一次RPC调用过程是怎么样的?
注册中心
RPC(Remote Procedure Call)翻译成中文就是 {远程过程调用}。RPC 框架起到的作用就是为了实现,调用远程方法时,能够做到和调用本地方法一样,让开发人员更专注于业务开发,不用去考虑网络编程等细节。
RPC 框架怎么就实现不让开发人员关注网络编程等细节呢?
首先我们区分两个角色一个服务提供方,一个是服务调用方。服务调用方其实是通过动态代理、负载均衡、网络调用等机制去服务提供方的机器上去执行对应的方法。服务提供方将方法执行完成后,将执行结果再通过网络传输返回到服务提供方。 大致过程如下:
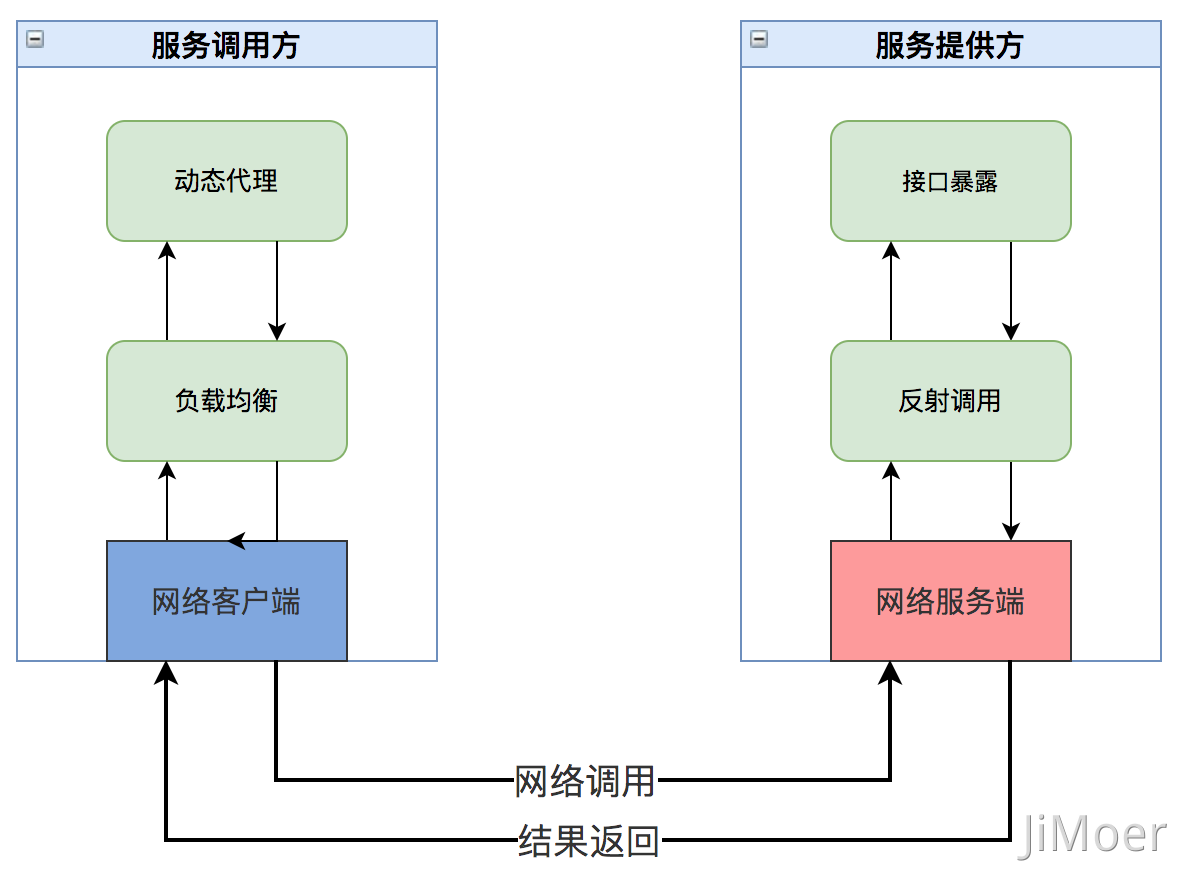
但是现在的服务都是集群部署,那么服务调用方怎么能够实时的知道服务提供方的集群中的变化,例如服务提供方的 IP 地址变了,或者是服务重启时怎么能够及时的切换流量呢?
