【大模型技术教程】FastGPT一站式解决方案[1-部署篇]:轻松实现RAG-智能问答系统
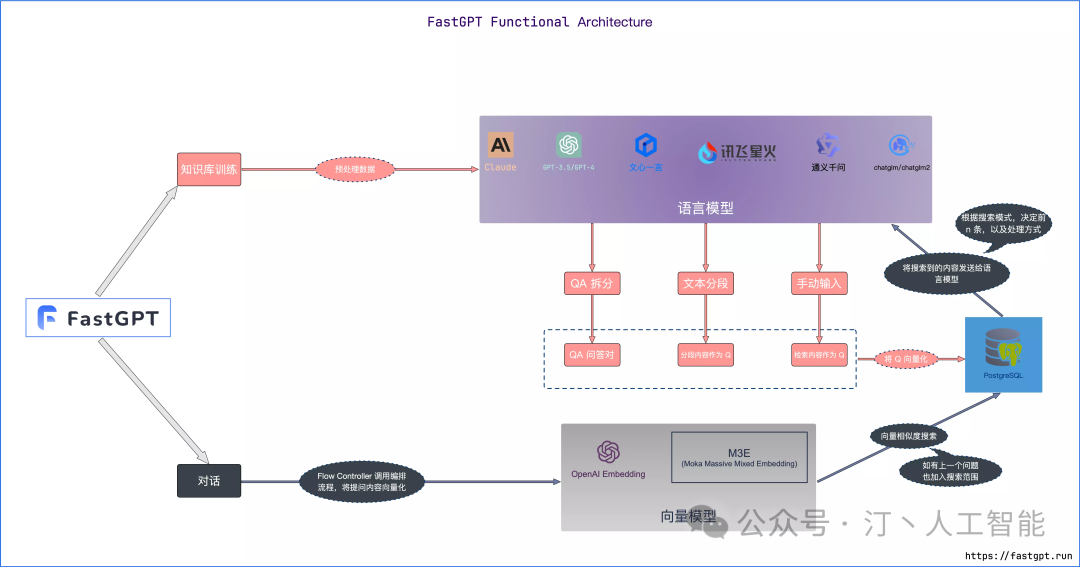
FastGPT是一个功能强大的平台,专注于知识库训练和自动化工作流程的编排。它提供了一个简单易用的可视化界面,支持自动数据预处理和基于Flow模块的工作流编排。FastGPT支持创建RAG系统,提供自动化工作流程等功能,使得构建和使用RAG系统变得简单,无需编写复杂代码。
-
官方:https://fastgpt.in/
-
github:https://github.com/labring/FastGPT
专属 AI 客服:通过导入文档或已有问答对进行训练,让 AI 模型能根据你的文档以交互式对话方式回答问题。
-
多库复用,混用
-
chunk 记录修改和删除
-
源文件存储
-
支持手动输入,直接分段,QA 拆分导入
-
支持 txt,md,html,pdf,docx,pptx,csv,xlsx (有需要更多可 PR file loader)
-
支持 url 读取、CSV 批量导入
-
混合检索 & 重排
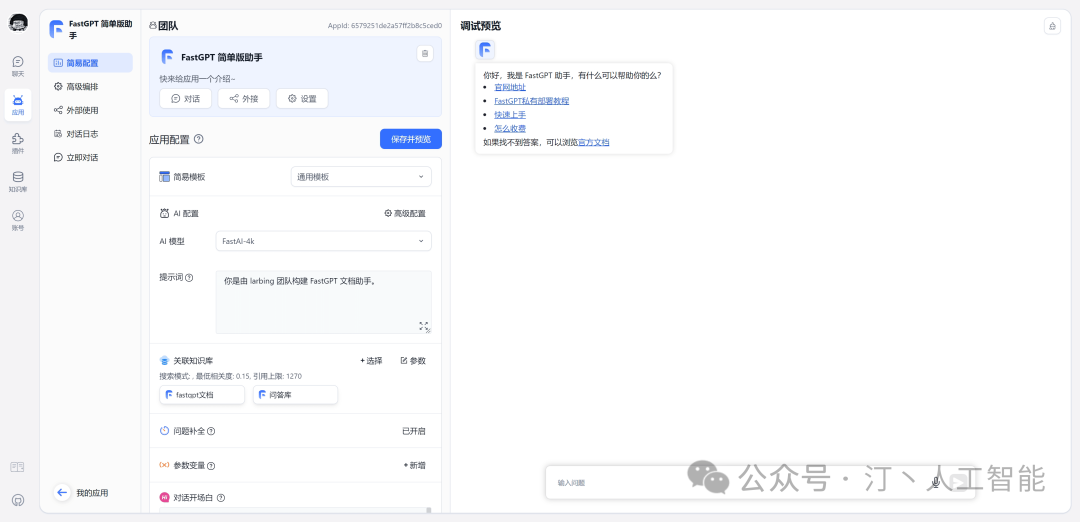
简单易用的可视化界面:FastGPT 采用直观的可视化界面设计,为各种应用场景提供了丰富实用的功能。通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。
-
自动数据预处理:提供手动输入、直接分段、LLM 自动处理和 CSV 等多种数据导入途径,其中“直接分段”支持通过 PDF、WORD、Markdown 和 CSV 文档内容作为上下文。FastGPT 会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。 -
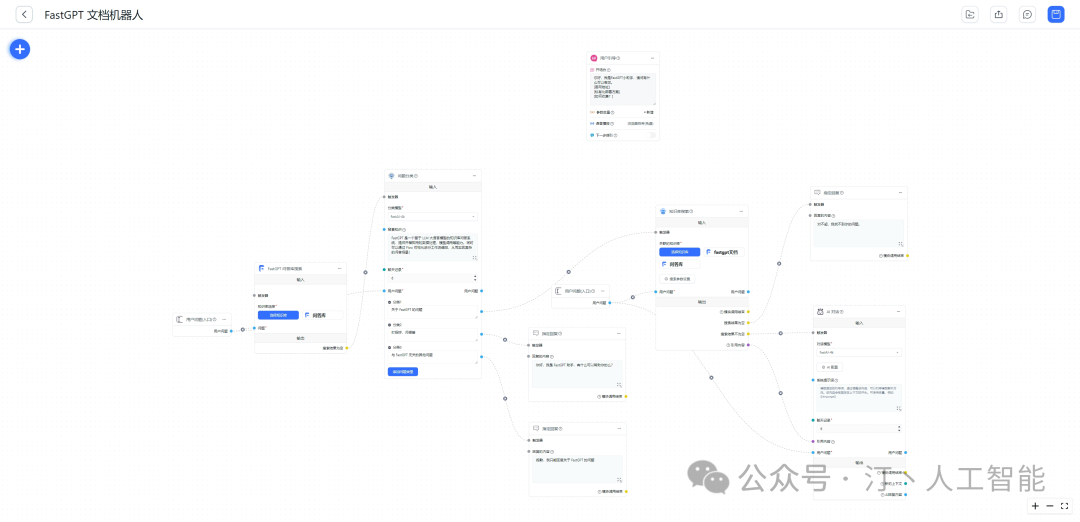
工作流编排:基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。
-
提供简易模式,无需操作编排
-
工作流编排
-
工具调用
-
插件 - 工作流封装能力
-
Code sandbox
强大的 API 集成:FastGPT 对外的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。
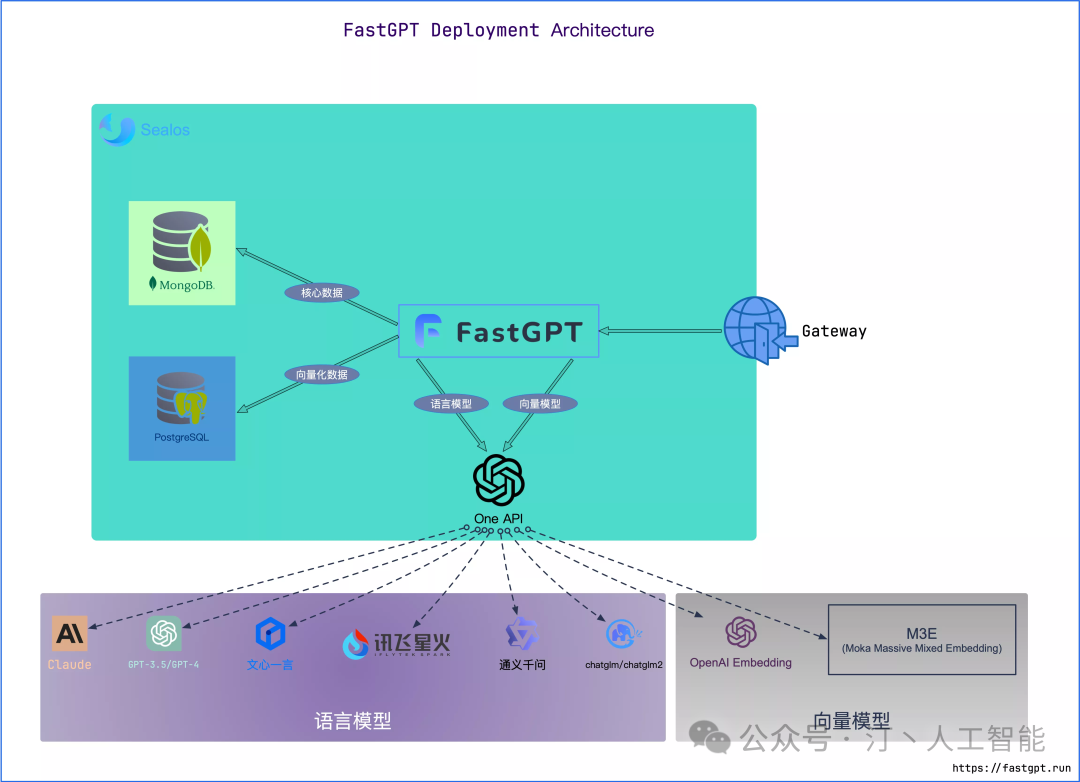
1.Sealos 云端快速部署
github:https://github.com/labring/sealos/blob/main
一款以 Kubernetes 为内核的云操作系统发行版,使用 Sealos 服务,无需采购服务器、无需域名,支持高并发 & 动态伸缩,并且数据库应用采用 kubeblocks 的数据库,在 IO 性能方面,远超于简单的 Docker 容器部署
-
核心功能
-
应用管理:在模板市场中轻松管理并快速发布可公网访问的分布式应用。
-
数据库管理:秒级创建高可用数据库,支持 MySQL、PostgreSQL、MongoDB 和 Redis。
-
公私一致:即是公有云也是私有云,支持传统应用无缝迁移到云环境。
-
优势
-
高效 & 经济:仅需为容器付费,自动伸缩杜绝资源浪费,大幅度节省成本。
-
通用性强,无心智负担:专注于业务本身,无需担心复杂性,几乎没有学习成本。
-
灵活 & 安全:多租户共享机制在确保安全的同时,实现资源隔离与高效协作。
北京区服务提供商为火山云,国内用户可以稳定访问,但无法访问 OpenAI 等境外服务,价格约为新加坡区的 1/4。登录链接:https://bja.sealos.run/?openapp=system-template%3FtemplateName%3Dfastgpt
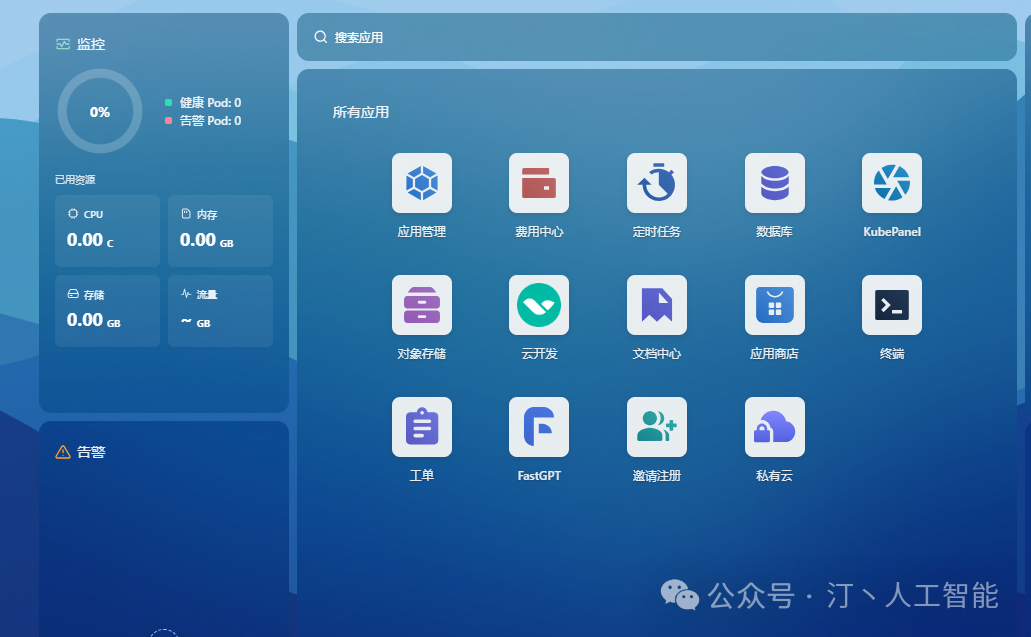
