力扣hot100--链表
目录
链表
1. 2. 两数相加
2. 19. 删除链表的倒数第 N 个结点
3. 21. 合并两个有序链表
4. 23. 合并 K 个升序链表
5. 141. 环形链表
6. 142. 环形链表 II
7.148. 排序链表
8. 160. 相交链表
链表
1. 2. 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:

输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0] 输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9] 输出:[8,9,9,9,0,0,0,1]
提示:
- 每个链表中的节点数在范围
[1, 100]内 0 <= Node.val <= 9- 题目数据保证列表表示的数字不含前导零
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {int t = 0; // 初始化进位为0ListNode *dummy = new ListNode(0); // 创建一个哑节点,初始值为0ListNode* cur = dummy; // 使用指针 cur 指向 dummy// 当 l1 或 l2 不为空时循环while (l1 || l2) {if (l1) {t += l1->val; // 将 l1 的值加到 t 上l1 = l1->next; // 移动到 l1 的下一个节点}if (l2) {t += l2->val; // 将 l2 的值加到 t 上l2 = l2->next; // 移动到 l2 的下一个节点}cur->next = new ListNode(t % 10); // 创建一个新节点,值为 t 的个位数cur = cur->next; // 移动到新创建的节点t = t / 10; // 更新 t 为进位数}// 如果还有进位,创建一个新节点存储进位数if (t) {cur->next = new ListNode(t);}return dummy->next; // 返回结果链表的头节点(跳过哑节点)}
};2. 19. 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
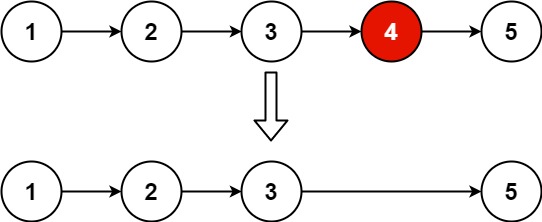
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1 输出:[]
示例 3:
输入:head = [1,2], n = 1 输出:[1]
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
// 链表+数学计算
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {int count{};// 删除倒数第n个,即删除第count-n+1ListNode* cNode = head;while(cNode != nullptr){cNode = cNode->next;count++;}ListNode *cNodeX = new ListNode(0);cNodeX->next = head;count = count - n +1;ListNode *node = cNodeX;while(count--){if(0 == count){node->next = node->next->next;break;}node = node->next;}return cNodeX->next;}
};
3. 21. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = [] 输出:[]
示例 3:
输入:l1 = [], l2 = [0] 输出:[0]
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
// 链表 + 递归/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {// 如果 list1 为空,则直接返回 list2,因为没有节点可合并if (!list1) return list2;// 如果 list2 为空,则直接返回 list1,因为没有节点可合并if (!list2) return list1;// 定义一个指针 node,作为合并后的链表头节点ListNode* node;// 比较 list1 和 list2 的当前节点的值,将较小的值加入到合并后的链表中if (list1->val < list2->val) {// 如果 list1 的当前值小于 list2 的当前值,则选择 list1 的节点node = list1;// 继续递归合并 list1 的下一个节点和 list2,设置为 node 的下一个节点list1 = list1->next;} else {// 如果 list2 的当前值小于或等于 list1 的当前值,则选择 list2 的节点node = list2;// 继续递归合并 list2 的下一个节点和 list1,设置为 node 的下一个节点list2 = list2->next;}// 将选中的节点的 next 指针设置为剩余节点递归合并的结果node->next = mergeTwoLists(list1, list2);// 返回合并后的链表头节点return node;}
};
4. 23. 合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [1->4->5,1->3->4,2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
