统计学基本原理
目录
文章目录
- 目录
- 统计学
- 统计学基本概念
- 描述性统计
- 数据可视化图表工具
- 汇总统计
- 统计数据的分布情况:中位数、众数、平均值
- 统计数据的离散程度:极差、方差、标准差、离散系数
- 相关分析
- Pearson 线性关系相关系数
- Spearman 单调关系相关系数
- 回归分析
- 回归模型
- 一元线性回归模型
- 多元线性回归模型
- 判别分析
- 聚类分析
- 主成分分析
- 定性和定量分析的关系
统计学
- 定义:是一门关于 “数据资料” 的收集、整理、 描述、分析和解释的学科。
- 目的:探索数据集合的内在特征与规律性。
- 应用:对系统进行深入、全面的认识;对未来作出准确的预测,继而帮助决策。
- 方法:调查研究。
- 路径:数据收集、数据分析、建立概念、描述预测。
掌握统计学的数据科学家或工程师,他们和具体的行业紧密相联,有扎实的统计基础,也有丰富的行业经验。会编程、做数据可视化。通过海量数据进行分析,获得具有巨大价值的产品和服务,或深刻的洞见。
统计学基本概念
使用解字法,我们可以将 “统计学” 拆分为以下基本概念:
数据:英文单词 data,在拉丁文里是 “已知或事实” 的含义。典型的数据类型包括:
- 定性变量数据(Qualitative): 用于描述事物的属性或类别,其值通常是非数值的,无法进行数学运算。
- 名义变量(Nominal Scale):表示无顺序或等级差异的分类数据,仅用于标识或区分不同类别。例如:性别、颜色等。
- 顺序变量(Ordinal Scale):类别具有自然顺序或等级,但类别间的差异无法量化。例如:满意度评分、教育水平等。
- 定量变量数据(Quantitative):以数值形式表示,具有明确的数学意义,可进行算术运算
- 区间变量(Interval Scale):数值具有等距性,但无绝对零点。例如:温度、年份、IQ 分数等。允许加减运算,但不能计算比率,例如:20℃ 不是 10℃ 的两倍热。
- 比率变量(Ratio Scale):具有区间变量的所有特性,且还拥有绝对零点。即:“0” 可以表示 “无”。例如:身高、体重、收入等。可进行乘除运算,例如:身高 180cm 是 90cm 的两倍。
数据化:把现象转变成可以制表分析的量化形式过程。
数据收集:典型的数据来源包括:
- 统计数据:调查数据、实验数据、汇总数据等。
- 传感器记录数据:金融交易、市场价格、生产过程、财务、营销、传感器等。
- 新媒体网络数据:微信、微博、QQ、手机短信、图片、视频、音频等。
数据分析:典型的分析行为包括:
- 描述和分析系统特征,包括:现状、结构、因素之间关系等。
- 分析系统的运行规律与发展趋势,即:动态数据。
- 对系统的未来状态进行预测,例如:建立模型。
描述性统计
描述性统计用于将数据进行可视化展示,是一种将 “抽象思维” 转换为 “形象思维” 的工具和方法论。
