YOLO V10简单使用
一.环境安装
1、下载官方源码
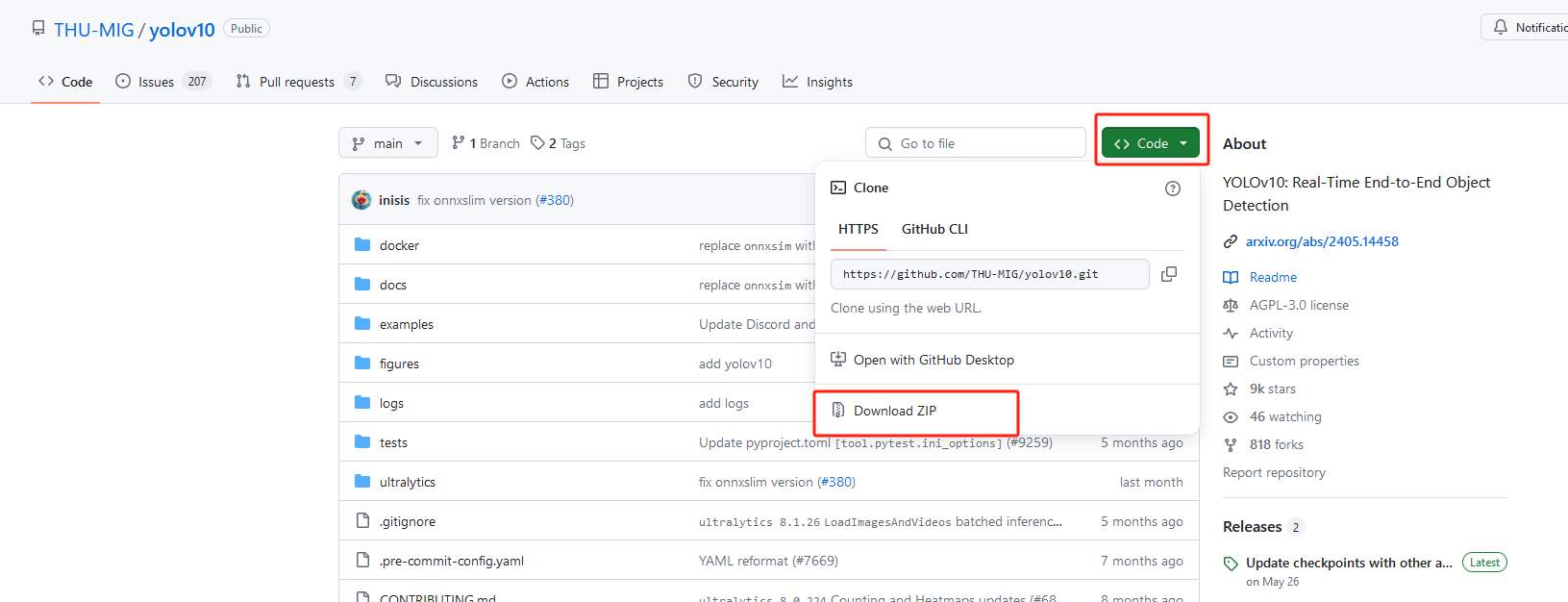
官方GitHub地址:https://github.com/THU-MIG/yolov10 点击跳转
2. 配置conda环境
- 在conda创建python3.9环境
conda create -n yolov10 python=3.9
- 激活切换到创建的python3.9环境
conda activate yolov10
3. 安装YOLOv10依赖
- 切换到yolov10源码根目录下,安装依赖
- 注意:会自动根据你是否有GPU自动选择pytorch版本进行按照,这里不需要自己去选择pytorch和cuda按照,非常良心
pip install -r requirements.txt
如果执行效果缓慢可以试试加速镜像
pip install -r requirements.txt -i https://pypi.doubanio.com/simple
- 执行命令
pip install -e .