示例 2:
输入:lists = [] 输出:[]
示例 3:
输入:lists = [[]] 输出:[]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
// 链表/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:// 方法 1:合并两个有序链表ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if (!list1) return list2; // 如果 list1 为空,返回 list2if (!list2) return list1; // 如果 list2 为空,返回 list1// 创建一个虚拟头节点,便于操作ListNode* node = new ListNode(0);ListNode* tail = node;// 遍历 list1 和 list2,合并两个链表while (list1 && list2) {if (list1->val < list2->val) {tail->next = list1; // 将 list1 的当前节点接入合并链表list1 = list1->next; // 移动 list1 指针到下一个节点} else {tail->next = list2; // 将 list2 的当前节点接入合并链表list2 = list2->next; // 移动 list2 指针到下一个节点}tail = tail->next; // 移动合并链表的尾节点}// 将剩余的链表部分直接连接到合并链表的尾部tail->next = list1 ? list1 : list2;// 返回合并后的链表头节点(去除虚拟头节点)return node->next;}// 方法 2:合并多个链表ListNode* mergeKLists(vector<ListNode*>& lists) {int k = lists.size();ListNode* node{}; // 初始合并链表为空// 逐个合并链表for (int i = 0; i < k; ++i) {node = mergeTwoLists(node, lists[i]);}return node; // 返回最终合并后的链表头节点}
};
5. 141. 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
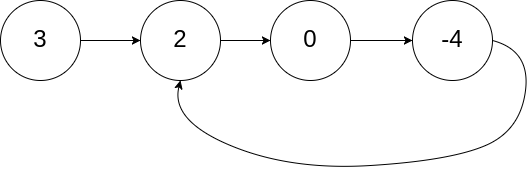
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
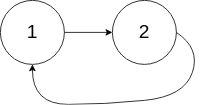
输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1 输出:false 解释:链表中没有环。
提示:
- 链表中节点的数目范围是
[0, 104] -105 <= Node.val <= 105pos为-1或者链表中的一个 有效索引 。
// 双指针方法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val; // 节点的值
* ListNode *next; // 指向下一个节点的指针
* ListNode(int x) : val(x), next(NULL) {} // 构造函数
* };
*/
class Solution {
public:
// 方法:检查链表是否有环
bool hasCycle(ListNode *head) {
ListNode *slow = head; // 慢指针,初始指向链表头
ListNode *fast = head; // 快指针,初始指向链表头// 当快指针和快指针的下一个节点存在时,继续循环
while(fast && fast->next){
slow = slow->next; // 慢指针每次移动一步
fast = fast->next->next; // 快指针每次移动两步// 如果慢指针和快指针相遇,说明链表中存在环
if(slow == fast){
return true; // 有环,返回true
}
}return false; // 无环,返回false
}
};
解释:
- 慢指针和快指针:慢指针每次移动一步,而快指针每次移动两步。如果链表中有环,快指针最终会追上慢指针。
- 循环条件:在
while循环中,我们确保快指针和快指针的下一个节点都不为空,以避免访问空指针。 - 相遇检测:如果在某个时刻,慢指针和快指针相遇,则说明链表中存在环。返回
true。 - 无环返回:如果快指针到达链表的末尾,说明链表没有环,返回
false。
6. 142. 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
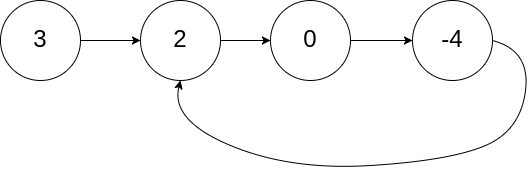
输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
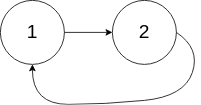
输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -105 <= Node.val <= 105pos的值为-1或者链表中的一个有效索引
// 双指针 + 数学方法
// 核心:a = c + (n−1)(b + c) 的等量关系
// 我们会发现:从相遇点到入环点的距离加上 (n−1) 圈的环长,恰好等于从链表头部到入环点的距离
/**
* Definition for singly-linked list.
