【Python】的语言基础学习方法 快速掌握! 源码可分享!
python语言基础
第一章 你好python
1.1安装python
https://www.python.org/downloads/release/python-3104/

自定义安装,全选

配置python的安装路径

验证:cmd输入python

1.2python解释器

解释器主要做了两件事:
- 翻译代码
- 提交给计算机去运行
解释器就是这个python.exe

在命令提示符中的python,就是调用了这里的python.exe解释器
1.3pycharm安装
https://blog.csdn.net/weixin_59047731/article/details/135634418
https://www.jetbrains.com/pycharm/download/other.html
1.4pycharm基础使用
1.4.1更改主题

1.4.2更改字体大小
setting->Editor->font

设置增加的快捷键 ctrl+鼠标上滚轮,缩小输入decrease

1.4.3安装中文语言包

1.4.4安装翻译软件
输入translation

1.4.5常用快捷键


在方法上按住ctrl+p可以查看参数

第二章 python基础语法
2.1 字面量
字面量:被写下来的固定的值
6种值的类型

字符串:又称为文本,是由任意数量的字符如中文、英文、各类符号、数字等组成。所以叫做字符的串。(凡是被引号包围起来的,统统都是字符串)
2.2 注释
单行 #
多行 """ """
2.3 变量

2.4数据类型
type()
通过type(变量) 可以输出数据的类型,因为变量无11类型,但是他存储的数据有。

2.5 类型转换


2.6 标识符
大小写敏感
只能使用 中文 、数字 、下划线、英文字母。
不能以数字开头
不可使用关键字

变量命名
- 多个单词组合名,需要使用下划线做分割
- 英文字母全小写
2.7 算数运算符

除和整除的区别:除是小数,整除是取整
2.8字符串拓展
2.8.1 字符串的三种定义方式
可以使用三种定义:
- 单引号
- 双引号
- 三引号
引号嵌套:
- 可以使用:\ 来进行转义
- 单引号内可以写双引号,或者双引号内可以写单引号
2.8.2 字符串拼接
使用 “+”号连接字符串变量或者字符串字面量即可
其他类型不能使用加号和字符串拼接

2.8.3 字符串格式化
%s
- %表示:我要占位
- s 表示:将变量变成字符串放入占位的地方
多个变量占位,变量要用括号括起来,并且按照占位的顺序填入
2.8.4 格式化的精度控制
1.m.n
-
m 控制宽度,要求是数字(很少使用)
-
n控制小数点精度,会进行小数的四舍五入

2.f“{占位}
#f:format
print(f"我是{name},我的歌曲:{song},今年{age}")
2.8.5 对表达式进行格式化
表达式:一条具有明确执行结果的代码语句

2.9 数据输入
input()接收的所有类型都是字符串,如果你想转换为其他类型可以自行转换
第三章 python 判断语句
3.1布尔类型和逻辑运算符


3.2 if语句的基本格式
1.基本格式:
if 判断条件:条件成立要执行的语句
else:2.注意:
- 判断条件结果一定是bool类型
- 不要忘记判断条件后的:
- 归属于if语句的代码块,需要在前方填充4个空格缩进

3.3 if elif else语句的基本格式
-
if elif else 语句可以用来完成多个条件的判断
-
注意点:
elif可以写多个
判断是互斥并且有序的,上一个满足后面的就不会判断了
可以在条件判断中,直接写input语句,节省代码量
第四章 python 循环语句
4.1while循环的基础应用

4.2 while 循环的基础案例
添加一个end=’ ',可以不换行
print("world",end='')\t效果等同于在键盘上按下 tab键
打印九九乘法表
# 定义外层循环的控制变量
i = 1
while i<=9:# 控制里面每一行的内容输出j = 1while j<=i:print(f"{j}*{i}={j*i}\t",end='')# print("%d * %d=" %(j,i),j*i,"\t",end='')j+=1i+=1print("")4.3 for循环的基础使用
for 变量 in 被处理的数据同while循环不同,for循环是无法定义循环条件的
只能从被处理的数据集中,依次取出内容进行处理
4.4 range 语句
for循环语句本质上是遍历:序列类型
语法1:
range(num)获取一个从0开始,到num结束的数字序列,不包括num本身(默认从0开始)
比如range(5)取得的数据是[0,1,2,3,4]
语法2:
range(num1,num2)获取一个从num1开始到num2结束的数字序列,不包括num2本身
语法3:
range(num1,num2,step)获得一个从num1开始,到num2结束的数字序列(不包括num2本身),step默认为1
range(5,10,2)所取得的数据是:[5,7,9]

4.5 for循环的嵌套应用
打印99乘法表
for x in range(1,10):for y in range(1,x+1):print(f"{x}*{y} = {x*y}\t",end='')print("")4.6 continue关键字

continue关键字只可以控制他所在的循环临时中断
4.7 break关键字
break关键字可以用于直接结束循环,直接循环就全部结束
import random
money = 8000
for x in range(1,21):grade_point = random.randint(1,10)if grade_point<5:print(f"员工{x},绩效分{grade_point},低于5,不发工资,下一位")continueelse:if money <= 0:print("工资发完了,下个月吧")breakprint(f"向员工{x},发放工资1000元,账户余额还剩{money-1000}")money -= 1000第五章 python函数
5.1 函数基础用法
函数:可复用的代码段
函数的定义:
def 函数名(传入参数)函数体return 返回值函数的调用:
函数名(参数)注意:
- 参数和返回值可以省略
- 函数必须先定义后使用
变量可以接收函数的返回值:
变量 = 函数(参数)5.2 None类型
None:表示这个函数没有返回有意义的内容,就是返回空的意思
如果我们的函数没有使用return语句来返回数据:函数有返回值

