DataStreamAPI实践原理——计算模型
引入
通过前面我们对于Flink的理解,我们知道它吸收了 Dataflow 的理念,以及此前已有的流处理系统(如 S4、Storm、MillWheel)的经验,实现了批流一体化的高效数据处理,并且通过灵活的窗口机制、事件时间与水位线机制、容错机制和状态管理等特性,为开发者提供了应对各种复杂的实时数据处理挑战的能力。对于它的核心实现原理可以看我前面的Flink执行原理文章。
Flink 为流式/批式处理应用程序的开发提供了不同级别的抽象:
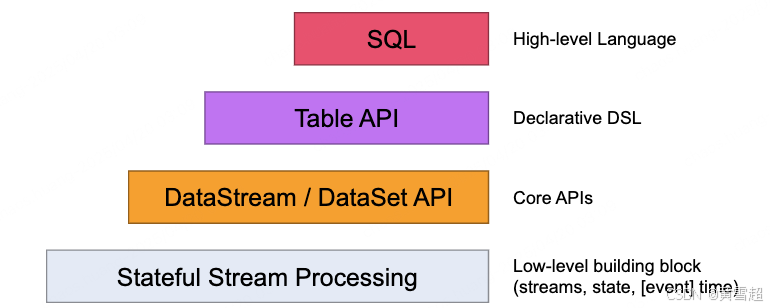
- Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态。此外,用户可以在此层抽象中注册事件时间(event time)和处理时间(processing time)回调方法,从而允许程序可以实现复杂计算。
- Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。Process Function 这类底层抽象和 DataStream API 的相互集成使得用户可以选择使用更底层的抽象 API 来实现自己的需求。DataSet API 还额外提供了一些原语,比如循环/迭代(loop/iteration)操作。
- Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。Table API 遵循(扩展)关系模型:即表拥有 schema(类似于关系型数据库中的 schema),并且 Table API 也提供了类似于关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以声明的方式定义应执行的逻辑操作,而不是确切地指定程序应该执行的代码。尽管 Table API 使用起来很简洁并且可以由各种类型的用户自定义函数扩展功能,但还是比 Core API 的表达能力差。此外,Table API 程序在执行之前还会使用优化器中的优化规则对用户编写的表达式进行优化。表和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。
- Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。
DataStream API实践原理小节的重点在于DataStream API,它主要用于构建流式类型的Flink应用,处理实时无界数据流。和Storm组合式编程接口不同,DataStream API属于定义式编程接口,具有强大的表达力,可以构建复杂的流式应用,例如对状态数据的操作、窗口的定义等。开发者只要调用统一的编程API,传入具体的计算逻辑,不必太多关心底层的细节,就可以完成各种复杂的计算了,并且可以实现快速部署、资源调度、任务容错等,大大的提高了开发效率。
下面我们先看看Flink的计算模型是如何设计的,便于后面我们基于DataStream API开发,并深入其实现原理。
Flink计算模型
DataStream是Flink流式计算编程的抽象数据集(与Spark的RDD是类似的),抽象数据集里面不装要真正要计算的数据,而是记录一些描述信息,例如从哪里读取数据,掉了用了什么方法,传入了什么计算逻辑,通过调用DataStreamTransformation(s)和Sink后,构建成执行计划图DataFlow Graph(类似Spark的DAG),然后生成Task提交到集群中执行真正的计算逻辑。通过前面实时计算核心论文系列文章,我们知道Flink实时计算模型主要分为数据源、转换操作和数据输出三部分。
- 数据源:关注与外部数据系统的打通,读取消息、中间件等数据
- 转换操作:关注数据的转换,包括filter、transform和connect操作
- 数据输出:将转换后的数据输出到外部数据系统,供用户获取
在开发Flink实时计算程序,首先学要创建StreamExecutionEnvironment,然后调用相应的Source算子创建原始的DataStream,再调用零到多次Transformation(转换算子),每调用一次Transformation都会生成一个新的DataStream,最后调用Sink,我们写的程序就形成一个Data Flow Graph(数据流图),然后提交给JobManager,经过优化后生成包含有具体计算逻辑的Task实例,然后调度到TaskManager的slot中开始计算。
Data Source数据源
在实时计算DataStream API中,Source是用来获取外部数据源的操作,按照获取数据的方式,可以分为:基于集合的Source、基于Socket网络端口的Source、基于文件的Source、第三方Connector Source和自定义Source五种。
前三种Source是Flink已经封装好的方法,这些Source只要调用StreamExecutionEnvironment的对应方法就可以创建DataStream了,使用起来比较简单,我们在学习和测试的时候会经常用到。如果以后生产环境想要从一些分布式、高可用的消息中间件中读取数据,可以使用第三方Connector Source,比如Apache Kafka Source、AWS Kinesis Source、Google Cloud PubSub Source等(国内公司使用比较多的是Kafka这个消息中间件作为数据源),使用这些第三方的Source,需要额外引入对应消息中间件的依赖jar包。于此同时Flink允许开发者根据自己的需求,自定义各种Source,只要实现SourceFunction这个接口,然后将该实现类的实例作为参数传入到StreamExecutionEnvironment的addSource方法就可以了,这样大大的提高了Flink与外部数据源交互的灵活性。
从并行度的角度,Source又可以分为非并行的Source和并行的Source。非并行的Source它的并行度只能为1,即用来读取外部数据源的Source只有一个实例,在读取大量数据时效率比较低,通常是用来做一些实验或测试,例如Flink的Socket网络端口读取数据的Source就是一个非并行的Source;并行的Source它的并行度可以是1到多个,即用来读取外部数据源的Source可以有一个到多个实例(在分布式计算中,并行度是影响吞吐量一个非常重要的因素,在计算资源足够的前提下,并行度越大,效率越高)。例如Kafka Source就是并行的Source。
Transformation转换算子
Transformation翻译成中文意为转换,是将一个或多个DataStream调用某个转换算子,生成一个新的DataStream,原来的DataStream不变。Flink程序可以将多个Transformation生成的DataStream组合成一个复杂的DataFlow拓扑。这里所提到的转换算子,其实就是DataStream的转换方法,调用转换算子后,一定会生成一个新的DataStream。
我们前面的内容提到过,DataStream其实是一个抽象的数据集,调用了DataStream的转换算子,并不会立即触发任务的执行,对于Flink程序而言,仅是记录了调用了哪个方法,传入了具体什么处理逻辑,这些转换操作会生成多个有着依赖关系和先后顺序的DataStream,这些DataStream组成了DataFlow拓扑(类似Spark的DAG有向无环图),这个DataFlow其实就是一个任务的逻辑执行计划,Flink最终会将这个逻辑计划转成真正的物理计划,最后提交到集群中运行。
Data Sink 数据输出
经过一系列Transformation转换操作后,最后一定要调用Sink操作,才会形成一个完整的DataFlow拓扑。只有调用了Sink操作,才会产生最终的计算结果,这些数据可以写入到的文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是打印到控制台。