GaussDB关键技术原理:高弹性(五)
书接上文GaussDB关键技术原理:高弹性(四)从扩容流程框架方面对hashbucket扩容技术进行了解读,本篇将从日志多流和事务相关方面继续介绍GaussDB高弹性技术。
目录
4.2 日志多流
4.2.1 日志多流总体流程
4.2.2 基线数据传输
4.2.3 日志传输与回放
4.2.3.1 日志流的处理
4.2.3.2 回放的处理
4.2.4 CBI索引相关处理
4.3 事务相关
4.3.1 CLOG拆分
4.3.1.1 事务ID分配及CLOG/CSNLOG
4.3.1.2 CLOG拆分背景
4.3.1.3 CLOG拆分处理可见性判断
4.3.2 xid调整
4.3.2.1 xid调整背景
4.3.2.2 xid调整流程
4.3.3 bucket锁
4.2 日志多流
本节介绍日志多流技术,hashbucket扩容的思路仍然是基线数据加增量数据,其中基线数据为bucket物理文件和bucket级CLOG文件,增量数据采用搬迁增量XLOG并回放日志的方式进行追增。日志多流只在hashbucket扩容期间动态的产生和使用,扩容框架会根据当前正在搬迁的bucket列表,解析并生成对应的日志流用来进行后续的数据追增。
4.2.1 日志多流总体流程
日志多流总体流程由gs_redis_bucket工具下发的MOVE BUCKETS语句触发,
ALTER DATABASE database_name MOVE BUCKETS (bucket_list) FROM sender_dn TO receiver_dn;
MOVE BUCKETS语句中包含如下信息:正在进行扩容重分布的库database_name,本批搬迁bucket列表的bucketlist,老节点为sender_dn,新节点receiver_dn。
如图所示为日志多流示意图。主要涉及三个角色:老节点主DN(下简称老DN),新节点主DN(简称新DN),新节点备DN(简称备DN)。CN收到MOVE BUCKETS命令后转发给老DN和新DN。
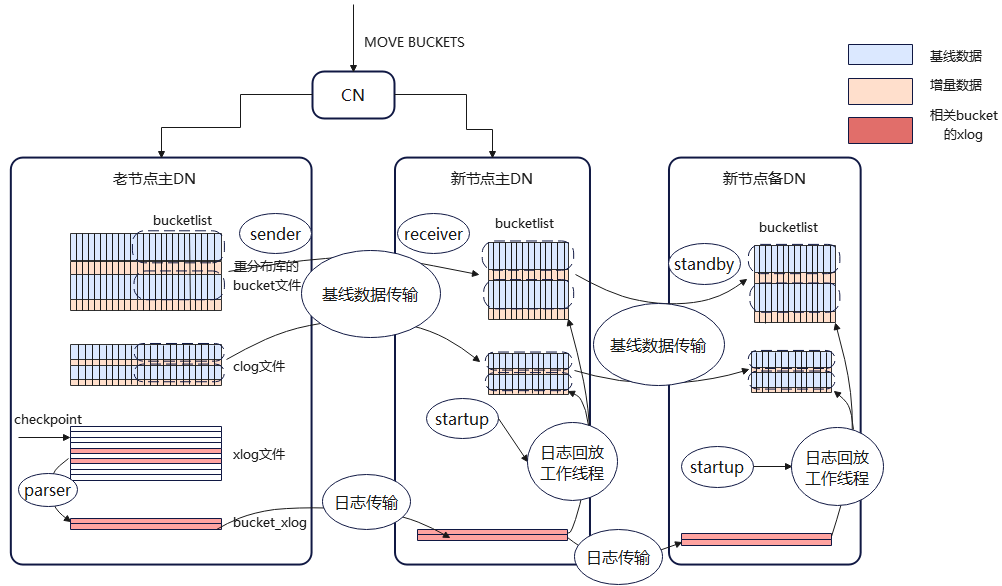
图1 日志多流示意图