这就需要{注册中心} 起作用了,我们可以把注册中心看作服务端,然后每个服务都看成客户端,每个客户端都需要将自己注册到注册中心,然后一个服务调用方要调用另一个服务时,需要从注册中心获取服务提供方的信息,主要是获取服务提供方的服务器 IP 地址列表和端口信息。
服务调用方获取到这些信息后缓存到自己本地,并且跟注册中心保持一个长连接当服务提供方有任何变化时,注册中心能够实时的通知给服务调用方,调用方能够及时更新自己本地缓存的信息(也可以采用定时轮询的方式)。
服务调用方获取到服务器 IP 地址信息后,根据自己的负载均衡策略选择一个 IP 地址然后发起网络调用的请求。
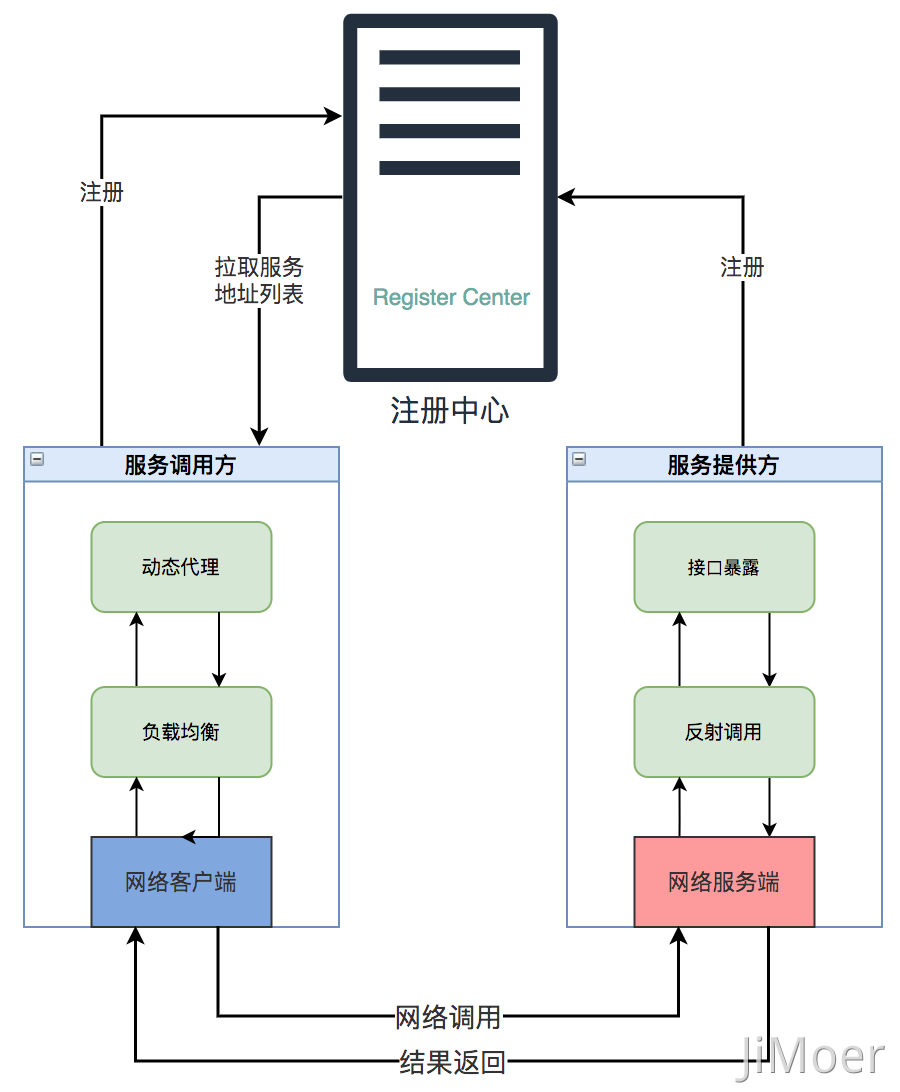
那么网络客户端是通过什么发起的网络调用呢?
