multi_agents
多智能体系统(Multi-agent Systems)
什么是智能体?
在 LangGraph 中,智能体(Agent) 是一个使用大型语言模型(LLM)来决定应用程序控制流程的系统。随着系统的发展,单一智能体可能会变得越来越复杂,导致管理和扩展变得困难。例如,您可能会遇到以下问题:
- 工具过多导致决策失误:智能体拥有过多的工具,可能无法有效选择下一个要调用的工具。
- 上下文过于复杂:单一智能体难以跟踪和管理复杂的上下文。
- 需要多个专业化领域:系统中可能需要多个专门化领域的智能体,如规划器、研究员、数学专家等。
多智能体系统的解决方案
为了解决上述问题,您可以将应用程序拆分为多个较小、独立的智能体,并将它们组合成一个多智能体系统。这些独立的智能体可以简单如一个提示和一个 LLM 调用,或复杂如 ReAct 智能体(ReAct agent)等。
多智能体系统的主要优势
- 模块化(Modularity):分离的智能体使得开发、测试和维护系统更加容易。
- 专业化(Specialization):可以创建专注于特定领域的专家智能体,从而提高整个系统的性能。
- 控制性(Control):可以明确控制智能体之间的通信方式,而不是依赖于函数调用。
多智能体架构(Multi-agent Architectures)
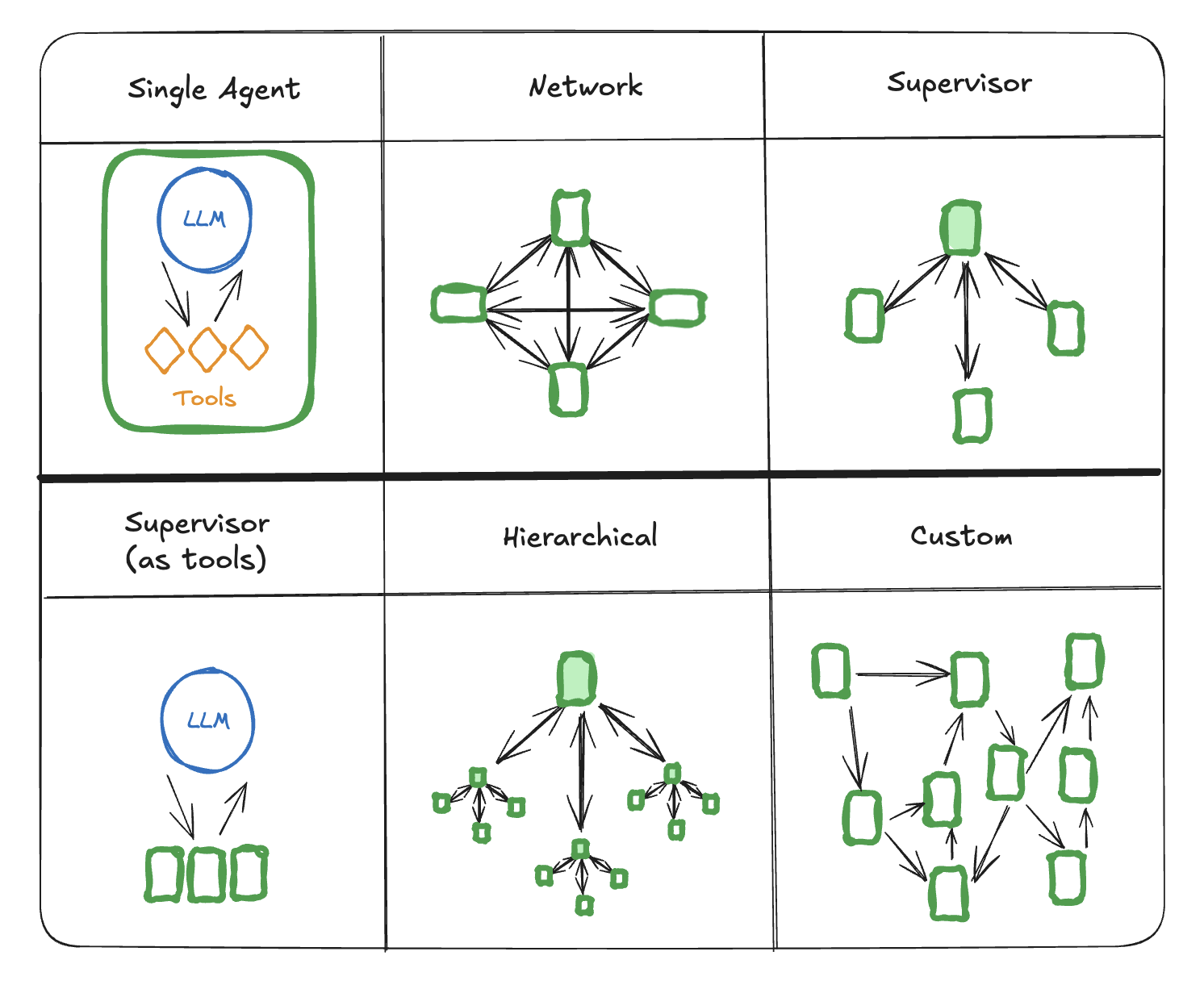
多智能体系统有几种不同的连接方式:
1. 网络(Network)架构
多智能体网络详解
本文详细介绍了如何使用 LangGraph 构建一个多智能体网络架构,以有效处理复杂任务。该方法受 Wu 等人 在论文《AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation》的启发。以下内容将逐步解析博客中的各个部分,包括概念介绍、环境设置、工具定义、代理创建、图的构建以及实例演示。
1. 多智能体网络概述
在单一领域内,单个智能体通常可以利用少量工具高效运作。然而,当涉及到多种工具和跨领域任务时,即使是像 GPT-4 这样强大的模型,其表现可能也不尽如人意。为了解决这一问题,本文提出了一种“分而治之”的方法:为每个任务或领域创建专门的智能体,并将任务路由到相应的“专家”智能体。这种架构即为 多智能体网络。
2. 环境设置
在开始构建多智能体网络之前,需要安装必要的包并设置 API 密钥。以下是具体步骤:
%%capture --no-stderr
%pip install -U langchain langchain_openai langsmith pandas langchain_experimental matplotlib langgraph langchain_coreimport getpass
import osdef _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}")_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")
- 包安装:使用
pip安装所需的 Python 包,包括langchain、langgraph等。 - API 密钥设置:通过
_set_if_undefined函数,检查并设置环境变量中的OPENAI_API_KEY和TAVILY_API_KEY,确保后续调用 API 时具备必要的认证信息。
此外,建议注册 LangSmith 服务,以便快速发现问题并提升 LangGraph 项目的性能。LangSmith 提供了追踪数据,用于调试、测试和监控使用 LangGraph 构建的 LLM 应用。
3. 创建代理(Agents)
多智能体网络的核心在于各个代理(Agents)的协作。以下是创建代理的辅助函数:
from langchain_core.messages import (BaseMessage,HumanMessage,ToolMessage,
)
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langgraph.graph import END, StateGraph, STARTdef create_agent(llm, tools, system_message: str):"""Create an agent."""prompt = ChatPromptTemplate.from_messages([("system","You are a helpful AI assistant, collaborating with other assistants."" Use the provided tools to progress towards answering the question."" If you are unable to fully answer, that's OK, another assistant with different tools "" will help where you left off. Execute what you can to make progress."" If you or any of the other assistants have the final answer or deliverable,"" prefix your response with FINAL ANSWER so the team knows to stop."" You have access to the following tools: {tool_names}.\n{system_message}",),MessagesPlaceholder(variable_name="messages"),])prompt = prompt.partial(system_message=system_message)prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))return prompt | llm.bind_tools(tools)
create_agent函数:用于创建一个代理。该函数接收一个语言模型 (llm)、一组工具 (tools) 和一个系统消息 (system_message)。- 提示模板:通过
ChatPromptTemplate定义了系统消息,指示代理在协作中如何使用工具回答问题。如果当前代理无法完全回答,其他具备不同工具的代理将接手。 - 工具绑定:将指定的工具绑定到语言模型上,使代理能够调用这些工具来完成任务。
4. 定义工具(Tools)
代理需要使用特定的工具来执行任务。以下是工具的定义:
from typing import Annotatedfrom langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
from langchain_experimental.utilities import PythonREPLtavily_tool = TavilySearchResults(max_results=5)# Warning: This executes code locally, which can be unsafe when not sandboxedrepl = PythonREPL()@tool
def python_repl(code: Annotated[str, "The python code to execute to generate your chart."],
):"""Use this to execute python code. If you want to see the output of a value,you should print it out with `print(...)`. This is visible to the user."""try:result = repl.run(code)except BaseException as e:return f"Failed to execute. Error: {repr(e)}"result_str = f"Successfully executed:\n\`\`\`python\n{code}\n\`\`\`\nStdout: {result}"return (result_str + "\n\nIf you have completed all tasks, respond with FINAL ANSWER.")
tavily_tool:一个搜索工具,用于获取相关的搜索结果,最多返回 5 个结果。python_repl:一个 Python 运行时工具,允许代理执行 Python 代码并返回结果。请注意,执行本地代码存在安全风险,尤其是在未进行沙箱化处理时。
5. 创建图(Graph)
在定义了代理和工具之后,接下来需要构建代理之间的交互图。以下是主要步骤:
5.1 定义状态(State)
import operator
from typing import Annotated, Sequence
from typing_extensions import TypedDictfrom langchain_openai import ChatOpenAI# This defines the object that is passed between each node
# in the graph. We will create different nodes for each agent and tool
class AgentState(TypedDict):messages: Annotated[Sequence[BaseMessage], operator.add]sender: str
AgentState类:定义了在图中传递的对象,包含消息列表 (messages) 和发送者 (sender) 的标识。
5.2 定义代理节点
import functoolsfrom langchain_core.messages import AIMessage# Helper function to create a node for a given agent
def agent_node(state, agent, name):result = agent.invoke(state)# We convert the agent output into a format that is suitable to append to the global stateif isinstance(result, ToolMessage):passelse:result = AIMessage(**result.dict(exclude={"type", "name"}), name=name)return {"messages": [result],# Since we have a strict workflow, we can# track the sender so we know who to pass to next."sender": name,}llm = ChatOpenAI(model="gpt-4o")# Research agent and node
research_agent = create_agent(llm,[tavily_tool],system_message="You should provide accurate data for the chart_generator to use.",
)
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")# chart_generator
chart_agent = create_agent(llm,[python_repl],system_message="Any charts you display will be visible by the user.",
)
chart_node = functools.partial(agent_node, agent=chart_agent, name="chart_generator")
agent_node函数:辅助函数,用于创建指定代理的节点。代理根据当前状态 (state) 进行调用,并将结果转换为适合添加到全局状态的格式。- 创建两个代理:
- Researcher:负责提供准确的数据,使用
tavily_tool工具进行搜索。 - chart_generator:负责生成图表,使用
python_repl工具执行 Python 代码。
- Researcher:负责提供准确的数据,使用
5.3 定义工具节点
from langgraph.prebuilt import ToolNodetools = [tavily_tool, python_repl]
tool_node = ToolNode(tools)
ToolNode:一个预定义的节点,用于运行工具。这里将之前定义的tavily_tool和python_repl工具加入到工具节点中。
5.4 定义边逻辑
from typing import Literaldef router(state):# This is the routermessages = state["messages"]last_message = messages[-1]if last_message.tool_calls:# The previous agent is invoking a toolreturn "call_tool"if "FINAL ANSWER" in last_message.content:# Any agent decided the work is donereturn ENDreturn "continue"
router函数:用于根据当前状态决定下一步的节点走向。- 如果上一个消息中包含工具调用 (
tool_calls),则路由到call_tool节点。 - 如果消息内容中包含
"FINAL ANSWER",则结束流程。 - 否则,继续当前的工作流程。
- 如果上一个消息中包含工具调用 (
5.5 构建整个图
workflow = StateGraph(AgentState)workflow.add_node("Researcher", research_node)
workflow.add_node("chart_generator", chart_node)
workflow.add_node("call_tool", tool_node)workflow.add_conditional_edges("Researcher",router,{"continue": "chart_generator", "call_tool": "call_tool", END: END},
)
workflow.add_conditional_edges("chart_generator",router,{"continue": "Researcher", "call_tool": "call_tool", END: END},
)workflow.add_conditional_edges("call_tool",# Each agent node updates the 'sender' field# the tool calling node does not, meaning# this edge will route back to the original agent# who invoked the toollambda x: x["sender"],{"Researcher": "Researcher","chart_generator": "chart_generator",},
)
workflow.add_edge(START, "Researcher")
graph = workflow.compile()
-
StateGraph:定义了整个多智能体网络的状态图。 -
添加节点:将
Researcher、chart_generator和call_tool节点添加到图中。 -
添加边缘:
Researcher节点:- 如果继续工作,则路由到
chart_generator。 - 如果调用工具,则路由到
call_tool。 - 如果结束,则流程结束。
- 如果继续工作,则路由到
chart_generator节点:- 类似地,继续则路由回
Researcher,调用工具则路由到call_tool,结束则结束流程。
- 类似地,继续则路由回
call_tool节点:- 根据
sender字段,路由回调用工具的原始代理节点。
- 根据
-
启动节点:流程从
START节点开始,首先调用Researcher节点。 -
编译图:通过
workflow.compile()将定义好的图编译为可执行的graph对象。
6. 实例演示:绘制英国 GDP 图表
通过构建好的多智能体网络,接下来进行一次实际调用,尝试绘制英国过去五年的 GDP 图表。
6.1 调用图
events = graph.stream({"messages": [HumanMessage(content="Fetch the UK's GDP over the past 5 years,"" then draw a line graph of it."" Once you code it up, finish.")],},# Maximum number of steps to take in the graph{"recursion_limit": 150},
)
for s in events:print(s)print("----")
- 输入消息:用户请求获取过去五年的英国 GDP 数据,并绘制折线图。
- 执行流程:代理根据图的定义,依次调用
Researcher和chart_generator节点,使用相应的工具完成任务。
6.2 执行过程解析
以下是执行过程中的部分输出,展示了代理间的交互和工具调用的情况:
-
Researcher 节点:
- 接收到用户请求,调用
tavily_tool进行搜索,尝试获取英国 GDP 数据。 - 返回部分搜索结果,指出缺少 2022 和 2023 年的数据。
- 接收到用户请求,调用
-
call_tool 节点:
- 调用工具获取更多信息,但仍未找到完整的数据。
-
Researcher 和 chart_generator 节点反复尝试:
- 由于缺少关键年份的数据,代理无法完成任务。
-
最终尝试绘制图表:
chart_generator尝试使用python_repl工具执行 Python 代码绘制图表,但由于数据不完整,图表不准确。
-
结束流程:
- 由于无法获取完整的数据,任务最终未能完成。
6.3 代码修正与完成
在执行过程中,发现代码中存在年份和 GDP 数据长度不匹配的问题。以下是修正后的代码:
import matplotlib.pyplot as plt# UK GDP data obtained from search results for 2018-2021 (in billion USD)
# No data for 2022 and 2023 are available
# Note: 2021 data is used as a placeholder and should be updated when actual figures are available
gdp_data = {'Year': [2018, 2019, 2020, 2021],'GDP (Billion USD)': [2851.41, 2851.41, 2697.81, 3141.51]
}# Plot a line graph
plt.figure(figsize=(10, 5))
plt.plot(gdp_data['Year'], gdp_data['GDP (Billion USD)'], marker='o')# Title and labels
plt.title('UK GDP from 2018 to 2021')
plt.xlabel('Year')
plt.ylabel('GDP (Billion USD)')# Show grid
plt.grid(True)# Display the graph
plt.show()
- 修正点:
- 去除了 2022 和 2023 年的占位符数据,确保年份和 GDP 数据的长度一致。
- 更新标题以反映数据范围(2018-2021 年)。
执行修正后的代码后,成功生成了 2018-2021 年的英国 GDP 折线图。
总结
本文通过 LangGraph 构建了一个多智能体网络,展示了如何通过分工协作来处理复杂任务。具体步骤包括:
- 环境设置:安装必要的包并配置 API 密钥。
- 工具定义:定义搜索工具和 Python 运行时工具。
- 代理创建:创建负责数据获取和图表生成的代理。
- 图构建:定义代理之间的交互逻辑,确保任务能够合理分配和执行。
- 实例演示:通过实际例子展示了多智能体网络的运行过程,尽管在数据获取上遇到了挑战,但通过修正代码,成功生成了部分数据的图表。
这种多智能体网络架构在处理需要跨领域工具协作的复杂任务时,具有显著优势。通过专门的代理和清晰的任务分配,可以提高整体效率和任务完成度。
MessagesPlaceholder
在上述代码中,MessagesPlaceholder(variable_name="messages") 的主要作用是:
- 预留消息插入点:在提示模板中预留一个位置,等待在运行时插入实际的对话消息。
- 支持动态对话:通过
messages变量名,agent可以在不同的对话轮次钟插入不同的消息,实现动态的对话交互。 - 增强提示模板灵活性:使得同一个提示模板可以适应不同的对话内容,无需为乜咯对话单独创建新的模板。
PythonREPL()
PythonREPL() 是 LangChain 库中的一个工具,提供了一个 Python 运行时环境(REPL:Read-Eval-Print Loop),允许Agent动态地执行 Python 代码。通过这个工具,Agent可以在对话或任务处理中,运行自定义的 Python 脚本,完成数据处理、图表生成、计算等各种任务。
PythonREPL()的作用
- 代码执行:允许代理在运行时执行任意的 Python 代码,从而扩展其功能。例如,生成图表、进行数据分析、调用外部 API 等。
- 动态任务处理:根据任务需求,代理可以动态生成并执行代码,实现灵活的任务处理能力。
- 结果反馈:执行代码后,代理可以将结果反馈给用户,提供实时的反馈和交互。
整体代码
# 导入必要的模块
import os
import functools
import operator
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from dotenv import load_dotenv# 从 LangChain 和 LangGraph 导入所需的类和函数
from langchain_core.messages import (BaseMessage,HumanMessage,ToolMessage,AIMessage,
)
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langgraph.graph import END, StateGraph, START
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
from langchain_experimental.utilities import PythonREPL
from langgraph.prebuilt import ToolNode# 导入 ChatTongyi 模型
from langchain_community.chat_models.tongyi import ChatTongyi# 加载 .env 文件
load_dotenv()# 读取环境变量
api_key = os.getenv("DASHSCOPE_API_KEY")if not api_key:raise ValueError("API Key not found in .env file.")# 初始化 LLM(ChatTongyi)
llm = ChatTongyi(model='qwen-plus')def create_agent(llm,tools,system_message:str):prompt = ChatPromptTemplate.from_messages([("system","你是一个有帮助的 AI 助手,正在与其他助手协作。""使用提供的工具来推进回答问题。""如果你无法完全回答,也没关系,另一个具有不同工具的助手会接手你留下的部分。""尽你所能执行任务以取得进展。""如果你或任何其他助手已经有了最终答案或可交付成果,请在你的回复前加上 '最终答案',以便团队知道停止。""你可以使用以下工具:{tool_names}。\n{system_message}",),MessagesPlaceholder(variable_name="messages")])print("system_message"+system_message)print("tools"+", ".join([tool.name for tool in tools]))# partial方法就是填充变量prompt = prompt.partial(system_message=system_message)prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))return prompt | llm.bind_tools(tools)# 定义工具
tavily_tool = TavilySearchResults(max_results=5)
# 执行代码工具
repl = PythonREPL()@tool
def python_repl(code: Annotated[str, "生成图表所需执行的 Python 代码。"],
):"""使用此工具来执行 Python 代码。如果你想查看某个值的输出,你应该使用 `print(...)`。这将对用户可见。"""# 自动添加 plt.savefig 功能if "plt.show()" in code:# 替换 plt.show() 为 plt.savefig 并继续展示图表code = code.replace("plt.show()", 'plt.savefig("uk_gdp_chart.png"); plt.show()')else:# 如果没有 plt.show(),则直接在最后添加保存命令code += '\nplt.savefig("uk_gdp_chart.png")'try:result = repl.run(code)except BaseException as e:return f"执行失败。错误:{repr(e)}"result_str = f"成功执行:\n```python\n{code}\n```\n标准输出:{result}"return (result_str + "\n\n如果你已完成所有任务,请回复 '最终答案'。")# 定义状态
class AgentState(TypedDict):# Sequence是一种泛型集合类型,表示一个个有序的元素序列messages: Annotated[Sequence[BaseMessage],operator.add]sender: str# 定义代理节点
"""
agent_node函数负责:
调用agent并获取其输出。
判断输出消息的类型。
根据消息类型,将其格式化为适当的形式,以便后续流程处理。
更新全局状态,确保消息被正确记录和传递。
"""
def agent_node(state,agent,name):result = agent.invoke(state)# 将agent输出转换为合适附加到全局状态的格式# 如果agent的输出是工具消息,这保持不变(pass)# 否则将agent的输出转换为AIMessage类型,并添加发送者名称if isinstance(result,ToolMessage):passelse:# 将result转换为AIMessage,并添加发送者名称(name)# 在复杂的多agent系统中,明确每条消息的来源和类型,避免混淆。result = AIMessage(**result.dict(exclude={"type","name"}),name=name)# 更新全局状态,推动流程图的下一个步骤return {"messages": [result],"sender":name,}# 创建research agent和node
research_agent = create_agent(llm,[tavily_tool],system_message="你应该为 chart_generator 提供准确的数据。"
)# functools.partial:用于创建一个新的函数,通过固定原函数的某些参数,生成的新函数可以调用时只需要剩余未固定的参数。
# 第一个参数是原函数,之后的参数就是目前固定的参数
research_node = functools.partial(agent_node,agent=research_agent,name="Researcher")# 创建图表生成agent和node
chart_agent = create_agent(llm,[python_repl],system_message="你需要按照要求使用代码工具画出图表。",
)
chart_node = functools.partial(agent_node,agent=chart_agent,name="chart_generator")# 定义工具节点
tools = [tavily_tool,python_repl]tool_node = ToolNode(tools)# 定义路由逻辑
# 根据state决定下一步应该执行的节点或操作
def router(state):message = state["messages"]last_message = message[-1]# 获取消息列表中的最后一条消息,这条消息是最新的,也是路由决策基础if last_message.tool_calls:# 检查最后一条消息是否包含工具调用消息return "call_tool"# 流程转到处理工具调用的节点if "最终答案" in last_message.content: # 检查最后一条消息中是否包含“最终答案”(标志已经完成任务)# 任何代理决定工作已完成return ENDreturn "continue"workflow = StateGraph(AgentState)# 创建工作流程图
workflow = StateGraph(AgentState)workflow.add_node("Researcher", research_node)
workflow.add_node("chart_generator", chart_node)
workflow.add_node("call_tool", tool_node)workflow.add_conditional_edges("Researcher",router,{"continue": "chart_generator", "call_tool": "call_tool", END: END},
)
workflow.add_conditional_edges("chart_generator",router,{"continue": "Researcher", "call_tool": "call_tool", END: END},
)workflow.add_conditional_edges("call_tool",# 每个代理节点更新 'sender' 字段# 工具调用节点不更新,这意味着# 此边缘将路由回调用工具的原始代理lambda x: x["sender"],{"Researcher": "Researcher","chart_generator": "chart_generator",},
)
workflow.add_edge(START, "Researcher")
graph = workflow.compile()# 运行流程
if __name__ == "__main__":events = graph.stream({"messages": [HumanMessage(content="获取过去 5 年日本新生人口数据,然后绘制一条折线图。一旦你编写完代码,结束任务。")],},# 最大递归深度{"recursion_limit": 150},)# 逐个处理流式生成的事件。# events是一个生成器(generator),每个事件都是流程中的一步,可能包含节点的执行结果、错误消息或最终的回复for s in events:print(s)print("----")# 用于分隔事件输出,让每次事件输出更清晰
2. 监督器(Supervisor)架构

当然!我将详细解读您提供的官方入门案例“Multi-agent Supervisor”,帮助您快速理解和掌握其中的概念和代码实现。这将包括对每个代码部分的逐步解释,以及它们在整体系统中的作用。
概述
Multi-agent Supervisor 示例展示了如何使用多个代理(agents)协作完成复杂任务。与之前自动基于初始研究者代理输出路由消息的示例不同,这里我们引入了一个监督者(supervisor)代理,利用大型语言模型(LLM)来协调不同的代理。这种设计模式使系统更加灵活和可扩展。
核心概念
- 代理组(Agent Group):由多个代理组成,每个代理负责特定的任务。
- 监督者代理(Supervisor Agent):负责管理和协调各个代理,根据任务需求分配工作。
- 工具(Tools):代理使用的外部工具,如搜索引擎或代码执行工具。
- 工作流程图(StateGraph):定义代理之间的交互和任务的执行顺序。
步骤详解
让我们按照官方示例的结构,逐步解读每一部分代码及其作用。
1. 安装和设置
首先,需要安装必要的Python包并设置API密钥。
1.1 安装依赖
%%capture --no-stderr
%pip install -U langgraph langchain langchain_openai langchain_experimental langsmith pandas
%%capture --no-stderr:这是Jupyter Notebook中的魔法命令,用于捕获并隐藏输出,避免安装包时的杂乱信息。%pip install -U ...:升级并安装所需的包,包括:langgraph: 用于构建和管理代理工作流程。langchain: 一个用于构建应用的框架,特别是与语言模型交互。langchain_openai: LangChain与OpenAI的集成。langchain_experimental: LangChain的实验性工具和功能。langsmith: 可能用于监控和调试LangChain项目。pandas: 数据处理和分析库。
1.2 设置API密钥
import getpass
import osdef _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}")_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")
getpass.getpass:安全地获取用户输入,不会在控制台显示输入内容。_set_if_undefined函数:检查环境变量是否已设置,如果未设置,则提示用户输入对应的API密钥。OPENAI_API_KEY:用于访问OpenAI的API。TAVILY_API_KEY:用于访问Tavily搜索工具的API。
1.3 设置LangSmith(可选)
Set up LangSmith for LangGraph developmentSign up for LangSmith to quickly spot issues and improve the performance of your LangGraph projects. LangSmith lets you use trace data to debug, test, and monitor your LLM apps built with LangGraph — read more about how to get started here.