1.可以用在函数无返回值上:
def say_hi():print("你好呀~")return None2.和if搭配:None在if判断中表示false的意思,故可以通过if去判断返回值
if not status:# 能够进入if表示status是none值print("未成年人 不可以进入网吧")3.用在无内容的变量上:定义了一个变量但是暂时不需要有具体值,可以用None来代替
name = None5.3 函数说明
在函数最开始的时候敲"""回车pycharm会自动生成
# 定义函数,进行文档说明
def add(x,y):"""add函数可以接收两个参数,进行两数相加的功能:param x:形参x表示相加的其中一个数字:param y:形参y表示相加的另一个数字:return:返回值是2数相加的和"""result = x+yreturn result在pycharm调用之后将鼠标悬停,可以看到相关的注释

5.4 嵌套调用
def func_b():print("---b---")def fun_abc():print("---a---")func_b()print("---c---")
fun_abc()5.5 函数的作用域
局部变量:作用范围定义在函数内部,在函数外部无法使用
全局变量:在函数的外部定义的变量,在函数的内部可以使用,在函数的外部也可以使用
可以通过global关键字将函数内定义的变量声明为全局变量
def test_a():print("test_a",{num})
def test_b():# 通过global关键字声明a是一个全局变量global numnum = 500 #局部变量print("test_b:",{num})
test_a()
test_b()
print(num)5.6 综合案例
银行ATM机
name = None
money = 100name = input("请输入您的名字:")def query(show_header):if show_header:print("--------------查询余额--------------")print(f"您好~{name}的余额剩余:{money}元")
def save(carry):global moneymoney = money + carryprint(f"存完了,你现在剩余余额为{money}")query(False)
def get_money(carry):global moneyflag = Truewhile flag:carry = int(input("请输入您要取的金额:"))if carry > money:print("钱不够,请修改余额")else:flag = Falsemoney = money - carryquery(False)
def show(name):outFlag = Truewhile outFlag:print("--------------主菜单--------------")print(f"你好~{name},欢迎来到ATM,请选择操作:")print("查询余额\t[输入1]")print("存款\t[输入2]")print("取款\t[输入3]")print("退出\t[输入4]")choice = int(input("请输入您的选择:"))if choice == 1:query(True)elif choice == 2:print("--------------存款--------------")carry = int(input("请输入您要存的金额:"))save(carry)elif choice ==3:print("--------------取款--------------")carry = Noneget_money(carry)elif choice == 4:print("--------------退出--------------")outFlag = Falseelse:print("您输入的数字不合法,请重新输入")
show(name)第六章 python数据容器
数据容器:一种可以存储多个元素的数据类型



6.1 列表list
6.1.1列表定义

6.1.2列表的下标索引

反向索引:

嵌套的列表:

6.1.3 列表的常用操作

1.列表的查询功能:
功能:查找指定元素在列表中的下标,如果找不到,报错ValueError
列表.index(元素)2.列表的修改
列表[元素下标] = 值3.插入元素
列表.insert(下标,元素)4.追加元素到尾部
列表.append(元素)5.追加一批元素
列表.extend(元素)6.删除元素
按照下标删除
-
语法1:
del 列表[下标] -
语法2:
列表.pop(下标)
按照元素的内容删除(只能删除第一个匹配项)
列表.remove()7.清空列表
列表.clear()8.统计列表中元素的数量
列表.count()9.统计列表中全部的元素数量
len(列表)6.1.4 列表的特点

6.1.5列表的遍历
可以使用while或者for循环
count = 0
list = ['a', 'b', 'c']
while count<len(list):print(list[count])count += 1
for x in range(len(list)):print(list[x])不同点:
- while比较自由,for只能一个个的从list里面取元素
- while可以无限循环,只要count每次不加1
- while通用,for适用于简单的想要遍历所有的元素和固定次数
6.2 元组tuple
元组可以看作是一个只读的list,不可修改
6.2.1元组的定义

定义单个元素的时候一定要在后面写上一个逗号,否则就不是元组了
6.2.2 元组的方法


6.3 字符串str
字符串是字符的容器,一个字符串可以存放任意数量的字符
6.3.1 字符串的常见方法

同其他容器一样,字符串可以通过下标访问
- 从前向后,下标从0开始
- 从后向前,下标从-1开始
字符串是一个不可修改的数据容器
1.查找某个字符串在这个字符串中的起始位置
字符串.index表示可以查找这个字符串起始字母所在位置
2.字符串的替换
可以将字符串1全部替换为字符串2,这里并不是修改字符串本身,而是得到了一个新的字符串
字符串.replace(字符串1,字符串2)3.字符串的分割
按照指定的分隔符字符串,将字符串划分为多个字符串,并存入到列表对象中。这里是字符串本身不变,得到了一个列表对象
字符串.split(分隔符字符串)4.字符串的规整操作(去掉前后空格)
- 不传入参数默认就是把头和尾的空格去除
字符串.strip()- 传入参数,就将其传入的参数划分为单个字母的小子串,然后首尾去除相应的内容
5.统计字符串中某个字符串出现的次数 count
字符串.count("所要统计的字符串")6.统计字符串的长度
len(字符串)6.3.2字符串 的特点

