faster-RCNN训练【环境配置→自建数据集→训练→改错】
前期工作:下载pycharm、anaconda、visual studio,下载faster-RCNN代码(我用的是B站霹雳吧啦Wz大佬的代码,地址如下:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing)
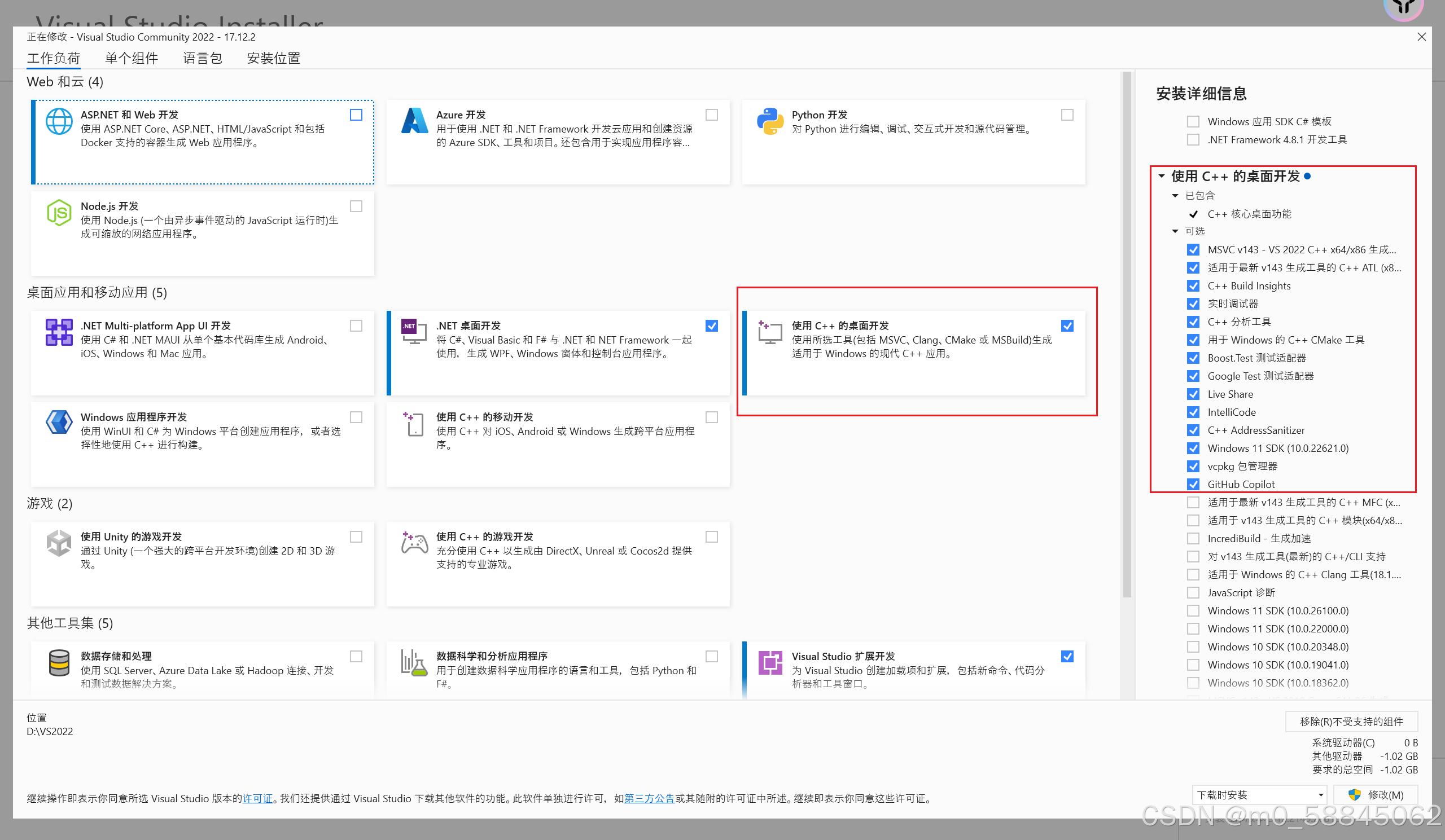
1.visual studio下载完要安装【使用C++的桌面开发】
如图3所示,按红框里的选。如果一开始没装,打开Visual Studio,按图1-图3红框依次点击,最后点图3右下角“修改”即可。