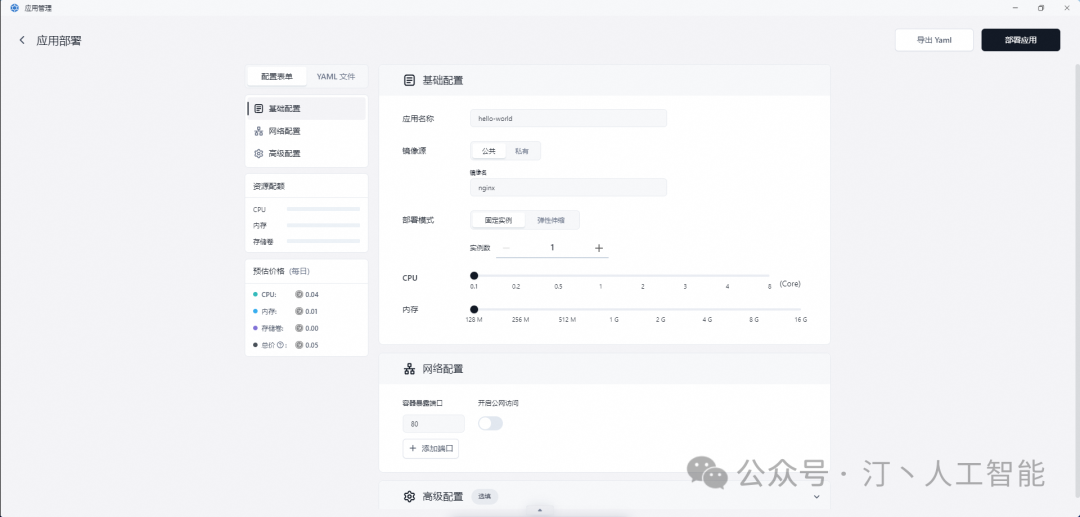
登录FastGPT直接就可以使用,模板市场有一些例子
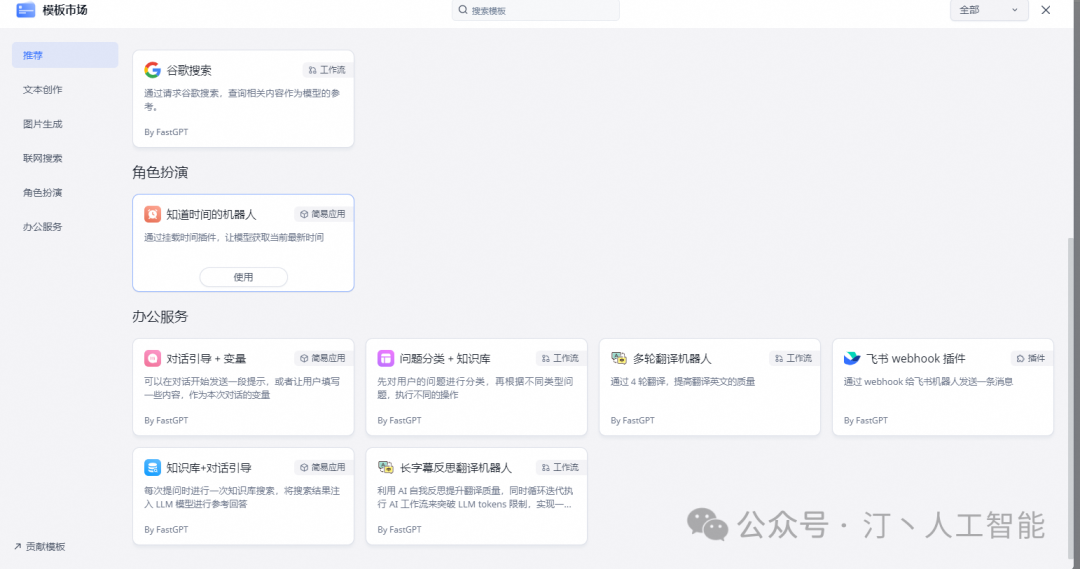
同时Sealos市场也提供了很多AI应用
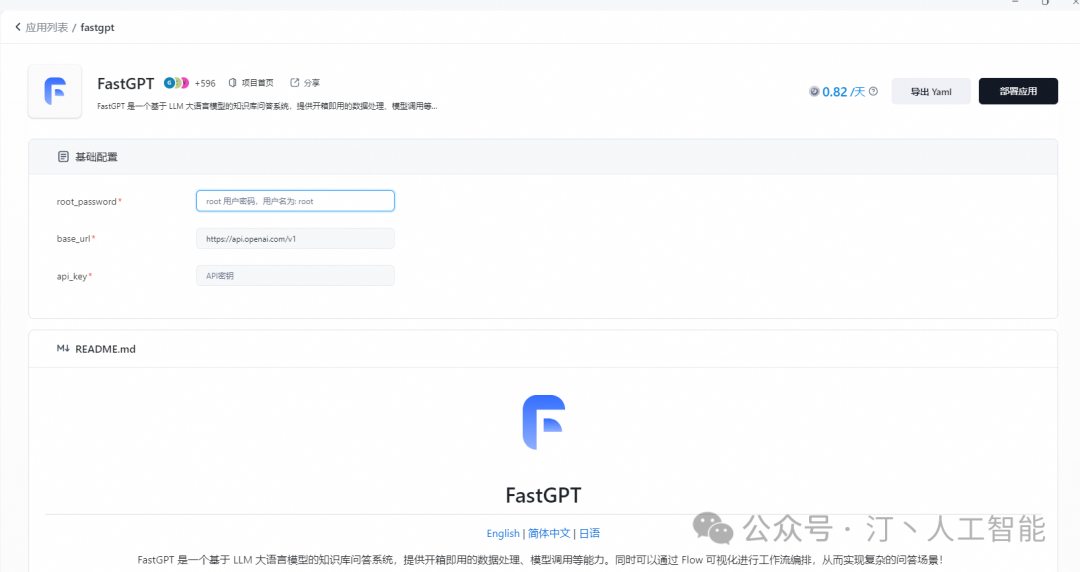
更多配置见:https://doc.tryfastgpt.ai/docs/development/sealos/
2.Docker部署
2.1 推荐配置
MongoDB:用于存储除了向量外的各类数据,PostgreSQL/Milvus:存储向量数据,OneAPI: 聚合各类 AI API,支持多模型调用
- PgVector 版本
体验测试首选
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c2g | 2c4g |
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
“c”代表CPU核心数量,“g”代表内存大小,而“GB”则是存储空间大小的单位
- Milvus 版本
对于千万级以上向量性能更优秀。
点击查看 Milvus 官方推荐配置
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c8g | 4c16g |
| 100w 组向量 | 未测试 | |
| 500w 组向量 | ||
具体配置参考:https://milvus.io/docs/prerequisite-docker.md
- zilliz cloud 版本
亿级以上向量首选。由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
2.2 前置工作
- 确保网络环境
如果使用OpenAI等国外模型接口,请确保可以正常访问,否则会报错:Connection error 等。 方案可以参考:代理方案
- 准备 Docker 环境
#安装 Docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
#安装 docker-compose
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
#验证安装
docker -v
docker-compose -v
#如失效,自行百度~2.3 开始部署
1. 下载 docker-compose.yml
非 Linux 环境或无法访问外网环境,可手动创建一个目录,并下载配置文件和对应版本的docker-compose.yml,在这个文件夹中依据下载的配置文件运行 docker,若作为本地开发使用推荐docker-compose-pgvector版本,并且自行拉取并运行sandbox和fastgpt,并在 docker 配置文件中注释掉sandbox和fastgpt的部分
-
config.json
-
docker-compose.yml (注意,不同向量库版本的文件不一样)
所有
docker-compose.yml配置文件中MongoDB为 5.x,需要用到 AVX 指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24**(需要自己在 docker hub 下载,阿里云镜像没做备份)
Linux 快速脚本
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json#pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
#milvus 版本
#curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
#zilliz 版本
#curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml如果下载不下来建议采用下面方法:
从github官网下载所有文件,然后进入FastGPT-main/files/docker
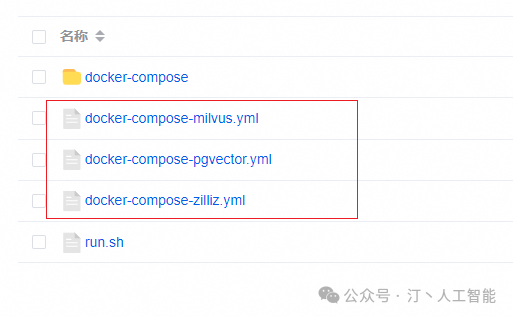
docker compose -f docker-compose-pgvector.yml up
#cp docker-compose-pgvector.yml docker-compose.yml
#docker compose up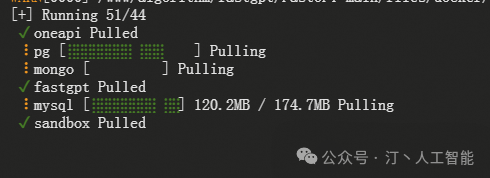
并将/projects/app/data/config.json 移动到docker目录下
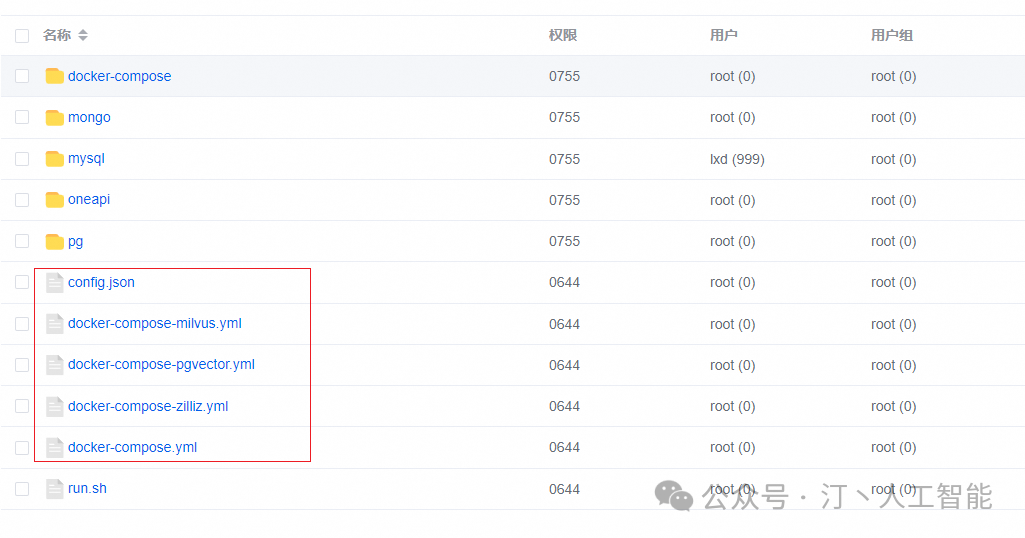
2. 修改 docker-compose.yml 环境变量
PG和milvus无需修改,zilliz参考如下
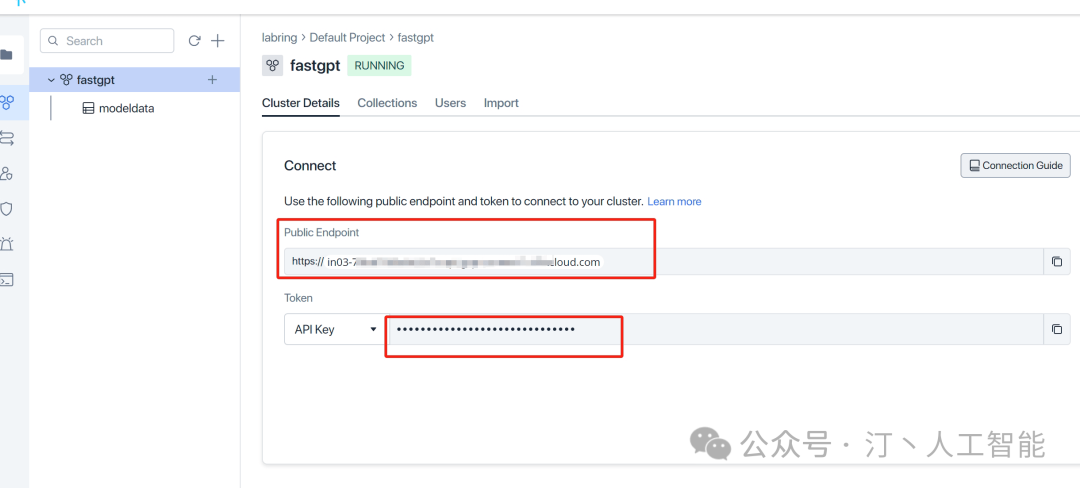
修改MILVUS_ADDRESS和MILVUS_TOKEN链接参数,分别对应 zilliz 的 Public Endpoint 和 Api key,记得把自己 ip 加入白名单。
3. 启动容器
在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在 2.17 以上,否则可能无法执行自动化命令。
4. 打开 OneAPI 添加模型
可以通过ip:3001访问 OneAPI,默认账号为root密码为123456。
在 OneApi 中添加合适的 AI 模型渠道。点击查看相关教程
- 添加月之暗面为例商业模型为例
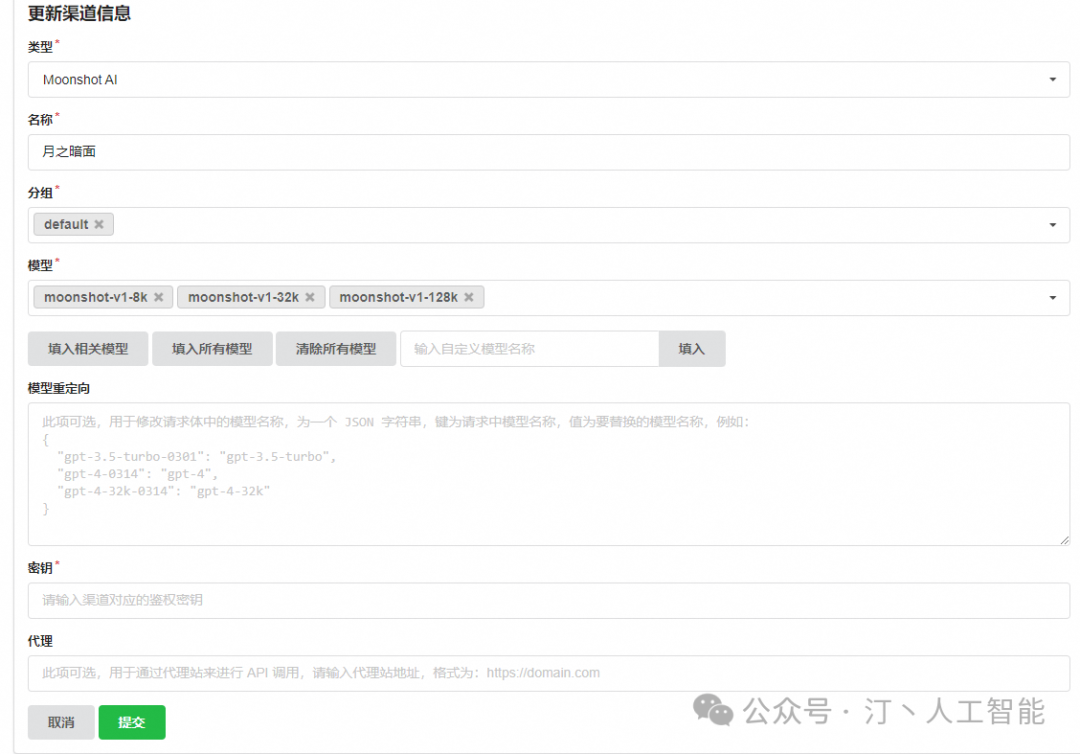
- 修改config.json文件,添加对应模型
,{"model": "moonshot-v1-128k","name": "moonshot-v1-128k","avatar": "/imgs/model/moonshot.svg","maxContext": 125000,"maxResponse": 8000,"quoteMaxToken": 120000,"maxTemperature": 1.2,"charsPointsPrice": 0,"censor": false,"vision": true,"datasetProcess": false,"usedInClassify": true,"usedInExtractFields": true,"usedInToolCall": true,"usedInQueryExtension": true,"toolChoice": true,"functionCall": false,"customCQPrompt": "","customExtractPrompt": "","defaultSystemChatPrompt": "","defaultConfig": {}}然后重启docker
docker-compose down
docker-compose up -d
5. 访问 FastGPT
目前可以通过 ip:3000 直接访问 (注意防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的 DEFAULT_ROOT_PSW。
如果需要域名访问,请自行安装并配置 Nginx。
首次运行,会自动初始化 root 用户,密码为 1234(与环境变量中的DEFAULT_ROOT_PSW一致),日志里会提示一次MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;可忽略。
2.4 Xinference 部署模型接入
Xinference 是一款开源模型推理平台,除了支持 LLM,它还可以部署 Embedding 和 ReRank 模型,这在企业级 RAG 构建中非常关键。同时,Xinference 还提供 Function Calling 等高级功能。还支持分布式部署,也就是说,随着未来应用调用量的增长,它可以进行水平扩展。