6.4数据容器的切片
6.4.1 序列的定义
序列:内容连续,有序,可以使用下标索引的一类数据容器
列表、元组、字符串都可以看作是序列
6.4.2 序列的常用操作
切片:从一个序列中,取出一个子序列
序列[起始下标:结束下标:步长]- 起始下标不写视作从头
- 结束下标(不含),可以留空,留空视作截取到结尾
- 步长:一次取元素的间隔大小
- 步长为1,一个个的取元素
- 步长为2,每次跳过1个元素取
- 步长为n,每次跳过n-1个元素取
- 步长为负数表示反向区
对序列进行切片操作并不会影响到序列本身,而是会得到一个新的序列。(因为元组和字符串都是不支持修改的)
my_list = [1, 2, 3, 4, 5]
new_my_list = my_list[::-1] # 等同于将数列反转了如果步长是负的,那么需要起始下标需要从尾部开始,终止下标需要从头部结束
my_str = ("123456")
new_my_str = my_str[6:1:-2]6.2.3 序列的案例
str1 = "万过薪月,员序程马黑来,nohtyP学"
# 倒序字符串 ,切片取出
newstr = str1[5:10:]
newstr2 = newstr[::-1]
print(newstr2)#切片取出 倒序
newstr3 = str1[::-1][9:14:1]
print(newstr3)#split分割 replace
newstr4 = str1.split(",")[1].replace("来",'')[::-1]
print(newstr4)6.5 集合set

6.5.1集合的定义


如果想定义一个空集合只能使用 set(),不能使用set={},这种写法被字典占用了
6.5.2集合的方法
因为集合是无序的,所以集合不支持:下标索引访问
但是集合和列表一样,是允许修改的

pop() 如果都是数字会自动排列 顺序,pop取的是0号元素。但是字符串是随机排列的
difference_update :消除两个集合的差集 调用者的集合被修改删掉了相同的元素
# 集合的遍历
# 集合不支持下标索引,不能用while循环
# 可以用for循环
set1 = {1,2,3,4,5,6,7,8,9}
for i in set1:print(i)6.5.3集合的特点

6.6 字典dict
6.6.1 字典的定义

注意事项:
- 字典中的key是不允许重复的,新的会将旧的覆盖掉
- key和value可以是任意类型
dict1 = {"周杰伦":"稻香","陶喆":"流沙","陈奕迅":"爱是一本书"}
print(dict1)
# 定义空字典
dict2 = dict()
dict3 = {}
# 定义重复的Key的字典
dict4 = {"周杰伦":"稻香","周杰伦":"流沙","陈奕迅":"爱是一本书"}
print(dict4)
print(dict1['周杰伦'])
# 定义嵌套字典
stu_score_dict={"小红":{"语文":99,"数学":100,"英语":98},"小王":{"语文": 100,"数学": 100,"英语": 100}
}
print(stu_score_dict['小王']['语文'])6.6.2 字典的方法

dict1 = {"周杰伦":"稻香","陶喆":"流沙","陈奕迅":"爱是一本书"}
# 新增
dict1["方大同"] = "三人行"
print(dict1)
# 更新元素
dict1["周杰伦"] = "暗号"
print(dict1)
# 删除元素 结果获得指定值的value
song = dict1.pop("周杰伦")
print(song)
print(dict1)
# 清空字典
dict1.clear()
print(dict1)
# 获取全部的key
dict2 = {"周杰伦":"稻香","陶喆":"流沙","陈奕迅":"爱是一本书"}
keys = dict2.keys()
print(keys)#遍历字典
# 方式1:通过获取到的全部的key来完成遍历
for key in keys:print(dict2[key])
# 方式2:直接对字典进行for循环,每一次循环都是直接得到key
for key in dict2:print(dict2[key])# 统计字典的元素数量
print(len(dict2))6.6.3 字典的特点

6.7 总结
数据容器的通用操作:
- 遍历
- 五类数据容器都支持for循环遍历
- 列表、元组、字符串都支持while循环,集合、字典不支持(无法下标索引)
- len(容器)
- max(容器)统计容器的最大元素
- min(容器) 统计容器的最小元素
- 类型转换

字典转其他,key保留,value舍弃

排序的结果会统统变为列表对象,将内容排序放入列表之中
reverse=True说明是降序

6.8 拓展 字符串大小比较


第七章 python 进阶
7.1函数
7.1.1函数的多返回值

7.1.2函数传参方式


关键字参数传参的时候可以不按照参数的定义顺序传参
位置参数和关键字参数混用的时候,位置参数必须在关键字参数的前面

设置默认值的时候,必须要统一的都在最后


"""
演示多种传参的形式
"""
# 位置参数 默认使用形式
def user_info(name,age,gender):print(f"姓名是{name},年龄是{age},性别是{gender}")
user_info("周杰伦",46,'男')# 关键字参数
user_info(name = '小王',age = 11,gender='女')
user_info(age = 11,name = '小丽',gender='女')
user_info('陶喆',age=100,gender='男')
# 缺省参数(默认值)
def user_info(name,age=20,gender='男'):print(f"姓名是{name},年龄是{age},性别是{gender}")
user_info("周杰伦",46,'男')
user_info("林俊杰")# 不定长 位置不定长 *号
# 不定长定义的形式参数会作为元组存在,接收不定长数量的参数传入
def user_info(*args):print(f"args参数的类型是:{type(args)} 内容是:{args}")
user_info("孙燕姿",'雨天',11)
# 不定长 关键字不定长 **号
def user_info(**kwargs):print(f"args参数的类型是:{type(kwargs)} 内容是:{kwargs}")
user_info(song="雨天",singer='孙燕姿')7.1.3 匿名函数
1.函数的传入形式
函数本身也可以作为参数传入到另一个函数内
普通的函数:数据不确定,具体的运算逻辑在函数体内写好了
函数的传入形式:被计算的数据是确定的,不确定的是计算数据的逻辑
def compute(x,y):return x+y
def funcompute(compute):result = compute(2,3)print(f"compute函数的类型是:{type(compute)}")print(result)
funcompute(compute)2.lambda匿名函数