二、数据图片准备
这里以视频为例,自选任意视频,使用如下代码将视频抽帧处理
import cv2video = cv2.VideoCapture("./001.mp4")
num=0#计数器
save_setp=30#间隔帧数
while True:ret,frame=video.read()if not ret:breaknum+=1if num%save_setp==0:cv2.imwrite("./img/"+str(num)+".jpg",frame)
三、图片标注
1. 环境安装
环境安装:pip install labelimg
启动:labelimg

2.基础设置
- 设置打开文件夹和保存文件夹
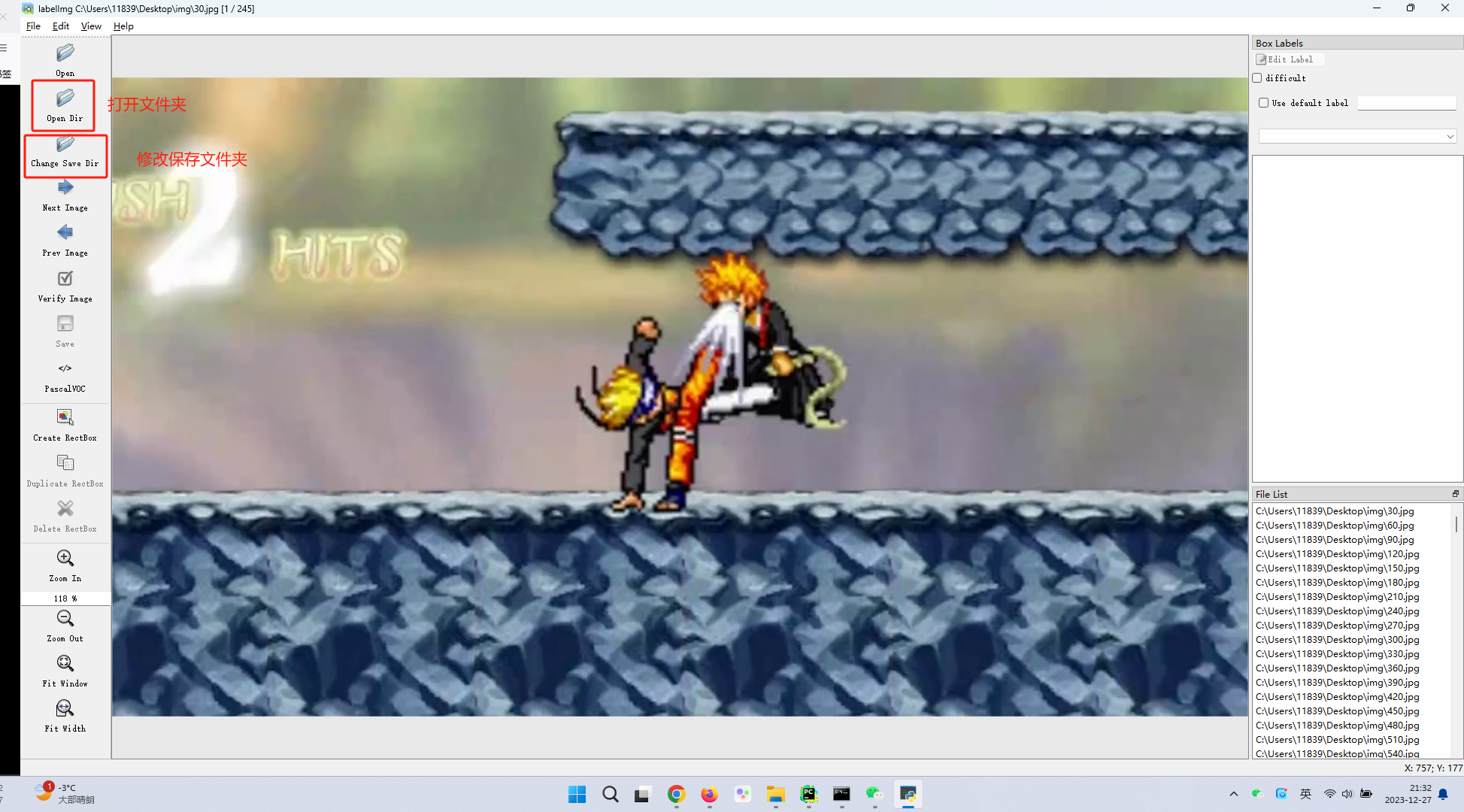
- 设置自动保存:工具栏 view-auto save mode
- 切换模式
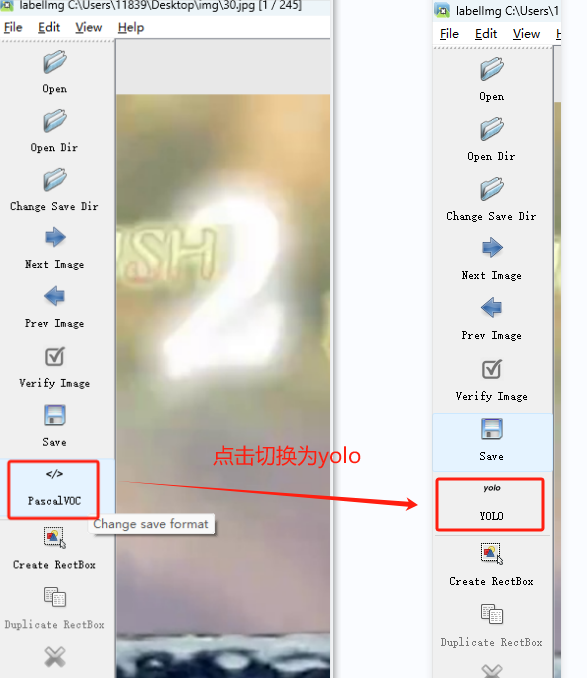
