]);}return null;}//初始化public void init(){for(int i=0;i<father.length;i++){father[i]=i;}}//寻根public int find(int u){ return father[u]==u? u:find(father[u]);}//判断是否在通一个集合public boolean isSame(int v,int u){return find(u)==find(v);}//合并public void join(int u,int v){u=find(u);v=find(v);if(u==v)return;father[v]=u;}
}
994、腐烂的橘子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值 0 代表空单元格;
- 值 1 代表新鲜橘子;
- 值 2 代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 __-1 。
示例 1:
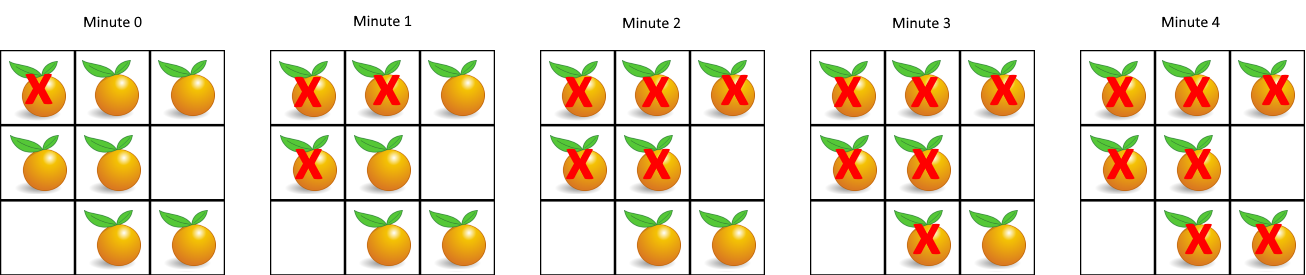
输入:grid = [[2,1,1],[1,1,0],[0,1,1]]
输出:4
示例 2:
输入:grid = [[2,1,1],[0,1,1],[1,0,1]]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
是这些被腐烂的橘子再向外拓展腐烂相邻的新鲜橘子,这与广度优先搜索的过程均一一对应,上下左右相邻的新鲜橘子就是该腐烂橘子尝试访问的同一层的节点,路径长度就是新鲜橘子被腐烂的时间。
我们记录下每个新鲜橘子被腐烂的时间,最后如果单元格中没有新鲜橘子,腐烂所有新鲜橘子所必须经过的最小分钟数就是新鲜橘子被腐烂的时间的最大值。
思路
- 一开始,我们找出所有腐烂的橘子,将它们放入队列,作为第 0 层的结点。
- 然后进行 BFS 遍历,每个结点的相邻结点可能是上、下、左、右四个方向的结点,注意判断结点位于网格边界的特殊情况。
- 由于可能存在无法被污染的橘子,我们需要记录新鲜橘子的数量。在 BFS 中,每遍历到一个橘子(污染了一个橘子),就将新鲜橘子的数量减一。如果 BFS 结束后这个数量仍未减为零,说明存在无法被污染的橘子。
class Solution {public int orangesRotting(int[][] grid) {int[][] dir ={{0,1},{0,-1},{1,0},{-1,0}};int m=grid.length;int n=grid[0].length;int result=0; //记录所需要的最小时间int count=0; //新鲜橘子的数目Queue<int[]> queue =new LinkedList<>(); //队列存储腐烂橘子的坐标//先统计新鲜橘子的个数,并把初始腐烂橘子入队for(int i=0;i<m;i++){for(int j=0;j<n;j++){if(grid[i][j]==1)count++;else if(grid[i][j]==2)queue.add(new int[]{i,j});}}while(count>0 && !queue.isEmpty()) { result++;int size=queue.size();for(int i=0;i<size;i++) //遍历队列中的所有腐烂的橘子{int[] orange=queue.poll();int x=orange[0];int y=orange[1]; for(int j=0;j<4;j++){int nx=x+dir[j][0];int ny=y+dir[j][1];if(nx<0 ||ny<0 ||nx>=m ||ny>=n)continue;if(grid[nx][ny]==1){count--;grid[nx][ny]=2;queue.add(new int[]{nx,ny});}}}}if(count>0) //腐烂的橘子周围都遍历完了return -1;elsereturn result;}
}
207、课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
解题思路:
class Solution {public boolean canFinish(int numCourses, int[][] prerequisites) {int[] indegrees = new int[numCourses]; //记录每个结点的入度 List<List<Integer>> list=new ArrayList<>(); //边表Queue<Integer> queue =new LinkedList<>(); //存储入度为0的顶点for(int i=0;i<numCourses;i++)list.add(new ArrayList<>()); //初始化每个顶点的边表for(int[] cp : prerequisites) //有前驱关系,即cp[1]指向cp[0]{indegrees[cp[0]]++;list.get(cp[1]).add(cp[0]);} //把入度为0的结点加入队列for(int i=0;i<numCourses;i++)if(indegrees[i]==0)queue.add(i);//拓扑排序while(!queue.isEmpty()){int pre =queue.poll();numCourses--; //把入度为0的结点移除for(int cur :list.get(pre)){indegrees[cur]--;if(indegrees[cur]==0)queue.add(cur);}}return numCourses==0;}
}
208、实现 Trie (前缀树)
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
- Trie() 初始化前缀树对象。
- void insert(String word) 向前缀树中插入字符串 word 。
- boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
- boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
示例:
输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
class TrieNode { // 节点boolean isWord; // 从root根节点至此是否是一个完整的单词(即这个节点是否是一个单词的结尾) TrieNode[] children = new TrieNode[26]; // 巧妙的用数组的下标作为26个字母;数组的值则为子节点
