大模型训练实战经验总结
在当今AI技术飞速发展的背景下,定制化大模型的自主训练已成为满足特定行业需求、保障数据安全、提升模型应用效能的关键途径。本文将深度剖析这一过程的核心价值与实践智慧,从数据隐私保护、模型透明度增强,到数据预处理的精细操作,特别是数据配比在维持模型通用性与垂类能力平衡中的核心作用,为读者勾勒出一幅清晰的大模型训练全景图。


背景
▐ 定制化需求
每个行业和应用场景都有其独特的需求,预训练的通用大模型可能并不能完全满足这些需求。自主训练大模型可以:
- 细化功能:根据特定任务调整和优化模型,以提高准确性和效率。
- 行业特定术语:对于代码、客服等特定领域,可以训练模型理解和生成与这些领域相关的专业术语和复杂语句。
▐ 数据隐私和安全
对于许多企业和组织而言,数据隐私和数据安全是最重要的。通过自己训练模型,可以确保数据仅在内部使用,避免数据外泄风险。
- 数据掌控:确保数据不被第三方访问或使用,满足数据隐私法律和法规的要求。
- 安全性:减少数据泄露的风险,保护敏感信息。
▐ 更好的模型使用
训练自己的大模型可以帮助团队更好地理解模型的内部工作机制和决策过程,这对于后续的RAG、知识图谱、Function call和Agent非常有帮助。
- 透明度:更全面地理解模型如何处理数据与做出决策,有助于解释和改进模型。
- 可解释性:在风险控制、法律法规要求的领域,模型的可解释性尤为重要。
数据——巧妇难为无米之炊
▐ 数据的清洗步骤有哪些?

这种所谓的严格的数据清洗,可能更多的依赖严格的数据来源。通常而言,处理互联网数据集都包含以下几个规则:
- 语言识别:判断文章的语言类型,在LLaMA的数据预处理中过滤掉一些非英文语料。
- 规则过滤:用规则过滤低质量内容,例如:同一句话中间出现过多的标点、或包含一些违禁词等。
- 基于打分模型的内容过滤:通过轻量的机器学习模型,用于判断一篇文章是否足够优质。
- 文章去重:去掉一些相似内容的文章。
- 对于输入历史对话数据进行左截断,保留最新的对话记录。
- 去掉样本中明显的语气词,如嗯嗯,啊啊之类。
- 去掉样本中不合适的内容,如AI直卖,就不应出现转人工的对话内容。
- 样本中扩充用户特征标签,如年龄,性别,地域,人群等。
▐ 什么是数据配比?数据配比有什么用?
用了大量的行业数据,模型怎么反而变弱了?
比如,对一个回答问题能力不错的模型,用大量数据做指令微调以后,模型变得不会回答问题了。对这个问题,正好做了不少实验,也和周边很多有实践的人讨论了这方面的问题。得到的最宝贵的经验就是:数据配比!
当然这还有别的原因可能导致这样的问题,比如:数据差异过大等问题。
大模型可能在训练过程中过度专注于垂类数据,导致loss的收敛不再依赖全局而是从部分数据进行考虑。
如下是一篇关于垂类大模型构建的论文,其中有详细的数据配比的内容可以参考:
在贝壳中的论文中可以看到,比较好的结果是开源数据集:垂域数据集为4:1,即开源占比总体训练数据的80%,而垂类数据仅占20%。
《垂域大模型训练》https://arxiv.org/pdf/2307.15290.pdf

贝壳中的数据配比
这和论文中的比的对象是反过来的:
对continue pretraining来说,如果要让模型不丢失通用能力,比如summarization,qa等,「领域数据的比例要在15%以下」,一旦超过这个阈值,模型的通用能力会下降很明显。所以,在做领域数据continue pretraining的时候,一定更要混大量的通用数据。而且,这个阈值和不同的预训练模型是相关的,有些模型比如llama需要控制的阈值更低。这个阈值其实是个经验主义的结论,感觉大家的范围都在10%-15%左右。而且,该阈值和预训练模型的大小,预训练时原始数据的比例等条件都息息相关,需要在实践中反复修正。
对sft来说,这个比例就可以提高不少,大概领域数据和通用数据比例在1:1的时候还是有不错的效果的。当然,如果sft的数据量少,混不混数据的差别就不太大了。
训练——工欲善其事
正如古语所说:“工欲善其事,必先利其器。”为训练高性能的大模型,我们需要选择和优化合适的工具和方法。
▐ 大模型的训练如何简单地理解呢?
