线性回归算法
文章目录
- 线性回归
- 最优解
- 多元线性回归
- 线性回归算法的推导
- 中心迹象定理
- 正态分布与预测的关系
- 误差
- 最大似然估计
- 概率密度函数
- 线性回归损失函数MSE推导
- 解析解方法求解线性回归
- 判定损失函数凸函数
线性回归
- 线性回归是机器学习中有监督机器学习下的一种算法。
- 回归问题主要关注确定一个唯一的因变量(dependentvariable)(需要预测的值)和一个或多个数值型的自变量(independent variables)(预测变量)之间的关系。
- 需要预测的值:即目标变量,target,y,连续值。
- 预测变量:影响目标变量的因素,predictors,X1…Xn,可以是连续值也可以是离散值。

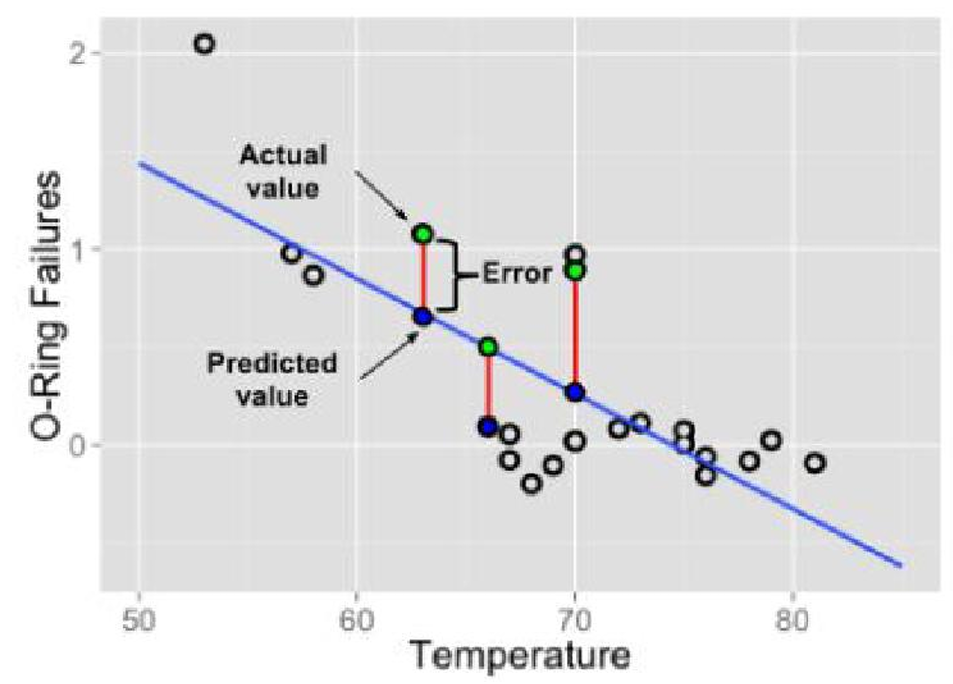
最优解
- Actual value:真实值,即已知的y
- Predicted value:预测值,是把已知的x带入到公式里面和猜出来的参数a,b计算得到的
- Error:误差,预测值和真实值的差距
- 最优解:尽可能的找到一个模型使得整体的误差最小,整体的误差通常叫做损失Loss
- Loss:整体的误差,loss通过损失函数lossfunction计算得到
多元线性回归

- examples是已知的样本,examples中包含X也包含Y,Y就是outcome已知结果,如果咱们有m条历史记录,就是有m条样本,也就是有m个Y值,或者说Y为包含m个值的一维向量。
- feature:把影响结果的因素,因为有多个所以图里就是features,值得一提的是X0一列,是为了后面可以通过公式计算出截距项而加的,同时会把X0一列所有值设置恒为1,这样X就是m行4列的二维数组即矩阵。
- 中ε代表error误差,每条样本预测的值和真实值之间都会有误差,所以有m条样本就对应m个ε值,ε和Y一样是包含m个值得一维向量。
- 在多元线性回归中W是一维向量,代表的是 W 0 W_0 W0到 W n W_n Wn,可以用线性代数的方式去表达公式,这时算法要求解的就是这个向量。
y = W T X + ε , y = X W + ε y=W^TX+ε,y=XW+ε y=WTX+ε,y=XW+ε

线性回归算法的推导
- 回归简单来说就是“回归平均值”(regressiontothemean)。但是这里的mean并不是把历史数据直接当成未来的预测值,而是会把期望值当作预测值。
中心迹象定理
- 高尔顿钉板