-
详细安装内容参考:Xinference实战指南:全面解析LLM大模型部署流程,加速AI项目落地进程
-
官网:https://xorbits.cn/inference
-
github:https://github.com/xorbitsai/inference/tree/main
-
官方手册:https://inference.readthedocs.io/zh-cn/latest/index.html
如果你的目标是在一台 Linux 或者 Window 服务器上部署大模型,可以选择 Transformers 或 vLLM 作为 Xinference 的推理后端:
-
Transformers:通过集成 Huggingface 的 Transformers 库作为后端,Xinference 可以最快地 集成当今自然语言处理(NLP)领域的最前沿模型(自然也包括 LLM)。 -
vLLM: vLLM 是由加州大学伯克利分校开发的一个开源库,专为高效服务大型语言模型(LLM)而设计。它引入了 PagedAttention 算法, 通过有效管理注意力键和值来改善内存管理,吞吐量能够达到 Transformers 的 24 倍,因此 vLLM 适合在生产环境中使用,应对高并发的用户访问。 -
SGLang:是一个用于大型语言模型和视觉语言模型的推理框架。基于并增强了多个开源 LLM 服务引擎(包括LightLLM、vLLM和Guidance )的许多优秀设计。SGLang 利用了FlashInfer注意力性能 CUDA 内核,并集成了受gpt-fast启发的 torch.compile -
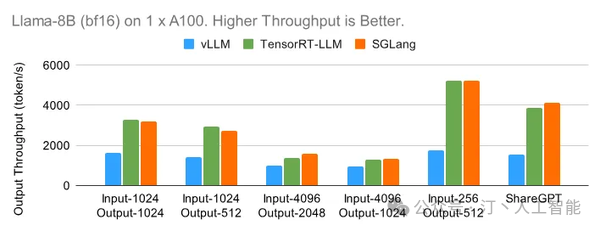
1 x A100 (bf16) 上的 Llama-8B 从小模型 Llama-8B 开始,下图展示了每个引擎在离线设置下在六个不同数据集上可以实现的最大输出吞吐量。TensorRT-LLM 和 SGLang 都可以在输入较短的数据集上实现高达每秒 5000 个 token 的出色吞吐量。
假设你服务器配备 NVIDIA 显卡,可以cuda安装教程详解指令来安装 CUDA,从而让 Xinference 最大限度地利用显卡的加速功能。
安装 Xinference
详细安装内容参考:Xinference实战指南:全面解析LLM大模型部署流程,加速AI项目落地进程
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name xinference python=3.11
conda activate xinference以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
pip install "xinference"
pip install "xinference[ggml]"
pip install "xinference[pytorch]"#安装xinference所有包
pip install "xinference[all]"pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[transformers,vllm]" # 同时安装
#或者一次安装所有的推理后端引擎
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simplepython -c "import torch; print(torch.cuda.is_available())"如果输出结果为True,则表示 PyTorch 正常,否则需要重新安装 PyTorch。
- 启动xinference 服务(UI) Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
