推荐系统/业务,相关知识/概念1
推荐系统核心原理
推荐系统的本质是通过用户行为数据和物品特征数据建立个性化匹配模型,最终预测用户对未知物品的偏好程度。
(推荐系统的核心应该是个性化推荐,根据用户的行为和偏好来预测他们可能喜欢的物品。)
典型架构分层
- 数据层
- 用户数据:
- 物品数据:
- 上下文数据:
- 算法层
- 召回阶段:从百万级候选集中快速筛选千级物品
- 协同过滤
- 内容召回
- 排序阶段:精准预测Top- N物品
- 深度排序模型:Wide&Deep、YouTube DNN
- 实时特征:用户最近30分钟行为序列建模
- 召回阶段:从百万级候选集中快速筛选千级物品
- 应用层
- 结果呈现:考虑多样性(品类分布)、新鲜度(新品加权)、商业目标(GMV优化)
- 效果评估:A/B测试对比点击率(CTR)、转化率(CVR)
上下游流程全链路
graph LR
A[数据采集] --> B{特征工程}
B --> C[离线训练]
B --> D[实时特征]
C --> E[模型仓库]
D --> F[在线服务]
E --> F
F --> G[推荐展示]
G --> H[用户反馈]
H --> A- 上游数据流
- 日志采集:埋点系统捕获用户全链路行为
- 数据清洗:处理异常值(如秒退点击)、去重(刷新重复曝光)
- 特征存储:构建用户画像(长期兴趣/短期意图)、物品图鉴
- 中台处理层
- 离线计算:T+1更新用户长期兴趣向量
- 实时计算:Flink处理最近5分钟行为序列
- 模型更新:在线学习
- 下游应用:
- 多场景适配:首页Feed流、个性化推荐
- 业务融合:结合搜索关键词优化推荐(混合排序)
- 效果监控:异常检测
召回、排序、重排的作用及应用场景
一、召回
作用:
召回是从海量物品库中快速筛选出少量候选集(比如几百到几千个),解决效率问题。核心是通过规则、简单模型或协同过滤算法,初步缩小推荐范围。
应用场景:
- 协同过滤:
- ItemCF:通过物品相似度推荐(例如“买了A的用户也买了B”)
- UserCF:基于用户相似度推荐(例如“和你有相似兴趣的用户喜欢C”)
- 双塔模型:用户和物品分别通过两个神经网络塔生成向量,计算相似度召回。
- 规则召回:基于地理位置、物品热门、用户历史行为等直接筛选。
技术要点:
- 召回需兼顾覆盖率和效率,常采用多路召回融合(如协同过滤+双塔模型+规则召回)
- 负样本选择需要区分“感兴趣”和“完全不感兴趣”,例如曝光未点击作为负样本。
二、排序
作用:
对召回阶段的候选集进行精细化打分,解决精准度问题。通过复杂模型(如深度学习)融合用户画像、物品特征和上下文信息,预测用户对物品的偏好程度。
应用场景:
- 多目标模型:同时优化点击率、播放时长、点赞率等指标。
- MMoE模型:通过专家网络共享底层特征,灵活适配多任务学习。
- 特征融合:用户画像(如兴趣标签)、物品画像(如类目)、上下文特征(如时间、地点)前期融合。
技术要点:
- 排序模型需区分“感兴趣”和非常感兴趣,负样本通常为点击未转化或低互动行为。