* struct ListNode {
* int val; // 节点的值
* ListNode *next; // 指向下一个节点的指针
* ListNode(int x) : val(x), next(NULL) {} // 构造函数
* };
*/
class Solution {
public:
// 方法:检测链表中的环并返回环的起始节点
ListNode *detectCycle(ListNode *head) {
// 检查链表是否为空或节点不足以形成环
if(!head || !head->next || !head->next->next) return {};ListNode* slow = head; // 慢指针,初始指向链表头
ListNode* fast = head; // 快指针,初始指向链表头// 使用快慢指针检测是否存在环
while(fast && fast->next) {
slow = slow->next; // 慢指针每次移动一步
fast = fast->next->next; // 快指针每次移动两步// 如果慢指针和快指针相遇,说明存在环
if(slow == fast) {
break; // 跳出循环
}
}// 如果慢指针没有与快指针相遇,则说明没有环
if(slow != fast) return {}; // 返回空指针// 从相遇点重新初始化慢指针到链表头部
slow = head;// 同时移动慢指针和快指针,直到相遇
while(slow != fast) {
slow = slow->next; // 慢指针每次移动一步
fast = fast->next; // 快指针每次移动一步
}// 返回相遇点,即环的起始节点
return slow;
}
};
解释:
- 检测环的存在:首先使用快慢指针方法检测链表中是否存在环。如果慢指针和快指针相遇,说明链表中有环。
- 重新定位慢指针:当检测到环时,将慢指针重新指向链表头部。
- 寻找环的起始节点:然后,慢指针和快指针同时向前移动,每次移动一步。它们会在环的起始节点相遇,因为从链表头到环的起始节点的距离与从相遇点到环的起始节点的距离是相等的。
- 返回环的起始节点:当两指针再次相遇时,返回这个节点,即为环的起始节点。
7.148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3] 输出:[1,2,3,4]
示例 2:
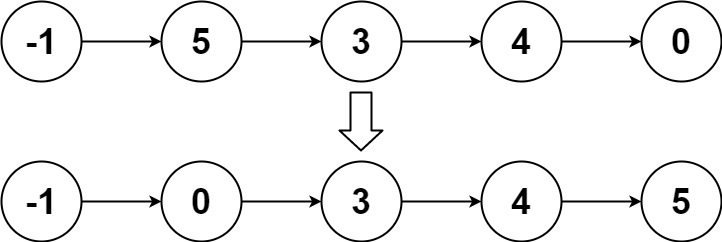
输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5]
示例 3:
输入:head = [] 输出:[]
提示:
- 链表中节点的数目在范围
[0, 5 * 104]内 -105 <= Node.val <= 105
// 链表节点的定义
/**
* Definition for singly-linked list.
* struct ListNode {
* int val; // 节点存储的值
* ListNode *next; // 指向下一个节点的指针
* ListNode() : val(0), next(nullptr) {} // 默认构造函数
* ListNode(int x) : val(x), next(nullptr) {} // 带值构造函数
* ListNode(int x, ListNode *next) : val(x), next(next) {} // 带值和下一个节点的构造函数
* };
*/class Solution {
public:
// 排序链表的主函数
ListNode* sortList(ListNode* head) {
vector<int> v; // 创建一个动态数组,用于存储链表节点的值ListNode* cur = head; // 初始化当前节点为链表的头节点
// 遍历链表,将每个节点的值存入动态数组
while(cur) {
v.push_back(cur->val); // 将当前节点的值加入数组
cur = cur->next; // 移动到下一个节点
}// 对动态数组中的值进行排序
sort(v.begin(), v.end());cur = head; // 重新初始化当前节点为链表的头节点
// 将排序后的值重新赋值给链表的节点
for(int i{}; i < v.size(); ++i) {
cur->val = v[i]; // 将排序后的值赋给当前节点
cur = cur->next; // 移动到下一个节点
}return head; // 返回排序后的链表头节点
}
};