lambda无法去写多行
def test_func(compute):result = compute(1,2)print(f"结果是{result}")
# 通过lambda匿名函数的形式,将匿名函数作为参数传入
test_func(lambda x,y:x+y)第八章 python文件操作
8.1文件的读取操作
1.open() 打开函数

mode常用的三种基础访问模式:
- r 以只读的方式打开文件,文件的指针会放在文件的开头。这是默认模式
- w 打开一个文件只用于写入,如果该文件已经存在则打开文件,并从开头开始编辑,原有的内容会被删除,如果该文件不存在,则创建新文件
- a 打开一个文件用于追加,如果这个文件已经存在,那么新的内容将会被写入到已有内容之后,如果这个文件不存在,创建新文件进行
TextIOWrapper是对文本文件进行IO操作功能的一个类
2.read()读操作

如果在程序中多次调用read,上一次read会在下一次read的结尾处接着读取



8.2 文件读取的小案例 统计字符
# 方式1
f = open("word.txt","r",encoding="utf-8")content = f.read()print(content)count = content.count("itheima")print(count)# 方式2
count = 0
for line in f:line = line.strip()words = line.split(" ")for word in words:if word == 'itheima':count = count + 1
print(count)
f.close()strip 可以去除字符串开头和结尾的空格以及换行符
8.3文件的写入操作

文件不存在w模式是帮你创建文件
当文件已经存在的时候,你再用write会将里面的内容全部清空
"""
演示文件的写入
"""
import time#打开文件,不存在的文件
f = open("test.txt","w",encoding="utf-8")
# write 写入
f.write("Hello World!") #将内容写入到内存中
# flush 刷新
#f.flush() # 将内存中积攒的东西,写入到硬盘的文件中# close 关闭
f.close() # close方法是内置了flush的功能# 打开一个存在的文件
f = open("test.txt","w",encoding="utf-8")
# write写入 flush刷新
f.write("柳絮飘")
# close 关闭
f.close()8.4 文件的追加操作

8.5 文件操作的综合案例
name,date,money,type,remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式将正式数据写入备份
"""
演示文件操作综合案例:文件备份
"""
f = open("bill.txt","r",encoding="utf-8")
f2 = open("bill.txt.bak","w",encoding="utf-8")
for line in f:newline = line.strip().split(',')print(newline)if newline[4] == "正式":f2.write(line)f2.write("\n")
f.close()
f2.close()第九章 python异常、模块与包
9.1 异常的捕获





# 基本捕获语法
try:f = open('test111.txt','r')
except:f = open('test.txt','w')
# 捕获指定的异常
try:print(name)# 1/0
except NameError as e:print("出现了变量未定义的异常")print(e)
# 捕获多个异常
try:# print(name)1/0
except (ZeroDivisionError,NameError) as e:print("出现了变量未定义的异常 或者除以0的异常错误")print(e)
#捕获所有异常
try:# 1/0print(1)f = open('test2.txt','r')
except Exception as e:
# 或者直接写 except: 起到同样的效果print("出现异常了")print(e)f = open('test2.txt','w')
else:print("没有出现异常")
finally:f.close()9.2 异常的传递