可以自己使用 JDK 原生的 BIO 或者 NIO 来实现一套网络通信模块,但是这里我们建议直接使用强大的网络通信框架 Netty。它是基于 NIO 的网络通信框架,支持高并发,封装完善,而且性能好传输快。
Netty 不是我们本文的主要内容,这里就不展开说了。
客户端调用过程
因为我们知道数据在网络中传输的时候都是以二进制的形式的,所以在调用方将调用的参数进行传递的时候是需要进行序列化的。服务提供方在接收到参数时也是需要进行反序列化的。
网络协议
调用方既然需要序列化,服务提供方又要进行反序列化,这样双方就要确定好一个协议,调用方传输什么参数,服务提供方就按照这个协议去进行解析,而且在返回结果的时候也是按照这个协议进行结果解析。
那么这个协议应该是怎么样的结构,都是什么样子的呢? 因为这个协议可以自定义,我们为了方便就以 JSON 的形式给举个例子:
{"interfaces": "interface=com.jimoer.rpc.test.producer.TestService;method=printTest;parameter=com.jiomer.rpc.test.producer.TestArgs","requestId": "3","parameter": {"com.jiomer.rpc.test.producer.TestArgs": {"age": 20,"name": "Jimoer"}}
}首先第一个参数interfaces是,我们要让服务提供方知道调用方要调用哪个接口,以及接口中的哪个方法,并且方法的参数是什么类型的。
第二个参数是当前一次请求的一个唯一标识,在多个线程同时请求一个方法时,用这个 id 来进行区分,以后无论是做链路追踪还是日志管理都可以以此 id 为依据。
第三个参数就是 实际的调用方法中的参数值。具体是什么类型的,每个属性值都是什么。
调用
下面也是举一个简单的例子来说明一下调用的过程。我们一部分采用代码的形式一部分采用文字的形式来将整个调用过程串起来。
// 定义请求的URL
String tcpURL = "tcp://testProducer/TestServiceImpl";
// 定义接口请求
TestService testService = ProxyFactory.create(TestService.class, tcpURL);
// 组装请求参数
TestArgs testArgs = new TestArgs(20,"Jimoer");
// 通过动态代理执行请求
String result = testService.printTest(testArgs);通过查看上面的代码我们可以看到整个调用过程最核心的地方在 ProxyFactory.create() 方法里,这个方法里面主要的过程是,动态代理生成接口的实际代理对象,然后使用 Netty 的接口发起网络请求。