- LangSmith:一个用于监控和调试LangGraph项目的平台。通过追踪数据,可以快速发现问题并优化性能。
- 步骤:
- 注册LangSmith账号。
- 配置LangSmith以监控LangGraph项目(具体步骤在“get started here”链接中详细说明)。
2. 创建工具(Create Tools)
在这个示例中,我们需要两个工具:
- Web Research Agent:用于进行网络搜索和数据获取。
- Plotting Agent:用于生成和保存图表。
2.1 导入工具相关模块
from typing import Annotatedfrom langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.tools import PythonREPLTooltavily_tool = TavilySearchResults(max_results=5)# This executes code locally, which can be unsafe
python_repl_tool = PythonREPLTool()
TavilySearchResults:- 用途:用于执行网络搜索,获取指定查询的搜索结果。
- 参数:
max_results=5:限制返回的搜索结果数量为5条。
PythonREPLTool:- 用途:执行任意Python代码。这是一个强大的工具,但需要小心使用,因为它可能执行不安全的代码。
2.2 工具API参考
API Reference: TavilySearchResults | PythonREPLTool
- 提供了工具的详细API文档链接,方便进一步了解其功能和用法。
3. 定义辅助函数(Helper Utilities)
为了简化每个代理节点中的代码,我们定义了一个辅助函数,用于创建图节点并处理代理的响应。
3.1 导入必要模块
from langchain_core.messages import HumanMessage
HumanMessage:表示用户发送的消息,主要用于将代理的响应转换为标准格式。
3.2 定义agent_node函数
def agent_node(state, agent, name):result = agent.invoke(state)return {"messages": [HumanMessage(content=result["messages"][-1].content, name=name)]}
-
参数:
state:当前的全局状态,包含了一系列消息和发送者信息。agent:要调用的代理实例(如Researcher或Coder)。name:发送者的名称,用于标识消息的来源。
-
功能:
- 调用代理:
result = agent.invoke(state):调用代理的invoke方法,传入当前状态,执行任务并获取结果。
- 处理代理响应:
- 创建一个新的
HumanMessage,其内容是代理返回的最新消息内容,并标记发送者名称。
- 创建一个新的
- 返回新状态:
- 返回一个字典,包含更新后的消息列表和发送者信息。
- 调用代理:
-
API参考:
API Reference: HumanMessage
4. 创建代理监督者(Create Agent Supervisor)
监督者代理负责管理和协调多个代理,根据任务需求分配工作。它使用函数调用来选择下一个工作节点或结束处理。
4.1 导入相关模块
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from typing import Literal
ChatPromptTemplate和MessagesPlaceholder:用于构建聊天提示模板。ChatOpenAI:用于与OpenAI的聊天模型交互。BaseModel和Literal:用于定义结构化的响应模型。
4.2 定义代理成员和系统提示
members = ["Researcher", "Coder"]
system_prompt = ("You are a supervisor tasked with managing a conversation between the"" following workers: {members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH."
)
# Our team supervisor is an LLM node. It just picks the next agent to process
# and decides when the work is completed
options = ["FINISH"] + members
members:定义了代理组中的成员,即“Researcher”和“Coder”。system_prompt:定义了监督者代理的系统消息,指示它如何管理和分配任务。- 监督者需要根据用户请求决定下一个应该行动的代理,或决定任务是否完成(
FINISH)。
- 监督者需要根据用户请求决定下一个应该行动的代理,或决定任务是否完成(
options:定义了监督者可以选择的下一个步骤,包括代理成员和FINISH。
4.3 定义路由响应模型
class routeResponse(BaseModel):next: Literal[*options]
routeResponse:使用pydantic定义了一个模型,限制next字段的值只能是options中的一个。- 这样可以确保监督者的响应是有效的,防止无效的路由选择。
4.4 构建聊天提示模板
prompt = ChatPromptTemplate.from_messages([("system", system_prompt),MessagesPlaceholder(variable_name="messages"),("system","Given the conversation above, who should act next?"" Or should we FINISH? Select one of: {options}",),]
).partial(options=str(options), members=", ".join(members))
ChatPromptTemplate.from_messages:创建一个聊天提示模板,包含系统消息和占位符。- 第一个系统消息:描述监督者的任务和工作成员。
MessagesPlaceholder:占位符,用于插入当前对话的消息。- 第二个系统消息:明确询问监督者下一个应该行动的成员或是否结束任务。
partial方法:- 填充模板中的
{options}和{members}变量。 - 生成最终的聊天提示模板。
- 填充模板中的
4.5 初始化监督者代理
llm = ChatOpenAI(model="gpt-4o")def supervisor_agent(state):supervisor_chain = prompt | llm.with_structured_output(routeResponse)return supervisor_chain.invoke(state)
-
ChatOpenAI(model="gpt-4o"):初始化一个OpenAI的聊天模型,使用gpt-4o模型。 -
supervisor_agent函数:- 构建监督者链:
- 将提示模板与LLM模型连接,指定输出格式为
routeResponse。
- 将提示模板与LLM模型连接,指定输出格式为
- 调用代理:
supervisor_chain.invoke(state):传入当前状态,监督者代理根据对话内容选择下一个行动的代理或决定结束任务。
- 构建监督者链:
-
API参考:
API Reference: ChatPromptTemplate | MessagesPlaceholder | ChatOpenAI
5. 构建工作流程图(Construct Graph)
现在,我们将开始构建整个工作流程图,定义状态和工作节点。
5.1 导入相关模块
import functools
import operator
from typing import Sequence
from typing_extensions import TypedDictfrom langchain_core.messages import BaseMessagefrom langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import create_react_agent
functools和operator:用于函数工具和操作符。TypedDict:定义类型安全的字典。BaseMessage:消息的基类。StateGraph:用于构建和管理工作流程图。create_react_agent:LangGraph预构建的函数,用于创建基于React模式的代理。
5.2 定义代理状态结构
class AgentState(TypedDict):# Sequence是一种泛型集合类型,表示一个个有序的元素序列messages: Annotated[Sequence[BaseMessage], operator.add]# The 'next' field indicates where to route to nextnext: str
AgentState:messages:一个消息序列,记录了对话和工具调用的历史。next:一个字符串,指示下一个要路由到的节点或操作。
5.3 创建代理和节点
research_agent = create_react_agent(llm, tools=[tavily_tool])
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")# NOTE: THIS PERFORMS ARBITRARY CODE EXECUTION. PROCEED WITH CAUTION
code_agent = create_react_agent(llm, tools=[python_repl_tool])
code_node = functools.partial(agent_node, agent=code_agent, name="Coder")
create_react_agent:- 用途:创建一个基于React模式的代理,结合LLM模型和指定的工具。
- 参数:
llm:大型语言模型实例(如OpenAI的gpt-4o)。tools:代理可以使用的工具列表。
research_agent:- 工具:使用
TavilySearchResults工具进行网络搜索和数据获取。 - 节点:通过
functools.partial固定agent为research_agent,name为"Researcher",简化调用。
- 工具:使用
code_agent:- 工具:使用
PythonREPLTool工具执行Python代码。 - 节点:通过
functools.partial固定agent为code_agent,name为"Coder"。
- 工具:使用
5.4 构建工作流程图
workflow = StateGraph(AgentState)
workflow.add_node("Researcher", research_node)
workflow.add_node("Coder", code_node)
workflow.add_node("supervisor", supervisor_agent)
StateGraph(AgentState):初始化一个工作流程图实例,定义了状态类型为AgentState。- 添加节点:
"Researcher":对应research_node,负责数据研究和获取任务。"Coder":对应code_node,负责代码执行和图表生成任务。"supervisor":对应supervisor_agent,负责管理和分配任务。
5.5 连接图中的边缘(Edges)
for member in members:# We want our workers to ALWAYS "report back" to the supervisor when doneworkflow.add_edge(member, "supervisor")
# The supervisor populates the "next" field in the graph state
# which routes to a node or finishes
conditional_map = {k: k for k in members}
conditional_map["FINISH"] = END
workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)
# Finally, add entrypoint
workflow.add_edge(START, "supervisor")graph = workflow.compile()
-
为每个成员添加边缘:
for member in members:workflow.add_edge(member, "supervisor")- 目的:确保每个代理完成任务后,总是将控制权回报给监督者代理。
- 流程:例如,
"Researcher"完成任务后,会将控制权传回"supervisor"。
-
定义条件边缘:
conditional_map = {k: k for k in members} conditional_map["FINISH"] = END workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)conditional_map:映射next字段的值到相应的节点或结束流程。- 例如,如果
next为"Coder",则流程转到"Coder"节点。 - 如果
next为"FINISH",则流程结束(END)。
- 例如,如果
workflow.add_conditional_edges:- 来源节点:
"supervisor"。 - 条件函数:
lambda x: x["next"],根据状态中的next字段决定下一个节点。 - 映射:根据
conditional_map,选择下一个节点或结束流程。
- 来源节点:
-
添加入口点:
workflow.add_edge(START, "supervisor")- 作用:定义工作流程的起始点为
"supervisor"节点。
- 作用:定义工作流程的起始点为
-
编译工作流程:
graph = workflow.compile()- 作用:完成工作流程图的定义和编译,准备执行。
6. 启动和运行流程(Invoke the team)
现在,工作流程图已构建完毕,可以通过调用它来执行任务。
6.1 示例调用
for s in graph.stream({"messages": [HumanMessage(content="Code hello world and print it to the terminal")]}
):if "__end__" not in s:print(s)print("----")
-
graph.stream(...):- 参数:
- 初始状态:包含一条
HumanMessage,即用户的任务请求(“Code hello world and print it to the terminal”)。
- 初始状态:包含一条
- 返回值:一个生成器(generator),逐步生成流程中的各个事件。
- 参数:
-
事件处理:
- 循环迭代:
for s in graph.stream(...):逐个处理生成的事件。 - 过滤结束信号:
if "__end__" not in s:只打印未结束的事件。 - 打印事件:
print(s):输出当前事件的内容。print("----"):用分隔符区分事件,便于阅读和调试。
- 循环迭代:
6.2 运行示例输出解析
假设执行上面的调用,输出如下:
{'supervisor': {'next': 'Coder'}}
----
- 解释:
- 监督者代理决定下一个应该行动的代理是
"Coder"。 - 因此,流程转到
"Coder"节点。
- 监督者代理决定下一个应该行动的代理是
``````output
Python REPL can execute arbitrary code. Use with caution.
``````output
{'Coder': {'messages': [HumanMessage(content='The code to print "Hello, World!" in the terminal has been executed successfully. Here is the output:\n\n```python\nHello, World!\n```', additional_kwargs={}, response_metadata={}, name='Coder')]}}
----
- 解释:
Python REPL工具执行了代码,并成功打印了"Hello, World!"。- 生成的
HumanMessage包含执行结果,标记为"Coder"。
{'supervisor': {'next': 'FINISH'}}
----
- 解释:
- 监督者代理决定任务已完成,流程结束(
FINISH)。
- 监督者代理决定任务已完成,流程结束(
6.3 另一个调用示例
for s in graph.stream({"messages": [HumanMessage(content="Write a brief research report on pikas.")]},{"recursion_limit": 100},
):if "__end__" not in s:print(s)print("----")
-
任务请求:编写一份关于“pikas”(一种小型哺乳动物)的简短研究报告。
-
预期流程:
- 监督者代理决定下一个行动的代理(
"Researcher")。 Researcher代理使用TavilySearchResults工具搜索相关信息。Researcher完成任务后,将控制权回报给监督者代理。- 监督者代理决定是否分配给
"Coder"代理或结束任务。 Coder代理可能用于进一步处理或完善报告(具体取决于监督者代理的决策)。- 最终,监督者代理决定任务完成,流程结束。
- 监督者代理决定下一个行动的代理(
-
示例输出:
-
步骤解释:
-
第一次调用:
- 用户请求:
"Code hello world and print it to the terminal"。 - 监督者代理决定由
"Coder"代理执行任务。 Coder代理使用PythonREPLTool执行代码,打印"Hello, World!"。- 任务完成,监督者代理决定结束流程。
- 用户请求:
-
第二次调用:
- 用户请求:
"Write a brief research report on pikas."。 - 监督者代理决定由
"Researcher"代理执行任务。 Researcher代理使用TavilySearchResults工具搜索并编写关于“pikas”的研究报告。- 监督者代理决定由
"Coder"代理进一步处理(例如,完善报告或生成图表)。 Coder代理执行相关任务,最终监督者代理决定结束流程。
- 用户请求:
-
6.4 主要功能总结
-
代理协调:
- 监督者代理负责决定哪个代理下一步执行任务,或是否结束任务。
- 通过监督者代理,可以灵活地管理多个代理的协作,确保任务按需分配。
-
工具使用:
TavilySearchResults:用于进行网络搜索和数据获取。PythonREPLTool:用于执行Python代码,完成如代码生成或数据处理等任务。
-