# 定义一个出现异常的方法
def func01():print("这是func01开始")num = 1/0print("这是func01结束")
# 定义一个没有异常的方法 调用上面的方法
def func02():print("这是func02开始")func01()print("这是func02结束")
# 定义一个方法,调用上面的方法def main(): #异常在main中被捕获try:func02()except Exception as e:print(e)
main()9.3 模块

 ```
```
使用import 导入time 模块使用sleep
import time # 导入python内置的time模块
print(“你好”)
time.sleep(2)
print(“hi”)
#只使用time中的sleep
from time import sleep
print(“你好”)
sleep(2)
print(“hi”)
使用 * 导入time模块的全部功能
from time import *
print(“你好”)
sleep(2)
print(“hi”)
使用as给指定功能加上别名
import time as t
t.sleep(2)
from time import sleep as sl
sl(2)
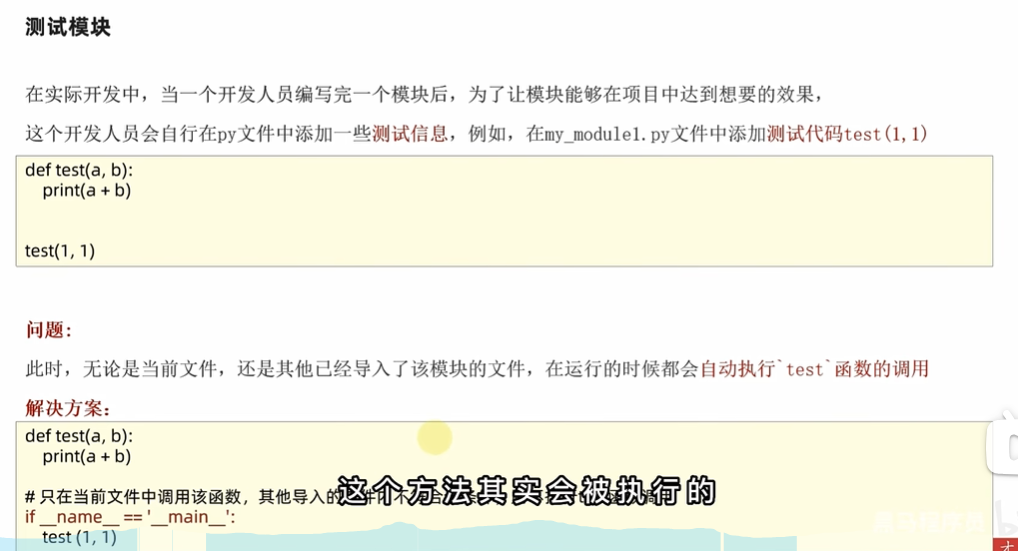> 内置变量`__name__`右键运行的时候,会将这个值设置为`__main__`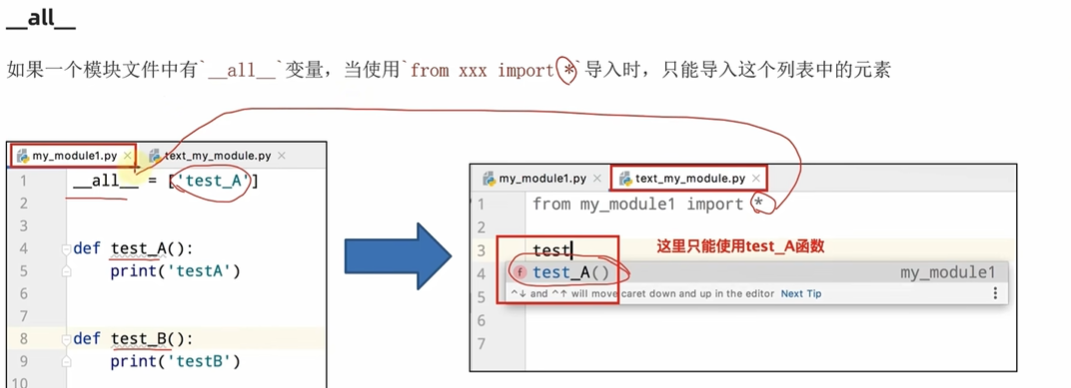导入自定义模块使用
import my_module
my_module.test(1,2)
#导入不同模块的同名功能
from my_module import test
from my_module2 import test
test(3,1)
__main__变量
from my_module import test
__all__变量
from my_module import *
test_a()
test_b() 但是此时可以用import指定的名字导入
from my_module import test_b
my\_module的内容:all = [‘test_a’]
演示自定义模块
def test(a,b):
print(a+b)
if name==‘main’:
test(1, 2)
def test_a():
print(“a+b”)
def test_b():
print(“a-b”)
### 9.4 python包#### 9.4.1 python自定义包基于python模块,我们可以在编写代码的时候,使用很多外部代码来丰富功能,但如果python模块太多了,可能会造成一定的混乱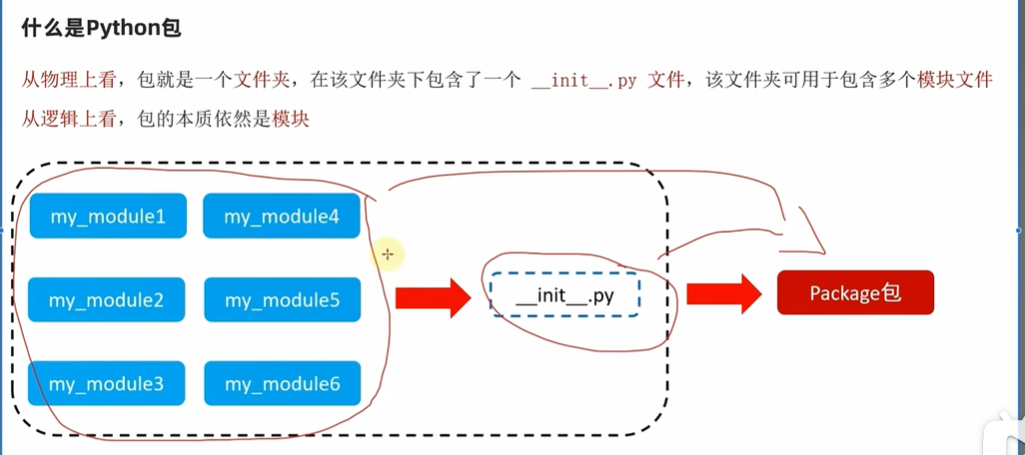> 有这个`__init__.py`就是一个python包,没有的话就是一个普通的文件夹而已创建一个包
导入自定义的包中的模块,并使用
import my_package.my_module1
import my_package.my_module2
my_package.my_module1.test(1,2)
my_package.my_module2.test(1,2)
from my_package import my_module1
from my_package import my_module2
my_module1.test(1,2)
my_module2.test(1,2)
from my_package.my_module1 import test
from my_package.my_module2 import test
通过__all__变量,控制import * 在__init__.py中写
from my_package import *
my_module1.test(1,2)
my_module2.test(1,2)
#### 9.4.2 python 安装第三方包* 在命令提示符中pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
* 在pycharm中在pycharm中点击interpreter settings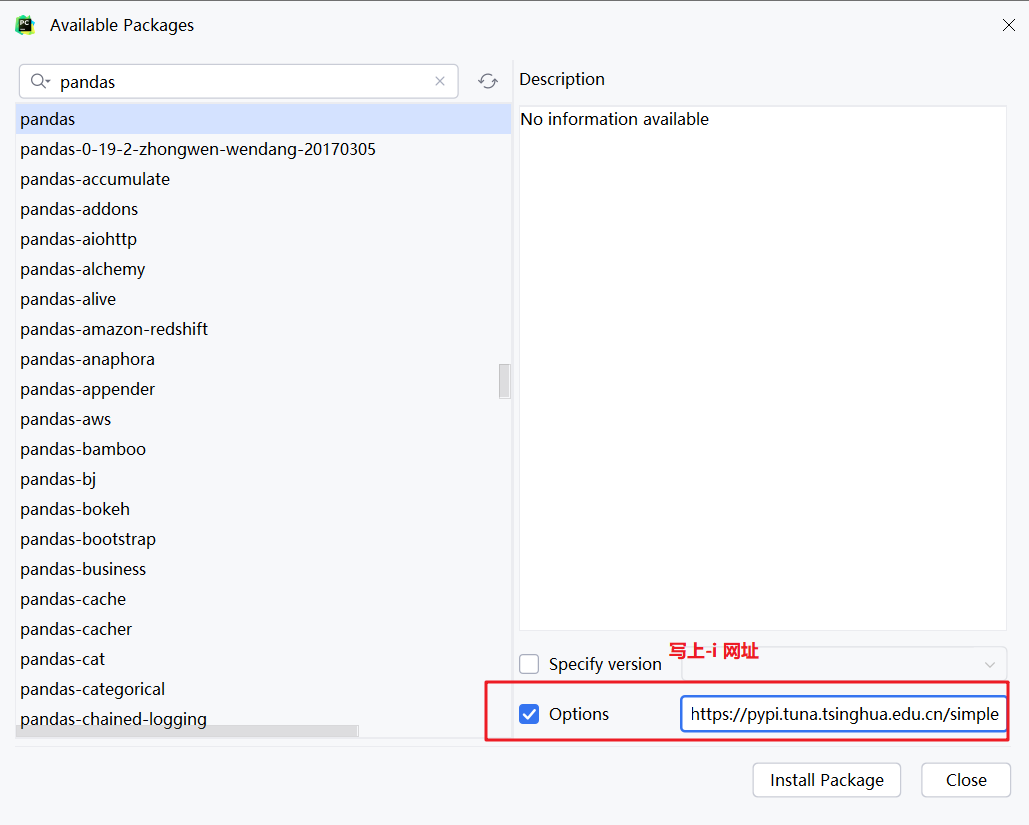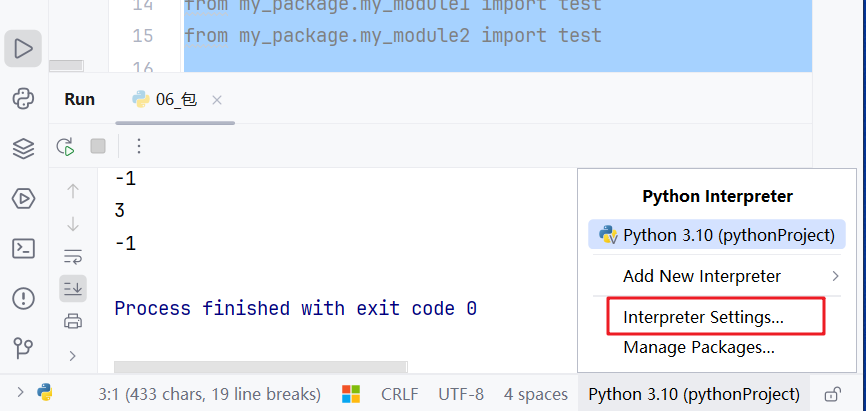### 9.5 自定义工具包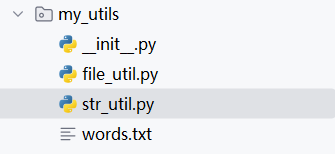file\_util.pydef print_file_info(fname):
f = None
try:
f = open(fname, ‘r’, encoding=‘utf-8’)
content = f.read()
print(content)
except:
print(“文件不存在”)
finally:
if f: # 如果变量是None,表示false,如果有任何内容,就是True
f.close()
def append_to_file(fname, data):
f = open(fname, ‘w’, encoding=‘utf-8’)
f.write(data)
f.write(“\n”)
f.close()
if name == ‘main’:
print_file_info(“word.txt”)
append_to_file('words.txt','123')
str\_util.pydef str_reverse(s):
return s[::-1]
def substr(s,x,y):
return s[x:y]
if name == ‘main’:
print(str_reverse(‘hello’))
print(substr(‘hello’,0,2))
第十章 python基础综合案例