新DN收到MOVE BUCKETS命令后启动receiver线程,receiver线程负责与其他节点进行数据传输。receiver线程与老DN建立连接,老DN启动sender线程;receiver与备DN建立连接,备DN启动standby线程。sender、standby线程也负责与其他节点进行数据传输。建连后,receiver向sender发送BUCKETBASE请求,sender将对应于bucketlist的基线数据(包括bucket数据文件、CLOG文件等)发送给receiver。receiver再将基线数据转发给standby。
另一方面,老DN收到MOVE BUCKETS命令后启动parser线程,将bucketlist对应的增量XLOG日志筛选出来放在bucketxlog目录下。待基线数据传输完成后,sender将增量XLOG日志发送给receiver,receiver转发给standby。日志传输完成后,新DN和备DN拉起startup线程,进入日志回放逻辑,通过回放增量xlog日志的方式,追加增量数据。
因此,追增完成的判断分为两部分,一部分是parser解析到老DNbucketlist对应的最新LSN,另一部分新DN和备DN回放完所有存量bucketxlog。
4.2.2 基线数据传输
sender收到receiver的BUCKETBASE请求后向receiver传输基线数据。按照tablespaceoid map、bucket数据文件、CLOG文件的顺序进行传输。若包含备机,基线数据部分都需要传输到备机。
tablespaceoid map包含sender节点上tablespace的name与oid的对应关系。由于sender和receiver分别在不同的DN上,同一个tablespace在不同DN上的tablespaceid可能是不同值,因此在日志回放前需要将日志中的tablespaceid及dbid替换成本地的tablespaceid及dbid。receiver根据name通过tablespaceoid map查到本地的tablespaceoid,在后续XLOG解析阶段进行替换。tablespaceid的映射关系需要传到备机。
bucket数据文件是位于对应database的数据目录下形如 *_b* 的文件,如:/base/db_oid目录或/pg_tblspc/tblspc_oid/db_oid目录下的2_b1,2_b1.1,2_b1_fsm,2_b1_vm等。
CLOG文件按bucket粒度拆分,在基线数据搬迁时,sender将对应bucket的所有CLOG文件均传输给receiver。CLOG搬迁涉及事务提交状态及可见性等问题,详见"事务相关" 小节。
