【详细原理】蒙特卡洛树搜索
单一状态蒙特卡洛规划:多臂赌博机
多臂赌博机问题(Multi-Armed Bandit)是强化学习中的经典问题,涉及在有限的时间内,从多台赌博机(即“臂”)中选择,以最大化累积奖励。单一状态蒙特卡洛规划是一种解决该问题的有效方法。
问题描述
假设有 K K K 个臂的赌博机,每个臂 k k k 的奖励分布未知。目标是在 T T T 次尝试中,选择臂 a t a_t at,使得累积奖励 R = ∑ t = 1 T r a t R = \sum_{t=1}^{T} r_{a_t} R=∑t=1Trat 最大,其中 r a t r_{a_t} rat 是在时间步 t t t 选择臂 a t a_t at 获得的奖励。
探索与利用的权衡
在多臂赌博机问题中,需要在探索(尝试不同的臂以了解其潜在奖励)和利用(选择当前估计最优的臂以获取高奖励)之间取得平衡。
如果有 k k k 个赌博机,这 k k k 个赌博机产生的操作序列为 X i , 1 , X i , 2 , … X_{i,1}, X_{i,2}, \dots Xi,1,Xi,2,… ( i = 1 , 2 , … , k i = 1,2, \dots, k i=1,2,…,k)。在时刻 t = 1 , 2 , … t = 1, 2, \dots t=1,2,…,选择第 I t I_t It 个赌博机后, 可得到奖赏 X I t , t X_{I_t,t} XIt,t,则在 n n n 次操作后定义悔值函数:
R n = max i = 1 , … , k ∑ t = 1 n X i , t − ∑ t = 1 n X I t , t R_n = \max_{i=1,\dots,k} \sum_{t=1}^{n} X_{i,t} - \sum_{t=1}^{n} X_{I_t,t} Rn=i=1,…,kmaxt=1∑nXi,t−t=1∑nXIt,t
悔值函数表示了如下意思:在第 t t t 次对赌博机操作时,假设知道哪个赌博机能够给出最大奖赏(虽然在现实生活中这是不存在的),则将得到的最大奖赏减去实际操作第 I t I_t It 个赌博机所得的奖赏。将 n n n 次操作的差值累加起来,就是悔值函数的结果。
很显然,一个良好的多臂赌博机操作的策略是在不同人进行了多次玩法后,能够让悔值函数的方差最小。
上限置信区间
在多臂赌博机的研究过程中,上限置信区间(Upper Confidence Bound, UCB)成为一种较为成功的策略学习方法,因为其在探索-利用(exploration-exploitation)之间取得平衡。
在 UCB 方法中,使 X i , T i ( t − 1 ) X_{i,T_i(t-1)} Xi,Ti(t−1) 来记录第 i i i 个赌博机在过去 t − 1 t-1 t−1 时刻内的平均奖赏,则在第 t t t 时刻,选择使如下具有最佳上限置信区间的赌博机:
I t = arg max i ∈ { 1 , … , k } { X i , T i ( t − 1 ) + c t − 1 , T i ( t − 1 ) } I_t = \arg\max_{i \in \{1, \dots, k\}} \left\{ X_{i,T_i(t-1)} + c_{t-1,T_i(t-1)} \right\} It=argi∈{1,…,k}max{Xi,Ti(t−1)+ct−1,Ti(t−1)}
其中, c t , s c_{t,s} ct,s 取值定义如下:
c t , s = 2 ln t s c_{t,s} = \sqrt{\frac{2 \ln t}{s}} ct,s=s2lnt
T i ( t ) = ∑ s = 1 t 1 ( I s = i ) T_i(t) = \sum_{s=1}^{t} \mathbf{1}(I_s = i) Ti(t)=∑s=1t1(Is=i) 为在过去时刻(初始时刻到第 t t t 时刻)过程中选择第 i i i 个赌博机的次数总和。