- 点击save保存修改
3.开始标注
- 双击右侧FileList内的图片打开后,右键create RectBox开始标注,在图像上拖拽画出矩形框,在弹出的对话框里输入标签名称(以Ly为例)或选择,然后点击 OK
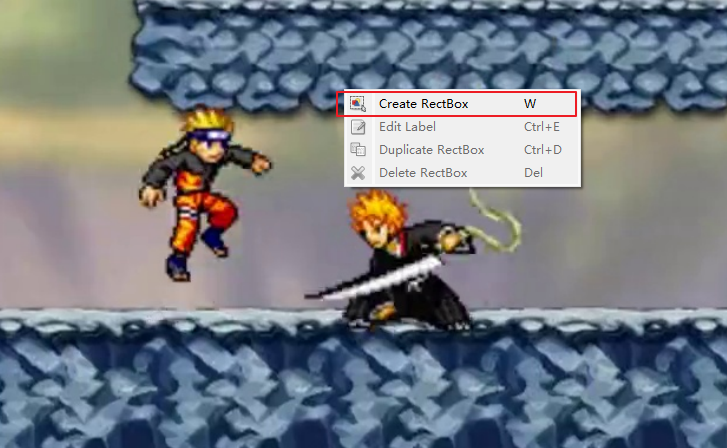
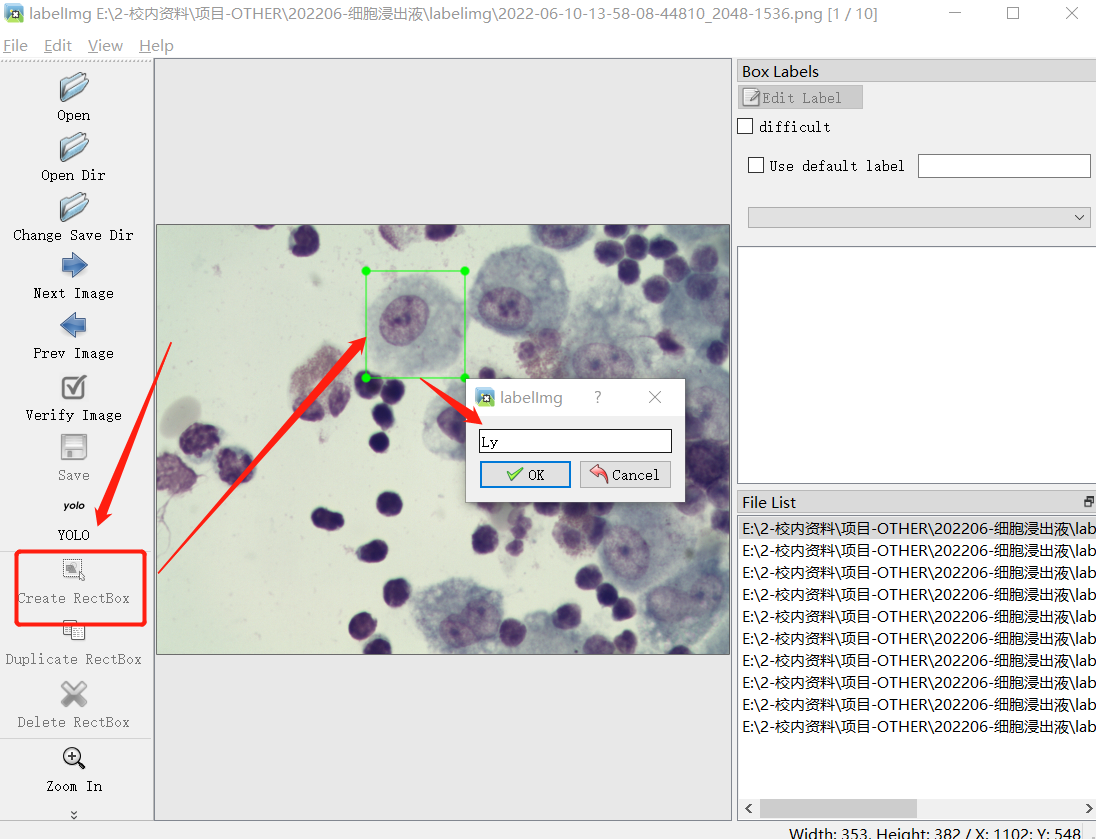
- 相同的步骤对目标物体进行标注,使用过的标签再下一次可直接选择不必重新输入;已经标注的框可在右侧看到,可以在图像中进行二次拖拽调整
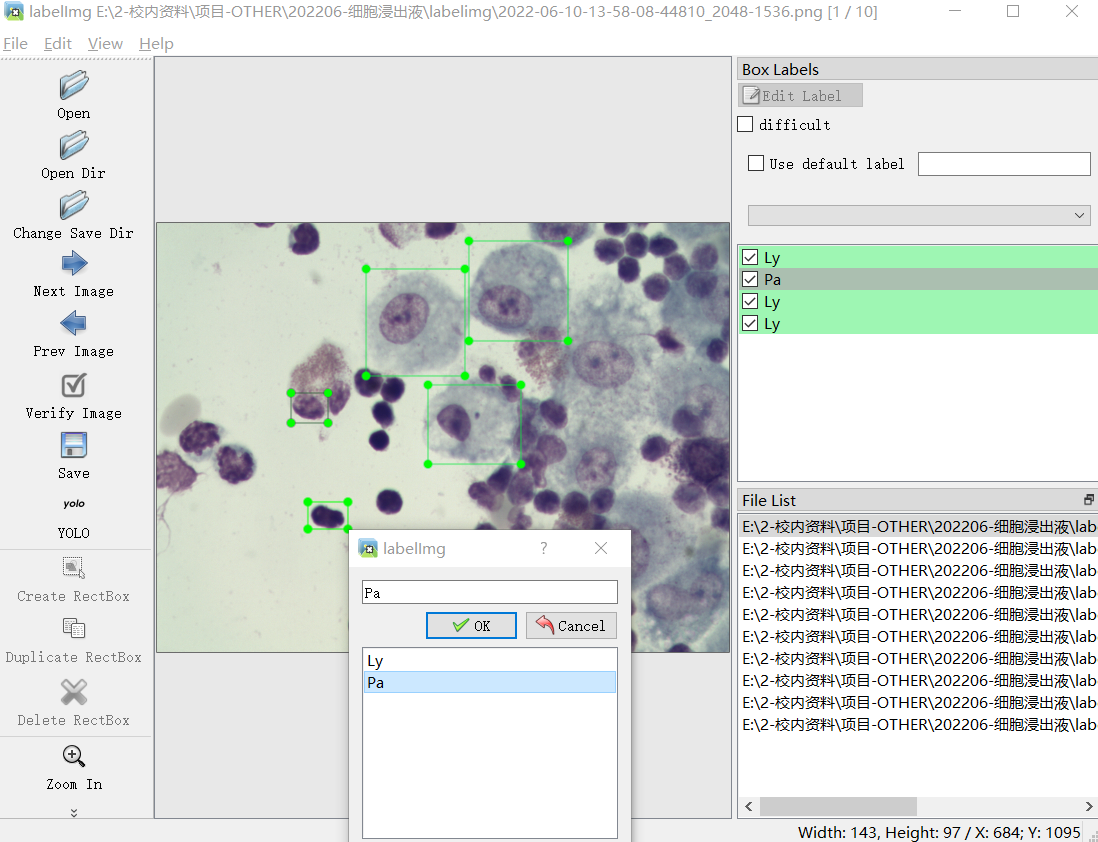
- 然后点击 Next Image,对下一个图片进行标注
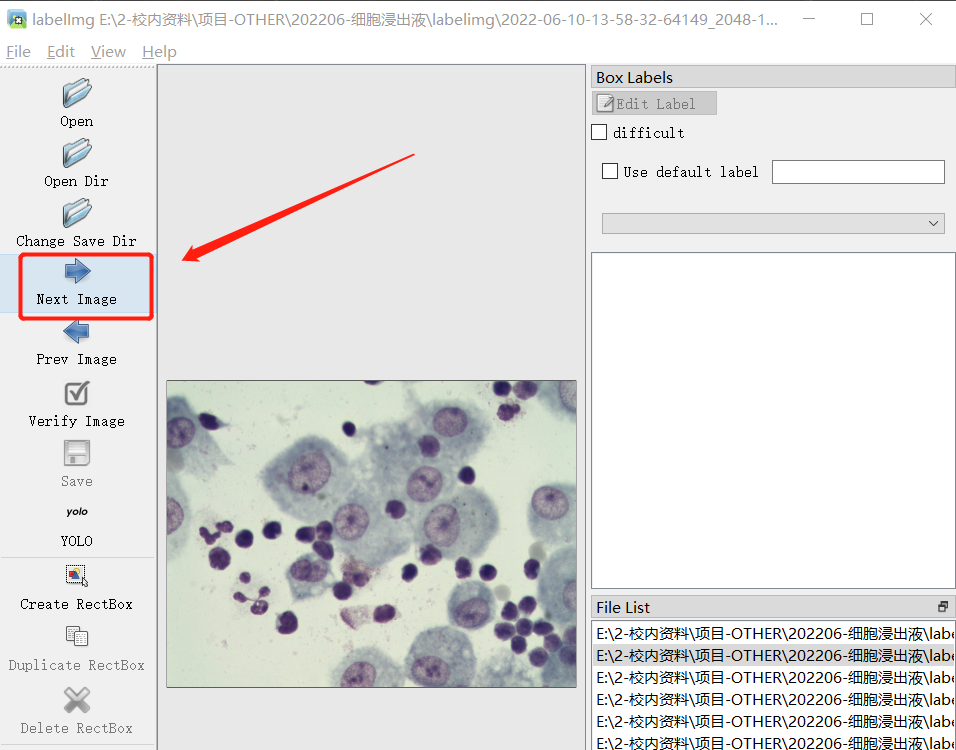
- 然后会在此前设置好的保存目录中得到标注信息
注意:yolov10标注完成后的数据文件中,每一行的数据格式为: 类型 x中心坐标 y中心坐标 宽度 高度