另外,在接收完成基线数据后,遍历有CBI索引的表,扫描对应bucket上的heap页面,插入索引作为基线数据,详见"CBI索引相关处理"小节。
至此基线数据传输阶段完成,进入日志传输与回放阶段。
4.2.3 日志传输与回放
增量数据通过XLOG日志传输和日志回放的方式进行追增。首先sender节点的parser线程挑选出需要回放的日志并写入bucket_xlog目录。sender线程收到receiver的BUCKETXLOG请求后,从bucket_xlog目录读取日志传输给receiver。receiver节点的receiver线程将收到的XLOG日志转发给standby并写入bucket_xlog目录。最后startup线程启动回放工作线程进行回放。standby节点与receiver节点同理。
4.2.3.1 日志流的处理
(1)parser挑选bucketlist对应日志
DML日志只涉及一个bucket,在发送和接收时只需要根据bucketlist过滤即可。而commit/abort日志则可能包含多个bucket,因此需要特殊处理:
-
commit/abort日志只涉及一个bucket写日志时,则与DML日志一样,在header部分写入bucketid,在receiver回放时直接进行回放;
-
commit/abort日志包含多个bucket,则在header部分写入一个特殊的id(ComboBktId),在receiver回放时,将无关的bucketid给过滤掉,只回放bucketlist中的bucketid。
(2)日志格式修改
将bucket日志从原来的XLOG中挑出来写到新的日志文件后,原来的LSN信息丢失了,这导致后面回放时LSN校验失败。为了保留原始的LSN值,在解析日志时将原始的LSN值写在bucket日志的后面,在回放前,用这个LSN值去替换日志的LSN。图2为日志格式修改示意图。

图2 日志格式修改示意图
(3)日志中元数据的处理
日志多流技术中,新节点上的数据可能来自于不同的老节点,相同的tablespace及database在不同DN上对应的tablespaceid及dbid很可能是不同的,因此在日志回放前需要将日志中的tablespaceid及dbid替换成本地的tablespaceid及dbid。替换方法:
-
dbid: 在进行重分布前,在内核中记录各个节点本次要重分布的dbid,在日志回放的解析日志阶段,把日志里所有的block里的dbid进行替换。
-