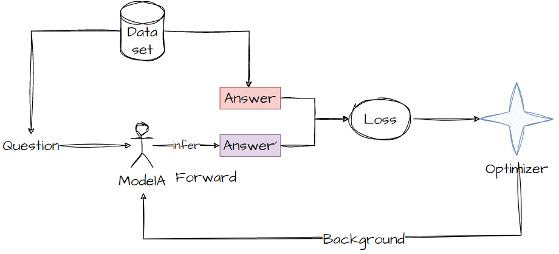
这个过程有什么可以理解的内容:
- 直接决定训练时间的数据量的Token个数
- Token的数量=Epoch数据条数平均数据长度*token转换比
- 这里的Token这样理解:通常一个中文/英文单词会变成一个Token,也就是数字向量
- 能训练的环境一定能推理(HF推理方式)
- Epochs决定Dataset的数据要重复几次
- batch_size决定每张卡一次训练放入几个样本进行推理,这样可以使得模型训练的结果更具备均衡性。
- Learning_rate作用于优化器中,全量训练推荐2e-5,Lora训练推荐5e-5,随着batch_size变大Learning_rate也需要变大,按照大模型经验公式为根号下同比,例如batch从8变为16扩大2倍,则LR扩大根号二倍。
训练流程的简单理解:
- 针对模型的生成的**“字(Token)”来和正确答案对比,得到损失函数**(+2给你问题处理,你的产出和+2的预期,得到对你工作的评价)。
- 将损失函数交给Optimizer对模型优化进行指导(+1拿到你评价,对你的工作进行优化,从后往前优化,选择每一次最影响的内容进行修改)。
- 通过数据量的不断叠加,模型逐渐优秀。
▐ 如何选择合适的微调方案?
首先,有两种不同的基座模型分别是base和chat两个版本,我们要明白其中的不同:chat=base+sft
仅用SFT做领域模型时,资源有限就用在Chat模型基础上训练,资源充足就在Base模型上训练。(资源=数据+显卡)资源充足时可以更好地拟合自己的数据,如果你只拥有小于10k数据,建议你选用Chat模型作为基座进行调;如果你拥有100k的数据,建议你在Base模型上进行微调。
基模型的base和chat选择
在模型选择中有如下准则:
- 垂域和基模型差异过大,选择base版本,可以先进行知识注入再进行指令微调
- 资源不充足下,采用chat版本具有一定的对话能力
- LoRA选择chat版本
- 数据限制:数据小于10k,选择chat版本,数据大于100k,选择base版本
额外小技巧:
\1. 领域技术标准文档或领域相关技术是领域模型的二次预训练的关键所在。
\2. 垂直领域训练过后,往往通用能力就会有所下降,因此在训练模型时候需要一定的数据配置来解决这个问题 a. 根据BloombergGPT(从头预训练)预训练金融和通用数据基本为50%,ChatHome二次预训练发现:领域数据与通用数据的配置大约为1:5。根据一些博文的介绍,在全量SFT过程中需要50%的数据。因此领域数据的训练配置大约在20-50%之间。
\3. 在二次预训练同步加入SFT数据,即MIP,Multi-Task-Instruction Pre-Training
\4. 仅用SFT做领域模型时,资源有限就用Chat模型来训练,资源充足就用Base来完成。
\5. 领域评测集时必要内容,建议准备两份,一份选择题形式自动评测,另外一份形式为人工评测。
▐ 训练需要多少的显存资源呢?(全量训练)

在神经网络的推理阶段,没有优化器状态和梯度,也不需要保存中间激活。少了梯度、优化器状态、中间激活、模型推理阶段占用的显存要远远小于训练阶段。模型推理阶段,占用显存的大头主要是模型参数,如果使用float16来进行推理,推理阶段模型参数占用的显存大概是2φbytes.如果使用KV cache来加速推理过程,KV cache也需要占用显存,此外,输入数据也需要放到GPU上,还有一些中间结果(推理过程中的中间结果用完会尽快释放掉),不过这部分占用的显存是很小。
在训练过程中,占用显存的大头主要分为四个部分:
- 模型参数
- 前向传播过程中的激活值
- 反向传播过程中的梯度
- 优化器状态
