介绍一下,Stable Diffusion!文生图的稳定之选
Stable Diffusion(SD模型),由Stability AI与LAION等机构合作研发,是一款功能强大的生成式模型,拥有约10亿(1B)参数。其应用广泛,包括但不限于文生图(txt2img)、图生图(img2img)及图像修复(inpainting)等功能。

stable diffusion整合包可以扫描下方,免费获取

Stable Diffusion网络架构
** #**Stable Diffusion主要工作流:
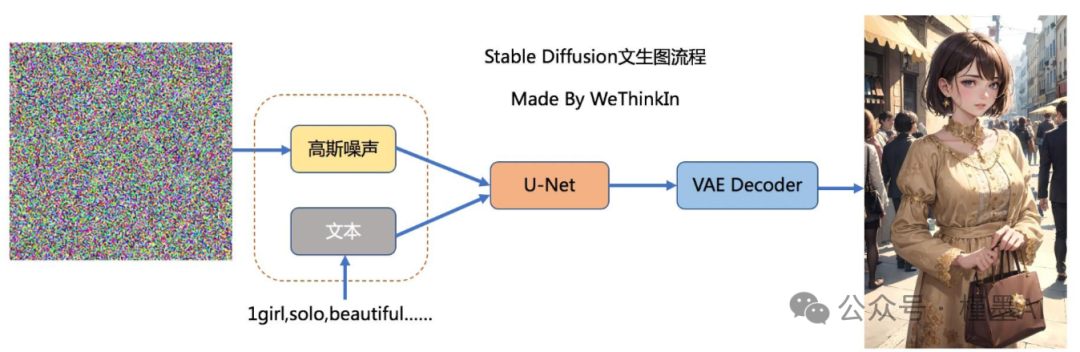
**· 提示词输入与文本编码:
文本编码器(Text Encoder)首先将用户输入的提示词(Prompt)转换为语义向量**,这些语义向量携带着文本信息的精髓,为后续的图像生成提供指导。
**· 潜在空间压缩:
为降低计算复杂度并提取图像的核心特征,采用变分自编码器(VAE)将高维度的图像数据压缩到一个低维度的潜在空间。这个潜在空间是图像信息的精简表示**,为后续的处理提供了便利。
**· 正向扩散过程:
在潜在空间中,模型通过逐步添加噪声来模拟物理中的扩散现象**。这个过程使得图像的特征逐渐模糊,最终转化为完全随机的噪声分布。该步骤是后续噪声预测和图像恢复提的基础。
**· 噪声预测器训练:
在训练阶段,采用U-Net结构的神经网络作为噪声预测器**,该网络通过学习如何从噪声图像中恢复出原始图像来训练自己,从而具备预测潜在空间中图像噪声的能力。
**· 反向扩散与图像生成:
在生成阶段,模型利用训练好的噪声预测器来估计潜在空间中图像的噪声**,并逐步去除这些噪声。通过这一过程,模型能够从噪声中恢复出清晰的图像,实现图像的生成。
**· 条件生成机制:
SD模型通过提示词来引导图像的生成。这些提示词首先被分词且转换为嵌入向量**,再将向量输入到噪声预测器中,以指导整个图像生成过程。这种条件生成机制确保了生成的图像与提示词的内容高度匹配。
**· VAE解码与图像输出:
**最后,潜在空间中的图像通过VAE的解码器被转换回原始的像素空间,生成最终的图像。这一步骤将潜在空间中的图像信息还原为可视化的图像。
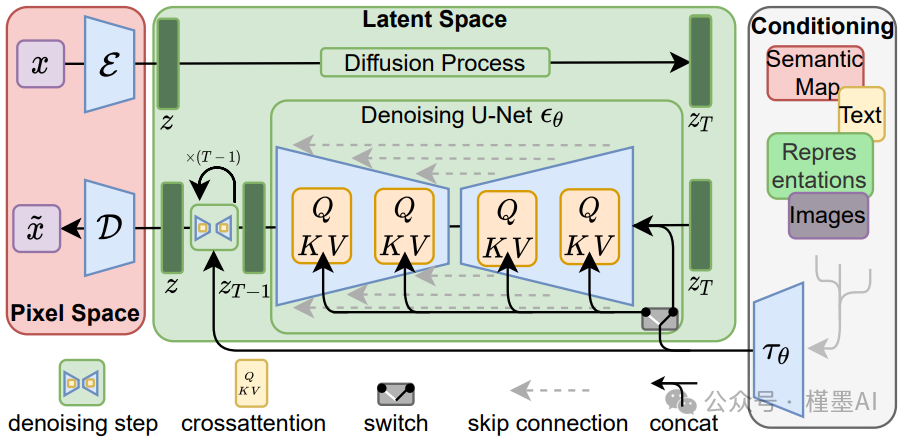
** #***CLIP Text Encoder模型:*
在SD模型中前置引入CLIP Text Encoder模块,该模块负责将输入的文本信息编码成Text Embeddings特征矩阵,这一矩阵紧密关联并反映了文本信息的核心内容。随后,这些Text Embeddings被用作SD模型的控制信号,指导图像的生成过程,确保生成的图像与输入的文本信息高度匹配。