tablespaceid: 由于tablespaceid可能会有多个,sender会把tablespace的name与id的对应关系传给receiver,receiver再根据name查出本地的tablespaceid,然后在解析阶段进行替换。tablespaceid的映射关系需要传到备机。
4.2.3.2 回放的处理
startup线程会拉起回放工作线程,包括pageredo线程、bucketwriter线程和bucketflush线程。同时使用私有缓冲区隔离,避免未上线前污染共有缓冲区。图3为日志回放示意图。
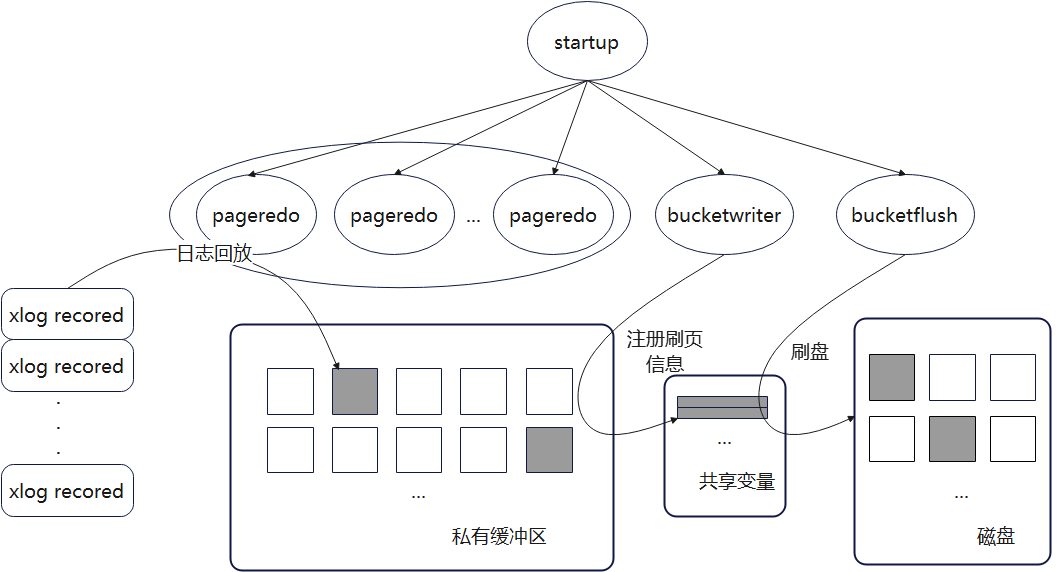
图3 日志回放示意图
pageredo线程负责日志回放,bucketwriter线程负责将私有缓冲区中的内容注册给bucketflush线程,bucketflush线程负责刷脏工作。同时新增共享变量,记录需要落盘的页面信息。
bucketwriter线程负责把缓冲区中的所有内容记录到共享变量中,在后台轮询工作。bucketflush线程启动时会初始化本地hash表,bucketflush线程从共享变量中拷贝需要刷盘的信息到本地hash表中,完成落盘操作。
以上所有操作均在startup线程存在期间完成,扩容上线逻辑会判断bucketwriter线程是否完成刷页,bucketwriter线程会等待bucketflush线程完成落盘,因此上线提交时能够保证所有页面已经完成落盘。如果此时发生故障,上线事务回滚,下次重入时本批bucket重新进行move bucket全逻辑,以保证数据正确性。
4.2.4 CBI索引相关处理
GaussDB针对hashbucket表有两种索引,bucket全局索引(跨bucket索引,cross-bucket index, CBI)和bucket本地索引(local-bucket index, LBI)。CBI索引为段页式存储,表现为只有一个bucketnode为1024的relation,索引元组中额外存储tablebucketid,从而缩小扫描范围;LBI索引为hashbucket类型的特殊段页式存储,同hashbucket表,pg_class中虽只有一条记录,存储层有bucketnode为[0-1023]的fake relation存在,索引扫描时需逐个遍历bucket索引。