xinference-local --host 0.0.0.0 --port 7861xinference-local -H 0.0.0.0将本地模型接入 One API
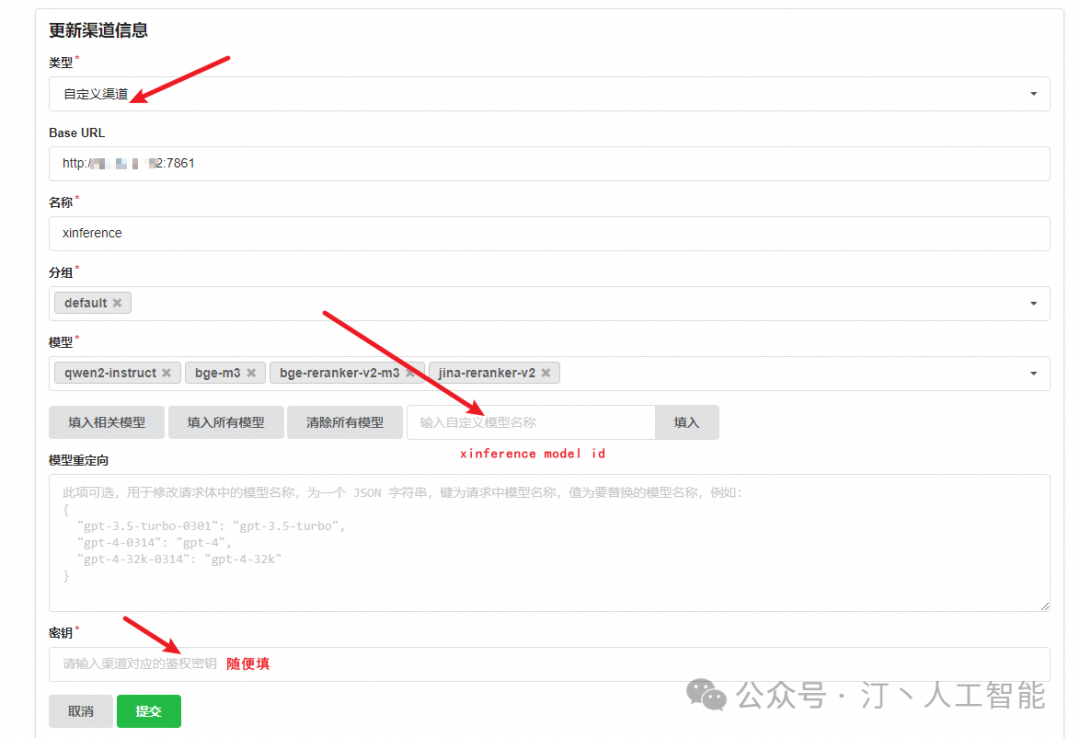
为 qwen2-instruct 添加一个渠道,这里的 Base URL 需要填 Xinference 服务的端点,并且注册 qwen2-instruct (模型的 UID) 。
可以使用以下命令进行测试:将 <oneapi_url> 替换为你的 One API 地址,<oneapi_token> 替换为你的 One API 令牌。model 为刚刚在 One API 填写的自定义模型。
curl --location --request POST 'https://<oneapi_url>/v1/chat/completions' \
--header 'Authorization: Bearer <oneapi_token>' \
--header 'Content-Type: application/json' \
--data-raw '{"model": "qwen2-instructt","messages": [{"role": "user", "content": "Hello!"}]
}'将本地模型接入 FastGPT
由于环境变量不利于配置复杂的内容,新版 FastGPT 采用了 ConfigMap 的形式挂载配置文件,你可以在 projects/app/data/config.json 看到默认的配置文件。可以参考 docker-compose 快速部署 来挂载配置文件。
开发环境下,你需要将示例配置文件 config.json 复制成 config.local.json 文件才会生效。
参考官网配置文件介绍:
- 关于模型 logo 统一放置在项目的public/imgs/model/xxx目录中,目前内置了以下几种,如果有需要,可以PR增加。默认头像为 Hugging face 的 logo~
/imgs/model/baichuan.svg - 百川
/imgs/model/chatglm.svg - 智谱
/imgs/model/calude.svg - calude
/imgs/model/ernie.svg - 文心一言
/imgs/model/moonshot.svg - 月之暗面
/imgs/model/openai.svg - OpenAI GPT
/imgs/model/qwen.svg - 通义千问
/imgs/model/yi.svg - 零一万物
/imgs/model/gemini.svg - gemini
/imgs/model/deepseek.svg - deepseek
/imgs/model/minimax.svg - minimax- LLM
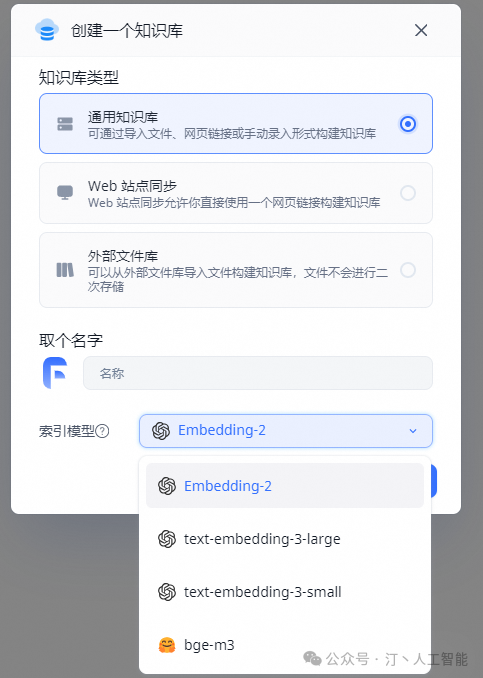
"feConfigs": {"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。},"systemEnv": {"vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。},"llmModels": [{"model": "gpt-3.5-turbo", // 模型名(对应OneAPI中渠道的模型名)"name": "gpt-3.5-turbo", // 别名"avatar": "/imgs/model/openai.svg", // 模型的logo"maxContext": 16000, // 最大上下文"maxResponse": 4000, // 最大回复"quoteMaxToken": 13000, // 最大引用内容"maxTemperature": 1.2, // 最大温度"charsPointsPrice": 0, // n积分/1k