当选择第 i i i个赌博机的次数越少, s s s越小, c t , s c_{t,s} ct,s越大,即第 i i i个赌博机获得的奖励越不确定, c t − 1 , T i ( t − 1 ) c_{t-1,T_i(t-1)} ct−1,Ti(t−1)的意义在于摇动那些选择次数较少的赌博机以博取更大的奖励。
也就是说,在第 t t t 时刻,UCB 算法一般会选择具有如下最大值的第 j j j 个赌博机:
U C B = X ‾ j + 2 ln n n j 或者 U C B = X ‾ j + C × 2 ln n n j UCB = \overline{X}_j + \sqrt{\frac{2 \ln n}{n_j}} \quad \text{或者} \quad UCB = \overline{X}_j + C \times \sqrt{\frac{2 \ln n}{n_j}} UCB=Xj+nj2lnn或者UCB=Xj+C×nj2lnn
其中, X ‾ j \overline{X}_j Xj 是第 j j j 个赌博机在过去时间内所获得的平均奖赏值, n j n_j nj 是在过去时间内拉动第 j j j 个赌博机臂膀的总次数, n n n 是过去时间内拉动所有赌博机臂膀的总次数。 C C C 是一个平衡因子,其决定着在选择时偏重探索还是利用。
从这里可看出,UCB算法如何在探索-利用(exploration-exploitation)之间寻找平衡:既需要拉动在过去时间内获得最大平均奖赏的赌博机,又希望去选择拉动臂膀次数最少的赌博机。
蒙特卡洛树搜索
蒙特卡罗树搜索(Monte Carlo Tree Search,简称 MCTS)是一种用于决策过程的启发式搜索算法,特别适用于具有巨大搜索空间的游戏和问题,例如围棋、国际象棋和复杂的组合优化问题。MCTS 通过在决策树中进行随机模拟(也称为蒙特卡罗模拟),逐步构建搜索树,从而找到最优的决策路径。
核心概念
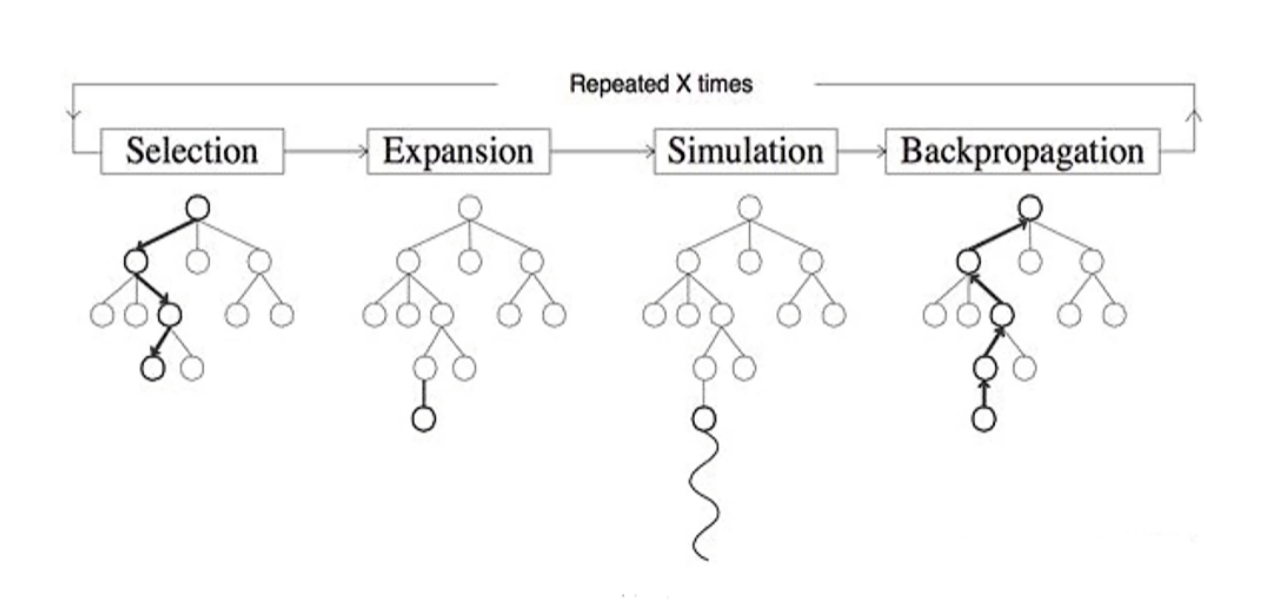
MCTS 的核心思想是通过在决策树上进行大量的随机模拟,来估计各个节点的价值,从而指导搜索过程。它主要由以下四个步骤组成,每次迭代都会重复这四个步骤:
-
选择(Selection):从根节点开始,根据某种策略(如上置信区间 UCB),选择一个子节点,直到到达一个尚未被完全展开的节点。
-
扩展(Expansion):如果选中的节点不是终止节点,从该节点中随机选择一个未被访问过的子节点,添加到搜索树中。
-
模拟(Simulation):从新添加的节点开始,进行一次随机的模拟(也称为“Playout”),直到到达终止状态(如游戏结束)。
-
回溯更新(Backpropagation):将模拟结果(如胜利或失败)沿着路径反向传播,更新各个节点的统计信息(如胜率、访问次数)。
关键组件
-
选择策略:在选择步骤中,常用的策略是上置信区间应用于树(Upper Confidence Bounds applied to Trees,UCT)。UCT 平衡了探索(选择访问次数少的节点)和利用(选择具有高胜率的节点)。
UCT = w i n i + c × ln N n i \text{UCT} = \frac{w_i}{n_i} + c \times \sqrt{\frac{\ln N}{n_i}} UCT=niwi+c×nilnN
其中, w i w_i wi 是节点 i i i 的获胜次数, n i n_i ni 是节点 i i i 的访问次数, N N N 是父节点的访问次数, c c c 是探索参数。
-
模拟策略:通常是随机的,也可以使用启发式或领域特定的知识来改进模拟的质量。
-
回溯更新:在回溯过程中,更新节点的胜率和访问次数,以反映最新的模拟结果。
总结
蒙特卡罗树搜索是一种强大的搜索算法,能够在复杂的决策空间中进行有效的搜索。通过大量的随机模拟和巧妙的选择策略,MCTS 在许多领域都展现出了卓越的性能。然而,其计算成本和对模拟策略的依赖性也是需要考虑的因素。随着计算能力的提升和算法的改进,MCTS 的应用前景将更加广阔。