CBI索引比LBI索引少一层顺序遍历bucket的扫描,故查询性能显著提升。但由于CBI索引为段页式表,不会通过物理文件搬迁和bucket日志回放的方式进行重分布,故需对其进行特殊处理,思路仍然是基线数据+增量数据。图4为CBI索引基线数据构建与日志追增示意图。
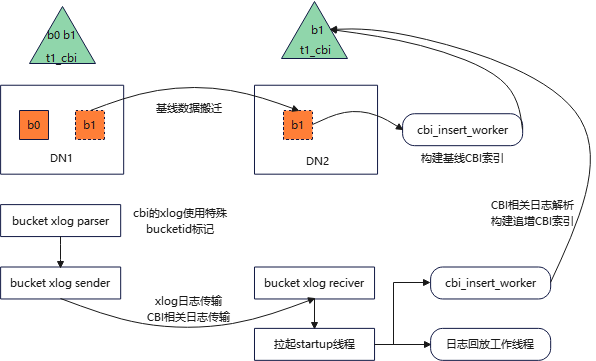
图4 CBI索引基线构建与追增示意图
-
基线数据搬迁完后,启动cbi_insert_worker线程,使用私有缓冲区。遍历有CBI索引的表,扫描对应bucket上的heap页面,插入索引作为基线数据。全部CBI索引基线数据构建完成后,完成基线数据搬迁阶段,进入日志传输与回放阶段。
-
CBI索引相关XLOG记录特殊bucketid,扩容时随日志流传输,作为扩容期间CBI增量数据的标记。
-
启动回放线程时启动cbi_insert_worker线程解析CBI索引相关的记录了特殊bucketid的XLOG日志,提取数据后插入索引。
4.3 事务相关
4.3.1 CLOG拆分
4.3.1.1 事务ID分配及CLOG/CSNLOG
为了在数据库内部区别不同的写事务,GaussDB会为它们分配唯一的标识符,即事务id(transaction id,缩写xid),xid是uint64单调递增的序列,从FIRST_NORMAL_XACT_ID (3)开始分配。对于页面上的元组,xmin记录插入时的xid,xmax记录删除时的xid。当事务结束后,使用CLOG记录是否提交。对于每个xid,一共有4种状态:事务未开始或还在运行中、已经提交、已经回滚、子事务已经commit而父事务状态未知。可以用2个bit记录一个xid状态,所以8K的页面可以记录32K个xid状态。
使用CSNLOG(commit sequence number log)记录该事务提交的序列,用于可见性判断。CSN是uint64单调递增的序列,从COMMITSEQNO_FIRST_NORMAL(3)开始分配。一个CSN占用8字节,所以一个8K的页面可以记录1K个xid状态。CSNLOG以及CLOG均采用了SLRU(simple least recently used,简单最近最少使用)机制来实现文件的读取及刷盘操作。
4.3.1.2 CLOG拆分背景
xid是由各个DN自己维护的。在hashbucket扩容中,不同源DN的CLOG可能会搬迁到同一个新DN。同一个xid在不同DN记录的提交状态可能不一样,无法用同一个CLOG去表示不同bucket的提交状态。例如DN1、DN2为源节点,DN3为新节点,扩容重分布过程中会把DN1和DN2中的CLOG日志搬到DN3。xid100的状态在DN1是已提交,在DN2是已回滚。因此,CLOG需要按bucket粒度拆分。