** #***VAE模块:*
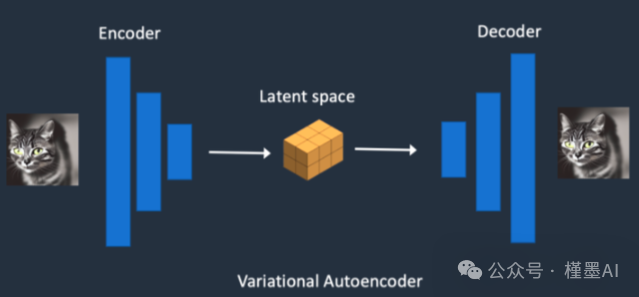
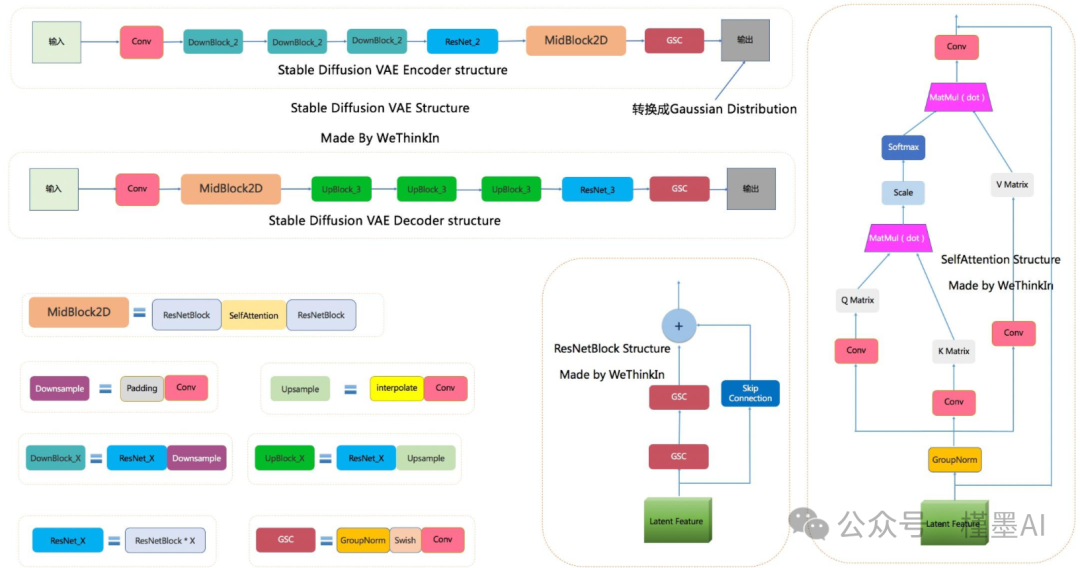
对于图生图任务,在提供文本信息的同时,还需要将原始图片送入VAE,VAE(变分自编码器,全称Variational Auto-Encoder)是一种基于Encoder-Decoder架构的先进生成模型。
VAE的Encoder组件负责将输入的图像高效地转换为一个低维度的Latent特征空间表示,这一表示捕捉了图像的关键信息。随后,这个低维的Latent特征被用作U-Net架构的输入,以进一步驱动图像的生成过程。
VAE的Decoder组件则承担着重建任务,它能够将这个低维的Latent特征逆向映射回原始的像素级图像,实现图像的高质量还原。
对于文生图任务,流程则相对简化:仅需输入文本信息,并借助random函数生成一个高斯噪声矩阵,这个矩阵将作为Latent Feature的替代。
** #**正向扩散与反向扩散:
· 正向扩散过程(Forward Diffusion Process):是一个逐步向图像添加高斯噪声的过程,直至图像最终转变为近乎纯粹的随机噪声矩阵。这一过程模拟了信息从清晰图像向无序状态的自然过渡。
· 反向扩散过程(Reverse Diffusion Process):则是一个去噪过程。它从一个随机噪声矩阵起始,通过一系列迭代步骤,逐步减少并去除噪声,直至最终恢复并生成一张清晰、有意义的图像。这一过程体现了从无序向有序、从潜在空间向可观察图像空间的逆向映射。
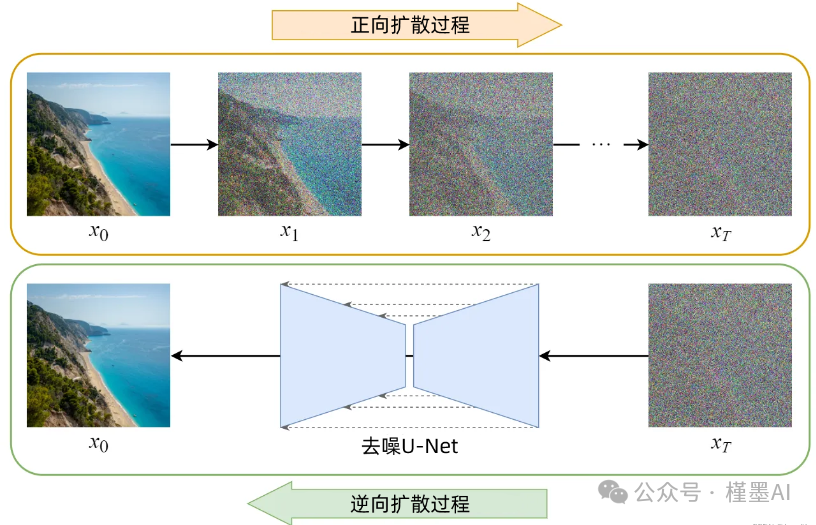
