【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读
文章目录
- 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读
- 前言
- autopad函数
- Conv类
- __init__成员函数
- forward成员函数
- forward_fuse成员函数
- Bottleneck类
- __init__成员函数
- forward成员函数
- Concat类
- __init__成员函数
- forward成员函数
- DetectMultiBackend类
- __init__成员函数
- forward成员函数
- 总结
前言
在详细解析YOLOV3网络之前,首要任务是搭建Ultralytics–YOLOV3【Windows11下YOLOV3人脸检测】所需的运行环境,并完成模型的训练和测试,展开后续工作才有意义。
本博文对models/common.py代码进行解析,common.py文件存放着YOLOV3网络搭建常见的通用模块。其他代码后续的博文将会陆续讲解。这里只做YOLOV3相关模块的代码解析,其他的通用模块是YOLO后续系列中创新和提出的。
autopad函数
用于自动计算卷积层的填充值(padding),以确保当步幅为1时卷积操作后的输出特征图尺寸保持不变。
def autopad(k, p=None): # kernel, padding"""用于自动计算卷积层的填充值:param k:卷积核大小:param p:填充值:return:计算得到的填充值"""if p is None: # 检查是否需要自动计算填充值,否则用户指定填充值# 正方形卷积核:isinstance(k, int)表示k是一个整数,卷积核是正方形,填充值p被为k//2,即卷积核大小的一半向下取整# 非正方形卷积核: 是一个列表或元组,则对每个维度分别计算填充值,同理计算填充值pp = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn p
理论基础: 在二维卷积中,输出特征图的尺寸可以通过以下公式计算:
O u t p u t S i z e = I n p u t S i z e + 2 p − k s + 1 OutputSize = \frac{{InputSize + 2p - k}}{{\rm{s}}} + 1 OutputSize=sInputSize+2p−k+1
其中: I n p u t S i z e InputSize InputSize是输入特征图的尺寸; p p p是填充大小; k k k是卷积核大小; s s s是步长。
根据上述方程,当 s = 1 s=1 s=1且输出尺寸等于输入尺寸时,解出 p p p的值:
p = ⌈ k − 1 2 ⌉ = ⌊ k 2 ⌋ p = \left\lceil {\frac{{k - 1}}{2}} \right\rceil = \left\lfloor {\frac{k}{2}} \right\rfloor p=⌈2k−1⌉=⌊2k⌋
由于填充大小 p p p必须是整数,因此使用向下取整除法(//),即 p = k / / 2 p=k//2 p=k//2 来自动计算填充值,确保了无论卷积核大小 k k k是奇数还是偶数,都可以正确计算出合适的填充大小,使得在步长为1的情况下,输出尺寸尽可能接近输入尺寸。对于非对称的卷积核,分别对每个维度应用此规则以保证各自的输出尺寸匹配相应的输入尺寸。
Conv类
__init__成员函数
构造函数,初始化自定义的卷积模块,通常包含卷积层、批量归一化层和激活函数。调用了【models/common.py】的autopad函数。