工作流程图(StateGraph):
- 节点:
"Researcher"、"Coder"和"supervisor"。 - 边缘:
- 每个成员完成任务后,都会将控制权回报给监督者代理。
- 监督者代理根据
next字段决定下一个代理或结束任务。
- 起始点:工作流程从
"supervisor"节点开始,监督者代理根据初始任务决定下一个代理。
- 节点:
-
消息处理:
- 代理的响应被封装为
HumanMessage,并包含发送者名称,确保消息的一致性和可追溯性。 - 通过消息和状态的更新,工作流程图能够动态调整任务的执行顺序和代理的选择。
- 代理的响应被封装为
7. 高级设计模式
官方示例提到,create_react_agent和其他“高级代理”笔记本展示了如何在LangGraph中实现特定的设计模式。根据需求,可以将这些模式与其他基础模式结合使用,以获得最佳性能和灵活性。
-
设计模式:
- React模式:通过
create_react_agent创建的代理,能够响应当前状态并采取相应的行动。 - 监督者模式:通过监督者代理协调和管理多个代理的任务分配。
- React模式:通过
-
最佳实践:
- 模块化:将不同的功能封装在不同的代理和工具中,增强代码的可维护性和可扩展性。
- 状态管理:使用
StateGraph有效管理任务状态和消息传递,确保流程的连贯性和正确性。 - 错误处理:通过监督者代理可以实现更灵活的错误处理和任务重试机制。
结论
通过官方的“Multi-agent Supervisor”示例,您可以学习如何构建一个由多个代理协作完成复杂任务的系统。关键点包括:
- 代理的创建和管理:使用
create_react_agent创建不同功能的代理,并通过functools.partial简化代理节点的定义。 - 监督者代理的设计:利用大型语言模型(LLM)来管理和协调多个代理,决定任务的执行顺序和结束时机。
- 工作流程图的构建:通过
StateGraph定义节点和边缘,确保任务按逻辑顺序执行,并能够动态调整任务分配。 - 工具的集成和使用:结合外部工具(如搜索引擎和代码执行工具)增强代理的功能,实现自动化的数据获取和处理。
学习建议
- 理解代理和工具的角色:明确每个代理和工具在系统中的职责,确保它们协同工作完成整体任务。
- 掌握工作流程图的构建:熟悉
StateGraph的使用,包括节点的添加、边缘的定义和条件的设置。 - 探索高级设计模式:了解并尝试实现不同的设计模式,如监督者模式、React模式等,以增强系统的灵活性和可扩展性。
- 实践和调试:通过实际运行和调试示例代码,观察代理之间的交互和工作流程的执行,深入理解其内部机制。
通过系统地学习和实践,您将能够快速掌握如何使用LangGraph和LangChain构建复杂的多代理系统,实现高效的任务自动化和协作。
汇总
当然!下面是一个完整的Python脚本,汇总了您之前提供的所有代码片段,并添加了详细的注释,以帮助您理解和执行整个多代理监督系统。此脚本使用LangGraph和LangChain库来创建和管理多个代理(Researcher和Coder),并通过一个监督者代理(Supervisor)来协调它们的工作。
脚本结构概述
- 依赖安装说明
- 导入必要的模块
- 设置API密钥
- 定义工具
- 定义辅助函数
- 创建代理和节点
- 定义监督者代理
- 构建工作流程图
- 运行工作流程
请按照以下步骤操作:
-
安装必要的Python包:
在运行脚本之前,请确保安装了所需的Python包。您可以在终端或命令提示符中运行以下命令:pip install -U langgraph langchain langchain_openai langchain_experimental langsmith pandas pydantic -
准备API密钥:
OPENAI_API_KEY:用于访问OpenAI的API。TAVILY_API_KEY:用于访问Tavily搜索工具的API。
您可以将这些密钥存储在环境变量中,或者在运行脚本时按提示输入。
完整的Python脚本
# multi_agent_supervisor.py"""
Multi-agent Supervisor Example using LangGraph and LangChain此脚本展示了如何使用LangGraph和LangChain构建一个多代理系统,
包括一个监督者代理(Supervisor)来协调Researcher和Coder代理的工作。运行前请确保安装所需的包:
pip install -U langgraph langchain langchain_openai langchain_experimental langsmith pandas pydantic
"""import os
import functools
import operator
import getpass
from typing import Annotated, Sequence, Literal
from typing_extensions import TypedDict
from dotenv import load_dotenvfrom langchain_core.messages import BaseMessage, HumanMessage, ToolMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langgraph.graph import END, StateGraph, START
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.tools import PythonREPLTool
from langgraph.prebuilt import ToolNode, create_react_agentfrom langchain_community.chat_models.tongyi import ChatTongyi
from langchain_openai import ChatOpenAI
from pydantic import BaseModel# 1. 加载环境变量
load_dotenv()def _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}: ")# 设置API密钥
_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")# 2. 初始化LLM模型(ChatTongyi)
llm = ChatTongyi(model='qwen-plus')# 3. 创建工具
tavily_tool = TavilySearchResults(max_results=5)
python_repl_tool = PythonREPLTool()# 4. 定义辅助函数 agent_node
def agent_node(state, agent, name):result = agent.invoke(state)# 如果agent的输出是ToolMessage,保持不变if isinstance(result, ToolMessage):passelse:# 将非ToolMessage类型的输出转换为AIMessage,并添加发送者名称result = AIMessage(**result.dict(exclude={"type", "name"}), name=name)return {"messages": [result],"sender": name,}# 5. 创建代理函数
def create_agent(llm, tools, system_message: str):prompt = ChatPromptTemplate.from_messages([("system","你是一个有帮助的 AI 助手,正在与其他助手协作。""使用提供的工具来推进回答问题。""如果你无法完全回答,也没关系,另一个具有不同工具的助手会接手你留下的部分。""尽你所能执行任务以取得进展。""如果你或任何其他助手已经有了最终答案或可交付成果,请在你的回复前加上 '最终答案',以便团队知道停止。""你可以使用以下工具:{tool_names}。\n{system_message}",),MessagesPlaceholder(variable_name="messages")])print("system_message: " + system_message)print("tools: " + ", ".join([tool.name for tool in tools]))# 填充变量prompt = prompt.partial(system_message=system_message)prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))# 绑定工具return prompt | llm.bind_tools(tools)# 6. 定义代理状态
class AgentState(TypedDict):messages: Annotated[Sequence[BaseMessage], operator.add]sender: strnext: str # 用于监督者决定下一个节点# 7. 创建代理和节点
# 创建Researcher代理
research_agent = create_react_agent(llm, tools=[tavily_tool])
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")# 创建Coder代理
code_agent = create_react_agent(llm, tools=[python_repl_tool])
code_node = functools.partial(agent_node, agent=code_agent, name="Coder")# 8. 定义监督者代理
class RouteResponse(BaseModel):next: Literal['FINISH', 'Researcher', 'Coder']members = ["Researcher", "Coder"]
system_prompt = ("You are a supervisor tasked with managing a conversation between the"" following workers: {members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH."
)options = ["FINISH"] + membersprompt = ChatPromptTemplate.from_messages([("system", system_prompt),MessagesPlaceholder(variable_name="messages"),("system","Given the conversation above, who should act next?"" Or should we FINISH? Select one of: {options}",),]
).partial(options=str(options), members=", ".join(members))# 初始化监督者LLM模型
supervisor_llm = ChatOpenAI(model="gpt-4")def supervisor_agent(state):supervisor_chain = prompt | supervisor_llm.with_structured_output(RouteResponse)return supervisor_chain.invoke(state)# 9. 构建工作流程图
workflow = StateGraph(AgentState)# 添加节点
workflow.add_node("Researcher", research_node)
workflow.add_node("Coder", code_node)
workflow.add_node("supervisor", supervisor_agent)# 为每个成员添加边缘,确保任务完成后回报给监督者
for member in members:workflow.add_edge(member, "supervisor")# 定义条件映射,监督者根据"next"字段决定下一步
conditional_map = {k: k for k in members}
conditional_map["FINISH"] = END
workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)# 添加入口点
workflow.add_edge(START, "supervisor")# 编译工作流程图
graph = workflow.compile()# 10. 运行工作流程
if __name__ == "__main__":# 示例1:执行编码任务print("=== 示例1:执行编码任务 ===")for s in graph.stream({"messages": [HumanMessage(content="Code hello world and print it to the terminal")],"next": "supervisor" # 初始路由到监督者},{"recursion_limit": 150},):if "__end__" not in s:print(s)print("----")# 示例2:执行研究任务print("\n=== 示例2:执行研究任务 ===")for s in graph.stream({"messages": [HumanMessage(content="Write a brief research report on pikas.")],"next": "supervisor"},{"recursion_limit": 150},):if "__end__" not in s:print(s)print("----")
脚本详细解释
1. 导入必要的模块
脚本开始时,导入了所有需要的Python模块和库,包括langgraph、langchain、pydantic等。这些模块用于创建和管理代理、工具以及工作流程图。
2. 设置API密钥
使用dotenv加载环境变量,并定义了一个辅助函数_set_if_undefined,用于检查和设置必要的API密钥。如果环境变量中未定义OPENAI_API_KEY或TAVILY_API_KEY,脚本会提示用户输入。
3. 初始化LLM模型
使用ChatTongyi初始化一个大型语言模型(LLM),这里使用的是qwen-plus模型。这个模型将用于处理代理的自然语言理解和生成任务。
4. 创建工具
定义了两个工具:
tavily_tool:用于执行网络搜索和数据获取。python_repl_tool:用于执行Python代码。
5. 定义辅助函数agent_node
这个函数负责调用指定的代理,并根据代理的输出类型(ToolMessage或AIMessage)处理消息,最后返回更新后的状态。通过functools.partial,可以简化代理节点的定义。
6. 创建代理函数
定义了一个函数create_agent,用于创建代理,将LLM模型与指定的工具绑定,并配置系统消息模板。系统消息定义了代理的行为和可用工具。
7. 定义代理状态
使用TypedDict定义了全局状态结构AgentState,包括消息序列和发送者信息,以及next字段用于监督者决定下一个节点。
8. 创建代理和节点
创建了两个代理:
research_agent:使用TavilySearchResults工具进行数据研究。code_agent:使用PythonREPLTool工具执行代码生成任务。
通过functools.partial,分别创建了对应的节点research_node和code_node,简化了节点调用时的参数传递。
9. 定义监督者代理
监督者代理负责管理和协调Researcher和Coder代理的工作。使用一个大型语言模型(如gpt-4)来决定下一个应该执行任务的代理或是否结束任务。
- 定义路由响应模型:
RouteResponse类限制了监督者可以选择的下一个步骤(Researcher、Coder或FINISH)。 - 构建聊天提示模板:定义了监督者的系统消息,指示其如何管理和分配任务。
- 初始化监督者代理:通过
supervisor_agent函数,使用监督者的提示模板和LLM模型来决定下一个行动的代理。
10. 构建工作流程图
使用StateGraph构建了一个工作流程图,定义了各个节点及其之间的连接和条件转移。
- 添加节点:包括
Researcher、Coder和supervisor节点。 - 添加边缘:确保每个代理完成任务后将控制权回报给监督者代理。
- 定义条件映射:监督者根据
next字段决定下一个节点或结束流程。 - 添加入口点:工作流程从
supervisor节点开始。 - 编译工作流程图:通过
workflow.compile()完成工作流程图的定义和编译。
11. 运行工作流程
在主程序入口,定义了两个示例任务:
-
示例1:执行编码任务
- 用户请求:
"Code hello world and print it to the terminal" - 监督者代理决定由
Coder代理执行任务。 Coder代理使用PythonREPLTool执行代码,打印"Hello, World!"。- 任务完成,监督者代理决定结束流程。
- 用户请求:
-
示例2:执行研究任务
- 用户请求:
"Write a brief research report on pikas." - 监督者代理决定由
Researcher代理执行任务。 Researcher代理使用TavilySearchResults工具搜索并编写关于“pikas”的研究报告。- 监督者代理决定由
Coder代理进一步处理(例如,完善报告或生成图表)。 Coder代理执行相关任务,最终监督者代理决定结束流程。
- 用户请求:
如何运行脚本
-
确保已安装依赖:
确保已按照上述安装说明安装了所有必要的Python包。 -
设置API密钥:
- 将
OPENAI_API_KEY和TAVILY_API_KEY存储在环境变量中,或者在运行脚本时按提示输入。
- 将
-
运行脚本:
在终端或命令提示符中运行以下命令:python multi_agent_supervisor.py -
观察输出:
脚本将依次执行示例任务,并在控制台中打印每一步的执行结果。输出将展示监督者代理如何决定下一个执行的代理,以及各个代理的响应。
注意事项
-
安全性:
PythonREPLTool可以执行任意Python代码,存在安全风险。在实际应用中,请确保代码执行环境的安全性和隔离性。
-
API使用:
- 确保您的API密钥有效,并且有足够的配额来执行请求。
-
扩展性:
- 您可以根据需要添加更多的代理和工具,通过调整
members列表和相应的工具定义,扩展系统的功能。
- 您可以根据需要添加更多的代理和工具,通过调整
总结
这个脚本展示了如何使用LangGraph和LangChain构建一个多代理系统,通过监督者代理来协调不同任务的执行。通过实际运行和观察输出,您可以深入理解代理之间的协作机制和工作流程的执行逻辑。如果您有任何问题或需要进一步的帮助,请随时提问!
3. 监督器(工具调用)架构
4. 分层(Hierarchical)架构
层级代理团队概述
在之前的例子(代理主管)中,我们介绍了单一的主管节点,用于在不同的工作节点之间路由任务。但如果一个工作节点的任务变得过于复杂,或者工作节点的数量过多,系统可能需要更高效的工作分配方式。这时,层级化的工作分配可能更为有效。
为什么需要层级化?