把数字置于视觉空间中,读者的大脑就会更容易发现其中隐藏的模式,得出许多出乎意料的结果。—— Nathan Yau
- 目的:通过数据来描述规律、讲述真相、解决问题。
- 思维:问题导向。数据是用来讲故事的,而故事是面向听众的,而听众是带着问题来的,所以数据可视化使用围绕 “问题” 展开。对讲述问题有用的数据应该展示,相反则可以忽略。
- 技巧:用数据说话的强烈意识 对系统特性的深入思考尝试性分析、对信息点敏感,尤其对异常数据点敏感。
- 工具:图表。
- 基本原则:
- 准确:能清晰地表达主题。
- 醒目:信息点特别突出。
- 美观:图形使用应丰富多彩。
- 图、文并茂:文字应与图、表的篇幅平衡。
- 详略得当,防止冗长的流水帐。
数据可视化图表工具
-
柱形图(Bar Chart):用于描述定性数据的分布。适用于定性数据,例如:豆瓣电影评分。包括堆积柱形图、百分比堆积柱形图、瀑布图、漏斗图等变体。

-
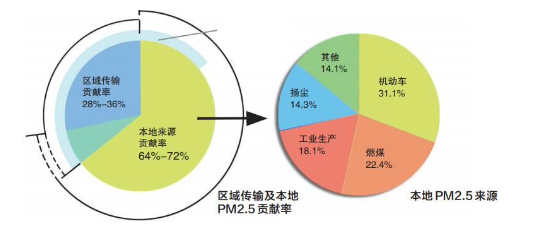
饼图(Pie Chart):用于描述数据的结构性特征。适用于定性数据,例如:北京市空气污染的主要来源。包括子母饼图、旭日图等变体。
-
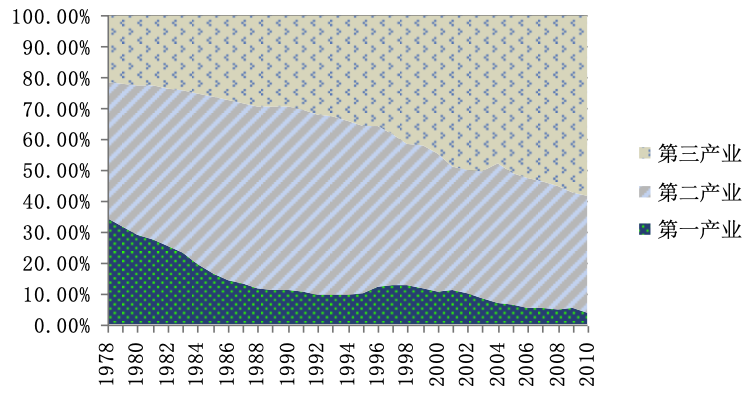
面积图:用于描述数据的动态比率结构。适用于定量数据,例如:上海就业人口的三产构成(1978—2011)。
-
折线图(Line Chart):用于描述数据的动态变化规律。适用于定量数据,例如:城乡居民家庭收入/元(1991~2003)。

-
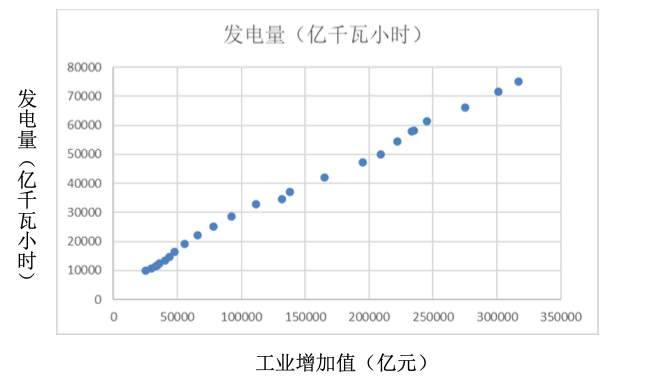
散点图(Scatter Plot):用于描述或反映 2 个定性变量之间的相关关系。例如:发电量与工业增加值的关系(1995~2019)
-
气泡图:用于描述 3 个定性变量的 n 个样本点之间的关系,例如:美国犯罪率气泡图。
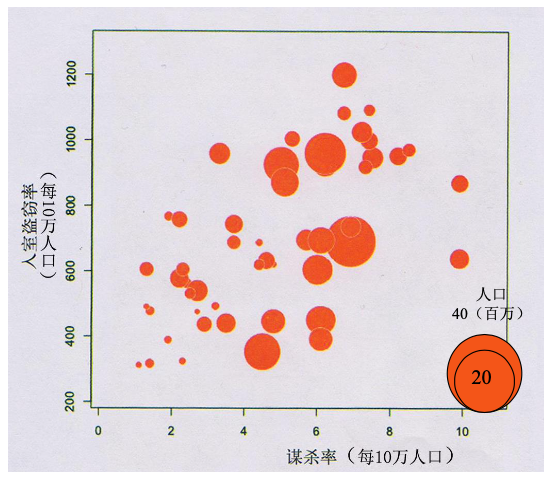
-
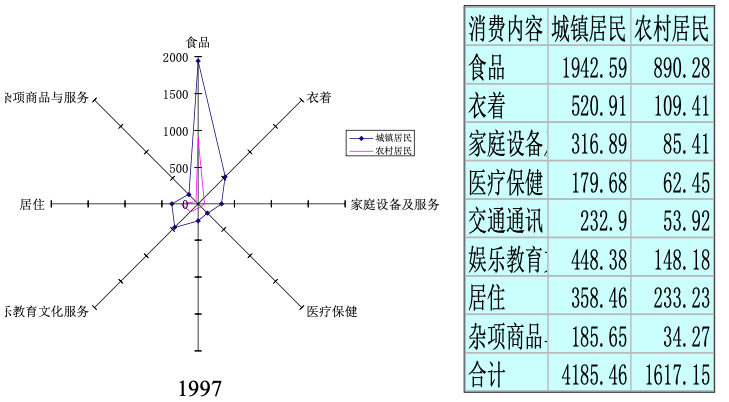
雷达图(Radar chart):用于描述多个定性变量之间的数量关系,例如:城乡居民家庭平均每人生活消费支出(1997 年)。
汇总统计
统计数据的分布情况:中位数、众数、平均值
我们通常可以使用 “中位数、众数、均值” 来描述基本的数据分布情况。但因为三者之间有着不同的特性,所以它们也有着不同的应用场景。
中位数(Median):将数据从小到大排序,处于中间位置的观测值(实际数值)。
- 对于一个数据集,中位数经过数值运算后始终是唯一的;
- 定性数据不能数值运算所以没有中位数;
- 只利用了数据集的中间位置数据,所以对两端的极端值不敏感。
- 应用场景:对于名义变量,用于描述集中趋势。
众数(Mode):出现频次最多的观测值。
- 对于一个数据集,众数可以不唯一;
- 众数不需要数值运算得出,所以定性数据有众数;