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups"""构造函数,初始化自定义的卷积模块:param c1:输入通道数:param c2:输出通道数:param k:卷积核大小,默认为 1:param s:步幅,默认为 1:param p:填充,默认为None(不指定为None会自动计算填充值):param g:分组卷积的分组数,默认为 1(标准卷积):param act:是否使用激活函数,默认为True(使用nn.SiLU()),False则使用nn.Identity()(相当于没使用任何函数),提供了指定激活函数对象则使用指定的激活函数"""super().__init__()# 创建一个二维卷积层self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)# 创建一个批量归一化层self.bn = nn.BatchNorm2d(c2)# 设置激活函数self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
本博文讲解的代码原论文的源码,是YOLOV5团队复现改进后的YOLOV3代码,因此自定义的卷积模块的结构与原论文的结构在激活函数的选择上有所不同。
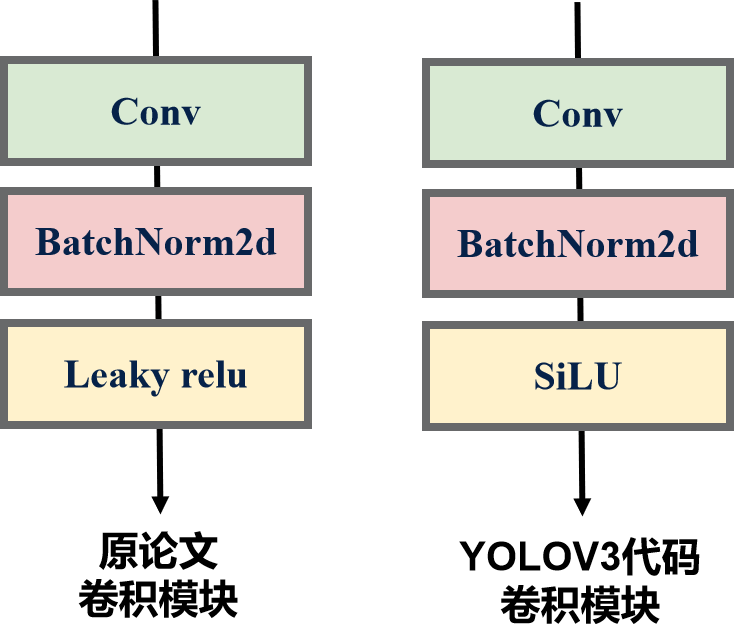
在YOLOV5中,SiLU替换了早期版本中的Leaky ReLU,显著提升了模型的性能。在EfficientNet系列中,SiLU成为了默认激活函数。
forward成员函数
前向传播,执行自定义的卷积模块。
def forward(self, x):"""前向传播,执行模块:param x:输入数据张量:return:卷积块的输出"""return self.act(self.bn(self.conv(x)))
forward_fuse成员函数
融合前向传播,跳过了批量归一化层,推理阶段使用可以提高计算效率。
def forward_fuse(self, x):"""融合前向传播,跳过了批量归一化层,推理阶段使用可以提高计算效率:param x:输入数据张量:return:卷积块的输出"""return self.act(self.conv(x))
Bottleneck类
__init__成员函数
自定义的瓶颈模块,通常用于构建类似残差网络的残差块。
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion"""构造函数,构建类似残差网络的残差块:param c1:输入通道数:param c2:输出通道数:param shortcut:是否使用残差连接,默认为 True:param g: 分组卷积的分组数,默认为1(标准卷积):param e:扩展比例,用于计算中间隐藏层的通道数默认为 0.5"""super().__init__()c_ = int(c2 * e) # 计算中间隐藏层的通道数self.cv1 = Conv(c1, c_, 1, 1) # 第一层1×1卷积层self.cv2 = Conv(c_, c2, 3, 1, g=g) # 第二层3×3卷积层self.add = shortcut and c1 == c2 # 判断是否添加残差连接:使用残差连接且输入通道数等于输出通道数
原论文中YOLOV3的瓶颈模块都是带有残差连接的,同时YOLOV3的结构中有很多1×1卷积+3×3卷积这种顺次排列的情况,与残差连接的瓶颈模块相似(但不是瓶颈模块)。因此,Ultralytics-YOLOV3代码为了yaml配置文件的简洁明了,将二则结合起来成了新的瓶颈模块,即可以选择是否激活残差连接。
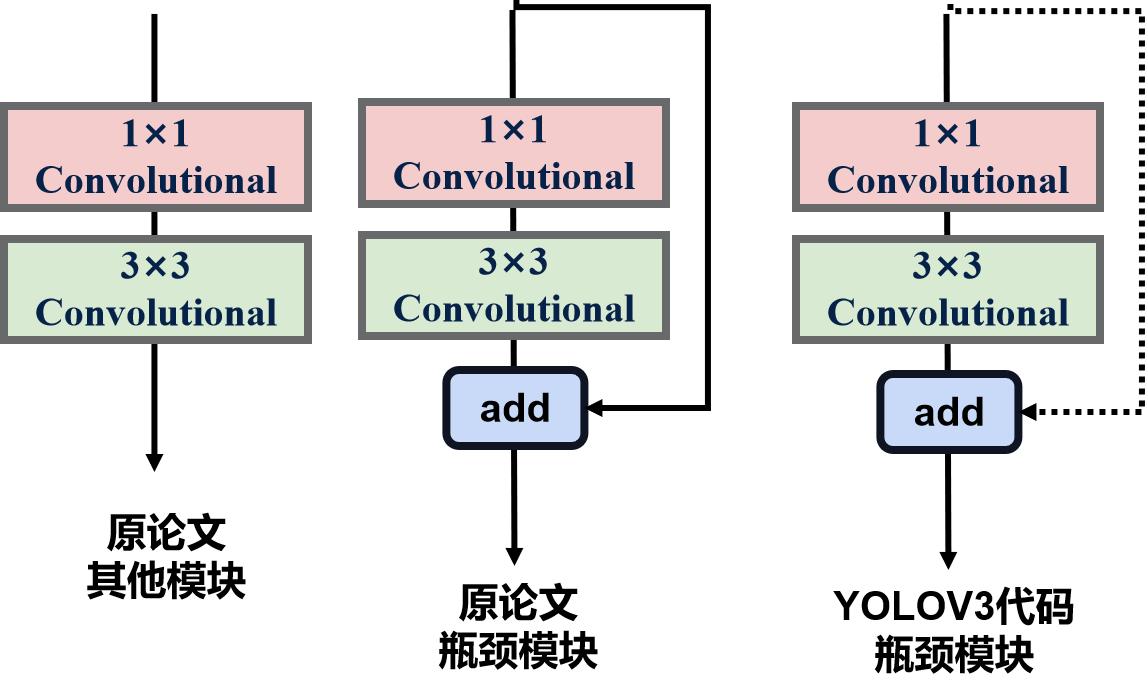
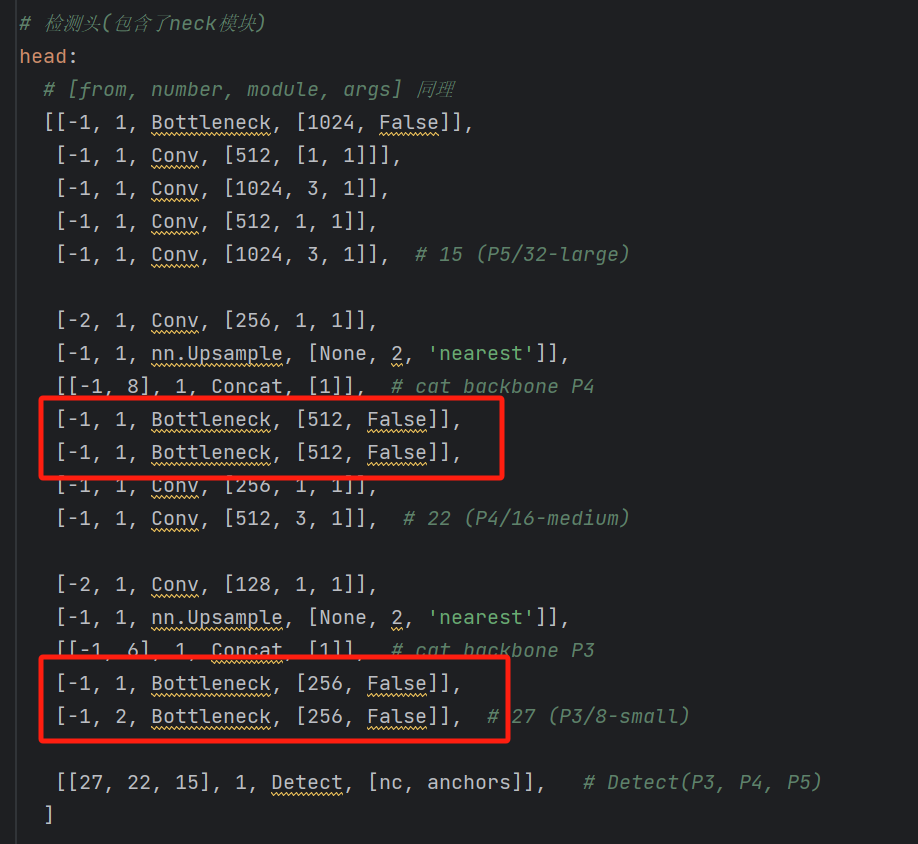
如下图标记的配置文件部分,假设不结合在一起,每个Bottleneck就要单独写俩个Conv,分别是1×1 Conv和3×3 Conv。
forward成员函数
前向传播,执行自定义的瓶颈模块。
def forward(self, x):"""前向传播,执行模块:param x:输入数据张量:return:瓶颈模块的输出"""# 如果进行残差连接,则将输入x和瓶颈模块的输出结果相加return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
Concat类
__init__成员函数
用于在深度学习模型中实现张量的拼接操作。