通常训练大模型会采用AdamW优化器,并且采用混合精度来加速训练,我们基于这个前提来进行显存分析。在一次的训练迭代中,每一个可以训练的参数都会有对应的1个梯度值,2个优化器状态(Adam优化器梯度的一阶动量和二阶动量)。假设模型的参数量为φ,那么梯度的参数数量也是φ,AdamW优化器的参数数量为2φ。已知float16(bf16)数据类型的参数会展2个bytes,float32数据类型的参数会占4个bytes。
在混合精度训练的时候,会使用float16的模型参数进行前向传播和反向传播,计算得到float16的梯度:在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。因此,针对每个科训练的模型参数,占用了**(2+4)+(2+4)+(4+4) = 20bytes**。如果使用AdamW优化器和混合精度训练来训练参数量为φ的大模型。模型参数、梯度和优化器状态占用的显存大小为20φbytes。
▐ LoRA训练一言以蔽之
在transformers层针对q_proj,k_proj层设计一个旁路,通过低秩分解,来进行模型参数的更新。利用矩阵乘法具备的广播来完成训练的时候原始模型全部固定,只有旁路参与训练,训练矩阵BA推理的时候会将矩阵BA相加到原始权重上,不会引入额外的推理延迟(合并模型Merge),针对于任务的切换可以通过切换支路来完成。
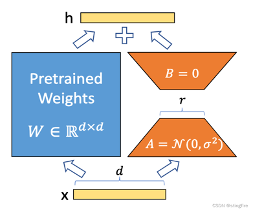
通过低秩参数来模型参数的改变,从而以极小的参数量来实现大模型的间接训练。
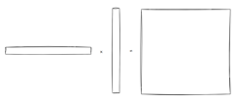
如上图所示,也就是说用284096代替了原始模型中4096*4096的参数来进行训练更新。
LoRA训练的优点:
- 只更新了一部分的参数
- 减少了通信时间
- 采用了各种低精度的加速技术
- 加速
LoRA训练的缺点:
- 参与训练的模型参数量是不足的,就是只有千分之三-千分之五左右,所以效果相差比较大。
- 如果在具备足够资源且数据量超过10K,推荐采用全量微调,LoRA只是解决了计算资源不够的场景下的问题。
▐ 大模型训练的流程是什么?每个流程的数据格式是什么样子?

目前大模型的微调模式主要分为:
二次预训练(pre-train,pt)
\1. 主要数据格式:文本段
\2. 适用类型:通用支持或无法有效整理成QA知识的
# txt格式Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.# json格式{ "completion": "下埔,是台湾宜兰县头城镇的一个传统地域名称,位于该镇南部。相较于今日行政区,其范围大致为包括顶埔里、下埔里。\n历史\n台湾清治末期,下埔地区为一街庄,称为「下埔庄」,隶属于头围堡。该庄东与三抱竹庄为邻,南与大塭庄为邻,西南边一小段与二围庄为邻,西边为中仑庄,北边为金面庄、新兴庄。\n1901年(日治明治三十四年)11月,废县厅改设二十厅,该庄隶属于宜兰厅,编入第四区。1905年(明治三十八年)7月,第四区改名「二围区」。1909年(明治四十二年)10月,合并二十厅为十二厅,该庄仍隶属于宜兰厅。1920年(大正九年),废十二厅改设五州二厅,该庄改制为「下埔」大字,隶属于台北州宜兰郡头围庄,大字下有「下埔」、「顶埔」小字名。\n战后头围庄改制为头围乡,隶属于台北县,大字亦改制为村。1946年9月,头围乡更名为头城乡。1948年再改制为头城镇,村改制为里。1950年10月,北、基、宜分治,头城镇改隶属于宜兰县。\n聚落\n本地区发展较早的聚落有顶埔、下埔等,在日治期初期的官方地图上已有记载。\n交通\n台铁宜兰线是台湾东北部铁路干线,大致以东北—西南走向经过下埔地区西北部。境内设有顶埔车站,属招呼站,只停靠区间车。