拆分后的CLOG目录如下图x,路径为数据目录/pg_clog。子目录名1表示bucketid,文件名000000000000表示对应的CLOG段文件。对于非hashbucket表,每SLRU_PAGES_PER_SEGMENT(2048)个页面切分一个段文件,文件名长度为8;对于bucket子目录下的CLOG文件,每SLRU_CLOG_PAGES_PER_SEGMENT(4)个页面切分一个段文件,文件名长度为10。文件名长度不同是为了方便解析工具判断段文件最多可容纳的页面数。
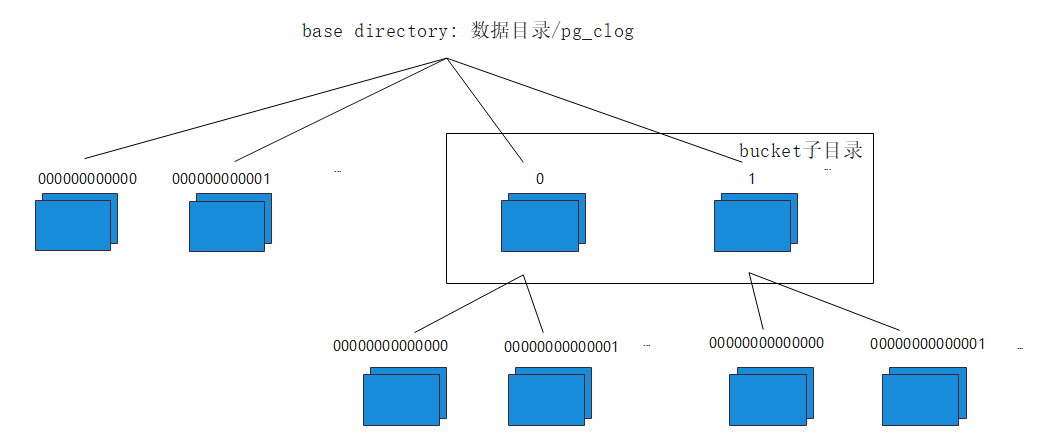
图5 CLOG磁盘目录
4.3.1.3 CLOG拆分处理可见性判断
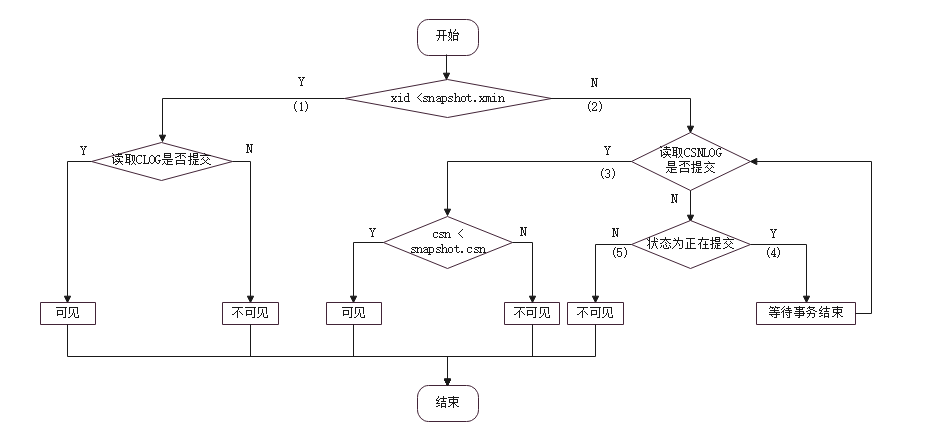
图6 快照可见性判断流程图
snapshot.xmin:获取快照时记录当前活跃的最小的xid
snapshot.snapshotcsn:当前最新提交的CSN号 + 1
如上图6所示,xid对于当前快照是否可见的简化有步骤如下:
(1) xid < snapshot.xmin,事务在快照开始前已经结束,根据CLOG状态判断是否提交:CLOG显示已提交,可见;否则,不可见。
(2) xid≥snapshot.xmin,事务在快照开始前未结束,根据CSNLOG读取xid对应的CSN;
(3) 如果CSN已提交,即CSN≥3,没有子事务标志,没有正在提交标志。如果CSN< snapshot.snapshotcsn,则可见。否则不可见。
(4) 如果CSN正在提交,则等待事务结束,重入(3)判断。
(5) 其他情况,不可见。
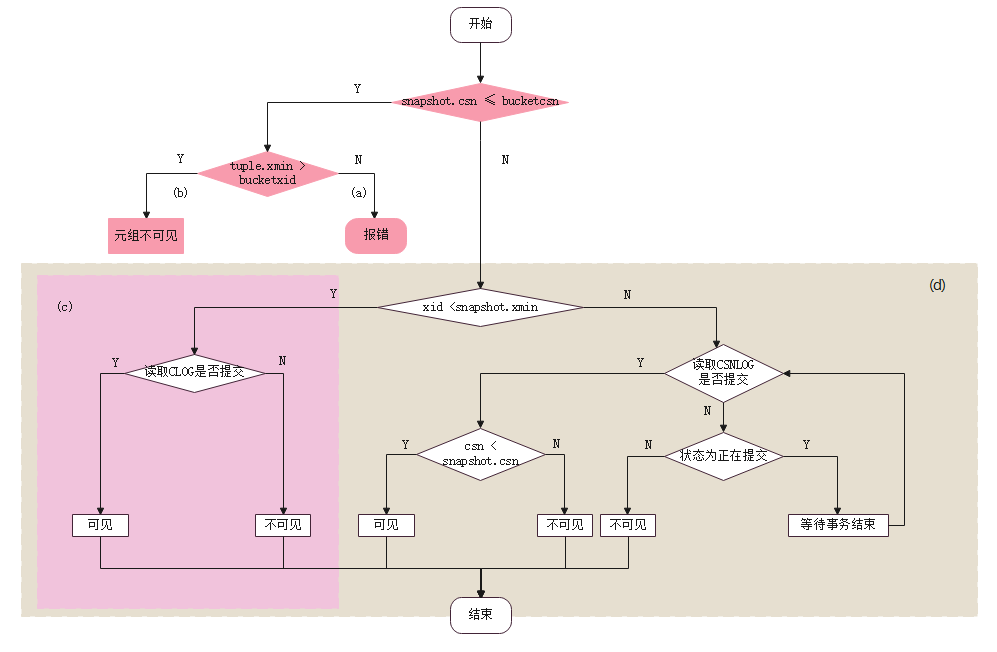
图7 新节点快照可见性判断流程图
图7为新节点快照可见性判断流程图。
bucketxid:bucket粒度,在当前库,新节点产生的最小xid
bucketcsn:bucket粒度,在当前库,来自源节点的最大CSN
bucket上线后,CLOG和数据文件已搬迁,CSNLOG未搬迁。CLOG拆分后对可见性判断:
-
老快照判断迁移数据的可见性:报错。因为CSNLOG未搬迁,无法读取CSN号;
-