Proxy.newProxyInstance(getClass().getClassLoader(), interfaces.getClass().getInterfaces(), new InvocationHandler() {@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 第一步:获取调用服务的地址列表ListregistryInfos = interfacesMethodRegistryList.get(clazz);if (registryInfos == null) {throw new RuntimeException("无法找到服务提供者");}// 第二步: 通过自身的负载均衡策略选择一个地址RegistryInfo registryInfo = loadBalancer.choose(registryInfos);// 第三步:Netty的网络请求处理ChannelHandlerContext ctx = channels.get(registryInfo);// 第四步:根据接口类的全路径名和方法生成唯一标识String identify = InvokeUtils.buildInterfaceMethodIdentify(clazz, method);String requestId;// 第五步:通过加锁的方式保证生成的requestId的唯一性synchronized (ApplicationContext.this) {requestIdWorker.increment();requestId = String.valueOf(requestIdWorker.longValue());}// 第六步: 组织参数JSONObject jsonObject = new JSONObject();jsonObject.put("interfaces", identify);jsonObject.put("parameter", param);jsonObject.put("requestId", requestId);System.out.println("发送给服务端JSON为:" + jsonObject.toJSONString());// $$ 多条消息之间的分隔符String msg = jsonObject.toJSONString() + "$$";ByteBuf byteBuf = Unpooled.buffer(msg.getBytes().length);byteBuf.writeBytes(msg.getBytes());// 第七步:这里发起调用ctx.writeAndFlush(byteBuf);// 这里会将线程进行阻塞,知道服务提供方将请求处理好之后返回结果,再唤醒。waitForResult();return result;}});执行过程大致分为这几步:
- 获取调用服务的地址列表。
- 通过自身的负载均衡策略选择一个地址。
- Netty 的网络请求处理(选择一个渠道 Channel)。
- 根据接口类的全路径名和方法生成唯一标识。
- 通过加锁的方式保证生成的 requestId 的唯一性。
- 组织请求参数。
- 发起调用。
- 线程阻塞,直到服务提供方返回结果。
- 填充返回结果,返回到调用方。
服务端处理过程
上面也说了,服务调用方发起网络请求后,会阻塞住,直到服务提供方返回数据,所以服务提供方处理完调用方法的逻辑后,还是要唤醒阻塞的调用线程的。
服务提供方在处理请求时也是先通过 Netty 获取到数据,然后再进行反序列化,然后再根据协议获取到需要调用的方法,然后通过反射去进行调用。
Netty 的返回入口在下面这部分逻辑里