由此可前往台铁沿线各地。\n省道台2线(头滨路三段)是台湾滨海公路系统之一,其中基隆至苏澳路段又称为「北部滨海公路」,大致以纵向转西北—东南走向经过本地区东北端。由该道路向北可前往头城市区、贡寮、瑞芳、基隆等地,向东南转南可前往壮围、五结、苏澳等地。\n省道台2庚线(青云路二段)是头城至二城的干线,大致以东北—西南走向经过本地区西北部边界地带。由该道路向东北可前往头城市区南侧并止于省道台2线路口,向西南可前往中仑北部、二城并止于省道台9线路口,亦可于该处连接国道5号头城交流道。\n县道191号是顶埔至宜兰的道路,其北侧端点位于本地区西北部边界上的省道台2庚线路口。由此向南南西出境后,可前往中仑、大塭、五股、茅埔、踏踏、抵美、五间、壮七并止于宜兰市区东侧的省道台7线路口。\n学校\n* 二城国小(大部分)", "source": "wikipedia.zh2307"}
有监督学习(supervised finetune,sft)
\1. 主要数据格式:QA问答
\2. 适用类型:微调的主要场景,垂直领域应用私有化重点能力
# 带有历史的QA{ "instruction": "你是谁?", "input": "", "output": "我是一个由XXX自主训练的生成式自然语言处理模型,名字为GPT,专门用于回答运维相关问题。", "history":[ [ "你好", "你好呀!请问有什么需要帮助的地方?"] ] }# 不带历史的QA提问{ "instruction": "你是谁?", "input": "", "output": "我是一个由XXXX自主训练的生成式自然语言处理模型,名字为GPT,专门用于回答运维相关问题。" }
奖励模型(reward model,rm)
\1. 主要数据格式:带有排序的QA方案
\2. 适用类型:用于SFT后的模型能力增强,训练奖励模型协助对模型结果进行优化符合人类预期
{ "instruction": "我需要举办6人晚宴。你能帮我推荐三道不包括坚果或海鲜的菜吗?", "input": "", "output": [ "好的,我将为您推荐三道不包含坚果或海鲜的菜。这三道菜都是容易做且好吃的家常菜,希望您能满意。\n1. 青椒土豆丝\n2. 西红柿炒鸡蛋\n3. 土豆炖豆角", "尖椒干豆腐,土豆丝,红烧肉", "如果是六个人,就点八个菜,一般是荤素搭配,凉菜+热菜,两三个素凉,一个肉凉,以及两三个素热,两三个肉热。" ], "history": [] }# 和sft的主要差异在于output中,需要排序给出对应的回答,依次从好到差这样排序
DPO\PPO 直接偏好优化
\1. 主要数据格式:
\2. 使用类型:直接跳过对应的RM训练过程中,利用数据来完成强化学习操作
{ "instruction": "解释为什么下面的分数等于 1/4\n4/16", "input": "", "output": [ "分数 4/16 等于 1/4,因为分子和分母都可以被 4 整除。将顶部和底部数字都除以 4 得到分数 1/4。", "1/4 与 1/4 相同。" ] }
在output中有两个答案,分别表示choosen和reject来表示数据是否接收。
▐ 中文****大模型训练经验
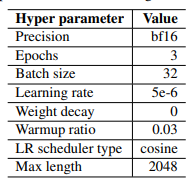
贝壳论文中推荐的超参数设置
如下是一些对于训练数据的消融实验:
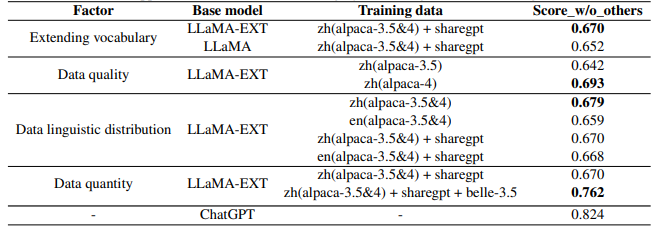
实验列表
根据贝壳论文中的消融实验可以看出:
\1. 扩充中文词表后,可以增量模型对中文的理解能力,效果更好。
\2. 数据质量越高越好,而且数据集质量提升可以改善模型效果。
\3. 数据语言分布,加了中文的效果比不加的好。