- 复杂任务处理:单个工作节点可能无法高效处理复杂任务,通过层级化可以将复杂任务分解,分配给多个子节点处理。
- 扩展性:当工作节点数量增加时,单一主管节点可能成为瓶颈。层级化可以分散负载,提高系统的扩展性和稳定性。
实现方法
通过组合不同的子图,并创建一个顶层主管节点以及中层主管节点,可以实现工作任务的层级化分配。
构建一个简单的研究助手
我们将通过一个简单的研究助手示例来展示如何构建层级代理团队。整个图的结构如下:

这个示例灵感来源于Wu等人的论文《AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation》。在这个示例中,我们将完成以下步骤:
- 定义代理的工具:包括访问网页和写文件的工具。
- 定义一些辅助工具:帮助创建图和代理。
- 创建和定义每个团队:包括网页研究团队和文档写作团队。
- 组合所有组件。
- 设置环境。
设置环境
首先,我们需要安装所需的包,并设置API密钥。
%%capture --no-stderr
%pip install -U langgraph langchain langchain_openai langchain_experimentalimport getpass
import osdef _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}")_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")
此外,还需要设置LangSmith用于LangGraph开发,这有助于快速发现问题并改进LangGraph项目的性能。
创建工具
每个团队将由一个或多个代理组成,每个代理拥有一个或多个工具。下面,我们将定义不同团队使用的所有工具。
研究团队工具
研究团队可以使用搜索引擎和URL抓取工具在网页上查找信息。您可以根据需要添加额外的功能以提升团队性能。
from typing import Annotated, List
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tooltavily_tool = TavilySearchResults(max_results=5)@tool
def scrape_webpages(urls: List[str]) -> str:"""使用requests和bs4抓取提供的网页以获取详细信息。"""loader = WebBaseLoader(urls)docs = loader.load()return "\n\n".join([f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'for doc in docs])
工具参考:WebBaseLoader、TavilySearchResults、tool
文档写作团队工具
接下来,我们将为文档写作团队提供一些工具。这些工具允许代理访问文件系统,但需要注意安全性问题。
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import Dict, Optional
from langchain_experimental.utilities import PythonREPL
from typing_extensions import TypedDict_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(_TEMP_DIRECTORY.name)@tool
def create_outline(points: Annotated[List[str], "主要点或章节列表。"],file_name: Annotated[str, "保存大纲的文件路径。"],
) -> Annotated[str, "保存的大纲文件路径。"]:"""创建并保存大纲。"""with (WORKING_DIRECTORY / file_name).open("w") as file:for i, point in enumerate(points):file.write(f"{i + 1}. {point}\n")return f"大纲已保存到 {file_name}"@tool
def read_document(file_name: Annotated[str, "文档文件路径。"],start: Annotated[Optional[int], "起始行。默认值为0"] = None,end: Annotated[Optional[int], "结束行。默认值为None"] = None,
) -> str:"""读取指定的文档。"""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()if start is not None:start = 0return "\n".join(lines[start:end])@tool
def write_document(content: Annotated[str, "要写入文档的文本内容。"],file_name: Annotated[str, "保存文档的文件路径。"],
) -> Annotated[str, "保存的文档文件路径。"]:"""创建并保存文本文档。"""with (WORKING_DIRECTORY / file_name).open("w") as file:file.write(content)return f"文档已保存到 {file_name}"@tool
def edit_document(file_name: Annotated[str, "要编辑的文档路径。"],inserts: Annotated[Dict[int, str],"字典,键为行号(1索引),值为要插入该行的文本。",],
) -> Annotated[str, "编辑后的文档文件路径。"]:"""通过在特定行号插入文本来编辑文档。"""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()sorted_inserts = sorted(inserts.items())for line_number, text in sorted_inserts:if 1 <= line_number <= len(lines) + 1:lines.insert(line_number - 1, text + "\n")else:return f"错误:行号 {line_number} 超出范围。"with (WORKING_DIRECTORY / file_name).open("w") as file:file.writelines(lines)return f"文档已编辑并保存到 {file_name}"# 警告:此功能在本地执行代码,未进行沙箱处理时可能不安全repl = PythonREPL()@tool
def python_repl(code: Annotated[str, "要执行的Python代码,用于生成图表。"],
):"""使用此工具执行Python代码。如果想查看变量的输出,应该使用`print(...)`。输出对用户可见。"""try:result = repl.run(code)except BaseException as e:return f"执行失败。错误:{repr(e)}"return f"执行成功:\n```python\n{code}\n```\n标准输出:{result}"
工具参考:PythonREPL
辅助工具
我们将创建一些辅助函数,以便更简洁地创建工作代理和主管,从而简化最终的图组合代码。
from typing import List, Optional
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langgraph.graph import END, StateGraph, START
from langchain_core.messages import HumanMessage, trim_messagesllm = ChatOpenAI(model="gpt-4o-mini")trimmer = trim_messages(max_tokens=100000,strategy="last",token_counter=llm,include_system=True,
)def agent_node(state, agent, name):result = agent.invoke(state)return {"messages": [HumanMessage(content=result["messages"][-1].content, name=name)]}def create_team_supervisor(llm: ChatOpenAI, system_prompt, members) -> str:"""基于LLM的路由器。"""options = ["FINISH"] + membersfunction_def = {"name": "route","description": "选择下一个角色。","parameters": {"title": "routeSchema","type": "object","properties": {"next": {"title": "Next","anyOf": [{"enum": options},],},},"required": ["next"],},}prompt = ChatPromptTemplate.from_messages([("system", system_prompt),MessagesPlaceholder(variable_name="messages"),("system","根据以上对话,谁应该下一个行动?或者我们应该 FINISH?请选择以下之一:{options}",),]).partial(options=str(options), team_members=", ".join(members))return (prompt| trimmer| llm.bind_functions(functions=[function_def], function_call="route")| JsonOutputFunctionsParser())
工具参考:JsonOutputFunctionsParser、ChatPromptTemplate、MessagesPlaceholder、ChatOpenAI、HumanMessage、trim_messages、END、StateGraph、START
定义代理团队
现在,我们可以开始定义层级代理团队。以下是“选择您的玩家!”的过程。
研究团队
研究团队将拥有一个搜索代理和一个网页抓取代理作为两个工作节点。我们将创建这些代理以及团队主管。
import functools
import operator
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai.chat_models import ChatOpenAI
from langgraph.prebuilt import create_react_agent# 研究团队图状态
class ResearchTeamState(TypedDict):# 每个团队成员完成后添加一条消息messages: Annotated[List[BaseMessage], operator.add]# 跟踪团队成员,了解彼此的技能team_members: List[str]# 用于路由工作。主管调用一个函数,每次做出决策时更新这个next: strllm = ChatOpenAI(model="gpt-4o")search_agent = create_react_agent(llm, tools=[tavily_tool])
search_node = functools.partial(agent_node, agent=search_agent, name="Search")research_agent = create_react_agent(llm, tools=[scrape_webpages])
research_node = functools.partial(agent_node, agent=research_agent, name="WebScraper")supervisor_agent = create_team_supervisor(llm,"You are a supervisor tasked with managing a conversation between the"" following workers: Search, WebScraper. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.",["Search", "WebScraper"],
)
工具参考:BaseMessage、HumanMessage、ChatOpenAI、create_react_agent
定义研究团队图
现在我们创建图,并添加节点和边,定义控制流程。
research_graph = StateGraph(ResearchTeamState)
research_graph.add_node("Search", search_node)
research_graph.add_node("WebScraper", research_node)
research_graph.add_node("supervisor", supervisor_agent)# 定义控制流程
research_graph.add_edge("Search", "supervisor")
research_graph.add_edge("WebScraper", "supervisor")
research_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"Search": "Search", "WebScraper": "WebScraper", "FINISH": END},
)research_graph.add_edge(START, "supervisor")
chain = research_graph.compile()
运行研究团队
我们可以直接给这个团队分配任务并运行。
def enter_chain(message: str):results = {"messages": [HumanMessage(content=message)],}return resultsresearch_chain = enter_chain | chainfrom IPython.display import Image, displaydisplay(Image(chain.get_graph(xray=True).draw_mermaid_png()))for s in research_chain.stream("when is Taylor Swift's next tour?", {"recursion_limit": 100}
):if "__end__" not in s:print(s)print("---")
输出示例:
{'supervisor': {'next': 'Search'}}
---
{'Search': {'messages': [HumanMessage(content='Taylor Swift\'s next tour is called "The Eras Tour," ...', name='Search')]}}
---
{'supervisor': {'next': 'FINISH'}}
---
文档写作团队
接下来,我们将使用类似的方法创建文档写作团队。这次,我们将为每个代理提供不同的文件写作工具。
import operator
from pathlib import Path# 文档写作团队图状态
class DocWritingState(TypedDict):# 跟踪团队的内部对话messages: Annotated[List[BaseMessage], operator.add]# 为每个工作成员提供关于其他成员技能的上下文team_members: str# 主管告诉LangGraph下一个要工作的代理next: str# 跟踪共享目录状态current_files: str# 代理运行前的前奏
def prelude(state):written_files = []if not WORKING_DIRECTORY.exists():WORKING_DIRECTORY.mkdir()try:written_files = [f.relative_to(WORKING_DIRECTORY) for f in WORKING_DIRECTORY.rglob("*")]except Exception:passif not written_files:return {**state, "current_files": "No files written."}return {**state,"current_files": "\nBelow are files your team has written to the directory:\n"+ "\n".join([f" - {f}" for f in written_files]),}llm = ChatOpenAI(model="gpt-4o")doc_writer_agent = create_react_agent(llm, tools=[write_document, edit_document, read_document]
)
# 在每次调用前注入当前目录工作状态
context_aware_doc_writer_agent = prelude | doc_writer_agent
doc_writing_node = functools.partial(agent_node, agent=context_aware_doc_writer_agent, name="DocWriter"
)note_taking_agent = create_react_agent(llm, tools=[create_outline, read_document])
context_aware_note_taking_agent = prelude | note_taking_agent
note_taking_node = functools.partial(agent_node, agent=context_aware_note_taking_agent, name="NoteTaker"
)chart_generating_agent = create_react_agent(llm, tools=[read_document, python_repl])
context_aware_chart_generating_agent = prelude | chart_generating_agent
chart_generating_node = functools.partial(agent_node, agent=context_aware_chart_generating_agent, name="ChartGenerator"
)doc_writing_supervisor = create_team_supervisor(llm,"You are a supervisor tasked with managing a conversation between the"" following workers: {team_members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.",["DocWriter", "NoteTaker", "ChartGenerator"],
)
定义文档写作团队图
authoring_graph = StateGraph(DocWritingState)
authoring_graph.add_node("DocWriter", doc_writing_node)
authoring_graph.add_node("NoteTaker", note_taking_node)
authoring_graph.add_node("ChartGenerator", chart_generating_node)
authoring_graph.add_node("supervisor", doc_writing_supervisor)# 添加始终发生的边
authoring_graph.add_edge("DocWriter", "supervisor")
authoring_graph.add_edge("NoteTaker", "supervisor")
authoring_graph.add_edge("ChartGenerator", "supervisor")# 添加路由条件边
authoring_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"DocWriter": "DocWriter","NoteTaker": "NoteTaker","ChartGenerator": "ChartGenerator","FINISH": END,},
)authoring_graph.add_edge(START, "supervisor")
chain = authoring_graph.compile()
运行文档写作团队
def enter_chain(message: str, members: List[str]):results = {"messages": [HumanMessage(content=message)],"team_members": ", ".join(members),}return resultsauthoring_chain = (functools.partial(enter_chain, members=authoring_graph.nodes)| authoring_graph.compile()
)from IPython.display import Image, displaydisplay(Image(chain.get_graph().draw_mermaid_png()))for s in authoring_chain.stream("Write an outline for poem and then write the poem to disk.",{"recursion_limit": 100},
):if "__end__" not in s:print(s)print("---")
输出示例:
{'supervisor': {'next': 'NoteTaker'}}
---
{'NoteTaker': {'messages': [HumanMessage(content='The poem has been written and saved to "poem.txt".', name='NoteTaker')]}}
---
{'supervisor': {'next': 'FINISH'}}
---
添加层级
在这个设计中,我们实施了自上而下的规划策略。已经创建了两个子图,但现在需要决定如何在它们之间路由任务。我们将创建第三个图来协调前两个图,并添加一些连接器,以定义顶层状态如何在不同图之间共享。
from langchain_core.messages import BaseMessage
from langchain_openai.chat_models import ChatOpenAIllm = ChatOpenAI(model="gpt-4o")supervisor_node = create_team_supervisor(llm,"You are a supervisor tasked with managing a conversation between the"" following teams: {team_members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.",["ResearchTeam", "PaperWritingTeam"],
)# 顶层图状态
class State(TypedDict):messages: Annotated[List[BaseMessage], operator.add]next: strdef get_last_message(state: State) -> str:return state["messages"][-1].contentdef join_graph(response: dict):return {"messages": [response["messages"][-1]]}# 定义顶层图
super_graph = StateGraph(State)
# 首先添加节点,执行工作
super_graph.add_node("ResearchTeam", get_last_message | research_chain | join_graph)
super_graph.add_node("PaperWritingTeam", get_last_message | authoring_chain | join_graph
)
super_graph.add_node("supervisor", supervisor_node)# 定义图连接,控制逻辑如何在程序中传播
super_graph.add_edge("ResearchTeam", "supervisor")
super_graph.add_edge("PaperWritingTeam", "supervisor")
super_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"PaperWritingTeam": "PaperWritingTeam","ResearchTeam": "ResearchTeam","FINISH": END,},
)
super_graph.add_edge(START, "supervisor")
super_graph = super_graph.compile()from IPython.display import Image, displaydisplay(Image(super_graph.get_graph().draw_mermaid_png()))
运行顶层图
for s in super_graph.stream({"messages": [HumanMessage(content="Write a brief research report on the North American sturgeon. Include a chart.")],},{"recursion_limit": 150},
):if "__end__" not in s:print(s)print("---")
输出示例(部分):
{'supervisor': {'next': 'ResearchTeam'}}
---
{'ResearchTeam': {'messages': [HumanMessage(content="...关于北美鲟鱼的简要研究报告...", name='WebScraper')]}}
---
{'supervisor': {'next': 'PaperWritingTeam'}}
---
{'PaperWritingTeam': {'messages': [HumanMessage(content="...文档写作团队已完成...", name='NoteTaker')]}}
---
{'supervisor': {'next': 'ResearchTeam'}}
---
...