----------------### 10.1数据可视化-折线图可视化#### 10.1.1 json数据格式json的格式数据转化:* 要么是一个字典
* 要么是列表里面嵌套了字典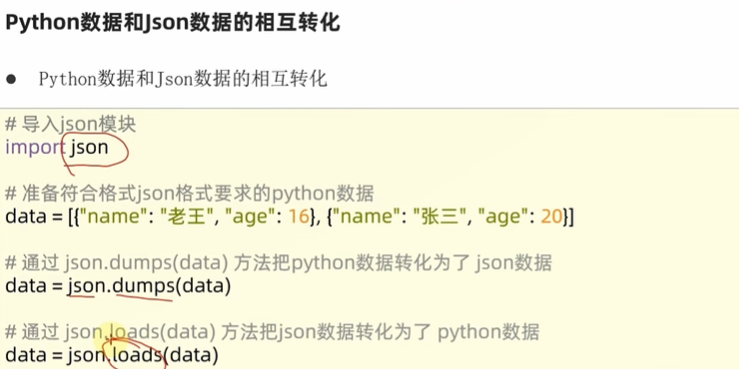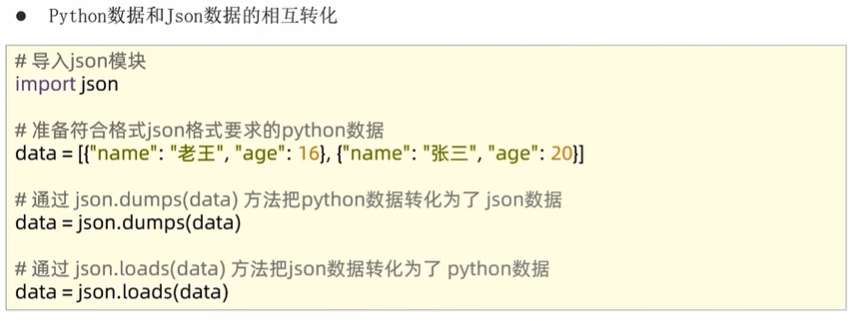“”"
演示json数据和python字典的相互转化
“”"
准备列表,列表内部每一个元素都是字典,将其转化为json
import json
data = [{“name”:“周杰伦”,“age”:47},{“name”:“林俊杰”,“age”:40},{“name”:“孙燕姿”,“age”:30}]
json_str = json.dumps(data, ensure_ascii=False)
print(json_str)
print(type(json_str))
准备字典,将字典转换为json
d = {“name”:“周杰伦”,“age”:47}
json_str = json.dumps(d, ensure_ascii=False)
print(json_str)
将json字符串转换为python数据类型[{k:v,k:v},{k:v,k:v}]
s = ‘[{“name”:“周杰伦”,“age”:47},{“name”:“林俊杰”,“age”:40},{“name”:“孙燕姿”,“age”:30}]’
l = json.loads(s)
print(l)
print(type(l))
将json字符串转换为python数据类型{k:v,k:v}
s = ‘{“name”:“周杰伦”,“age”:47}’
d = json.loads(s)
print(d)
print(type(d))
#### 10.1.2 pycharts的入门使用```
from pyecharts.charts import Line
#创建一个折线图对象
line = Line()
#给折线图对象添加x轴的数据
line.add_xaxis(['中国','美国','法国'])
#给折线图对象添加y轴的数据
line.add_yaxis('GDP',[10,2,6])
# 通过render方法,将代码生成为图像
line.render()

 ```
```
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
#创建一个折线图对象
line = Line()
#给折线图对象添加x轴的数据
line.add_xaxis([‘中国’,‘美国’,‘法国’])
#给折线图对象添加y轴的数据
line.add_yaxis(‘GDP’,[10,2,6])
#设置全局配置项
line.set_global_opts(
title_opts=TitleOpts(title = “GDP显示”,pos_left=“center”,pos_bottom=“1%”),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True),
)
通过render方法,将代码生成为图像
line.render()
#### 10.1.3生成折线图“”"
演示可视化需求:折线图开发
“”"
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts
处理数据
f_us = open(“折线图数据/美国.txt”, “r”, encoding=“utf-8”)
us_data = f_us.read()
f_india = open(“折线图数据/印度.txt”, “r”, encoding=“utf-8”)
india_data = f_india.read()
f_japan = open(“折线图数据/日本.txt”, “r”, encoding=“utf-8”)
japan_data = f_japan.read()
#去掉不合json规范的开头
us_data = us_data.replace(“jsonp_1629344292311_69436(”,“”)
india_data = india_data.replace(“jsonp_1629350745930_63180(”,“”)
japan_data = japan_data.replace(“jsonp_1629350871167_29498(”,“”)
#去掉不和json规范的结尾
us_data = us_data[:-2]
india_data = india_data[:-2]
japan_data = japan_data[:-2]
json转python字典
us_dict = json.loads(us_data)
india_dict = json.loads(india_data)
japan_dict = json.loads(japan_data)
获取trend key
us_trend_data = us_dict[‘data’][0][‘trend’]
india_trend_data = india_dict[‘data’][0][‘trend’]
japan_trend_data = japan_dict[‘data’][0][‘trend’]
获取日期数据,用于x轴,取2020年
us_x_data = us_trend_data[‘updateDate’][:314]
india_x_data = india_trend_data[‘updateDate’][:314]
japan_x_data = japan_trend_data[‘updateDate’][:314]
print(x_data)
获取确认数据,用于y轴,取2020年
us_y_data = us_trend_data[‘list’][0][‘data’][:314]