老快照判断新数据的可见性:元组是在bucket上线后插入的,即tuple.xmin > bucketxid。不可见;
-
新快照判断迁移数据的可见性:通过CLOG;
-
新快照判断新数据的可见性:正常可见性判断逻辑;
4.3.2 xid调整
4.3.2.1 xid调整背景
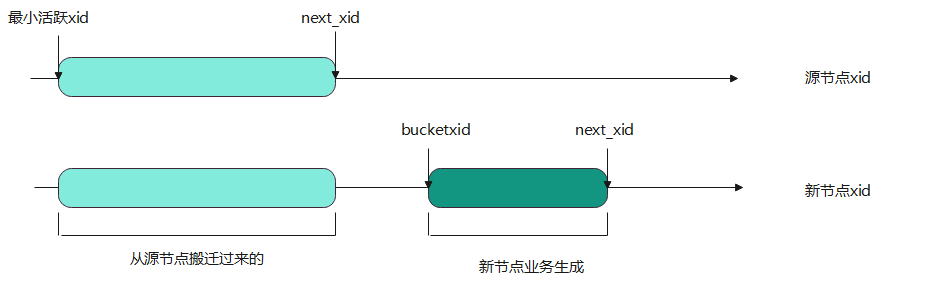
图8 源节点、新节点xid范围示意图
如上图8所示,新节点的每个bucket粒度的xid可以看成两段。左边一段是从源节点迁移过来的,也就是搬迁的CLOG中记录的。它的最大值next_xid是源节点下一个写事务分配的xid,最小值是最小活跃xid , 是源节点当前最小的需要通过CLOG读取事务状态的xid。Vaccum操作会清理掉页面中小于最小活跃xid的值,如果事务提交,则改为FROZEN_XACT_ID(2),表示对所有快照可见。如果事务回滚,则清理掉对应元组。
右边一段是新节点业务生成的,最小的xid是bucket在第一个库的上线事务对应的id,记为bucketxid。这个值可以在pg_hashbucket系统表的bucketxid列获取。
如果不调整xid, 那么新节点业务生成的xid和从源节搬迁过来的xid就有重合的问题,导致可见性判断错误。例如DN1为源节点,DN2为新节点。重分布前,bucket1的xid100的状态在DN1是已提交。DN2的xid没有调整,是从3开始分配的。bucket1在DN2上线后,使用xid100,并且状态为已回滚。那么在DN2读取迁移数据中的xid100提交状态错误。
4.3.2.2 xid调整流程
在加节点过程中,会调整新节点下一个要分配的xid,图9为xid调整流程图。
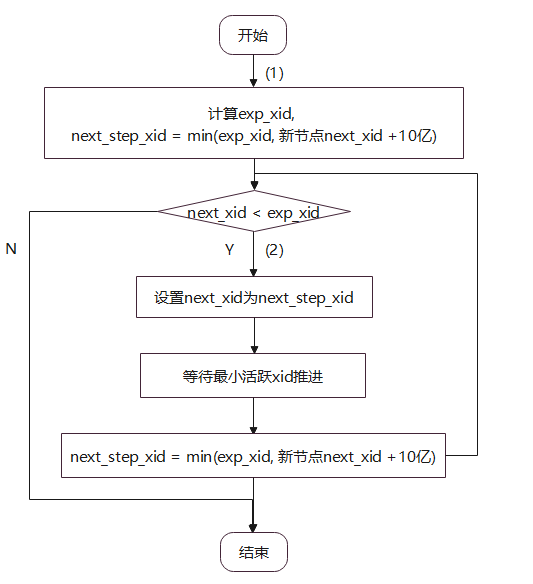
图9 xid调整流程图
-
根据源节点下一个要分配的xid(对应图中的next_xid)和业务对xid的消耗量计算新节点的预期xid计算exp_xid。计算下一步调整到的xid为next_step_xid = min(exp_xid, 新节点next_xid + 10亿)。这里需要分步调整xid。页面的xid取值范围依赖当前的最小活跃xid。如果一次设置为预期值,最小活跃事务号没有办法及时更新,则新设置的xid可能会超过已有页面的xid合法表达范围,出现写业务报错。
-
如果新节点next_xid < exp_xid,设置新节点next_xid为next_step_xid,并等待当前活跃事务的最小值推进,更新next_step_xid,直到next_xid不小于预期值。