U-Net是一种在噪声估计与去除中广泛应用的神经网络架构,其名称源自其独特的U形结构。作为一种全卷积神经网络,U-Net在图像处理领域展现出了极高的效用。
该网络的核心特点在于其能够接收图像作为输入,并通过逐步的下采样(或称为编码过程)来提取图像的低维特征表示。这一过程有助于网络聚焦于图像中的重要属性和结构。随后,U-Net利用上采样(或称为解码过程)逐步恢复图像的细节,直至输出与输入图像尺寸相近的去噪图像。这种设计使得U-Net在图像去噪、分割等多种任务中表现出色。
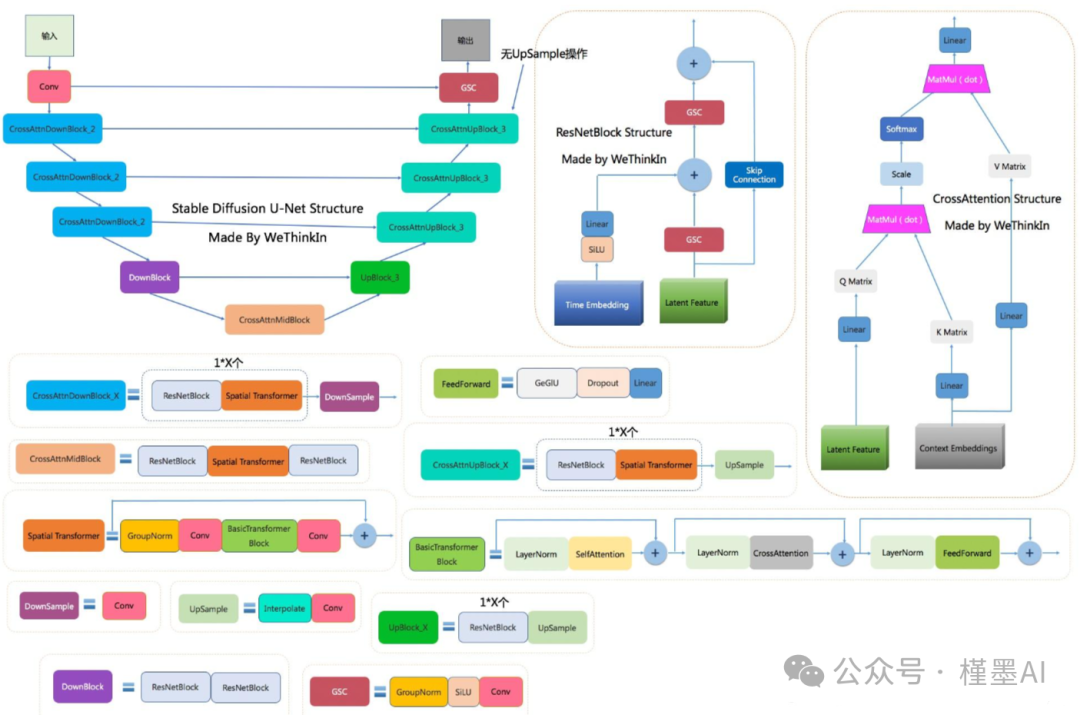
** #**图像生成:
U-Net网络在SD中扮演着预测噪声的关键角色,并不断优化生成过程。在预测噪声的同时,U-Net还负责不断融入文本语义信息,以增强生成图像的相关性和准确性。为了更有效地控制生成过程,schedule算法被引入,它对U-Net每次预测的噪声进行动态调整和优化,从而精确控制U-Net预测噪声的强度。
在SD模型中,U-Net的迭代优化过程通常包含大约50到100个Timestep。随着迭代步数的增加,Latent Feature(潜在特征)的质量逐步提升,表现为纯噪声的减少以及图像和文本语义信息的增加。这一过程确保了生成图像的高质量和与输入文本的高度一致性。

在U-Net网络和Schedule算法完成任务后,SD模型会接收经过优化迭代的潜在特征(Latent Feature),并将其输入到变分自编码器(VAE)的解码器部分,以便将这些潜在特征重建为像素级的图像。

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