4.make senc数据集标注工具
- 地址:https://www.makesense.ai/
- 辅助标注:
- pip instll tensorflowjs==2.8.5
- YOLOv5模型导出tfjs
- make scene上传模型
5.roboflow公开数据集
- https://public.roboflow.com/object-detection
- https://universe.roboflow.com/
四、训练数据准备
1.数据集准备
准备文件夹
- images:存放图片
- train:训练集图片
- val: 验证集图片
- labels:存放标签
1.train:训练集标签文件,要与训练集图片名称一一对应
2.val:验证集标签文件,要与验证集图片名称一一对应
3.classes.txt(可以没有):这个文件是标注的类型文件
此前打标签时导入的文件夹就是训练集,输出结果就是验证集,无非是把目录结构按上述更改一下
一般来说,训练集与验证集的数据比例是8:2,即如果又100张图片,那么80张作为训练集,20张作为验证集
2.文件准备
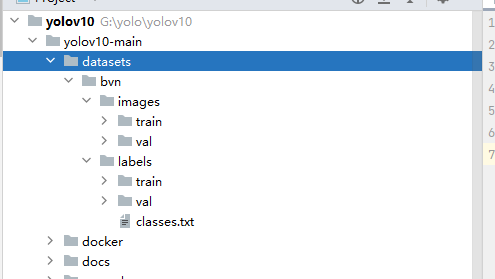
- 准备图片文件夹:在yolov10源码目录下,新建datasets文件夹,将刚才准备好的图片数据复制进该文件夹,bvn为项目名
- 从ultralytics/cfg/datasets文件夹下随便复制一个yaml配置文件至ultralytics-main根目录下
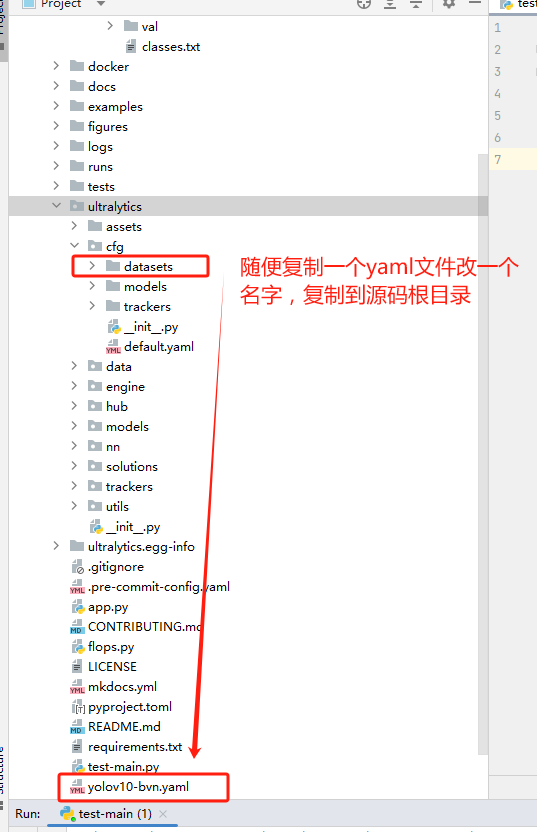
- 改写配置文件
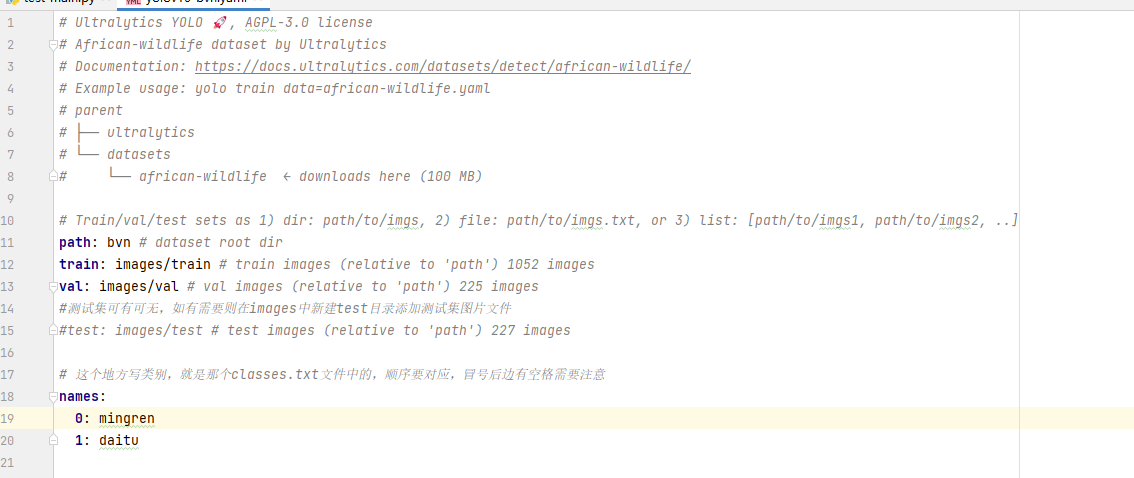
- path为从datasets目录开始算的根文件夹名称
- train与val时训练集与验证集的位置
- names这里就是分类标签,可以按照标注后生成的calsses.txt文件填下