该实现方法简单直观,但其时间复杂度为 O(nlogn)O(n \log n)O(nlogn)(排序部分)加上 O(n)O(n)O(n)(两次遍历链表),总的时间复杂度为 O(nlogn)O(n \log n)O(nlogn),空间复杂度为 O(n)O(n)O(n)(用于存储值的数组)。如果需要提高效率,可以考虑使用归并排序等其他算法。
归并排序如下:
class Solution {
public:
// 主函数,用于排序链表
ListNode* sortList(ListNode* head) {
// 基础情况:如果链表为空或只有一个节点,直接返回
if (!head || !head->next) return head;// 将链表分成两个部分
ListNode* mid = getMid(head); // 找到中间节点
ListNode* left = sortList(head); // 递归排序左半部分
ListNode* right = sortList(mid); // 递归排序右半部分// 合并两个已排序的部分并返回
return merge(left, right);
}private:
// 找到链表的中间节点
ListNode* getMid(ListNode* head) {
ListNode* slow = head; // 慢指针
ListNode* fast = head->next; // 快指针// 使用快慢指针法找到链表的中间节点
while (fast && fast->next) {
slow = slow->next; // 慢指针每次移动一步
fast = fast->next->next; // 快指针每次移动两步
}
ListNode* mid = slow->next; // 中间节点
slow->next = nullptr; // 切断链表,分成两部分
return mid; // 返回中间节点
}// 合并两个已排序的链表
ListNode* merge(ListNode* l1, ListNode* l2) {
ListNode dummy; // 创建一个虚拟节点作为合并链表的起始点
ListNode* tail = &dummy; // 尾指针,用于构建新的链表// 逐个比较两个链表的节点
while (l1 && l2) {
if (l1->val < l2->val) {
tail->next = l1; // 将较小的节点连接到新链表
l1 = l1->next; // 移动到下一个节点
} else {
tail->next = l2; // 将较小的节点连接到新链表
l2 = l2->next; // 移动到下一个节点
}
tail = tail->next; // 移动尾指针
}// 连接剩余的节点(如果有的话)
tail->next = l1 ? l1 : l2; // 追加剩余的节点
return dummy.next; // 返回合并后的链表
}
};
8. 160. 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
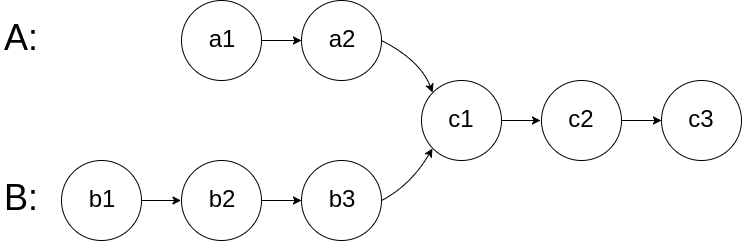
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
class Solution {
public:
// 函数用于找到两个单链表的交点
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
unordered_set<ListNode*> unS; // 创建一个哈希表,用于存储节点的指针// 遍历第一个链表,将节点指针存入哈希表
while(headA){
unS.insert(headA); // 将当前节点指针加入哈希表
headA = headA->next; // 移动到下一个节点
}// 遍历第二个链表,检查每个节点是否在哈希表中
while(headB){
// 如果当前节点在哈希表中,说明找到了交点,返回这个节点
if(unS.find(headB)!=unS.end()) return headB;
headB = headB->next; // 移动到下一个节点
}// 如果没有找到交点,返回空指针
return {};
}
};
解释:if(unS.find(headB)!=unS.end()) 这个条件判断的意思是:“如果 headB 这个节点的指针在哈希表 unS 中找到了对应的元素”,那么条件为真。如果 find 方法找到了 headB 这个指针,它会返回一个指向该元素的迭代器;如果没有找到,它会返回 end() 迭代器。因此,如果 find 的结果不等于 end(),说明 headB 已经在哈希表中了,这通常意味着 headB 是两个链表的交点,因为哈希表 unS 存储了第一个链表的所有节点指针。