2.conda环境配置
打开这个: (在电脑搜索栏搜“Anaconda Promp”就行),
(在电脑搜索栏搜“Anaconda Promp”就行),
依次输入以下代码,注意此处的“fasterRCNN”是你给环境起的名字,可以自行更改。
conda create -n fasterRCNN python=3.8
activate fasterRCNNconda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch输入下面代码,成功最好,如果出错了 ,就不管了,你先跳过,后面出错了看本文第六章【6.各种错误如何解决】
pip install -r requirements.txt3.pycharm环境配置
进到项目中,点右下角红框处(我这里是已经配置好了,你显示的肯定不跟我一样),

点红框

这里按图片顺序点,注意第4个红框选的那个python.exe文件,是你创建的环境中的文件

4.训练数据集制作
我这里从图像打标开始,如果你已经有图像以及对应的xml文件,可以直接看4.3划分数据集
4.1安装labelimg
进入Anaconda Promp,依次输入以下代码:
activate fasterRCNN【下面这个代码2就安装的时候输就行了,安装完了之后每次启动labelimg只用输代码1和代码3】
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simplelabelimg就进入到labelimg里了
4.2打标
点A,选择要打标的图片所在的文件夹;点B,选择标签保存的文件夹。(可以选择同一个文件夹)

按“W”,你鼠标上出来一条十字线,然后框上你需要标的目标,输入标签名就行了。按“A”和“D”是切换上一张图、下一张图,切换图片后自动保存上一张标签。
全部打完看看标签格式是不是xml(就是右键点击文件——属性),如果是txt,要改成xml格式(写个脚本就能实现,之后我会把脚本放上来,如果我忘放了,留言或者私信一下)
【打标特别注意事项:
1.如果你发现一张图上没有需要标的目标,可以跳过,但是一定记得打完标把这张图删掉!
2.如果你在一张图上打了个标签,并且标签已经保存了,但又不想要这个标签了,把这个标签删掉后,删掉后本图片上没有其他目标了,那么你文件夹中会有一个对应的 空的 xml文件,一定记得把这个xml文件和对应的图片删掉!】
4.3划分数据集
在faster_rcnn文件夹下建立红框中的文件夹,最好名字一模一样,不然后面还要改代码,几个名字放在这里,空格别复制啊:VOCdevkit VOC2012 Annotations ImageSets JPEGImages Main

把你所有的图片放在上述JPEGImages文件夹中;xml文件放在Annotations文件夹中。
打开代码【split_data.py】(红框),看下路径(黄框)没问题,直接运行。
这个代码是将数据划分为训练集和验证集,原代码写的验证集比例是0.5(橘框),我这里改成0.2了,可以随便改。

在根目录(最外层目录)下会生成两个txt文件【train.txt】和【val.txt】,剪切两个文件,粘贴到你前面创建的ImageSets的Main文件夹下

打开文件【pascal_voc_classes.json】,改成你的标签,最后一个标签记得给后面的逗号删掉,把多余的空行也删掉。

5.开始训练!!!!!!!!!!!!
我用的gpu训练,打开【train_multi_GPU.py】(红框)这个文件,可以改下黄框里的内容,调整训练参数,如果你路径和我的不一样,记得把图片中200行的路径也改了。运行!!!!

6.各种错误如何解决:
① The package for pytorch located at XXXXX appears to be corrupted
环境没安好,重新安一下
解决:进入Anaconda Prompt,依次输入:
activate fasterRCNNconda clean --packages问你Y/N就输Y,回车,下同
conda clean --allconda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch②RuntimeError: CUDA out of memory
解决:把batchsize调小
③ModuleNotFoundError: No module named XXX
解决:按红框顺序点,然后在下面输入pip install XXX
前面requirements.txt那没装好,就会出现好几个这个问题,出一个这个问题你就pip一个,直到不出这个错

④json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 colu
标签错啦
解决:打开根目录下的文件【pascal_voc_classes.json】,看看标签哪里有问题,打错字了、有多余空行、最后一个标签后面还有逗号......改就完了。
⑤AttributeError: 'Namespace' object has no attribute 'rank'
解决:train_multi_GPU.py文件最后一堆parser.add_argument最后加上以下代码
parser.add_argument('--rank', type=int, default=-1, help='The rank of the current process in distributed training')如图:
⑥训练出现一个警告:UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argume
解决:找到报错的地方,在括号里的最后加上:indexing = 'ij'
 即:torch.meshgrid(shifts_y, shifts_x,indexing = 'ij')
即:torch.meshgrid(shifts_y, shifts_x,indexing = 'ij')
⑦Loss is nan,stopping training
解决:可以先试试把batchsize调大,如果没用或者出现RuntimeError: CUDA out of memory问题,用以下方法:
打开【train_eval_utils.py】,把with torch.cuda.amp.autocast这行黄框代码注释了,记得把下面两行的缩进删除

【在整个项目中找某句代码小技巧:全局搜索】
全局搜索:

箭头处输入需要搜索的代码