五、启动训练
1. 命令行启动训练
yolo detect train data=coco.yaml model=yolov10n/s/m/b/l/x.yaml epochs=500 batch=256 imgsz=640 device=0,1,2,3,4,5,6,7
2. 代码启动训练
在源码目录下新建xx.py文件
from ultralytics import YOLOv10 #这里需要注意,这里导入的是YOLOv10
# 这个训练权重可以根据自己情况更换不同的权重文件,在后续权重文件章节会详细解释
# 关于这个yolov10n.pt文件从哪来,亦可以在后续权重文件章节找到下载路径
model = YOLOv10("yolov10n.pt")#这里启动训练,data为刚才的yaml文件路径,workers为0,表示单线程训练,windows系统中workers不为0可能会报错
model.train(data='yolov10-bvn.yaml',workers=0, epochs=50, batch=-1)在启动训练时候可能会报如下错误:
- ModuleNotFoundError: No module named ‘huggingface_hub’
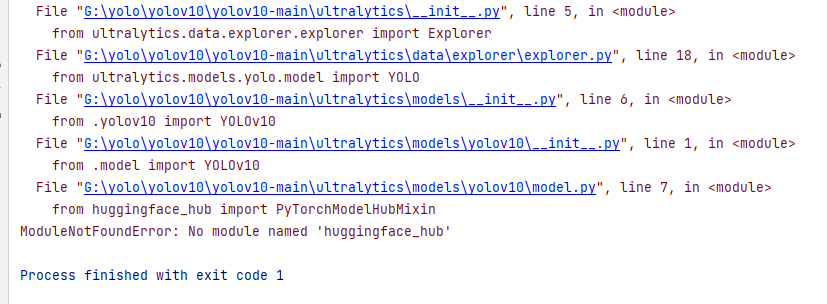
解决办法:
pip install huggingface_hub
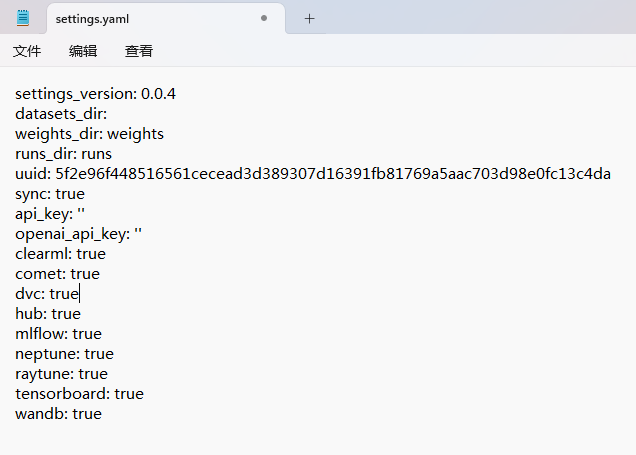
- Note dataset download directory is ‘G:\yolo\yolov10\datasets’. You can update this in ‘C:\Users\11839\AppData\Roaming\yolov10\settings.yaml’
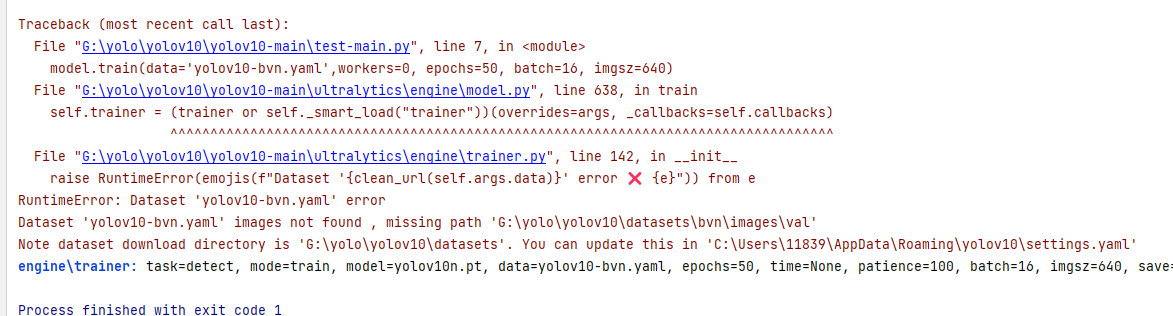