\4. 数据规模越大且质量越高,效果越好,大量高质量的微调数据集对模型效果提升最明显。解释下:数据量在训练数据量方面,数据量的增加已被证明可以显著提高性能。值得注意的是,如此巨大的改进可能部分来自belle-3.5和我们的评估数据之间的相似分布。评估数据的类别、主题和复杂性将对评估结果产生很大影响。
▐ 垂域****模型的二次预训练数据选择
对于垂域模型的二次预训练,我们推荐采用的是一些比较具有高密度知识的数据文档,可以帮助模型获取对应的数据内容,例如技术文档、书籍这些内容。其次就是领域内的博客和相关介绍这其中包含很多的无用内容。
领域模型Continue PreTrain时可以同步加入SFT数据,即MIP,Multi-Task Instruction PreTraining。预训练过程中,可以加下游SFT的数据,可以让模型在预训练过程中就学习到更多的知识。
▐ 如何解决SFT训练变傻的问题
SFT只是一些帮助大模型获取涌现能力的手段,并不是进行大模型注入新知识的方案,因此如果领域分布差异过大且过于单一,非常容易出现这种情况。
\1. 代表性。应该选择多个有代表性的任务;
\2. 数据量。每个任务实例数量不应太多(比如:数百个)否则可能会潜在地导致过拟合问题并影响模型性能;
\3. 不同任务数据量占比。应该平衡不同任务的比例,并且限制整个数据集的容量(通常几千或几万),防止较大的数据集压倒整个分布。
当然还有一些其他由于训练过程中的超参数导致训练效果比较差:微调初始学习率不要设置太高,lr=2e-5或者更小,可以避免此问题,不要大于预训练时的学习率。
不仅如此,还有如下的内容可以参考:
\1. Prompt的多样性:丰富多样的prompt数据,可以让模型更多的了解人类的指令,包括指令的意思,复杂指令中每一步的含义。Prompt的丰富程度决定了模型指令遵循的能力。
\2. Answer的质量:Answer的质量包括内容和格式两方面,一方面内容的正确性需要得到保证,一方面内容的格式也很重要,细节丰富,逻辑缜密的answer可以激发模型更多的回答能力。
SFT阶段不能太多的知识注入:过多的知识注入,或者超过模型能力本身的回答过多会导致对齐困难,这是OpenAI的blog也曾经提到的,会影响其学习指令遵循的能力。

推理测评——检验真理的唯一标准
▐ 常见的模型测评内容
知识面广度:请模型回答关于不同主题的问题。
理解能力:提出一些需要深入理解文本的问题,看看模型能否正确回答。
语言生成能力:让模型生成一段有关特定主体的文章或故事,评估其生成的文本在结构、语法和逻辑上的质量。
知识度广度:请模型回答关于不同主体的问题,以测试其对不同领域的知识掌握程度。
适应性:让模型处理各种不同类型的任务,例如写作、翻译、编程等。
长文本理解:提出一些需要处理长文本的问题。
长文本生成:模型创作一个故事或者文章,具备完整的情节,且不出现明显的逻辑矛盾或结构错误。
伦理和道德:测试模型在处理有关道德和伦理问题时候的表现,例如:”在什么情况下可以撒谎“。
对话和聊天:进行对话,测试其对自然语言处理的掌握程度。
逻辑推理能力:请模型回答需要具备一定推理或者逻辑分析的题目,例如:“所有的动物都会呼吸。狗是一种动物,狗会呼吸吗?”
问题解决能力:提供实际问题,例如数学、变成能力,看看模型是否能给出正确的回答。
情感分析能力:提供一段文本或者对话,让模型分析其中的情感和态度是否正确。

结语
通过解析训练流程、微调策略选择、资源需求评估,以及中文模型训练的独到见解,本文为读者勾勒出一幅清晰的大模型训练全景图。进一步也揭示了如何有效评测模型性能,确保其在知识广度、逻辑推理、情感理解等多维度达到高标准,为推动AI技术在各行各业的创新应用提供了宝贵的实操指南。
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