def __init__(self, dimension=1):"""构造函数,用于实现张量在指定维度上的拼接操作:param dimension: 指定拼接的维度,默认为 1"""super().__init__()self.d = dimension
forward成员函数
前向传播,执行拼接。
def forward(self, x):"""前向传播,执行拼接:param x:输入数据张量列表:return:拼接后的张量"""# 将输入张量列表沿着指定维度拼接成新的单一张量return torch.cat(x, self.d)
DetectMultiBackend类
__init__成员函数
构造函数,通用的模型加载器支持多种深度学习框架。调用了【models/experimental.py】的attempt_load函数。
def __init__(self, weights='yolov3.pt', device=None, dnn=True):"""构造函数,通用的模型加载器支持多种深度学习框架:param weights:模型权重文件路径,默认为'yolov3.pt':param device:指定设备(GPU或CPU),默认为 None:param dnn:是否使用OpenCV DNN模块加载ONNX模型,默认为 True"""super().__init__()w = str(weights[0] if isinstance(weights, list) else weights) # 要是权重路径列表则选择第一个权重路径,否则直接使用给的权重路径# 提取权重文件的后缀名,并检查其是否属于支持的后缀列表suffix, suffixes = Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '', '.mlmodel']# weights不同深度学习框架的用法:# PyTorch: *.pt# TorchScript: *.torchscript.pt# CoreML: *.mlmodel# TensorFlow: *_saved_model# TensorFlow: *.pb# TensorFlow Lite: *.tflite# ONNX Runtime: *.onnx# OpenCV DNN: *.onnx with dnn=Truecheck_suffix(w, suffixes)pt, onnx, tflite, pb, saved_model, coreml = (suffix == x for x in suffixes) # 根据后缀名判断模型的后端类型jit = pt and 'torchscript' in w.lower() # 为PyTorch模型且包含torchscript关键字则标记为TorchScript模型stride, names = 64, [f'class{i}' for i in range(1000)] # 生成一个包含1000个类名的列表# 根据不同的后端类型加载相应的模型:if jit: # TorchScript模型# 打印加载 TorchScript 模型的日志信息LOGGER.info(f'Loading {w} for TorchScript inference...')extra_files = {'config.txt': ''} # 参数用于提取模型的额外元数据# 使用torch.jit.load加载模型,并提取元数据model = torch.jit.load(w, _extra_files=extra_files)if extra_files['config.txt']: # 存在config.txt文件,解析元数据d = json.loads(extra_files['config.txt']) # 使用json.loads解析内容stride, names = int(d['stride']), d['names'] # 提取步长stride和类别名称nameselif pt: # PyTorch模型from models.experimental import attempt_load # 从models.experimental模块中导入attempt_load函数,避免循环依赖问题# 