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {try {String message = (String) msg;if (messageCallback != null) {// 将接收到的消息放到回调方法中messageCallback.onMessage(message);}} finally {ReferenceCountUtil.release(msg);}
}Netty 的 client 接收到响应的消息后,先将结果返回到调用方,处理完成之后再去释放之前的阻塞调用线程。
client.setMessageCallback(message -> {// 这里收单服务端返回的消息,先压入队列RpcResponse response = JSONObject.parseObject(message, RpcResponse.class);System.out.println("收到一个响应:" + response);String interfaceMethodIdentify = response.getInterfaceMethodIdentify();String requestId = response.getRequestId();// 设定唯一标识String key = interfaceMethodIdentify + "#" + requestId;Invoker invoker = inProgressInvoker.remove(key);// 将结果设置到代理对象中invoker.setResult(response.getResult());// 加锁再释放之前的阻塞线程。synchronized (ApplicationContext.this) {ApplicationContext.this.notifyAll();}
});setResult() 方法
@Override
public void setResult(String result) {synchronized (this) {this.result = JSONObject.parseObject(result, returnType);notifyAll();}
}上面的步骤就是这样,按照之前请求的唯一标识放入到返回的信息中,然后将结果设置到代理对象中,再通过返回结果,然后唤醒之前的调用阻塞线程。
总结
其实整个 RPC 的请求过程就是如下(不含异步调用):
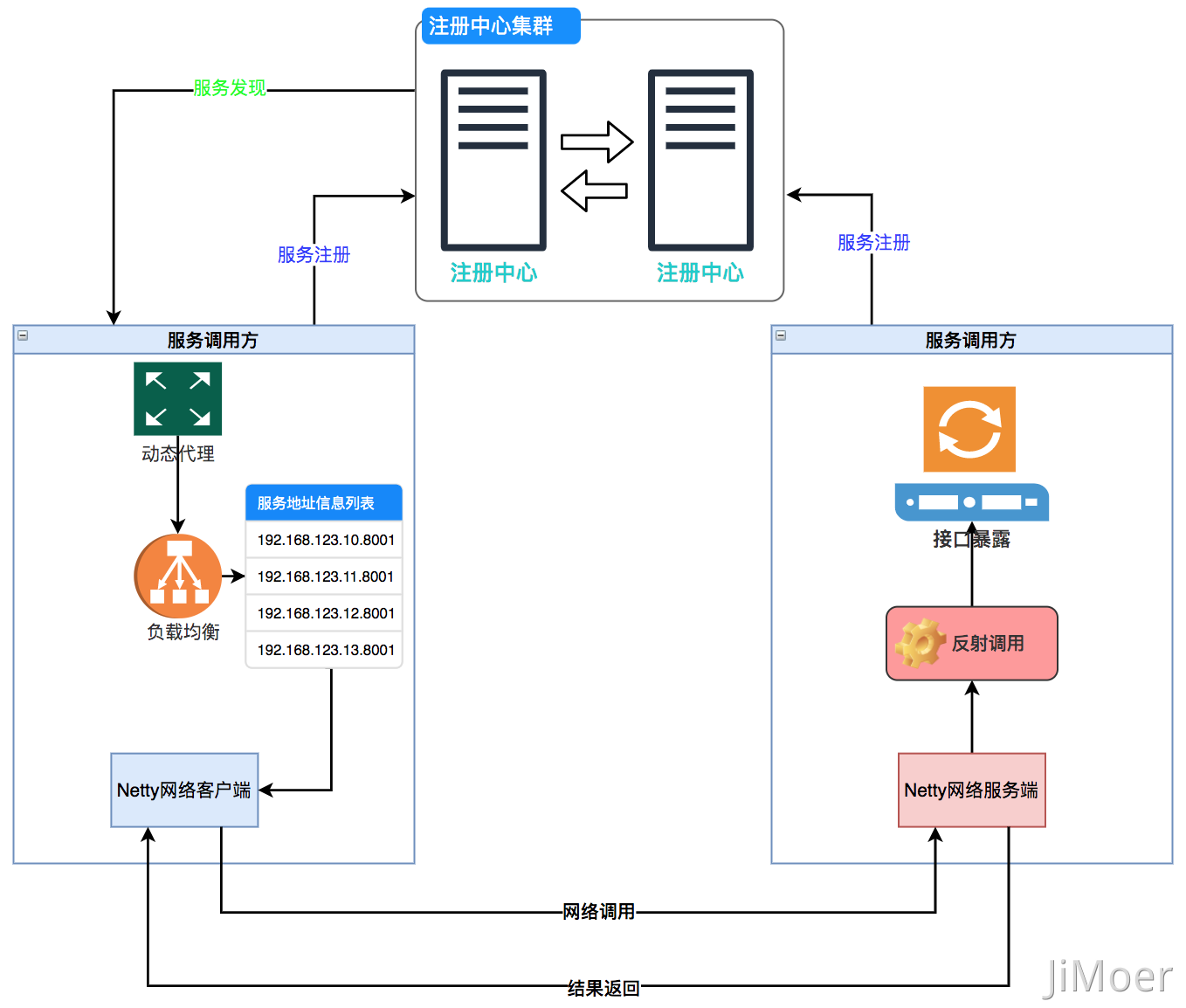
做一个总结,用大白话把一个 RPC 请求流程描述出来: 首先无论是调用方还是服务提供方都要注册到注册中心;
- 服务调用方把请求参数对象序列化成二进制数据,通过动态代理生成代理对象,通过代理对象,使用 Netty 选择一个从注册中心拉取到的服务提供方的地址,然后发起网络请求。
- 服务提供方从 TCP 通道中接收到二进制数据,根据定义的 RPC 网络协议,从二进制数据中反序列化后,分割出接口地址和参数对象,再通过反射找到接口执行调用。
- 然后服务提供方再把调用执行结果序列化后,回传到 TCP 通道中。
- 服务调用方获取到应答二进制数据后,再反序列化成结果对象。
这样就完成了一次 RPC 网络调用,其实后面框架扩展后,还要考虑限流、熔断、服务降级、序列化多样性扩展,服务监控、链路追踪等等功能。