}class Trie {TrieNode root; // 根节点public Trie() {root = new TrieNode(); // 构造字典树,就是先构造出一个空的根节点}//【向字典树插入单词word】// 思路:按照word的字符,从根节点开始,一直向下走:// 如果遇到null,就new出新节点;如果节点已经存在,cur顺着往下走就可以public void insert(String word) {TrieNode cur = root; //先指向根节点for(int i=0;i<word.length();i++) //如果是【后缀树】而不是【前缀树】,把单词倒着插就可以了,即for(len-1; 0; i--){int c=word.charAt(i)-'a';if(cur.children[c]==null) cur.children[c]=new TrieNode();cur=cur.children[c];}cur.isWord=true; // 一个单词插入完毕,此时cur指向的节点即为一个单词的结尾}//【判断一个单词word是否完整存在于字典树中】// 思路:cur从根节点开始,按照word的字符一直尝试向下走://如果走到了null,说明这个word不是前缀树的任何一条路径,返回false;//如果按照word顺利的走完,就要判断此时cur是否为单词尾端:如果是,返回true;//如果不是,说明word仅仅是一个前缀,并不完整,返回falsepublic boolean search(String word) {TrieNode cur = root; for(int i=0;i<word.length();i++) {int c=word.charAt(i)-'a';if(cur.children[c]==null) return false;cur=cur.children[c];}return cur.isWord; //顺利走完,判断是不是一个单词的结尾}//【判断一个单词word是否是字典树中的前缀】// 思路:和sesrch方法一样,根据word从根节点开始一直尝试向下走://如果遇到null了,说明这个word不是前缀树的任何一条路径,返回false;//如果安全走完了,直接返回true就行了———我们并不关心此事cur是不是末尾(isWord)public boolean startsWith(String prefix) {TrieNode cur = root; for(int i=0;i<prefix.length();i++) {int c=prefix.charAt(i)-'a';if(cur.children[c]==null) return false;cur=cur.children[c];}return true; //顺利走完,就说明是一个前缀}
}
820、 单词的压缩编码
单词数组 words 的 有效编码 由任意助记字符串 s 和下标数组 indices 组成,且满足:
- words.length == indices.length
- 助记字符串 s 以 ‘#’ 字符结尾
- 对于每个下标 indices[i] ,s 的一个从 indices[i] 开始、到下一个 ‘#’ 字符结束(但不包括 ‘#’)的 子字符串 恰好与 words[i] 相等
给你一个单词数组 words ,返回成功对 words 进行编码的最小助记字符串 s 的长度 。
示例 1:
输入:words = ["time", "me", "bell"]
输出:10
解释:一组有效编码为 s = "time#bell#" 和 indices = [0, 2, 5] 。
words[0] = "time" ,s 开始于 indices[0] = 0 到下一个 '#' 结束的子字符串,如加粗部分所示 "time#bell#"
words[1] = "me" ,s 开始于 indices[1] = 2 到下一个 '#' 结束的子字符串,如加粗部分所示 "time#bell#"
words[2] = "bell" ,s 开始于 indices[2] = 5 到下一个 '#' 结束的子字符串,如加粗部分所示 "time#bell#"
示例 2:
输入:words = ["t"]
输出:2
解释:一组有效编码为 s = "t#" 和 indices = [0] 。
/*【字典树】——— 之所以想到使用字典树,是因为该题完全发挥了字符串的后缀特征我们构造出这样的一个[逆序]字典树,很容易发现: "编码"后的字符串长度,就是忽略了后缀单词后,所有单词的(长度+1)之和这不难理解,比如"abcd#","bcd","cd","d"这种后缀单词就默认被包括了,因而算整个字符串的长度时,算"abcd"这个最长的就行了核心思路是:每次往字典树插入一个"新的word"时,就 += 该word的长度 + 1(#)需要注意的是,不是每一次插入单词,都需要加上该单词的长度而是先根据长度对words进行一次排序,先插入长的,再插入短的。如果插入时需要new出新节点,我们就认为这是一个"新word"举几个例子:1. 先插"cba",再插"dba" ———— 虽然后缀有重合,但是依旧需要new出新节点,认为是"新word",最终字符串只能为"cba#dba#"2. 先插"ba",再插"dcba" ———— 两次插入都有new出新节点的行为,因此算多了,3+1 + 5+1 =8,实际为"dcba#",为53. 先插"dcba",再插"ba" ———— 因为先插长的,第二次插入并没有出现new的行为,4+1 = 5,正确 ! ! !*/
class Solution {public int minimumLengthEncoding(String[] words) {int result=0;Arrays.sort(words,(s1,s2)->s2.length()-s1.length());Trie trie =new Trie();for(String word:words){result+=trie.insert(word);}return result;}
}class TrieNode{boolean isWord;TrieNode[] children =new TrieNode[26];
}class Trie{TrieNode root;public Trie(){root=new TrieNode();}public int insert(String word){TrieNode cur =root;boolean isNew=false;// 单词逆序插入字典树;插入的同时,//还会判断插入的单词是不是"新的",如果是新单词,返回其length+1;否则返回0for(int i=word.length()-1;i>=0;i--){int c=word.charAt(i)-'a';if(cur.children[c]==null){cur.children[c]=new TrieNode();isNew=true; //如果出现new出新节点的行为,则认为是"新word"}cur=cur.children[c];}cur.isWord=true;return isNew?word.length()+1:0;}}