如果文件名包含torchscript使用torch.jit.load加载模型,否则使用attempt_load函数加载权重文件model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)stride = int(model.stride.max()) # 计算模型的最大步长names = model.module.names if hasattr(model, 'module') else model.names # 获取类别名称elif coreml: # CoreML模型(苹果设备上的优化推理框架,适合部署到iOS和macOS平台)import coremltools as ctmodel = ct.models.MLModel(w) # 加载 CoreML 格式的模型elif dnn: # ONNX模型(OpenCV DNN)# 打印加载ONNX模型的日志信息LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')# 确保安装了OpenCV的版本不低于4.5.4check_requirements(('opencv-python>=4.5.4',))# 使用OpenCV的DNN模块加载ONNX模型net = cv2.dnn.readNetFromONNX(w)elif onnx: #ONNX模型(ONNX Runtime)# 打印加载ONNX模型的日志信息LOGGER.info(f'Loading {w} for ONNX Runtime inference...')# 确保安装了onnx和onnxruntime库,如果设备支持 CUDA则安装onnxruntime-gpu版本check_requirements(('onnx', 'onnxruntime-gpu' if torch.has_cuda else 'onnxruntime'))import onnxruntime# 使用onnxruntime.InferenceSession创建推理会话session = onnxruntime.InferenceSession(w, None)else: # TensorFlow模型import tensorflow as tfif pb: # TensorFlow冻结图模型# 定义wrap_frozen_graph函数def wrap_frozen_graph(gd, inputs, outputs):# # 使用tf.compat.v1.wrap_function包装冻结图x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), [])# prune方法用于修剪图,提取指定的输入和输出节点return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),tf.nest.map_structure(x.graph.as_graph_element, outputs))# 打印加载.pb文件的日志信息LOGGER.info(f'Loading {w} for TensorFlow *.pb inference...')# 创建一个空的GraphDef对象graph_def = tf.Graph().as_graph_def()# 使用ParseFromString方法从文件中读取冻结图的定义graph_def.ParseFromString(open(w, 'rb').read())# 调用wrap_frozen_graph函数:传入冻结图定义,输入节点x:0和输出节点Identity:0,返回修剪后的对象用于后续推理frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")elif saved_model: # TensorFlow SavedModel格式# 打印加载 SavedModel 的日志信息LOGGER.info(f'Loading {w} for TensorFlow saved_model inference...')