解决办法:找到所提示的yaml文件,这里是’C:\Users\11839\AppData\Roaming\yolov10\settings.yaml’,使用记事本打开将文件中的datasets_dir参数值删除并保存即可
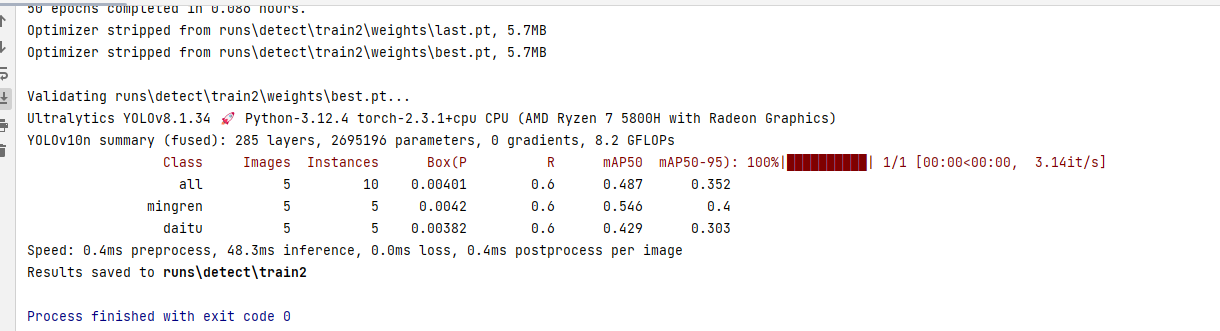
3. 模型训练结果
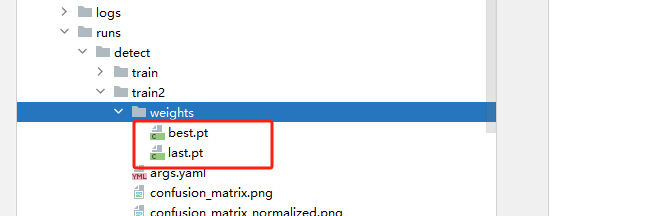
模型训练结果会保存至runs目录下
::: tip
模型存储在weights文件夹下
best.pt:是训练出的最好的模型
last.pt:是最后面的模型,如果需要继续训练需要使用
:::
4.模型测试:
yolo detect predict model=runs/detect/train/weights/best.pt source=001.mp4 show=True
001.mp4是抽帧的视频
5.注意事项

其中AppData是再当前用户目录下