- 预估分数需融合多目标结果(如加权求和)
三、重排
作用:
在排序后进一步优化推荐列表,解决多样性、业务规则和用户体验问题。例如去重、插入广告、调整顺序等。
应用场景:
- 多样性控制:避免同类物品连续出现(例如插入不同类目的内容)
- 业务规则:插入运营位(如热门活动)、敏感内容过滤。
- 上下文感知:根据用户当前场景(如深夜模式)调整推荐内容。
用户画像与物品画像
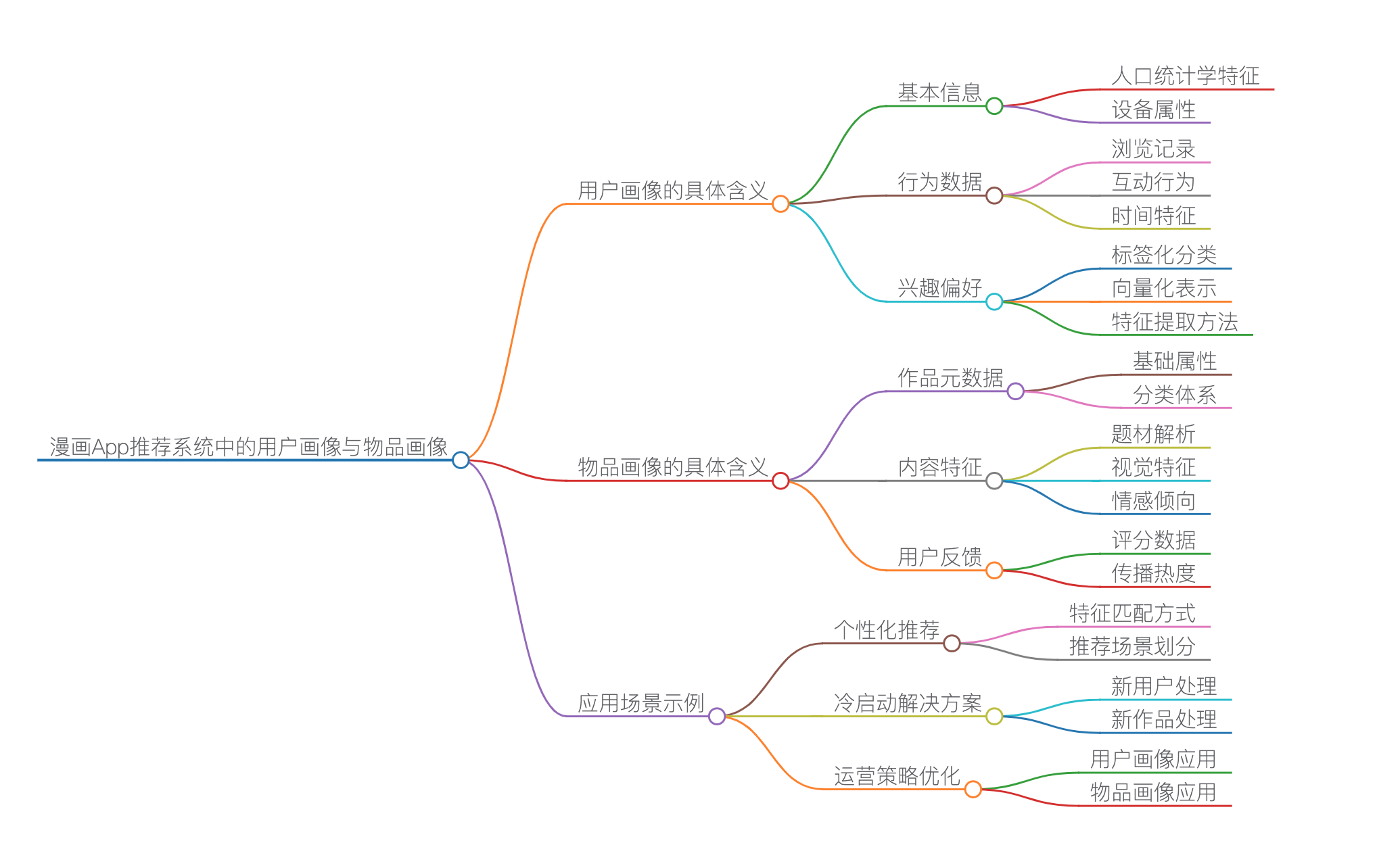
用户画像的具体含义
用户画像是对用户特征的结构化描述,通过多维标签体系刻画用户行为和偏好。
(用户画像方面,应该包括用户的基本信息、行为数据、兴趣偏好等。例如,用户的基本信息可能有年龄、性别,行为数据包括浏览、收藏、阅读时长等。兴趣偏好可能涉及喜欢的漫画类型、作者、画风。此外,社交属性如关注的用户或评论互动也可能重要。这些标签需要具体化到漫画场景,比如具体到“悬疑推理”或“日系画风”。)
具体包括以下内容:
- 基本信息
- 人口统计学特征:年龄、性别、地域(例如青少年偏好热血漫画,女性用户可能更关注恋爱题材)
- 设备属性:手机型号、网络环境(影响漫画加载策略)
- 行为数据
- 浏览记录:漫画点击、章节跳转路径
- 互动行为:收藏、点赞、评论(如用户频繁收藏“悬疑推理”类漫画)
- 时间特征:单次阅读时长、活跃时间段(例如晚间阅读高峰时段)
- 兴趣偏好
- 标签化分类:通过TE- IDF算法提取偏好标签(如“科幻”、“古风”、“日系画风”)
- 向量化表示:
- 社交属性
- 关注列表:追踪用户关注的创作者或同好
- 社区参与:评论互动频率、同人作品投稿记录
物品画像的具体含义
物品画像是对漫画作品的特征解析。
(物品画像,也就是漫画作品的特征。这里需要包括作品的基本信息,如标题、作者、类型,内容特征如题材、画风、剧情关键词,以及用户反馈,如评分、收藏量、评论情感分析。可能还需要考虑更新状态和章节数量等因素。)
主要包含三个维度:
- 作品元数据
- 基础属性:标题、作者、连载状态(如“已完结/周更”)
- 分类体系:官方标签(少年/少女/青年向)、用户自定义标签
- 内容特征
- 题材解析:使用NLP提取剧情关键词(如“穿越”、“异能战斗”)
- 设觉特征:通过CNN卷积网络分析画风(写实/萌系/水墨风格)
- 情感倾向:主角关系网络的情感分析(如“虐心”、“治愈”)
- 用户反馈
- 评分数据:加权计算作品质量得分
- 传播热度:收藏量、章节讨论贴数量
应用场景示例
- 个性化推荐
- 基于用户-物品特征匹配
- 场景化推荐:根据时间算推送不同内容(通勤时段推荐短篇,周末推荐长度连载)
- 冷启动解决方案
- 新用户:通过设备型号、初始选择偏好匹配相似用户群画像
- 新作品:利用内容特征相似度进行关联推荐(如相同画风作品)
- 运营策略优化
- 通过用户画像聚类识别细分市场(例如发现“国漫爱好者”群体增加显著)
- 结合物品画像调整推荐权重(对即将完结作品增加曝光)