Linux memcg lru lock提升锁性能
内核关于per memcg lru lock的重要提交:
f9b1038ebccad354256cf84749cbc321b5347497
6168d0da2b479ce25a4647de194045de1bdd1f1d
计算虚拟地址转换基本机制
为了处理多应用程序的地址冲突, linux 系统在应用中使用了虚拟地址,得益于硬件的MMU的广泛使用,虚拟地址到实际内存的物理地址转化变得快速很多。
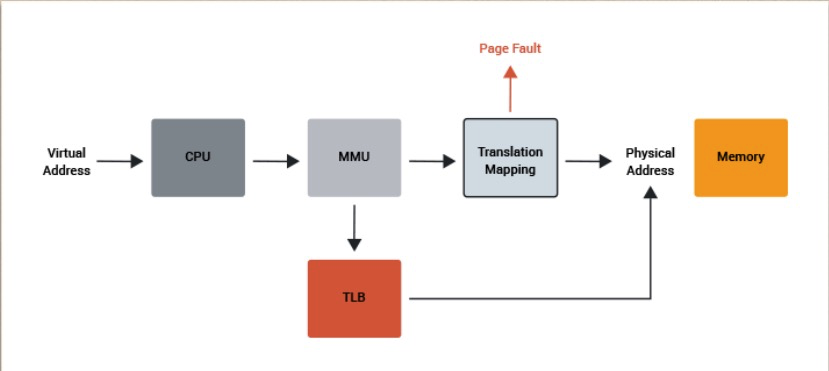
当虚拟地址送到cpu中后, 系统先前检查TLB表中是否有这个地址, 如果有,直接返回物理地址, 如果没有就去检查PageTable, 如果pagetable中也没有这个地址,系统产生一个page fault,来给这个地址实际分配物理内存。
每个应用的page table 保存了虚拟地址到物理地址一一对应表, 示意图如下所示:

Page fault 在linux中采用了称之为lazy fault的处理策略, 就是申请内存时并不实际分配物理内存, 直到实际使用这块内存时才实际分配内存。例如,得益于linux共享内存的设计,如果应用申请的share lib已经被其他程序实际分配到内存。 那么后来的应用只要在pagetable中填上对应的页表项就好。不需要发生实际的IO,这个过程叫做 minor fault. 第一个使用share lib的应用因为需要把share lib的内容读到内存, 需要有IO 的参与, 称之为Major fault.
问题背景
自电子计算机诞生以来,内存性能一直是行业关心的重点。内存也随着摩尔定律,在大小和速度上一直增长。现在的云服务器动辄单机接近 TB 的内存大小,加上数以百记的 CPU 数量也着实考验操作系统的资源管理能力。
作为世间最流行的操作系统 Linux, 内核使用 LRU(Last Recent Used)链表来管理全部用户使用的内存,用一组链表串联起一个个的内存页,并且使用 lru lock 来保护链表的完整性。
所有应用程序常用操作都会涉及到 LRU 链表操作,例如,新分配一个页,需要挂在 inactive lru 链上, 2 次访问同一个文件地址, 会导致这个页从 inactive 链表升级到 active 链表, 如果内存紧张, 页需要从 active 链表降级到inactive 链表, 内存有压力时,页被回收导致被从 inactive lru 链表移除。不单大量的用户内存使用创建,回收关系到这个链表, 内核在内存大页拆分,页移动,memcg 移动,swapin/swapout, 都要把页移进移出 lru 链表。
可以简单计算一下 x86 服务器上的链表大小:x86 最常用的是 4k 内存页, 4GB 内存会分成 1M 个页, 如果按常用服务器 256GB 页来算, 会有超过 6 千万个页挂在内核 lru 链表中。超大超长的内存链表和频繁的 lru 操作造成了 2 个著名的内核内存锁竞争, zone lock 和 lru lock。这 2 个问题也多次造成麻烦,系统很忙,但是业务应用并没得到多少 cpu 时间, 大部分 cpu 都花在 sys 上了。一个简单 2 次读文件的 benchmark 可以显示这个问题, 它可以造成 70% 的 cpu 时间花费在 LRU lock 上。https://git.kernel.org/pub/scm/Linux/kernel/git/wfg/vm-scalability.git/tree/case-lru-file-readtwice
作为一个知名内核性能瓶颈, 社区也多次尝试以各种方法解决这个问题, 例如,使用更多的 LRU list, 或者 LRU contention 探测(https://lwn.net/Articles/753058/)。
但是都因为各种原因被 Linux 内核拒绝。
swap换入流程