- 中心极限定理(centrallimittheorem)是概率论中讨论随机变量序列部分和分布渐近于正态分布的一类定理。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量累积分布函数逐点收敛到正态分布的积累分布函数的条件。
正态分布与预测的关系

误差
- 第 i i i个样本实际的值 y i y_i yi 等于 预测的值 y ^ i + ε i \hat y_i +ε_i y^i+εi,假定所有的样本的误差都是独立的,有上下的震荡,震荡认为是随机变量,足够多的随机变量叠加之后形成的分布,根据中心极限定理,它服从的就是正态分布,因为它是正常状态下的分布,也就是高斯分布!均值是某一个值,方差是某一个值。
ε i = ∣ y i − y ^ i ∣ \varepsilon_i =| y_i - \hat y_i | εi=∣yi−y^i∣ - 方差我们先不管,均值我们总有办法让它去等于零0的,因为我们这里是有W0截距的,所有误差我们就可以认为是独立分布的,1<=i<=m,服从均值为0,方差为某定值的高斯分布。
- 机器学习中我们假设误差符合均值为0,方差为定值的正态分布!!
最大似然估计
- 最大似然估计(英语:maximumlikelihood estimation,缩写为MLE):估计一个概率模型的参数的一种方法。“似然”用现代的中文来说即“可能性”。若称之为“最大可能性估计”则更加通俗易懂。
概率密度函数
-
在数学中,连续型随机变量的概率密度函数是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。
-
最常见的连续概率分布是正态分布,其概率密度函数为:
-
f ( x ∣ μ , σ 2 ) = 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 f(x \mid \mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \ e^{-\frac{(x - \mu)^2}{2\sigma^2}} f(x∣μ,σ2)=2πσ21 e−2σ2(x−μ)2
-
随着参数 μ \mu μ(均值)和 σ \sigma σ(标准差)变化,概率分布形态会相应改变。
-
误差项的概率密度函数:对于一组服从正态分布的数据误差,当假设误差分布的均值 μ = 0 \mu = 0 μ=0 时,单个样本误差 ε i \varepsilon_i εi 的概率密度函数可表示为:
f ( ε i ∣ μ , σ 2 ) = 1 2 π σ 2 e − ε i 2 2 σ 2 f(\varepsilon_i \mid \mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \ e^{-\frac{\varepsilon_i^2}{2\sigma^2}} f(εi∣μ,σ2)=2πσ21 e−2σ2εi2 -
该表达式通过平移正态分布的位置(截距项调整)实现了误差分布的零均值化处理。
-
正太分布的线性回归的最大总似然
线性回归损失函数MSE推导
- 最大似然估计就是一种参数估计的方式,就是把总似然最大的那一时刻对应的参数θ当成是要求的最优解。
arg max θ L θ ( ε 1 , … , ε m ) = arg max θ ∏ i = 1 m 1 2 π σ 2 e − ( y i − θ T x i ) 2 2 σ 2 \underset{\theta}{\arg \max } L_{\theta}\left(\varepsilon_{1}, \ldots, \varepsilon_{m}\right)=\underset{\theta}{\arg \max } \prod_{i=1}^{\mathrm{m}} \frac{1}{\sqrt{2 \pi \sigma^{2}}} e^{-\frac{\left(y_{i}-\theta^{T} x_{i}\right)^{2}}{2 \sigma^{2}}} θargmaxLθ(ε1,…,εm)=θargmaxi=1∏m2πσ21e−2σ2(yi−θTxi)2
- 通过最大化似然函数的形式成为我们的目标函数,因为我们的目标就是最大化这个式子从而求解 θ \theta θ。
- 对角化简化运算
arg max θ L θ ( ε 1 , … , ε m ) = arg max θ log e ( ∏ i = 1 m 1 2 π σ 2 e − ( y i − θ T x i ) 2 2 σ 2 ) \underset{\theta}{\arg \max } L_{\theta}\left(\varepsilon_{1}, \ldots, \varepsilon_{m}\right)=\underset{\theta}{\arg \max } \log _{\mathrm{e}}\left(\prod_{i=1}^{\mathrm{m}} \frac{1}{\sqrt{2 \pi \sigma^{2}}} e^{-\frac{\left(y_{\mathrm{i}}-\theta^{T} x_{i}\right)^{2}}{2 \sigma^{2}}}\right) θargmaxLθ(ε1,…,εm)=θargmaxloge(i=1∏m2πσ21e−2σ2(yi−θTxi)2)