- 只利用了数据集的一部分数据,所以不容易受到极端值的影响。
- 应用场景:对于顺序变量,用于描述集中趋势。
平均值(Mean):所有数据之和除以数据的个数,反映数据的总体平均水平。
- 对于一个数据集,均值经过数值运算后始终是唯一的;
- 定性数据不能数值运算所以没有均值;
- 利用了数据集的全部数据参与数值运算,所以容易受极端值影响。
- 应用场景:定量变量,一般使用平均值。例如:歌唱比赛,首先应该利用所有评委的评分,其次应该去除最高分和最低分这 2 个极端值。
统计数据的离散程度:极差、方差、标准差、离散系数
所谓离散程度,即:数据集中每 2 个数据之间的差异程度。通常使用极差、方差、标准差、离散系数进行测量。
极差(Rang):最大值与最小值之间的差距,显然容易受到极端值的影响。
- 四分位极差(Interquartile Rang):为了消除极端值的影响。
方差(Variance):以均值为中心,测量所有观测值与均值的平均偏离程度。
-
总体方差(Population Variance):描述整个数据集所有数据与总体均值的偏离程度。“方差” 通常指的就是整体方差。
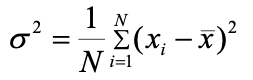
-
样本方差(Sample Variance):描述从整个数据集中抽取的样本数据与样本均值的偏离程度,是总体方差的估计量。当总体方差数据量特别巨大时,可以考虑用样本方差来进行预估。
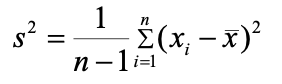
标准差(Standard Deviation):方差的平方根就是标准差。值得注意的是,在一个方差使用平方来表示观测值样本和均值先之间的 “垂直距离”,但平方也放大了数值的量纲。所以标准差就是对方差的平方开根,将结果数值还原为与原样本相同的量纲。
离散系数(Coefficient of Variation):标准差常用于描述一个数据集的离散程度;而离散系数则用于比较 2 个及以上数据集之间的离散程度。离散系数是一种 “无量纲” 的相对度量,公式如下,离散系数等于标准差除以均值,从而消除了量纲的影响,例如:1.4/6=0.23 和 14/60=0.23 之间的 CV 相同,但量纲相差了 10 倍。反之,通常不会使用标准差作为多个数据集之间的离散程度的比较。
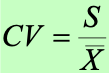
相关分析
线性关系:线性函数 Y=f(X),每一个 X 值都唯一地对应一个 Y 值。
随机关系(Stochastic Relationship):当 X 的值给定时,Y 的取值服从一个分布,而不是一个唯一对应的 Y 值。
相关系数(The Correlation Coefficient):在随机关系场景中,需要引入一个相关系数来描述 “X” 和 “Y 的取值分布” 之间的关联程度的量化指标。简而言之,相关系数描述了 2 个变量 a、b 之间是否存在关系,以及关系是否密切(是否线性相关)。