india_y_data = india_trend_data[‘list’][0][‘data’][:314]
japan_y_data = japan_trend_data[‘list’][0][‘data’][:314]
print(y_data)
生成图表
line = Line() #构建折线图对象
添加X轴数据
line.add_xaxis(us_x_data) #x轴是公用的,所以使用一个国家的数据即可
添加Y轴数据
line.add_yaxis(“美国确诊数据”,us_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis(“印度确诊数据”,india_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis(“日本确诊数据”,japan_y_data,label_opts=LabelOpts(is_show=False))
line.set_global_opts(
title_opts=TitleOpts(title=“2020年美日印三国确诊人数对比折线图”,pos_left=“center”,pos_bottom=“1%”)
)
生成图表
line.render()
关闭文件
f_us.close()
f_india.close()
f_japan.close()
### 10.2数据可视化-地图#### 10.2.1 全国疫情地图import json
from pyecharts.charts import Map
from pyecharts.options import *
读取数据文件
f = open(“地图数据/疫情.txt”,“r”,encoding=“utf-8”)
province_data = f.read()
关闭文件
f.close()
取到各省数据
province_dict = json.loads(province_data)
province_data_list = province_dict[‘areaTree’][0][‘children’]
组装每个省份和确诊人数为元组,并每个省的数据都封装入列表内
data_list = []
for data in province_data_list:
province_name = data[“name”]
province_confirm = data[“total”][“confirm”]
data_list.append((province_name,province_confirm))
创建地图对象
map = Map()
添加数据
map.add(“全国疫情数据”,data_list,“china”)
设置全局配置,定制分段的视觉映射
map.set_global_opts(
title_opts=TitleOpts(title=“全国疫情地图”),
visualmap_opts=VisualMapOpts(
is_show=True,#是否显示
is_piecewise=True,#是否分段
pieces=[
{“min”: 1, “max”: 9, “label”: “1-9”, “color”: “#CCFFFF”},
{“min”: 10, “max”: 99, “label”: “10-99”, “color”: “#FFFF99”},
{“min”: 100, “max”: 499, “label”: “100-499”, “color”: “#FF9966”},
{“min”: 500, “max”: 999, “label”: “500-999”, “color”: “#FF6666”},
{“min”: 1000, “max”: 9999, “label”: “1000-9999”, “color”: “#CC3333”},
{“min”: 10000, “label”: “10000以上”, “color”: “#990033”}
]
)
)
绘图
map.render(“全国疫情地图.html”)
#### 10.2.2 河南疫情地图import json
from pyecharts.charts import Map
from pyecharts.options import *
f = open(“地图数据/疫情.txt”,‘r’,encoding=‘utf-8’)
f_data = f.read()
f.close()
f_dict = json.loads(f_data)
henan_data_list = f_dict[‘areaTree’][0][‘children’][3][‘children’]
city_list = []
for city_data in henan_data_list:
city_name = city_data[‘name’]
city_comfirm = city_data[‘total’][‘confirm’]
city_list.append((city_name,city_comfirm))
print(city_list)
map = Map()
map.add(“河南省疫情地图”,city_list,“河南”)
map.set_global_opts(
title_opts=TitleOpts(title=“河南省疫情情况”,pos_left=“center”,pos_bottom=“1%”),
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{“min”: 1, “max”: 9, “label”: “1-9”, “color”: “#CCFFFF”},
{“min”: 10, “max”: 99, “label”: “10-99”, “color”: “#FFFF99”},
{“min”: 100, “max”: 499, “label”: “100-499”, “color”: “#FF9966”},