总结
通过以上步骤,我们构建了一个层级化的代理团队系统,包含研究团队和文档写作团队,并通过顶层主管协调它们之间的任务分配。这个系统展示了如何利用LangGraph创建复杂的多层级代理结构,以高效处理复杂或大量的任务。
关键点回顾
- 层级化分配:通过创建子图和中层主管,实现任务的层级化分配,提高系统的扩展性和效率。
- 工具定义:为不同团队定义专用工具,满足各自的任务需求。
- 辅助函数:创建辅助函数简化代理和主管的创建,便于组合图。
- 图定义与编译:定义各团队的状态图,添加节点和边,编译生成可执行的链。
- 层级协调:通过顶层主管协调各子团队的工作,确保任务按需分配和完成。
图的层级
在的LangGraph入门文档中,我们已经构建了一个层级化的代理团队系统,包括研究团队(ResearchTeam)和文档写作团队(PaperWritingTeam),并通过顶层主管(supervisor)协调它们之间的任务分配。为了更好地理解这个系统,以下将详细讲解图之间的协调机制,包括图的层级结构、不同图之间的共享与交互等关键内容。
1. 图的层级结构
顶层图与子图
在LangGraph中,层级化的图结构允许我们将复杂的任务分解为多个子任务,并通过不同的代理团队来处理这些子任务。这种层级结构有助于提高系统的可维护性、扩展性和效率。
顶层图(Super Graph):
- 职责:管理和协调各个子图(代理团队)的任务分配和执行。
- 节点:通常包括各个子图的入口节点以及一个主管节点,用于决定接下来的任务应该分配给哪个子图。
子图(Sub Graphs):
- 职责:处理具体的子任务,如研究、文档写作等。
- 节点:包括具体的代理节点(如Search、WebScraper、DocWriter、NoteTaker等)和一个主管节点,用于在子图内部进行任务分配。
示例层级结构
在您的示例中,层级结构如下:
顶层图(Super Graph)
├── ResearchTeam 子图
│ ├── Search 代理
│ ├── WebScraper 代理
│ └── ResearchSupervisor 主管
└── PaperWritingTeam 子图├── DocWriter 代理├── NoteTaker 代理├── ChartGenerator 代理└── WritingSupervisor 主管
2. 不同图之间的共享与交互
任务分配与路由
顶层主管节点负责根据用户的请求或当前的任务状态,将任务路由到合适的子图。具体来说,主管节点会根据预定义的逻辑(通常是通过LLM模型生成的决策),决定下一个执行任务的子图或代理。
代码示例:
# 定义顶层图的主管节点
supervisor_node = create_team_supervisor(llm,"你是一个主管,负责管理以下团队之间的对话:ResearchTeam, PaperWritingTeam。根据以下用户请求,回应下一个行动的团队。每个团队将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["ResearchTeam", "PaperWritingTeam"],
)# 定义顶层图
super_graph = StateGraph(State)
# 添加节点
super_graph.add_node("ResearchTeam", get_last_message | research_chain | join_graph)
super_graph.add_node("PaperWritingTeam", get_last_message | authoring_chain | join_graph
)
super_graph.add_node("supervisor", supervisor_node)# 添加边
super_graph.add_edge("ResearchTeam", "supervisor")
super_graph.add_edge("PaperWritingTeam", "supervisor")
super_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"PaperWritingTeam": "PaperWritingTeam","ResearchTeam": "ResearchTeam","FINISH": END,},
)super_graph.add_edge(START, "supervisor")
super_graph = super_graph.compile()
在这个示例中,顶层主管根据任务决定将任务分配给ResearchTeam或PaperWritingTeam,或者结束任务(FINISH)。
数据共享
在层级化的系统中,数据共享通常通过以下方式实现:
-
状态传递:顶层图和子图之间可以通过状态(State)传递必要的数据。例如,研究团队完成研究后,可以将研究结果传递给文档写作团队,以便后者编写报告。
-
共享存储:使用共享的文件系统或数据库,子图可以将数据存储在共享位置,其他子图可以访问这些数据。例如,研究团队将研究结果保存到一个文件中,文档写作团队读取该文件以编写报告。
代码示例:
在您的示例中,ResearchTeam的输出可以作为PaperWritingTeam的输入。例如:
# ResearchTeam 子图完成任务后,将结果传递给顶层图
research_result = {"messages": [HumanMessage(content="...研究结果内容...", name='WebScraper')]
}# 这些结果将被传递给顶层图,并可能被分配给 PaperWritingTeam
然后,顶层主管根据需要将这些结果传递给PaperWritingTeam进行进一步处理。
子图之间的独立性与协作
每个子图都是相对独立的,负责处理特定类型的任务。然而,通过顶层主管的协调,它们可以协同工作,完成更复杂的任务。例如,研究团队完成研究后,文档写作团队根据研究结果编写报告。
关键点:
- 独立性:子图可以独立设计和实现,便于模块化和重用。
- 协作:通过顶层主管协调,子图之间可以协同工作,完成复杂任务。
3. 详细解读代码中的协调机制
为了更好地理解图之间的协调,以下将逐步解析您提供的代码,并说明各部分如何协同工作。
3.1 顶层图的定义与协调
顶层主管的创建:
supervisor_node = create_team_supervisor(llm,"你是一个主管,负责管理以下团队之间的对话:ResearchTeam, PaperWritingTeam。根据以下用户请求,回应下一个行动的团队。每个团队将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["ResearchTeam", "PaperWritingTeam"],
)
- 功能:
create_team_supervisor函数创建了一个主管代理,使用LLM来决定下一个任务应该分配给哪个团队。 - 参数:
llm: 使用的语言模型。system_prompt: 系统提示,定义了主管的职责和行为。members: 管理的团队列表。
顶层图的构建:
super_graph = StateGraph(State)
super_graph.add_node("ResearchTeam", get_last_message | research_chain | join_graph)
super_graph.add_node("PaperWritingTeam", get_last_message | authoring_chain | join_graph
)
super_graph.add_node("supervisor", supervisor_node)# 添加边
super_graph.add_edge("ResearchTeam", "supervisor")
super_graph.add_edge("PaperWritingTeam", "supervisor")
super_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"PaperWritingTeam": "PaperWritingTeam","ResearchTeam": "ResearchTeam","FINISH": END,},
)super_graph.add_edge(START, "supervisor")
super_graph = super_graph.compile()
- 节点:
ResearchTeam和PaperWritingTeam:分别对应研究团队和文档写作团队的子图。supervisor:顶层主管节点。
- 边:
- 将子图节点连接到主管节点,表示子图完成任务后会返回给主管。
- 添加条件边,根据主管的决策(
next字段),决定下一个执行的子图或结束任务。
3.2 子图的定义与执行
研究团队子图:
research_graph = StateGraph(ResearchTeamState)
research_graph.add_node("Search", search_node)
research_graph.add_node("WebScraper", research_node)
research_graph.add_node("supervisor", supervisor_agent)# 定义控制流程
research_graph.add_edge("Search", "supervisor")
research_graph.add_edge("WebScraper", "supervisor")
research_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"Search": "Search", "WebScraper": "WebScraper", "FINISH": END},
)research_graph.add_edge(START, "supervisor")
research_chain = research_graph.compile()
- 节点:
Search和WebScraper:具体的代理节点,执行搜索和网页抓取任务。supervisor:研究团队内部的主管节点,负责在团队内部分配任务。
- 边:
- 子图内部的主管节点负责在
Search和WebScraper之间分配任务。 - 顶层主管将任务分配给研究团队,然后研究团队内部继续分配。
- 子图内部的主管节点负责在
文档写作团队子图:
authoring_graph = StateGraph(DocWritingState)
authoring_graph.add_node("DocWriter", doc_writing_node)
authoring_graph.add_node("NoteTaker", note_taking_node)
authoring_graph.add_node("ChartGenerator", chart_generating_node)
authoring_graph.add_node("supervisor", doc_writing_supervisor)# 添加边
authoring_graph.add_edge("DocWriter", "supervisor")
authoring_graph.add_edge("NoteTaker", "supervisor")
authoring_graph.add_edge("ChartGenerator", "supervisor")# 添加条件边
authoring_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"DocWriter": "DocWriter","NoteTaker": "NoteTaker","ChartGenerator": "ChartGenerator","FINISH": END,},
)authoring_graph.add_edge(START, "supervisor")
authoring_chain = authoring_graph.compile()
- 节点:
DocWriter、NoteTaker和ChartGenerator:具体的代理节点,分别负责文档写作、笔记记录和图表生成。supervisor:文档写作团队内部的主管节点,负责在团队内部分配任务。
- 边:
- 子图内部的主管节点负责在
DocWriter、NoteTaker和ChartGenerator之间分配任务。 - 顶层主管将任务分配给文档写作团队,然后文档写作团队内部继续分配。
- 子图内部的主管节点负责在
3.3 执行顶层图
顶层图负责协调研究团队和文档写作团队的任务。以下是执行顶层图的示例代码:
# 示例执行函数
def run_super_graph():"""运行顶层图的示例。"""initial_state = {"messages": [HumanMessage(content="Write a brief research report on the North American sturgeon. Include a chart.")],}for s in super_graph.stream(initial_state,{"recursion_limit": 150},):if "__end__" not in s:print(s)print("---")
执行流程:
- 用户输入:用户请求编写关于北美鲟鱼的简要研究报告并包含图表。
- 顶层主管决定:根据请求,顶层主管决定首先分配给
ResearchTeam进行研究。 - 研究团队执行:
ResearchTeam内部的Search和WebScraper代理执行搜索和抓取任务,完成后将结果返回给顶层主管。 - 主管分配:顶层主管根据研究结果,决定将任务分配给
PaperWritingTeam进行报告编写。 - 文档写作团队执行:
PaperWritingTeam内部的DocWriter、NoteTaker和ChartGenerator代理根据研究结果编写报告并生成图表。 - 任务完成:文档写作团队完成任务后,主管回应
FINISH,结束整个流程。
3.4 图之间的数据共享与交互
在层级化系统中,数据共享和交互通常通过以下几种方式实现:
3.4.1 状态传递
顶层图和子图之间通过状态(State)传递数据。例如,顶层图将用户的请求传递给ResearchTeam,子图完成后将结果传递回顶层图,然后再将结果传递给PaperWritingTeam。
代码示例:
# 研究团队完成任务后,将结果传递给顶层图
research_result = {"messages": [HumanMessage(content="...研究结果内容...", name='WebScraper')]
}# 这些结果将被传递给顶层图,并可能被分配给 PaperWritingTeam
3.4.2 共享存储
子图可以将数据存储在共享的文件系统或数据库中,其他子图可以访问这些数据。例如,研究团队将研究结果保存到一个文件中,文档写作团队读取该文件以编写报告。
代码示例:
# ResearchTeam 子图执行完研究任务后,将结果写入文件
write_document("研究结果内容", "research_results.txt")# PaperWritingTeam 子图读取研究结果文件
read_document("research_results.txt")
3.4.3 环境变量或全局状态
可以使用环境变量或全局状态对象,在不同图之间共享必要的数据。但需要注意数据的一致性和安全性。
4. 进一步优化与扩展
4.1 添加更多子图
随着系统的扩展,您可能需要添加更多的子图来处理不同类型的任务。例如,添加一个数据分析团队(DataAnalysisTeam)来处理数据统计和分析任务。
步骤:
- 定义新的工具:为新团队定义专用工具,如数据分析工具。
- 创建新子图:类似于
ResearchTeam和PaperWritingTeam,创建新的子图。 - 更新顶层主管:将新团队添加到顶层主管的管理列表中,并更新路由逻辑。
4.2 更复杂的任务协调
在更复杂的应用场景中,可能需要更复杂的协调逻辑。例如,多个子图可能需要并行执行任务,或者某些任务需要多个子图的协作。
实现方法:
- 并行执行:顶层主管可以同时分配任务给多个子图,并等待它们的结果。
- 依赖管理:使用状态对象管理任务之间的依赖关系,确保任务按正确的顺序执行。
4.3 错误处理与恢复
在实际应用中,可能会遇到各种错误情况,如代理失败、API调用失败等。需要在系统中实现错误处理和恢复机制,以确保系统的健壮性。
实现方法:
- 重试机制:在代理失败时自动重试任务。
- 备用路径:定义备用的任务分配路径,以应对某些子图无法执行任务的情况。
- 日志记录:记录错误日志,便于后续排查和修复问题。
5. 实际示例与执行
让我们回顾一下如何通过实际代码运行整个层级化的代理团队系统,并观察其协调机制。
5.1 执行顶层图
def run_super_graph():"""运行顶层图的示例。"""initial_state = {"messages": [HumanMessage(content="Write a brief research report on the North American sturgeon. Include a chart.")],}for s in super_graph.stream(initial_state,{"recursion_limit": 150},):if "__end__" not in s:print(s)print("---")
执行流程:
- 初始化状态:设置初始的用户请求消息。
- 任务分配:顶层主管决定将任务分配给
ResearchTeam。 - 研究团队执行:
ResearchTeam执行搜索和网页抓取任务,完成后将结果返回给顶层主管。 - 任务重新分配:顶层主管将任务分配给
PaperWritingTeam。 - 文档写作团队执行:
PaperWritingTeam编写报告并生成图表,完成后将结果返回给顶层主管。 - 结束任务:顶层主管回应
FINISH,任务结束。
5.2 执行研究团队与文档写作团队
def main():"""主函数,运行研究团队和文档写作团队的示例。"""print("运行研究团队示例...")for s in research_chain.stream("when is Taylor Swift's next tour?", {"recursion_limit": 100}):if "__end__" not in s:print(s)print("---")print("\n运行文档写作团队示例...")for s in authoring_chain.stream("Write an outline for a poem and then write the poem to disk.",{"recursion_limit": 100},):if "__end__" not in s:print(s)print("---")print("\n运行顶层图示例...")run_super_graph()
执行流程:
- 研究团队示例:模拟研究团队处理搜索任务。
- 文档写作团队示例:模拟文档写作团队编写大纲和诗歌。
- 顶层图示例:运行整个层级化系统,处理研究报告和图表生成任务。
6. 总结与建议
通过层级化的代理团队系统,您可以高效地管理复杂的任务分配和执行流程。以下是一些关键的总结和建议:
6.1 关键点回顾
- 层级化分配:通过顶层主管协调多个子图,实现任务的层级化分配,提高系统的扩展性和效率。
- 工具定义:为不同团队定义专用工具,满足各自的任务需求。
- 状态传递:利用状态对象在顶层图和子图之间传递必要的数据,实现数据共享和任务协作。
- 条件路由:使用条件边(conditional edges)根据任务状态动态决定下一个执行的子图或任务。
- 错误处理:在系统中实现错误处理和恢复机制,确保系统的健壮性。
6.2 最佳实践
- 模块化设计:将不同功能的代理和工具分离,保持代码的模块化和可维护性。
- 清晰的职责分离:确保每个子图或代理团队有明确的职责,避免职责重叠和混乱。
- 灵活的扩展性:设计系统时考虑到未来的扩展需求,便于添加新的子图或代理团队。
- 充分的日志记录:记录系统的运行日志,便于排查问题和优化系统性能。
- 安全性考虑:尤其在涉及文件系统访问和代码执行时,确保系统的安全性,防止潜在的安全风险。
6.3 进一步学习
- 深入了解LangGraph:阅读LangGraph的官方文档和源码,了解其内部机制和高级功能。
- 探索更多示例:通过构建更多的实际示例,提升对层级化代理团队系统的理解和掌握。
- 参与社区交流:加入相关的开发者社区,与其他开发者交流经验和技巧,共同进步。
希望这份详细的讲解能帮助您更深入地理解LangGraph中图之间的协调机制。如果您有任何进一步的问题或需要更具体的指导,请随时提问!