cpu接到访问一个虚拟地址的命令, cpu需要把这个虚拟地址转化成物理地址,于是先去访问TLB,如果命中TLB,返回物理地址, 如果没有继续访问页表,如果命中页表, 返回物理地址, 如果没有命中, 产生page fault, 在page fault处理程序中,发现,虚拟地址对应的页表项虽然present bit 为零但是内容非空,所以这个地址在一个被交换到swap设备的页中。继续检查,这个页是否在swapcache中,如果在,返回这个页地址加虚拟地址地址在页中的偏移,如果不在,获得一个内存页, 到swap设备上读取内容填到这个页,此处产生IO, 为Major page fault. 接下了就上把这个页加到swapcache,加入 LRU, 加入page table, 关联到所属的memcg, 并且添加反向映射,然后用户就可以正常使用了。 最后在某些机器上在更新mmu cache.(spark/ppc)
linux kernel 使用LRU来管理内存页。 Last Recent Used. 内核页管理方式如下图所示:
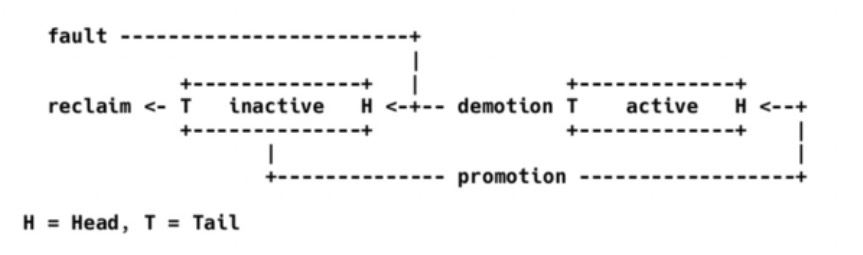
lru 由2个链表组成,一个是inactive list, 另一个是active list, page fault新产生的页加到inactive list的头上, 二次访问到的页从inactive list上提升到active list上, 如果内存有压力回收时,active list的页降级的inactive list, inactive list页从尾巴上回收掉。
lru 页管理涉及到的内核数据有3个,per node 上的 Lru_lock, page.flags上的 PG_lru bit 和per node 5个链表。linux 把所有用户使用的内存页都放在5个链表上, inactive anon, active anon, inactivec file, active file and unevictable list.
Lru_lock保护的对象有6个,

加锁保护的时机如下:

在2008年以前, memcg加入内核之前, 内核使用一个per node lru_lock保护per node的lru lists.

当memcg引入内核后, lru list改成了 per memcg的模式,每个memcg都有一组lru lists.

当每个memcg的页共同还在同一个lru lock上竞争时, 显然不如给每个memcg一个lru lock, 这样lock contention就会大大减小。

使用per memcg 的 lru_lock, 要先解决一个问题: 内存页不会一直在一个memcg上固定不变, 页也许会被移动到其他的memcg上, 也许memcg会销毁。 所以使用per memcg lru lock的关键就是如何在在lru lock 锁定期间 保证memcg固定。
开始很直接想到的是relock方案:

page在memcg之间移动要获得lru_lock, 所以lru_lock relock可以保护page在memcg之间的移动, 但是回顾上面读取swap device的例子, 我们会在关联memcg之前加入lru list, 这个导致页所属的memcg不稳定, 因而会拿错Lru_Lock 。解决的根本是改变页加入lru list和memcg的次序:如下所示,先关联memcg, 然后在加入lru list.

关键步骤更新后,页管理中的锁的使用次序页可以改变了:
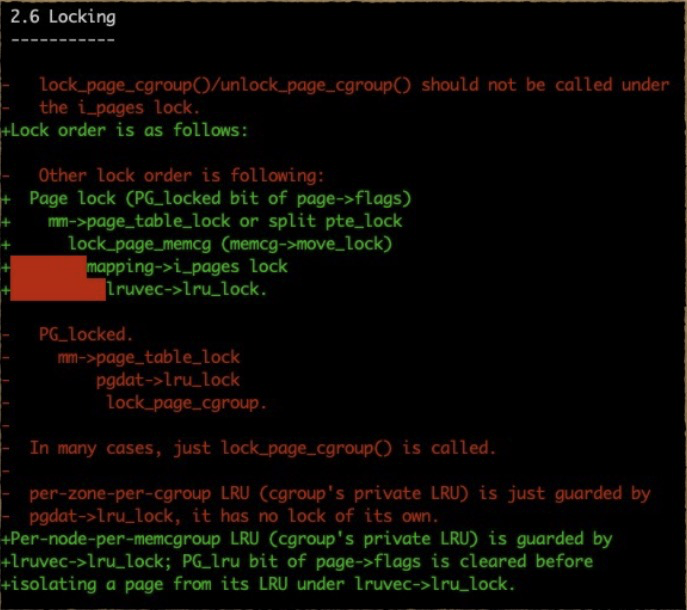
relock方案是可以用了。 但是relock 增加了lock 排队的机会 会导致性能下降。
更好的办法是不用lru_lock 保护memcg change, 比如拿出PG_lru bit做互斥: 原本的page isoaltion次序是:

get_page; get lru_lock; clear page lru; delete page from lru list. 新的方法是,
get_page; TestClearPageLRU; get lru_lock; delete page from lru list. page isolation互斥从lru lock上移到PG_bit, 通过线性获得PG_lru bit来保证。lru lock只用来保证list的完整性。加上一些code clean up. 新的lru lock保护对象只保留了 lists.

另外lru_lock使用时机还是不变。