{“min”: 500, “max”: 999, “label”: “500-999”, “color”: “#FF6666”},
{“min”: 1000, “max”: 9999, “label”: “1000-9999”, “color”: “#CC3333”},
{“min”: 10000, “label”: “10000以上”, “color”: “#990033”}
]
)
)
map.render(“河南省疫情地图.html”)
### 10.3 数据可视化-柱状图#### 10.3.1 柱状图的基础使用from pyecharts.charts import Bar
from pyecharts.options import *
使用Bar来构建基础柱状图
bar = Bar()
添加x y轴的数据
bar.add_xaxis([‘中国’,‘美国’,‘英国’])
#设置数值标签在右侧显示
bar.add_yaxis(“GDP”,[200,100,120],label_opts=LabelOpts(position=“right”))
#反转xy轴
bar.reversal_axis()
绘图
bar.render(“基础柱状图.html”)
#### 10.3.2 时间线from pyecharts.charts import Bar,Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType
创建3个柱状图
bar1 = Bar()
bar1.add_xaxis([‘中国’,‘美国’,‘英国’])
bar1.add_yaxis(“GDP”,[200,100,120],label_opts=LabelOpts(position=“right”))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis([‘中国’,‘美国’,‘英国’])
bar2.add_yaxis(“GDP”,[400,200,60],label_opts=LabelOpts(position=“right”))
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis([‘中国’,‘美国’,‘英国’])
bar3.add_yaxis(“GDP”,[900,300,200],label_opts=LabelOpts(position=“right”))
bar3.reversal_axis()
构建时间线对象
timeline = Timeline({
“theme”: ThemeType.LIGHT
})
#在时间线内添加柱状图对象
timeline.add(bar1,“点1”)
timeline.add(bar2,“点2”)
timeline.add(bar3,“点3”)
自动播放设置
timeline.add_schema(
play_interval=1000,
is_timeline_show=True, # 是否在自动播放的时候显示时间线
is_auto_play=True,# 是否自动播放
is_loop_play=True# 是否循环自动播放
)
绘图是用时间线对象绘图而不是bar对象了
timeline.render(“基础时间线柱状图.html”)
#### 10.3.3 动态柱状图绘制import json
from pyecharts.charts import Timeline
from pyecharts.charts import Bar
读取数据
f = open(“动态柱状图数据/1960-2019全球GDP数据.csv”,‘r’,encoding=‘GB2312’)
content = f.readlines() #结果是列表
f.close()
处理掉第一行的表头
content.pop(0)
data_dict={}
将每一行处理
for line in content:
newline = line.split(‘,’)
year = int(newline[0])
country = newline[1]
gdp = float(newline[2]) # 可以将科学计数法转换为整数
try:
data_dict[year].append([country,gdp])
except KeyError:
data_dict[year] = []
创建时间线对象
timeline = Timeline()
排序年份
print(data_dict)
直接for循环字典可能会乱掉
for year in data_dict:
# 取出GDP前8的国家
data_dict[year].sort(key = lambda element:element[1],reverse=True)
top_8 = data_dict[year][:8]
x_data = []
y_data = []
for country_gdp in top_8:
x_data.append(country_gdp[0])
y_data.append(country_gdp[1])
# 构建柱状图
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis(“GDP(亿)”, y_data)
# 反转x轴和y轴
bar.reversal_axis()
timeline.add(bar,str(year))
timeline设置
timeline.add_schema(play_interval=1000,is_loop_play=True,is_auto_play=True,is_timeline_show=True
)
timeline.render("1960~2019年全球GDP前8国家02.html")
👉 这份完整版的Python学习资料已经上传,朋友们如果需要可以扫描下方二维码或者点击链接免费领取【保证100%免费】