# 返回一个Keras模型对象直接用于推理model = tf.keras.models.load_model(w)elif tflite: # TensorFlow Lite模型if 'edgetpu' in w.lower(): # Edge TPU模型# 打印加载Edge TPU模型的日志信息LOGGER.info(f'Loading {w} for TensorFlow Edge TPU inference...')# 使用 tflite_runtime.interpreter库加载TFLite模型import tflite_runtime.interpreter as tfli# 根据操作系统类型选择对应 Edge TPU运行库路径delegate = {'Linux': 'libedgetpu.so.1', # install https://coral.ai/software/#edgetpu-runtime'Darwin': 'libedgetpu.1.dylib','Windows': 'edgetpu.dll'}[platform.system()]# tfli.load_delegate加载代理,tfli.Interpreter加载模型并传入代理interpreter = tfli.Interpreter(model_path=w, experimental_delegates=[tfli.load_delegate(delegate)])else: # 普通TensorFlow Lite模型# 打印加载 TFLite 模型的日志信息LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')# 使用tf.lite.Interpreter加载模型interpreter = tf.lite.Interpreter(model_path=w)# 调用allocate_tensors方法分配张量内存interpreter.allocate_tensors()# get_input_details和get_output_details获取输入和输出的详细信息(形状、数据类型等)input_details = interpreter.get_input_details()output_details = interpreter.get_output_details()self.__dict__.update(locals()) # 更新类属性,将所有局部变量赋值给类实例的属性
forward成员函数
前向传播,实现了对不同后端模型的推理逻辑。调用了【utils/general.py】的xywh2xyxy函数。
def forward(self, im, augment=False, visualize=False, val=False):"""实现了对不同后端模型的推理逻辑:param im:输入图像张量:param augment:是否启用数据增强(仅适用于部分模型):param visualize:是否可视化中间特征图(仅适用于部分模型):param val:是否处于验证模式(影响返回值的格式):return: 推理结果(通常为检测框,置信度和类别信息)"""# 输入数据的基本信息b, ch, h, w = im.shape # 批次大小,通道数,图像高度,图像宽度if self.pt: # PyTorch模型推理# 使用self.model 进行推理# 如果是TorchScript模型直接调用模型,否则传递augment 和 visualize参数y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)# 如果处于验证模式返回完整的输出;否则仅返回第一个输出,通常是检测结果return y if val else y[0]elif self.coreml: # CoreML模型推理im = im.permute(0, 2, 3, 1).cpu().numpy() # 输入张量从PyTorch的BCHW格式转换为NumPy的BHWC格式im = Image.fromarray((im[0] * 255).astype('uint8')) # NumPy数组转换为PIL图像并缩放到[0, 255]范围# im = im.resize((192, 320), Image.ANTIALIAS)y = self.model.predict({'image': im}) # 