4.3.3 bucket锁
类似于常规锁的表锁,对于hashbucket表,物理文件是库级bucket化的,扩容过程也是按照bucket级别上线的,因此引入一种新型的锁——bucket锁,每个bucket对应一把锁。只有用户业务的场景,DML和DDL业务间的并发仍然通过表锁实现,所有业务都拿bucket的一级锁。当用户扩容时,此时会发生bucket文件的搬迁,同时实现元数据从老节点下线,新节点上线的动作,此时需要通过bucket锁对用户业务做互斥。因此,bucket锁主要用在hashbucket在线扩容期间bucket在新节点上线时和在线业务做互斥,保证业务数据正确。
新增如下的语法来实现这一功能:
LOCK BUCKETS(bucketlist) IN LOCK_MODE [CANCELABLE];
其中,bucketlist如0,1,2,3表示次轮上线的bucket桶号,取值范围0-1023;
LOCK_MODE只有两种级别:ACCESS SHARE MODE和ACCESS EXCLUSIVE MODE
增加可选项[CANCELABLE]表示是否通过cancel用户业务而保证扩容拿到锁。
在线业务和扩容的交互如下图10所示:
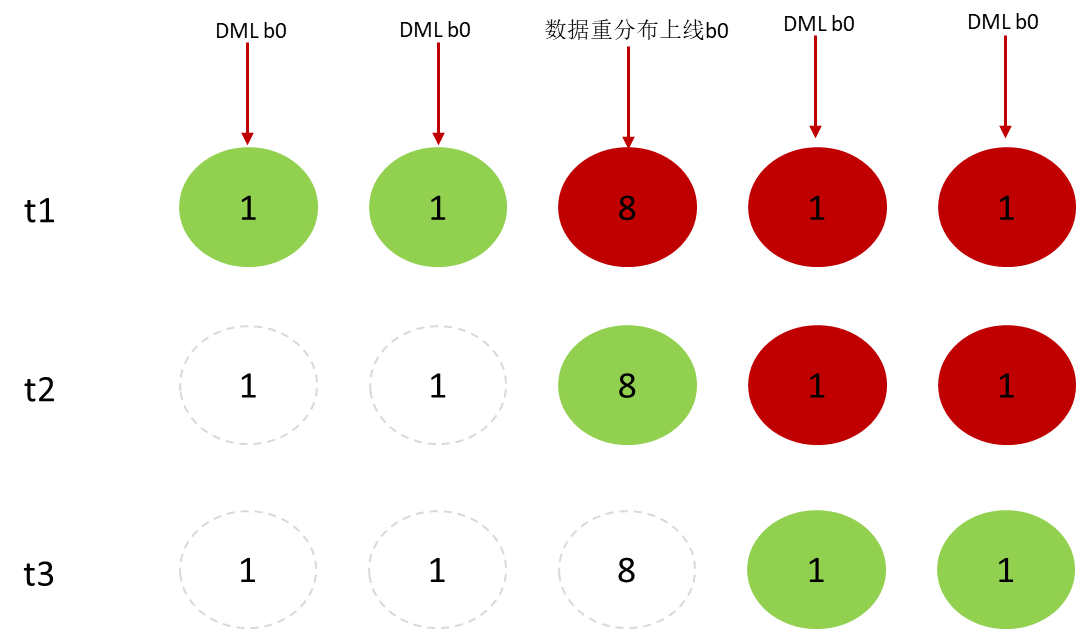
图10 xid调整流程图
-
t1时刻:对bucket 0操作的DML在上线事务之前的拿锁成功,数据重分布上线事务拿bucket 0的8级锁处于等待状态,排在数据重分布上线事务之后其它线程对于bucket 0的访问等在上线事务的8级锁上。
-
t2时刻:排在上线事务之前的用户业务放锁,上线事务持8级锁成功,之后所有访问bucket 0的用户业务均阻塞。
-
t3时刻:bucket 0在老节点下线,新节点上线,用户业务拿到bucket 0的锁获取最新的数据分布方式。
如果CN上能确定当前操作的bucket,则在CN上拿对应bucket的1级锁,如果不能确定则在DN上拿锁,通过前文提到过的pg_hashbucket记录的bucketlist进行过滤。扩容上线的LOCK BUCKETS语句现在执行CN拿锁成功再发送到其它所有CN和DN拿锁,全部成功则成功。
以上内容从hashbucket扩容方面对GaussDB高弹性能力进行了解读,下篇将从扩容实践方面继续介绍GaussDB高弹性技术,敬请期待!