解析解方法求解线性回归
J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 = 1 2 ( X θ − y ) ⊤ ( X θ − y ) J(\theta) = \frac{1}{2}\sum_{i=1}^{m} \left( h_{\theta}(x^{(i)}) - y^{(i)} \right)^2 = \frac{1}{2}(X\theta - y)^\top (X\theta - y) J(θ)=21i=1∑m(hθ(x(i))−y(i))2=21(Xθ−y)⊤(Xθ−y)
J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 = 1 2 ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ( h θ ( x ( i ) ) − y ( i ) ) = 1 2 ( X θ − y ) T ( X θ − y ) = 1 2 ( ( X θ ) T − y T ) ( X θ − y ) = 1 2 ( θ T X T − y T ) ( X θ − y ) = 1 2 ( θ T X T X θ − θ T X T y − y T X θ + y T y ) \begin{aligned} J(\theta) & =\frac{1}{2}\sum_{i=1}^m\left(h_\theta(x^{(i)})-y^{(i)}\right)^2 \\ & =\frac{1}{2}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})(h_\theta(x^{(i)})-y^{(i)}) \\ & =\frac{1}{2}(X\theta-y)^T(X\theta-y) \\ & =\frac{1}{2}((X\theta)^T-y^T)(X\theta-y) \\ & =\frac{1}{2}(\theta^TX^T-y^T)(X\theta-y) \\ & =\frac{1}{2}(\theta^TX^TX\theta-\theta^TX^Ty-y^TX\theta+y^Ty) \end{aligned} J(θ)=21i=1∑m(hθ(x(i))−y(i))2=21i=1∑m(hθ(x(i))−y(i))(hθ(x(i))−y(i))=21(Xθ−y)T(Xθ−y)=21((Xθ)T−yT)(Xθ−y)=21(θTXT−yT)(Xθ−y)=21(θTXTXθ−θTXTy−yTXθ+yTy)
-
为了方便理解,大家可以把下图的横轴看成是θ轴,纵轴看成是loss损失,曲线是loss function,然后你开着小车去寻找最优解。

-
如果我们把最小二乘看成是一个函数曲线,极小值(最优解)一定是个驻点,驻点顾名思义就是可以停驻的点,而图中你可以看出驻点的特点是统统梯度为0。
-
梯度:函数在某点上的切线的斜率
-
如何求?求函数在某个驻点上的一阶导数即为切线的斜率。更近一步,或者反过来说,就是我们是不是可以把函数的一阶导函数形式推导出来
J ′ ( θ ) = [ 1 2 ( θ T X T X θ − θ T X T y − y T X θ + y T y ) ] ′ = 1 2 [ ( θ T X T X θ ) ′ − ( θ T X T y ) ′ − ( y T X θ ) ′ + ( y T y ) ′ ] \begin{aligned} J^{^{\prime}}(\theta) & =[\frac{1}{2}(\theta^TX^TX\theta-\theta^TX^Ty-y^TX\theta+y^Ty)]^{\prime} \\ & =\frac{1}{2}[(\theta^TX^TX\theta)^{^{\prime}}-(\theta^TX^Ty)^{^{\prime}}-(y^TX\theta)^{^{\prime}}+(y^Ty)^{^{\prime}}] \end{aligned} J′(θ)=[21(θTXTXθ−θTXTy−yTXθ+yTy)]′=21[(θTXTXθ)′−(θTXTy)′−(yTXθ)′+(yTy)′]
-
已知是X和y,未知是θ,所以和θ没关系的部分求导都可以忽略不记

-
然后设置导函数为0,去进一步解出来驻点对应的θ值
θ = ( X T X ) − 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)−1XTy -
数值解是在一定条件下通过某种近似计算得出来的一个数值,能在给定的精度条件下满足方程 解析解为方程的解析式(比如求根公式之类的),是方程的精确解,能在任意精度下满足方程。
判定损失函数凸函数
- 判定损失函数是凸函数的好处在于我们可能很肯定的知道我们求得的极值即最优解,一定是全局最优解

- 判定凸函数的方式:看黑塞矩阵是否是半正定的。
- 黑塞矩阵(hessian matrix)是由目标函数在点 X 处的二阶偏导数组成的对称矩阵。在导函数的基础上再次对θ来求偏导,就是 X T X X^TX XTX所谓正定就是 A 的特征值全为正数,那么是正定的。半正定就是A的特征值大于等于0,就是半正定。
- 机器学习中往往损失函数都是凸函数,到深度学习中损失函数往往是非凸函数,即找到的解未必是全局最优,只要模型堪用就好。
- ML 学习特点,不强调模型 100% 正确,是有价值的,堪用的。