毛笔书体检测-hog+svm python opencv源码
链接:https://pan.baidu.com/s/1l-bw8zR9psv1HycmMqQBqQ?pwd=2ibp
提取码:2ibp
--来自百度网盘超级会员V2的分享
1、毛笔字检测运行流程
如果解压文件发现乱码,可以下载Bandizip
解压文件 数据集在百度网盘里面
将文件名字改成images
conda create -n 环境名称 python=3.8
conda activate 环境名称然后配置环境
pip install requirements.txt先运行cat_hog.ipynb观看猫咪图片的hog图片
第一次运行的话需要安装jupyter,过一段时间安装成功,会弹出如下图片(如果没有弹出再点击一次运行)点击python环境,选择你的虚拟环境
点击运行程序

之后打开hog+svm.ipynb
之后他就会安装一些依赖包,然后就可以运行每一个步骤了。运行需要依次点击图片的左边运行按钮,不能第3段程序比2段程序先运行,需要一步一步来,你就能看到每一步的结果了。
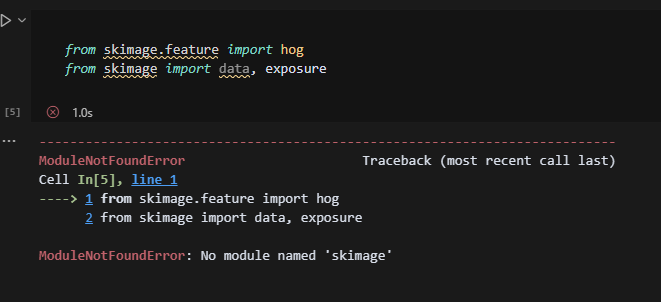
如果有些错误就需要下载相关的模块
运行到这里需要花一点时间
2、毛笔字检测程序分析
hog算法一般用来检测行人、车辆等边缘信息丰富的目标
-
为正常读取照片
-
读取数据的尺寸大小,并且用hog提取毛笔字的边缘特征
hog(image, orientations=4, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True)
是用定义hog的参数
hog(
image, # 输入图像(需为灰度图)
orientations=4, # 方向梯度分成的角度区间数(默认4)
pixels_per_cell=(16, 16), # 每个单元格的像素大小(宽, 高)
cells_per_block=(1, 1), # 每个块包含的单元格数(宽, 高)
visualize=True # 是否返回HOG特征的可视化图像
)
-
返回值
当 visualize=True 时,返回两个结果:
-
HOG特征向量:一维数组,包含所有块的归一化梯度直方图信息。
-
可视化图像:二维数组,直观显示图像中每个单元格的梯度方向。
具体理论可以看这个论文: https://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
-
训练级和测试集的定义,批量处理图片
-
输出zhunquelv
-
保存模型
-
调用保存的模型测试数据集
-
生成验证表格