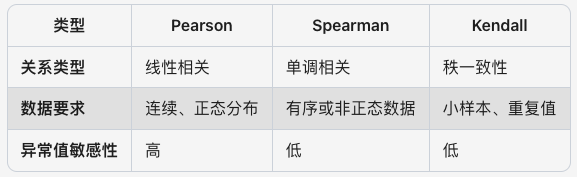
现如今,根据不同的数据类型和数据分析需求,相关系数有多种定义和计算方法。包括:Pearson、Spearman、Kendall 等相关系数。
Pearson 线性关系相关系数
Pearson(皮尔逊)相关系数 r(x, y),用于衡量两个连续变量之间的 “线性相关” 程度。
- 存在 2 个连续变量 x 和 y:

- Pearson 系数计算公式:分子为 x 和 y 的样本协方差,分母为 x 和 y 的样本方差的乘积。

r(x, y) 的取值范围诶 [-1, 1],对应的判别性质为:

最佳实践经验值为:

Spearman 单调关系相关系数
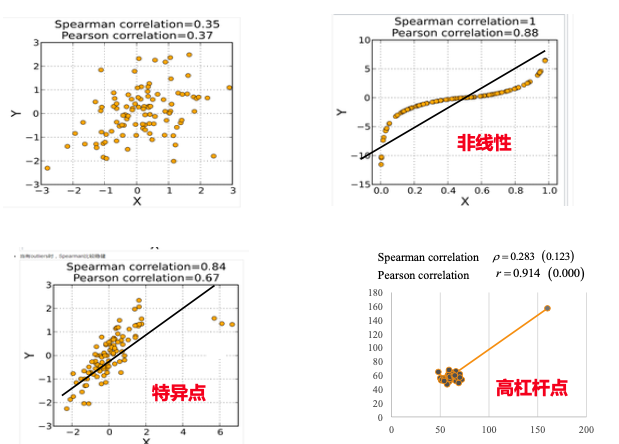
Pearson 用于测量 x 和 y 连续变量之间的线性相关性,但现实中存在大量非线性相关的数据集,但它们之间也会存在某种关联关系,如单调关系。单调关系,即:即一个 x 变量增加时,另一个 y 变量是否倾向于同向或反向的变化,而不会要求严格线性关系。
Spearman 单调关系(正相关、负相关)相关系数,基于 2 个连续变量之间的秩次( Ranks,排序位置)来进行计算。可用于线性或非线性连续变量数据集,尤其适用于顺序连续变量、存在异常值的连续变量、非正态分布连续变量。
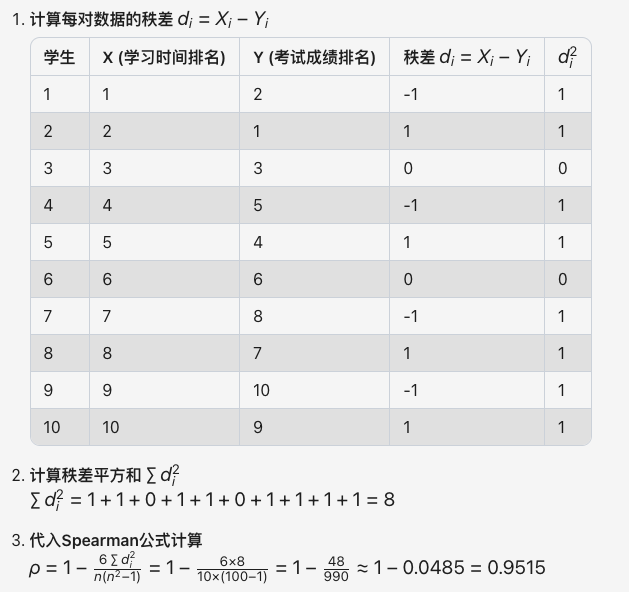
例如:使用 Spearman 来判别某班级 10 名学生按学习时间(小时/周)和考试成绩排名之间的单调关系。如下表。
| 学生 | 学习时长 a | 学习时长排名 x | 考试成绩 b | 考试成绩排名 y |
|---|---|---|---|---|
| A | 十小时 | 1 | 99 | 2 |
| B | 九小时 | 2 | 100 | 1 |
| C | 八小时 | 3 | 98 | 3 |
| D | 七小时 | 4 | 96 | 5 |
| E | 六小时 | 5 | 97 | 4 |
| F | 五小时 | 6 | 95 | 6 |
| G | 四小时 | 7 | 93 | 8 |
| H | 三小时 | 8 | 94 | 7 |
| I | 二小时 | 9 | 91 | 10 |
| J | 一小时 | 10 | 92 | 9 |
显然,以上 a 和 b 两组数据呈现出非线性特征,但这两组数据未必就不存在任何正相关或负相关的关系。同时 a 和 b 两组数据属于顺序变量类型,所以可以采用 Spearman 来测量判别。
从下述计算可知,Spearman 计算过程完全不关心 a 和 b 的实际数据,只会关系 x 和 y 的 ranks 排名关系。计算结果 Spearman 系数 ≈0.952,接近 1,表明学习时间排名与考试成绩排名存在极强的正相关。