token(商业版)"censor": false, // 是否开启敏感校验(商业版)"vision": false, // 是否支持图片输入"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型"customExtractPrompt": "", // 自定义内容提取提示词"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词"defaultConfig":{} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)}],"vectorModels": [{"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)"name": "Embedding-2", // 模型展示名"avatar": "/imgs/model/openai.svg", // logo"charsPointsPrice": 0, // n积分/1k token"defaultToken": 700, // 默认文本分割时候的 token"maxToken": 3000, // 最大 token"weight": 100, // 优先训练权重"defaultConfig":{}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)"queryConfig": {} // 参训时的额外参数}], {"model": "qwen2-instruct","name": "qwen2-instruct","avatar": "/imgs/model/qwen.svg","maxContext": 125000,"maxResponse": 8000,"quoteMaxToken": 120000,"maxTemperature": 1.2,"charsPointsPrice": 0,"censor": false,"vision": true,"datasetProcess": false,"usedInClassify": true,"usedInExtractFields": true,"usedInToolCall": true,"usedInQueryExtension": true,"toolChoice": true,"functionCall": false,"customCQPrompt": "","customExtractPrompt": "","defaultSystemChatPrompt": "","defaultConfig": {}}- 向量模型
{"model": "bge-m3","name": "bge-m3","avatar": "/imgs/model/bge.svg","charsPointsPrice": 0,"defaultToken": 512,"maxToken": 3000,"weight": 100}- ReRank 接入(私有部署)
配置文件中的 reRankModels 为重排模型,虽然是数组,不过目前仅有第1个生效。
{"reRankModels": [{"model": "bge-reranker-base", // 随意"name": "检索重排-base", // 随意"charsPointsPrice": 0,"requestUrl": "{{host}}/v1/rerank","requestAuth": "安全凭证,已自动补 Bearer"}]
}格式参考:目前仅有第1个生效