使用self.model.predict进行推理获取检测框坐标和置信度# 检测框坐标由(xywh)转换为(x1y1x2y2)并反归一化box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]])# 提取置信度最大值及其对应的类别索引conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)# 将检测框,置信度和类别信息拼接成一个NumPy数组y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)elif self.onnx: # ONNX模型推理im = im.cpu().numpy() # 将输入张量从PyTorch转换为NumPy数组if self.dnn: # OpenCV DNN加载ONNX模型self.net.setInput(im) # 使用self.net.setInput设置输入数据y = self.net.forward() # 调用 self.net.forward 进行推理else: # ONNX Runtime加载ONNX模型# 调用self.session.run进行推理,指定输入和输出名称y = self.session.run([self.session.get_outputs()[0].name], {self.session.get_inputs()[0].name: im})[0]else: # TensorFlow模型推理im = im.permute(0, 2, 3, 1).cpu().numpy() # 输入张量从PyTorch的BCHW格式转换为NumPy的BHWC格式if self.pb: # TensorFlow冻结图模型# 将输入张量转换为TensorFlow常量,调用self.frozen_func进行推理y = self.frozen_func(x=self.tf.constant(im)).numpy()elif self.saved_model: # SavedModel 格式# 调用self.model进行推理,指定 training=Falsey = self.model(im, training=False).numpy()elif self.tflite: # TensorFlow Lite模型# 获取输入和输出的详细信息input, output = self.input_details[0], self.output_details[0]int8 = input['dtype'] == np.uint8 # 如果是量化模型int8if int8:# # 对输入数据进行反量化scale, zero_point = input['quantization']im = (im / scale + zero_point).astype(np.uint8)# 使用self.interpreter.set_tensor设置输入数据self.interpreter.set_tensor(input['index'], im)# 调用 self.interpreter.invoke 进行推理self.interpreter.invoke()# 获取输出张量y = self.interpreter.get_tensor(output['index'])# 如果是量化模型,对输出数据进行重新量化if int8:scale, zero_point = output['quantization']y = (y.astype(np.float32) - zero_point) * scale# 反归一化检测框y[..., 0] *= w # xy[..., 1] *= h # yy[..., 2] *= w # wy[..., 3] *= h # h# 将推理结果转换为 PyTorch张量,统一返回格式y = torch.tensor(y)# 如验证模式返回(y, []),否则直接返回yreturn (y, []) if val else y
总结
尽可能简单、详细的介绍了核心文件common.py文件的作用:存放着YOLOV3网络搭建常见的通用模块。