汇总
当然可以!以下是将您提供的LangGraph入门文档中的所有工程代码汇总到一个完整的Python文件中的版本。您可以将其保存为一个 .py 文件(例如 langgraph_intro.py)并在您的环境中执行。请确保在运行此脚本之前已经安装了所有必要的依赖包,并且您拥有有效的 OPENAI_API_KEY 和 TAVILY_API_KEY。
# langgraph_intro.py
# LangGraph 层级代理团队入门示例# 环境设置
# 请确保已经安装了所需的包:
# pip install -U langgraph langchain langchain_openai langchain_experimentalimport os
import getpass
import functools
import operator
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import List, Dict, Optional
from typing_extensions import TypedDict
from langchain_experimental.utilities import PythonREPL
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, BaseMessage
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import create_react_agent# 注意:以下导入适用于Jupyter环境,用于显示图像。在纯Python环境中可能需要调整或移除。
try:from IPython.display import Image, display
except ImportError:# 如果不在Jupyter环境中,定义一个空的display函数def display(*args, **kwargs):pass# 设置环境变量函数
def _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}: ")# 设置OPENAI_API_KEY和TAVILY_API_KEY
_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")# 创建临时工作目录
_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(_TEMP_DIRECTORY.name)# 初始化ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")# 定义Trimmer,用于裁剪消息
from langchain_core.messages import trim_messagestrimmer = trim_messages(max_tokens=100000,strategy="last",token_counter=llm,include_system=True,
)# 定义工具# 研究团队工具
tavily_tool = TavilySearchResults(max_results=5)@tool
def scrape_webpages(urls: List[str]) -> str:"""使用requests和bs4抓取提供的网页以获取详细信息。"""loader = WebBaseLoader(urls)docs = loader.load()return "\n\n".join([f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'for doc in docs])# 文档写作团队工具@tool
def create_outline(points: List[str],file_name: str,
) -> str:"""创建并保存大纲。"""with (WORKING_DIRECTORY / file_name).open("w") as file:for i, point in enumerate(points):file.write(f"{i + 1}. {point}\n")return f"大纲已保存到 {file_name}"@tool
def read_document(file_name: str,start: Optional[int] = 0,end: Optional[int] = None,
) -> str:"""读取指定的文档。"""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()return "\n".join(lines[start:end])@tool
def write_document(content: str,file_name: str,
) -> str:"""创建并保存文本文档。"""with (WORKING_DIRECTORY / file_name).open("w") as file:file.write(content)return f"文档已保存到 {file_name}"@tool
def edit_document(file_name: str,inserts: Dict[int, str],
) -> str:"""通过在特定行号插入文本来编辑文档。"""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()sorted_inserts = sorted(inserts.items())for line_number, text in sorted_inserts:if 1 <= line_number <= len(lines) + 1:lines.insert(line_number - 1, text + "\n")else:return f"错误:行号 {line_number} 超出范围。"with (WORKING_DIRECTORY / file_name).open("w") as file:file.writelines(lines)return f"文档已编辑并保存到 {file_name}"# 警告:此功能在本地执行代码,未进行沙箱处理时可能不安全
repl = PythonREPL()@tool
def python_repl(code: str,
) -> str:"""使用此工具执行Python代码。如果想查看变量的输出,应该使用`print(...)`。输出对用户可见。"""try:result = repl.run(code)except BaseException as e:return f"执行失败。错误:{repr(e)}"return f"执行成功:\n```python\n{code}\n```\n标准输出:{result}"# 辅助工具函数def agent_node(state, agent, name):result = agent.invoke(state)return {"messages": [HumanMessage(content=result["messages"][-1].content, name=name)]}def create_team_supervisor(llm: ChatOpenAI, system_prompt: str, members: List[str]) -> str:"""基于LLM的路由器。"""options = ["FINISH"] + membersfunction_def = {"name": "route","description": "选择下一个角色。","parameters": {"title": "routeSchema","type": "object","properties": {"next": {"title": "Next","anyOf": [{"enum": options},],},},"required": ["next"],},}prompt = ChatPromptTemplate.from_messages([("system", system_prompt),MessagesPlaceholder(variable_name="messages"),("system","根据以上对话,谁应该下一个行动?或者我们应该 FINISH?请选择以下之一:{options}",),]).partial(options=str(options), team_members=", ".join(members))return (prompt| trimmer| llm.bind_functions(functions=[function_def], function_call="route")| JsonOutputFunctionsParser())# 定义研究团队class ResearchTeamState(TypedDict):"""研究团队的状态。"""messages: List[BaseMessage]team_members: List[str]next: strsearch_agent = create_react_agent(llm, tools=[tavily_tool])
search_node = functools.partial(agent_node, agent=search_agent, name="Search")research_agent = create_react_agent(llm, tools=[scrape_webpages])
research_node = functools.partial(agent_node, agent=research_agent, name="WebScraper")supervisor_agent = create_team_supervisor(llm,"你是一个主管,负责管理以下工作者之间的对话:Search, WebScraper。根据以下用户请求,回应下一个行动的工作者。每个工作者将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["Search", "WebScraper"],
)# 定义研究团队图
research_graph = StateGraph(ResearchTeamState)
research_graph.add_node("Search", search_node)
research_graph.add_node("WebScraper", research_node)
research_graph.add_node("supervisor", supervisor_agent)# 定义控制流程
research_graph.add_edge("Search", "supervisor")
research_graph.add_edge("WebScraper", "supervisor")
research_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"Search": "Search", "WebScraper": "WebScraper", "FINISH": END},
)research_graph.add_edge(START, "supervisor")
research_chain = research_graph.compile()# 定义进入研究链的函数
def enter_research_chain(message: str):return {"messages": [HumanMessage(content=message)],}# 研究链
research_chain = enter_research_chain | research_chain# 定义文档写作团队class DocWritingState(TypedDict):"""文档写作团队的状态。"""messages: List[BaseMessage]team_members: strnext: strcurrent_files: strdef prelude(state: DocWritingState) -> DocWritingState:"""在每次调用代理前运行,注入当前工作目录的状态。"""written_files = []if not WORKING_DIRECTORY.exists():WORKING_DIRECTORY.mkdir()try:written_files = [f.relative_to(WORKING_DIRECTORY) for f in WORKING_DIRECTORY.rglob("*")]except Exception:passif not written_files:return {**state, "current_files": "No files written."}return {**state,"current_files": "\n以下是您的团队已写入目录的文件:\n" + "\n".join([f" - {f}" for f in written_files]),}doc_writer_agent = create_react_agent(llm, tools=[write_document, edit_document, read_document]
)
# 注入当前目录工作状态
context_aware_doc_writer_agent = prelude | doc_writer_agent
doc_writing_node = functools.partial(agent_node, agent=context_aware_doc_writer_agent, name="DocWriter"
)note_taking_agent = create_react_agent(llm, tools=[create_outline, read_document])
context_aware_note_taking_agent = prelude | note_taking_agent
note_taking_node = functools.partial(agent_node, agent=context_aware_note_taking_agent, name="NoteTaker"
)chart_generating_agent = create_react_agent(llm, tools=[read_document, python_repl])
context_aware_chart_generating_agent = prelude | chart_generating_agent
chart_generating_node = functools.partial(agent_node, agent=context_aware_chart_generating_agent, name="ChartGenerator"
)doc_writing_supervisor = create_team_supervisor(llm,"你是一个主管,负责管理以下工作者之间的对话:DocWriter, NoteTaker, ChartGenerator。根据以下用户请求,回应下一个行动的工作者。每个工作者将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["DocWriter", "NoteTaker", "ChartGenerator"],
)# 定义文档写作团队图
authoring_graph = StateGraph(DocWritingState)
authoring_graph.add_node("DocWriter", doc_writing_node)
authoring_graph.add_node("NoteTaker", note_taking_node)
authoring_graph.add_node("ChartGenerator", chart_generating_node)
authoring_graph.add_node("supervisor", doc_writing_supervisor)# 添加边
authoring_graph.add_edge("DocWriter", "supervisor")
authoring_graph.add_edge("NoteTaker", "supervisor")
authoring_graph.add_edge("ChartGenerator", "supervisor")# 添加条件边
authoring_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"DocWriter": "DocWriter","NoteTaker": "NoteTaker","ChartGenerator": "ChartGenerator","FINISH": END,},
)authoring_graph.add_edge(START, "supervisor")
authoring_chain = authoring_graph.compile()# 定义进入文档写作链的函数
def enter_authoring_chain(message: str, members: List[str]):return {"messages": [HumanMessage(content=message)],"team_members": ", ".join(members),}# 文档写作链
authoring_chain = (functools.partial(enter_authoring_chain, members=authoring_graph.nodes)| authoring_chain
)# 定义顶层图supervisor_node = create_team_supervisor(llm,"你是一个主管,负责管理以下团队之间的对话:ResearchTeam, PaperWritingTeam。根据以下用户请求,回应下一个行动的团队。每个团队将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["ResearchTeam", "PaperWritingTeam"],
)class State(TypedDict):"""顶层图的状态。"""messages: List[BaseMessage]next: strdef get_last_message(state: State) -> str:return state["messages"][-1].contentdef join_graph(response: dict) -> dict:return {"messages": [response["messages"][-1]]}# 定义顶层图
super_graph = StateGraph(State)
# 添加节点
super_graph.add_node("ResearchTeam", get_last_message | research_chain | join_graph)
super_graph.add_node("PaperWritingTeam", get_last_message | authoring_chain | join_graph
)
super_graph.add_node("supervisor", supervisor_node)# 添加边
super_graph.add_edge("ResearchTeam", "supervisor")
super_graph.add_edge("PaperWritingTeam", "supervisor")
super_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"PaperWritingTeam": "PaperWritingTeam","ResearchTeam": "ResearchTeam","FINISH": END,},
)super_graph.add_edge(START, "supervisor")
super_graph = super_graph.compile()# 示例执行函数
def run_super_graph():"""运行顶层图的示例。"""initial_state = {"messages": [HumanMessage(content="Write a brief research report on the North American sturgeon. Include a chart.")],}for s in super_graph.stream(initial_state,{"recursion_limit": 150},):if "__end__" not in s:print(s)print("---")# 主函数
def main():"""主函数,运行研究团队和文档写作团队的示例。"""print("运行研究团队示例...")for s in research_chain.stream("when is Taylor Swift's next tour?", {"recursion_limit": 100}):if "__end__" not in s:print(s)print("---")print("\n运行文档写作团队示例...")for s in authoring_chain.stream("Write an outline for a poem and then write the poem to disk.",{"recursion_limit": 100},):if "__end__" not in s:print(s)print("---")print("\n运行顶层图示例...")run_super_graph()if __name__ == "__main__":main()
说明
-
环境设置:
- 安装依赖包:确保已经安装了
langgraph、langchain、langchain_openai和langchain_experimental。可以使用pip命令进行安装。 - API 密钥:脚本会提示您输入
OPENAI_API_KEY和TAVILY_API_KEY,请确保您已经在 OpenAI 和 Tavily 获取了相应的API密钥。
- 安装依赖包:确保已经安装了
-
工具定义:
- 研究团队工具:
scrape_webpages: 用于抓取指定URL的网页内容。
- 文档写作团队工具:
create_outline: 创建并保存大纲。read_document: 读取文档内容。write_document: 写入文档内容。edit_document: 编辑文档内容。python_repl: 执行Python代码。
- 研究团队工具:
-
辅助函数:
agent_node: 用于代理节点的通用函数。create_team_supervisor: 创建团队主管,用于路由任务。
-
团队定义:
- 研究团队:
- 包含
Search和WebScraper两个工作节点,以及一个主管supervisor。
- 包含
- 文档写作团队:
- 包含
DocWriter、NoteTaker和ChartGenerator三个工作节点,以及一个主管supervisor。
- 包含
- 研究团队:
-
顶层图:
- 管理
ResearchTeam和PaperWritingTeam两个子团队的任务分配。
- 管理
-
执行示例:
main函数中依次运行了研究团队、文档写作团队和顶层图的示例任务。
执行步骤
-
保存脚本:
- 将上述代码保存为
langgraph_intro.py。
- 将上述代码保存为
-
运行脚本:
-
在终端或命令行中导航到脚本所在的目录,执行以下命令:
python langgraph_intro.py
-
-
观察输出:
- 脚本会依次运行研究团队、文档写作团队和顶层图的示例任务,并在终端中打印输出结果。
注意事项
-
图像显示:
- 由于纯Python环境中无法直接显示Jupyter的图像,相关的
display(Image(...))部分在非Jupyter环境中将不会显示任何内容。如果您希望查看图形化的流程图,建议在Jupyter Notebook中运行相关部分代码。
- 由于纯Python环境中无法直接显示Jupyter的图像,相关的
-
文件系统访问:
- 文档写作团队工具涉及文件系统的读写操作,请确保脚本有适当的权限,并注意安全性问题。
-
执行Python代码:
python_repl工具允许执行任意Python代码,这在生产环境中可能存在安全风险。请谨慎使用,确保代码来源可信。
-
API 调用成本:
- 使用OpenAI的API会产生费用,请确保了解相关费用结构,避免意外的高额账单。
简化
当然可以!为了帮助您更快地理解和学习,我将简化您的LangGraph入门示例代码。我们将定义两个子图:
- 浏览网页并编写文档的子图(WebBrowsingWritingTeam)
- 评审文档的子图(DocumentReviewTeam)
这样,整个系统将由一个顶层主管节点协调这两个子图的任务分配和执行。以下是简化后的完整代码,并附有详细的注释,方便您理解每个部分的功能。
# simplified_langgraph.py
# LangGraph 简化示例:两个子图 - 浏览网页并编写文档,以及评审文档# 环境设置
# 确保已经安装了所需的包:
# pip install -U langgraph langchain langchain_openai langchain_experimentalimport os
import getpass
import functools
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import List, Dict, Optional
from typing_extensions import TypedDictfrom langchain_experimental.utilities import PythonREPL
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, BaseMessage
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import create_react_agent# 定义一个空的display函数以兼容非Jupyter环境
def display(*args, **kwargs):pass# 设置环境变量函数
def set_api_keys():"""提示用户输入API密钥并设置环境变量。"""for var in ["OPENAI_API_KEY", "TAVILY_API_KEY"]:if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}: ")set_api_keys()# 创建临时工作目录
_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(_TEMP_DIRECTORY.name)# 初始化ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")# 定义Trimmer,用于裁剪消息(可选,简化示例中可忽略)# 定义工具# 1. 浏览网页并编写文档的工具
tavily_tool = TavilySearchResults(max_results=5)@tool
def scrape_webpages(urls: List[str]) -> str:"""使用WebBaseLoader抓取网页内容。"""loader = WebBaseLoader(urls)docs = loader.load()return "\n\n".join([f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'for doc in docs])@tool
def write_document(content: str, file_name: str) -> str:"""创建并保存文本文档。"""with (WORKING_DIRECTORY / file_name).open("w") as file:file.write(content)return f"文档已保存到 {file_name}"# 2. 评审文档的工具
@tool
def read_document(file_name: str) -> str:"""读取指定的文档。"""with (WORKING_DIRECTORY / file_name).open("r") as file:return file.read()@tool
def review_document(content: str) -> str:"""评审文档内容并提供反馈。"""# 这里可以集成更复杂的评审逻辑或工具return f"文档评审完成。内容摘要:{content[:200]}..."# 警告:执行Python代码的工具(简化示例中可忽略)# 定义辅助函数def agent_node(state, agent, name):"""代理节点的通用函数。"""result = agent.invoke(state)return {"messages": [HumanMessage(content=result["messages"][-1].content, name=name)]}def create_team_supervisor(llm: ChatOpenAI, system_prompt: str, members: List[str]) -> str:"""基于LLM的主管,用于路由任务。"""options = ["FINISH"] + membersfunction_def = {"name": "route","description": "选择下一个团队。","parameters": {"title": "routeSchema","type": "object","properties": {"next": {"title": "Next","anyOf": [{"enum": options},],},},"required": ["next"],},}prompt = ChatPromptTemplate.from_messages([("system", system_prompt),MessagesPlaceholder(variable_name="messages"),("system","根据以上对话,哪个团队应该下一个行动?或者我们应该 FINISH?请选择以下之一:{options}",),]).partial(options=str(options), team_members=", ".join(members))return (prompt| llm.bind_functions(functions=[function_def], function_call="route")| JsonOutputFunctionsParser())# 定义子图1:浏览网页并编写文档class WebBrowsingWritingState(TypedDict):messages: List[BaseMessage]team_members: List[str]next: str# 创建浏览和写作代理
search_agent = create_react_agent(llm, tools=[tavily_tool])
search_node = functools.partial(agent_node, agent=search_agent, name="Search")web_writer_agent = create_react_agent(llm, tools=[scrape_webpages, write_document])
web_writer_node = functools.partial(agent_node, agent=web_writer_agent, name="WebWriter")# 创建浏览和写作团队的主管
web_writing_supervisor = create_team_supervisor(llm,"你是一个主管,负责管理以下团队之间的对话:Search, WebWriter。根据以下用户请求,回应下一个行动的团队。每个团队将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["Search", "WebWriter"],
)# 定义浏览和写作团队图
web_writing_graph = StateGraph(WebBrowsingWritingState)
web_writing_graph.add_node("Search", search_node)
web_writing_graph.add_node("WebWriter", web_writer_node)
web_writing_graph.add_node("supervisor", web_writing_supervisor)# 定义控制流程
web_writing_graph.add_edge("Search", "supervisor")
web_writing_graph.add_edge("WebWriter", "supervisor")
web_writing_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"Search": "Search", "WebWriter": "WebWriter", "FINISH": END},
)web_writing_graph.add_edge(START, "supervisor")
web_writing_chain = web_writing_graph.compile()def enter_web_writing_chain(message: str):"""初始化浏览和写作团队的状态。"""return {"messages": [HumanMessage(content=message)],}web_writing_chain = enter_web_writing_chain | web_writing_chain# 定义子图2:评审文档class DocumentReviewState(TypedDict):messages: List[BaseMessage]team_members: List[str]next: str# 创建评审代理
document_reviewer_agent = create_react_agent(llm, tools=[read_document, review_document])
document_reviewer_node = functools.partial(agent_node, agent=document_reviewer_agent, name="DocumentReviewer")# 创建评审团队的主管
document_review_supervisor = create_team_supervisor(llm,"你是一个主管,负责管理以下团队之间的对话:DocumentReviewer。根据以下用户请求,回应下一个行动的团队。每个团队将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["DocumentReviewer"],
)# 定义评审团队图
document_review_graph = StateGraph(DocumentReviewState)
document_review_graph.add_node("DocumentReviewer", document_reviewer_node)
document_review_graph.add_node("supervisor", document_review_supervisor)# 定义控制流程
document_review_graph.add_edge("DocumentReviewer", "supervisor")
document_review_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"DocumentReviewer": "DocumentReviewer", "FINISH": END},
)document_review_graph.add_edge(START, "supervisor")
document_review_chain = document_review_graph.compile()def enter_document_review_chain(message: str):"""初始化评审团队的状态。"""return {"messages": [HumanMessage(content=message)],}document_review_chain = enter_document_review_chain | document_review_chain# 定义顶层图,用于协调两个子图class TopLevelState(TypedDict):messages: List[BaseMessage]next: str# 创建顶层主管
top_level_supervisor = create_team_supervisor(llm,"你是一个顶层主管,负责管理以下团队:WebBrowsingWritingTeam, DocumentReviewTeam。根据以下用户请求,回应下一个行动的团队。每个团队将执行任务并回应他们的结果和状态。当完成时,回应FINISH。",["WebBrowsingWritingTeam", "DocumentReviewTeam"],
)# 定义顶层图
top_level_graph = StateGraph(TopLevelState)
top_level_graph.add_node("WebBrowsingWritingTeam", web_writing_chain)
top_level_graph.add_node("DocumentReviewTeam", document_review_chain)
top_level_graph.add_node("supervisor", top_level_supervisor)# 定义顶层控制流程
top_level_graph.add_edge("WebBrowsingWritingTeam", "supervisor")
top_level_graph.add_edge("DocumentReviewTeam", "supervisor")
top_level_graph.add_conditional_edges("supervisor",lambda x: x["next"],{"WebBrowsingWritingTeam": "WebBrowsingWritingTeam", "DocumentReviewTeam": "DocumentReviewTeam", "FINISH": END},
)top_level_graph.add_edge(START, "supervisor")
top_level_chain = top_level_graph.compile()# 定义进入顶层图的函数
def enter_top_level_chain(message: str):"""初始化顶层图的状态。"""return {"messages": [HumanMessage(content=message)],}top_level_chain = enter_top_level_chain | top_level_chain# 定义主函数,演示如何运行顶层图
def main():"""主函数,运行顶层图示例。"""print("运行顶层图示例...")initial_message = "请浏览相关网页并编写一份关于北美鲟鱼的研究报告,然后评审该报告。"for s in top_level_chain.stream(initial_message,{"recursion_limit": 150},):if "__end__" not in s:print(s)print("---")if __name__ == "__main__":main()
代码说明
1. 环境设置
- 安装依赖包:确保已经安装了
langgraph、langchain、langchain_openai和langchain_experimental。 - 设置API密钥:通过
set_api_keys函数提示用户输入OPENAI_API_KEY和TAVILY_API_KEY,并设置为环境变量。 - 创建临时工作目录:用于存储生成的文档。
2. 定义工具
2.1 浏览网页并编写文档的工具
scrape_webpages:使用WebBaseLoader抓取指定URL的网页内容。write_document:将内容写入指定的文档文件。
2.2 评审文档的工具
read_document:读取指定的文档内容。review_document:对文档内容进行简单评审并返回反馈。
3. 定义辅助函数
agent_node:通用的代理节点函数,用于调用代理并返回结果。create_team_supervisor:创建一个主管代理,用于根据任务分配决定下一个行动的团队。
4. 定义子图
4.1 子图1:浏览网页并编写文档(WebBrowsingWritingTeam)
- 状态定义:
WebBrowsingWritingState,包含消息、团队成员和下一个行动。 - 代理定义:
Search:用于搜索信息的代理。WebWriter:用于抓取网页内容和编写文档的代理。
- 主管定义:
web_writing_supervisor,负责在Search和WebWriter之间分配任务。 - 子图定义:
web_writing_graph,包含Search、WebWriter和supervisor节点,并定义任务流转。
4.2 子图2:评审文档(DocumentReviewTeam)
- 状态定义:
DocumentReviewState,包含消息、团队成员和下一个行动。 - 代理定义:
DocumentReviewer:用于读取和评审文档的代理。
- 主管定义:
document_review_supervisor,负责在DocumentReviewer之间分配任务。 - 子图定义:
document_review_graph,包含DocumentReviewer和supervisor节点,并定义任务流转。
5. 定义顶层图(TopLevelGraph)
- 状态定义:
TopLevelState,包含消息和下一个行动。 - 主管定义:
top_level_supervisor,负责在WebBrowsingWritingTeam和DocumentReviewTeam之间分配任务。 - 顶层图定义:
top_level_graph,包含WebBrowsingWritingTeam、DocumentReviewTeam和supervisor节点,并定义任务流转。
6. 执行流程
- 主函数:
main函数演示如何运行顶层图,接收用户请求,协调两个子图的任务执行,并输出结果。
运行步骤
-
保存脚本:将上述代码保存为
simplified_langgraph.py。 -
运行脚本:
python simplified_langgraph.py -
观察输出:脚本会运行顶层图,协调两个子图执行任务,并在终端中打印输出结果。
简化与优化
- 减少复杂性:移除了不必要的工具和功能,专注于两个核心子图。
- 清晰的结构:通过定义明确的子图和顶层图,使得整个系统更易于理解和维护。
- 注释详尽:在关键部分添加了详细的注释,帮助理解每个组件的作用和流程。
扩展与优化建议
- 增加更多工具:根据需求,可以为每个子图添加更多专用工具,如高级文档编辑工具或更复杂的评审逻辑。
- 错误处理:在实际应用中,添加错误处理机制以应对代理失败或API调用问题。
- 日志记录:集成日志记录功能,以便跟踪任务执行过程和调试。
- 安全性考虑:确保文件系统访问和代码执行工具的安全性,防止潜在的安全风险。
希望这个简化的示例能帮助您更好地理解和学习LangGraph的层级代理团队系统。如果您有任何进一步的问题或需要更详细的解释,请随时提问!
5. 自定义多智能体工作流(Custom multi-agent workflow)
智能体之间的通信(Communication between agents)
构建多智能体系统时,最重要的是确定智能体之间如何通信。以下是需要考虑的几个方面:
- 智能体通过图状态(Graph state)还是通过工具调用(Tool calls)进行通信?
- 如果两个智能体有不同的状态模式(state schemas),应该如何处理?
- 如何在共享消息列表(shared message list)上进行通信?
图状态 vs 工具调用
图状态:
在大多数上述架构中,智能体通过图状态进行通信。这意味着每个智能体节点接收当前的图状态,执行其逻辑后更新状态,然后将更新后的状态传递给下一个节点。
工具调用:
在监督器工具调用架构中,通信的“负载”是工具调用的参数。监督器根据工具的定义调用相应的智能体工具,并传递必要的参数。
不同的状态模式(Different state schemas)
有时候,一个智能体可能需要与其他智能体不同的状态模式。例如,一个搜索智能体可能只需要跟踪查询和检索到的文档。
在 LangGraph 中实现的方法:
- 定义带有单独状态模式的子图智能体:如果子图与父图之间没有共享的状态键(channels),需要添加输入/输出转换,使父图能够与子图通信。
- 定义具有私有输入状态模式的智能体节点函数:使得传递给该智能体的信息仅限于执行该智能体所需的信息。
共享消息列表(Shared message list)
最常见的智能体通信方式是通过共享的状态通道,通常是一个消息列表。这假设状态中至少有一个共享的键(channel)被所有智能体共享。
共享完整历史 vs 仅共享最终结果:
-
共享完整历史(Share full history):
- 智能体可以共享其整个思考过程(即“草稿板”)与其他智能体。
- 优点:可能帮助其他智能体做出更好的决策,提高系统的整体推理能力。
- 缺点:随着智能体数量和复杂性的增加,“草稿板”会迅速增长,可能需要额外的内存管理策略。
-
仅共享最终结果(Share final result):
- 每个智能体有自己的私有“草稿板”,仅与其他智能体共享最终结果。
- 优点:适用于智能体数量多或智能体更复杂的系统。
- 缺点:需要定义具有不同状态模式的智能体。
工具调用情况下:
对于作为工具调用的智能体,监督器根据工具的模式决定输入。此外,LangGraph 允许在运行时向单个工具传递状态,使得下属智能体可以访问父状态(parent state),如果需要的话。
总结
通过以上内容,您应该对 LangGraph 中的多智能体系统有了更深入的理解。以下是关键要点的总结:
- 多智能体系统可以帮助解决单一智能体在复杂应用中的扩展性和管理问题。
- 多种架构(如网络架构、监督器架构、分层架构等)提供了不同的方式来组织和管理多个智能体。
- 智能体之间的通信是多智能体系统设计的核心,您需要根据应用需求选择合适的通信方式和状态管理策略。
- 代码示例展示了如何在 LangGraph 中实现不同的多智能体架构,帮助您在实际项目中应用这些概念。
希望这些解释能帮助您更好地理解 LangGraph 的多智能体系统,并在学习和开发过程中取得更好的效果。如果您有任何进一步的问题或需要更具体的解释,欢迎随时提问!