"reRankModels": [{"model": "bge-reranker-v2-m3", // 随意"name": "bge-reranker-v2-m3", // 随意"charsPointsPrice": 0,"requestUrl": "http://10.80.1.252:7861/v1/rerank","requestAuth": "Bearer"},{"model": "jina-reranker-v2", // 随意"name": "jina-reranker-v2", // 随意"charsPointsPrice": 0,"requestUrl": "http://10.80.1.252:7861/v1/rerank","requestAuth": "Bearer"}],- ReRank 接入(Cohere) 这个重排模型对中文不是很好,不如 bge 的好用。 申请 Cohere 官方 Key: https://dashboard.cohere.com/api-keys
{"reRankModels": [{"model": "rerank-multilingual-v2.0", // 这里的model需要对应 cohere 的模型名"name": "检索重排", // 随意"requestUrl": "https://api.cohere.ai/v1/rerank","requestAuth": "Coherer上申请的key"}]
}配置完成后重启fastgpt
docker-compose down
docker-compose up -d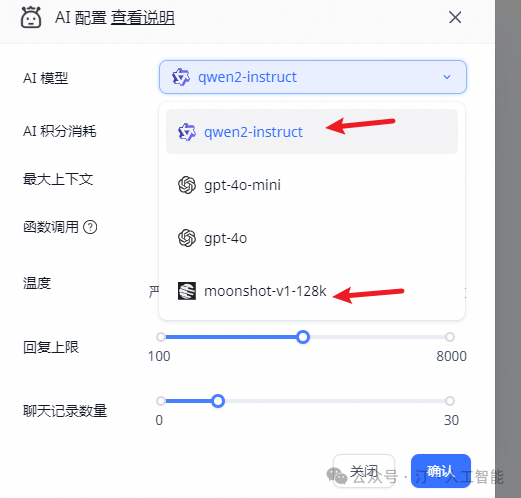
3.FAQ (1)
3.1 Mongo 副本集自动初始化失败
最新的 docker-compose 示例优化 Mongo 副本集初始化,实现了全自动。目前在 unbuntu20,22 centos7, wsl2, mac, window 均通过测试。仍无法正常启动,大部分是因为 cpu 不支持 AVX 指令集,可以切换 Mongo4.x 版本。
如果是由于,无法自动初始化副本集合,可以手动初始化副本集:
-
终端中执行下面命令,创建 mongo 密钥:
-
修改 docker-compose.yml,挂载密钥
-
重启服务
-
进入容器执行副本集合初始化
3.2 如何修改 API 地址和密钥
默认是写了 OneAPi 的连接地址和密钥,可以通过修改docker-compose.yml中,fastgpt 容器的环境变量实现。
OPENAI_BASE_URL(API 接口的地址,需要加 / v1) CHAT_API_KEY(API 接口的凭证)。
修改完后重启:
3.3 如何更新版本
-
查看更新文档,确认要升级的版本,避免跨版本升级。
-
修改镜像 tag 到指定版本
-
执行下面命令会自动拉取镜像:
-
执行初始化脚本(如果有)
3.4 如何自定义配置文件
修改config.json文件,并执行docker-compose down再执行docker-compose up -d重起容器。具体配置,参考配置详解。
3.5 如何检查自定义配置文件是否挂载
-
docker logs fastgpt可以查看日志,在启动容器后,第一次请求网页,会进行配置文件读取,可以看看有没有读取成功以及有无错误日志。 -
docker exec -it fastgpt sh进入 FastGPT 容器,可以通过ls data查看目录下是否成功挂载config.json文件。可通过cat data/config.json查看配置文件。
可能不生效的原因
-
挂载目录不正确
-
配置文件不正确,日志中会提示
invalid json,配置文件需要是标准的 JSON 文件。 -
修改后,没有
docker-compose down再docker-compose up -d,restart 是不会重新挂载文件的。
3.6 如何检查环境变量是否正常加载
-
docker exec -it fastgpt sh进入 FastGPT 容器。 -
直接输入
env命令查看所有环境变量。
3.7 为什么无法连接本地模型镜像
docker-compose.yml中使用了桥接的模式建立了fastgpt网络,如想通过 0.0.0.0 或镜像名访问其它镜像,需将其它镜像也加入到网络中。
3.8端口冲突怎么解决?
docker-compose 端口定义为:映射端口:运行端口。
桥接模式下,容器运行端口不会有冲突,但是会有映射端口冲突,只需将映射端口修改成不同端口即可。
如果容器1需要连接容器2,使用容器2:运行端口来进行连接即可。
(自行补习 docker 基本知识)
3.9relation “modeldata” does not exist
PG 数据库没有连接上 / 初始化失败,可以查看日志。FastGPT 会在每次连接上 PG 时进行表初始化,如果报错会有对应日志。
-
检查数据库容器是否正常启动
-
非 docker 部署的,需要手动安装 pg vector 插件
-
查看 fastgpt 日志,有没有相关报错
3.10 Illegal instruction
可能原因:
-
arm 架构。需要使用 Mongo 官方镜像: mongo:5.0.18
-
cpu 不支持 AVX,无法用 mongo5,需要换成 mongo4.x。把 mongo 的 image 换成: mongo:4.4.29
3.11 Operation auth_codes.findOne() buffering timed out after 10000ms
mongo 连接失败,查看 mongo 的运行状态对应日志。
可能原因:
-
mongo 服务有没有起来(有些 cpu 不支持 AVX,无法用 mongo5,需要换成 mongo4.x,可以 docker hub 找个最新的 4.x,修改镜像版本,重新运行)
-
连接数据库的环境变量填写错误(账号密码,注意 host 和 port,非容器网络连接,需要用公网 ip 并加上 directConnection=true)
-
副本集启动失败。导致容器一直重启。
-
Illegal instruction.... Waiting for MongoDB to start: cpu 不支持 AVX,无法用 mongo5,需要换成 mongo4.x
3.12 首次部署,root 用户提示未注册
日志会有错误提示。大概率是没有启动 Mongo 副本集模式。
3.13 登录提示 Network Error
由于服务初始化错误,系统重启导致。
-
90% 是由于配置文件写不对,导致 JSON 解析报错
-
剩下的基本是因为向量数据库连不上
3.14 如何修改密码
修改docker-compose.yml文件中DEFAULT_ROOT_PSW并重启即可,密码会自动更新。
4.FastGPT 私有部署常见问题(2)
4.1 错误排查方式
遇到问题先按下面方式排查。
-
docker ps -a查看所有容器运行状态,检查是否全部 running,如有异常,尝试docker logs 容器名查看对应日志。 -
容器都运行正常的,
docker logs 容器名查看报错日志 -
带有
requestId的,都是 OneAPI 提示错误,大部分都是因为模型接口报错。 -
无法解决时,可以找找 github Issue,或新提 Issue,私有部署错误,务必提供详细的日志,否则很难排查。
4.2 通用问题
其他模型没法进行问题分类 / 内容提取
-
看日志。如果提示 JSON invalid,not support tool 之类的,说明该模型不支持工具调用或函数调用,需要设置
toolChoice=false和functionCall=false,就会默认走提示词模式。目前内置提示词仅针对了商业模型 API 进行测试。问题分类基本可用,内容提取不太行。 -
如果已经配置正常,并且没有错误日志,则说明可能提示词不太适合该模型,可以通过修改
customCQPrompt来自定义提示词。
页面崩溃
-
95% 情况是配置文件不对。会提示 xxx undefined
-
提示
URI malformed,请 Issue 反馈具体操作和页面,这是由于特殊字符串编码解析报错。
-
关闭翻译
-
检查配置文件是否正常加载,如果没有正常加载会导致缺失系统信息,在某些操作下会导致空指针。
-
某些 api 不兼容问题(较少)
开启内容补全后,响应速度变慢
-
问题补全需要经过一轮 AI 生成。
-
会进行 3~5 轮的查询,如果数据库性能不足,会有明显影响。
- 对话接口报错或返回为空 (core.chat.Chat API is error or undefined)
-
检查 AI 的 key 问题:通过 curl 请求看是否正常。务必用 stream=true 模式。并且 maxToken 等相关参数尽量一致。
-
如果是国内模型,可能是命中风控了。
-
查看模型请求日志,检查出入参数是否异常。
页面中可以正常回复,API 报错
页面中是用 stream=true 模式,所以 API 也需要设置 stream=true 来进行测试。部分模型接口(国产居多)非 Stream 的兼容有点垃圾。 和上一个问题一样,curl 测试。
知识库索引没有进度 / 索引很慢
先看日志报错信息。有以下几种情况:
-
可以对话,但是索引没有进度:没有配置向量模型(vectorModels)
-
不能对话,也不能索引:API 调用失败。可能是没连上 OneAPI 或 OpenAI
-
有进度,但是非常慢:api key 不行,OpenAI 的免费号,一分钟只有 3 次还是 60 次。一天上限 200 次。
** Connection error**
网络异常。国内服务器无法请求 OpenAI,自行检查与 AI 模型的连接是否正常。
或者是 FastGPT 请求不到 OneAPI(没放同一个网络)
修改了 vectorModels 但是没有生效
-
重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型)
-
记得刷新一次浏览器。
-
如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。
4.3 常见的 OneAPI 错误
带有 requestId 的都是 OneAPI 的报错。
** **
OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。路径:打开 OneAPI -> 用户 -> root 用户右边的编辑 -> 剩余余额调大
xxx 渠道找不到
FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:如果 OneAPI 中,没有配置对应的模型,`config.json`中也不要配置,否则容易报错。
-
OneAPI 中没有配置该模型渠道,或者被禁用了。
-
FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。
-
使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。
Incorrect API key provided: sk-xxxx.You can find your api Key at xxx
OneAPI 的 API Key 配置错误,需要修改`OPENAI_API_KEY`环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。可以`exec`进入容器,`env`查看环境变量是否生效。
- bad_response_status_code bad response status code 503
-
模型服务不可用
-
模型接口参数异常(温度、max token 等可能不适配)
-
….
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。